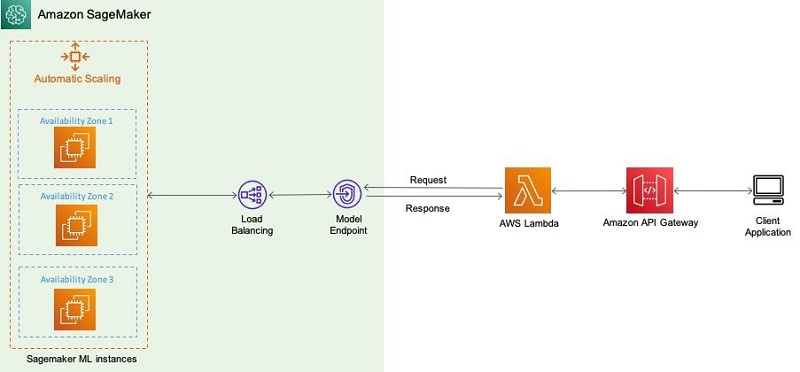
Amazon SageMaker Studio notebooks and Amazon SageMaker notebook instances are internet-enabled by default. However, many regulated industries, such as financial industries, healthcare, telecommunications, and others, require that network traffic traverses their own Amazon Virtual Private Cloud (Amazon VPC) to restrict and control which traffic can go through public internet. Although you can disable direct internet access to Sagemaker Studio notebooks and notebook instances, you need to ensure that your data scientists can still gain access to popular packages. Therefore, you may choose to build your own isolated dev environments that contain your choice of packages and kernels.
In this post, we learn how to set up such an environment for Amazon SageMaker notebook instances and SageMaker Studio. We also describe how to integrate this environment with AWS CodeArtifact, which is a fully managed artifact repository that makes it easy for organizations of any size to securely store, publish, and share software packages used in your software development process.
Solution overview
In this post, we cover the following steps:
- Set up the Amazon SageMaker for internet-free mode.
- Set up the Conda repository using Amazon Simple Storage Service (Amazon S3). You create a bucket that hosts your Conda channels.
- Set up the Python Package Index (PyPI) repository using CodeArtifact. You create a repository and set up AWS PrivateLink endpoints for CodeArtifact.
- Build an isolated dev environment with Amazon SageMaker notebook instances. In this step, you use the lifecycle configuration feature to build a custom Conda environment and configure your PyPI client.
- Install packages in SageMaker Studio notebooks. In this last step, you can create a custom Amazon SageMaker image and install the packages through Conda or pip client.
Setting up Amazon SageMaker for internet-free mode
We assume that you have already set up a VPC that lets you provision a private, isolated section of the AWS Cloud where you can launch AWS resources in a virtual network. You use it to host Amazon SageMaker and other components of your data science environment. For more information about building secure environments or well-architected pillars, see the following whitepaper, Financial Services Industry Lens: AWS Well-Architected Framework.
Creating an Amazon SageMaker notebook instance
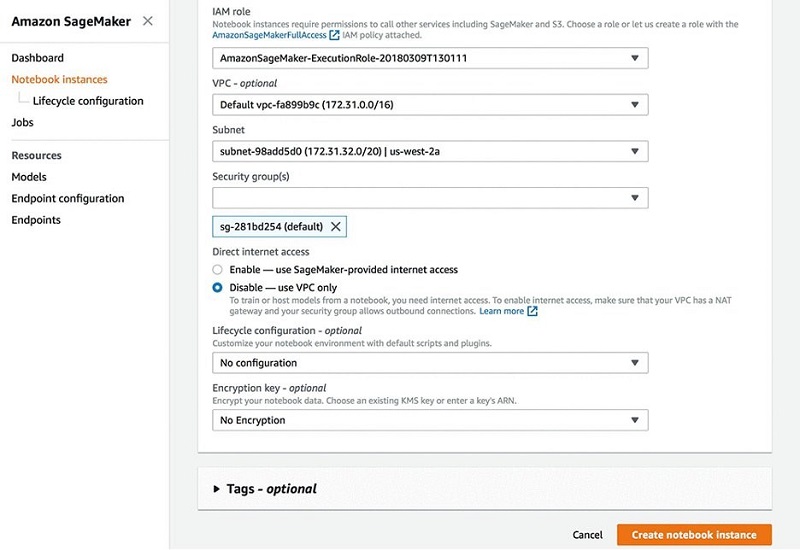
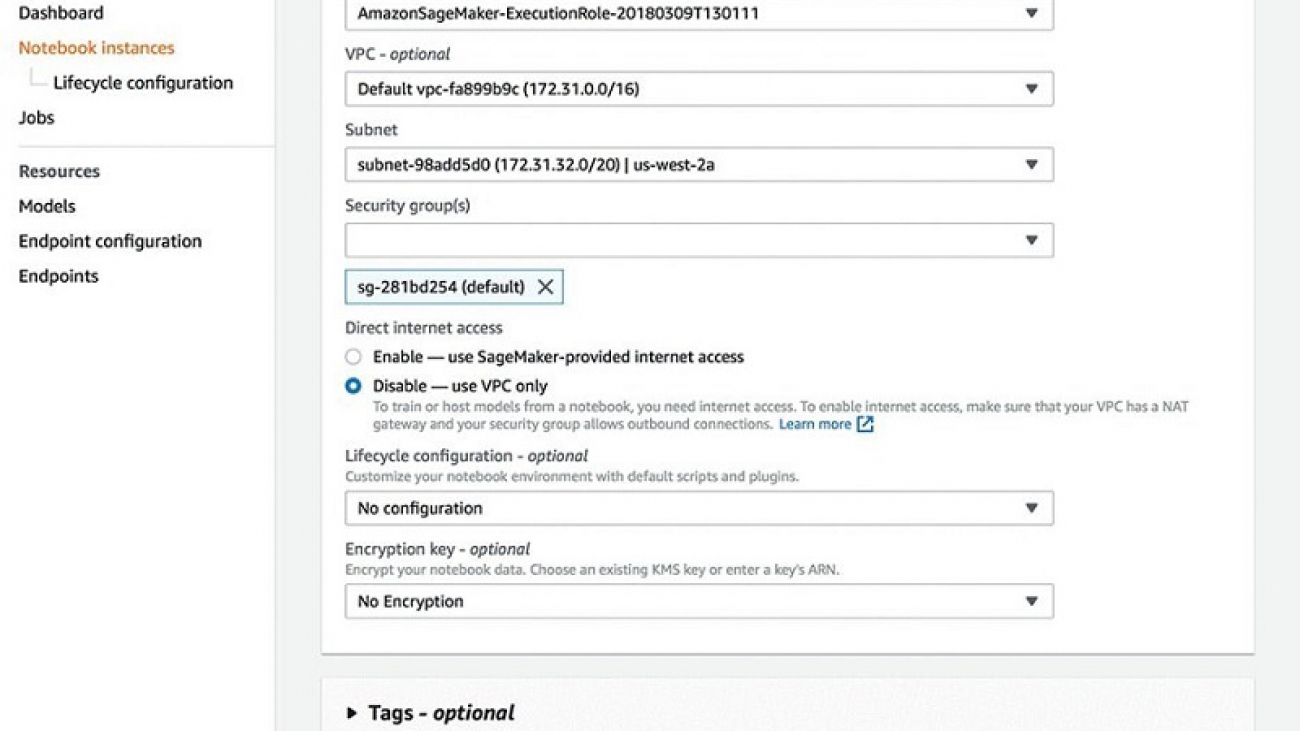
You can disable internet access for Amazon SageMaker notebooks, and also associate them to your secure VPC environment, which allows you to apply network-level control, such as access to resources through security groups, or to control ingress and egress traffic of data.
- On the Amazon SageMaker console, choose Notebook instances in the navigation pane.
- Choose Create notebook instance.
- For IAM role, choose your role.
- For VPC, choose your VPC.
- For Subnet, choose your subnet.
- For Security groups(s), choose your security group.
- For Direct internet access, select Disable — use VPC only.
- Choose Create notebook instance.
- Connect to your notebook instance from your VPC instead of connecting over the public internet.
Amazon SageMaker notebook instances support VPC interface endpoints. When you use a VPC interface endpoint, communication between your VPC and the notebook instance is conducted entirely and securely within the AWS network instead of the public internet. For instructions, see Creating an interface endpoint.
Setting up SageMaker Studio
Similar to Amazon SageMaker notebook instances, you can launch SageMaker Studio in a VPC of your choice, and also disable direct internet access to add an additional layer of security.
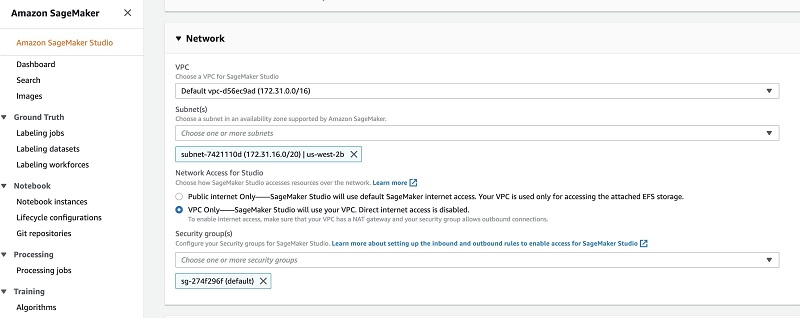
- On the Amazon SageMaker console, choose Amazon SageMaker Studio in the navigation pane.
- Choose Standard setup.
- To disable direct internet access, in the Network section, select the VPC only network access type for when you onboard to Studio or call the CreateDomain API.
Doing so prevents Amazon SageMaker from providing internet access to your SageMaker Studio notebooks.
- Create interface endpoints (via AWS PrivateLink) to access the following (and other AWS services you may require):
- Amazon SageMaker API
- Amazon SageMaker runtime
- Amazon S3
- AWS Security Token Service (AWS STS)
- Amazon CloudWatch
Setting up a custom Conda repository using Amazon S3
Amazon SageMaker notebooks come with multiple environments already installed. The different Jupyter kernels in Amazon SageMaker notebooks are separate Conda environments. If you want to use an external library in a specific kernel, you can install the library in the environment for that kernel. This is typically done using conda install. When you use a conda command to install a package, Conda environment searches a set of default channels, which are usually online or remote channels (URLs) that host the Conda packages. However, because we assume the notebook instances don’t have internet access, we modify those Conda channel paths to a private repository where our packages are stored.
- Build such custom channel is to create a bucket in Amazon S3.
- Copy the packages into the bucket.
These packages can be either approved packages among the organization or the custom packages built using conda build. These packages need to be indexed periodically or as soon as there is an update. The methods to index packages are out of scope of this post.
Because we set up the notebook to not allow direct internet access, the notebook can’t connect to the S3 buckets that contain the channels unless you create a VPC endpoint.
- Create an Amazon S3 VPC endpoint to send the traffic through the VPC instead of the public internet.
By creating a VPC endpoint, you allow your notebook instance to access the bucket where you stored the channels and its packages.
- We recommend that you also create a custom resource-based bucket policy that allows only requests from your private VPC to access to your S3 buckets. For instructions, see Endpoints for Amazon S3.
- Replace the default channels of the Conda environment in your Amazon SageMaker notebooks with your custom channel (we do that in the next step when we build the isolated dev environment):
# remove default channel from the .condarc
conda config --remove channels 'defaults'
# add the conda channels to the .condarc file
conda config --add channels 's3://user-conda-repository/main/'
conda config --add channels 's3://user-conda-repository/condaforge/'
Setting up a custom PyPI repository using CodeArtifact
Data scientists typically use package managers such as pip, maven, npm, and others to install packages into their environments. By default, when you use pip to install a package, it downloads the package from the public PyPI repository. To secure your environment, you can use private package management tools either on premises, such as Artifactory or Nexus, or on AWS, such as CodeArtifact. This allows you to allow access only to approved packages and perform safety checks. Alternatively, you may choose use a private PyPI mirror set up on Amazon Elastic Container Service (Amazon ECS) or AWS Fargate to mirror the public PyPI repository in your private environment. For more information on this approach, see Building Secure Environments.
If you want to use pip to install Python packages, you can use CodeArtifact to control access to and validate the safety of the Python packages. CodeArtifact is a managed artifact repository service to help developers and organizations securely store and share the software packages used in your development, build, and deployment processes. The CodeArtifact integration with AWS Identity and Access Management (IAM), support for AWS CloudTrail, and encryption with AWS Key Management Service (AWS KMS) gives you visibility and the ability to control who has access to the packages.
You can configure CodeArtifact to fetch software packages from public repositories such as PyPI. PyPI helps you find and install software developed and shared by the Python community. When you pull a package from PyPI, CodeArtifact automatically downloads and stores application dependencies from the public repositories, so recent versions are always available to you.
Creating a repository for PyPI
You can create a repository using the CodeArtifact console or the AWS Command Line Interface (AWS CLI). Each repository is associated with the AWS account that you use when you create it. The following screenshot shows the view of choosing your AWS account on the CodeArtifact console.

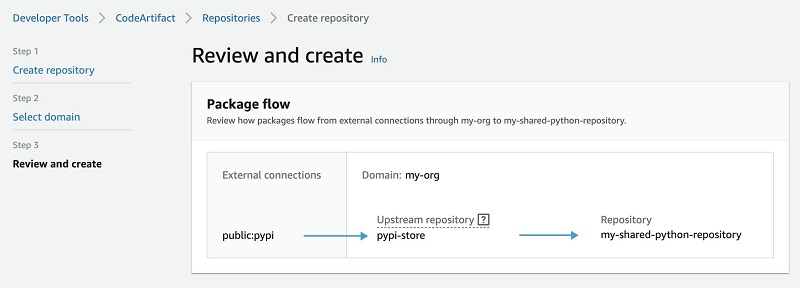
A repository can have one or more CodeArtifact repository associated with it as an upstream repository. It can facilitate two needs.
Firstly, it allows a package manager client to access the packages contained in more than one repository using a single URL endpoint.
Secondly, when you create a repository, it doesn’t contain any packages. If an upstream repository has an external connection to a public repository, the repositories that are downstream from it can pull packages from that public repository. For example, the repository my-shared-python-repository has an upstream repository named pypi-store, which acts as an intermediate repository that connects your repository to an external connection (your PyPI repository). In this case, a package manager that is connected to my-shared-python-repository can pull packages from the PyPI public repository. The following screenshot shows this package flow.
For instructions on creating a CodeArtifact repository, see Software Package Management with AWS CodeArtifact.
Because we disable internet access for the Amazon SageMaker notebooks, in the next section, we set up AWS PrivateLink endpoints to make sure all the traffic for installing the package in the notebooks traverses through the VPC.
Setting up AWS PrivateLink endpoints for CodeArtifact
You can configure CodeArtifact to use an interface VPC endpoint to improve the security of your VPC. When you use an interface VPC endpoint, you don’t need an internet gateway, NAT device, or virtual private gateway. To create VPC endpoints for CodeArtifact, you can use the AWS CLI or Amazon VPC console. For this post, we use the Amazon Elastic Compute Cloud (Amazon EC2) create-vpc-endpoint AWS CLI command. The following two VPC endpoints are required so that all requests to CodeArtifact are in the AWS network.
The following command creates an endpoint to access CodeArtifact repositories:
aws ec2 create-vpc-endpoint --vpc-id vpcid --vpc-endpoint-type Interface
--service-name com.amazonaws.region.codeartifact.api --subnet-ids subnetid
--security-group-ids groupid
The following command creates an endpoint to access package managers and build tools:
aws ec2 create-vpc-endpoint --vpc-id vpcid --vpc-endpoint-type Interface
--service-name com.amazonaws.region.codeartifact.repositories --subnet-ids subnetid
--security-group-ids groupid --private-dns-enabled
CodeArtifact uses Amazon S3 to store package assets. To pull packages from CodeArtifact, you must create a gateway endpoint for Amazon S3. See the following code:
aws ec2 create-vpc-endpoint --vpc-id vpcid --service-name com.amazonaws.region.s3
--route-table-ids routetableid
Building your dev environment
Amazon SageMaker periodically updates the Python and dependency versions in the environments installed on the Amazon SageMaker notebook instances (when you stop and start) or in the images launched in SageMaker Studio. This might cause some incompatibility if you have your own managed package repositories and dependencies. You can freeze your dependencies in internet-free mode so that:
- You’re not affected by periodic updates from Amazon SageMaker to the base environment
- You have better control over the dependencies in your environments and can get ample time to update or upgrade your dependencies
Using Amazon SageMaker notebook instancesartifcat
To create your own dev environment with specific versions of Python and dependencies, you can use lifecycle configuration scripts. A lifecycle configuration provides shell scripts that run only when you create the notebook instance or whenever you start one. When you create a notebook instance, you can create a new lifecycle configuration and the scripts it uses or apply one that you already have. Amazon SageMaker has a lifecycle config script sample that you can use and modify to create isolated dependencies as described earlier. With this script, you can do the following:
- Build an isolated installation of Conda
- Create a Conda environment with it
- Make the environment available as a kernel in Jupyter
This makes sure that dependencies in that kernel aren’t affected by the upgrades that Amazon SageMaker periodically roles out to the underlying AMI. This script installs a custom, persistent installation of Conda on the notebook instance’s EBS volume, and ensures that these custom environments are available as kernels in Jupyter. We add Conda and CodeArtifact configuration to this script.
The on-create script downloads and installs a custom Conda installation to the EBS volume via Miniconda. Any relevant packages can be installed here.
- Set up CodeArtifact.
- Set up your Conda channels.
- Install
ipykernel to make sure that the custom environment can be used as a Jupyter kernel.
- Make sure the notebook instance has internet connectivity to download the Miniconda installer.
The on-create script installs the ipykernel library so you can use create custom environments as Jupyter kernels, and uses pip install and conda install to install libraries. You can adapt the script to create custom environments and install the libraries that you want. Amazon SageMaker doesn’t update these libraries when you stop and restart the notebook instance, so you can make sure that your custom environment has specific versions of libraries that you want. See the following code:
#!/bin/bash
set -e
sudo -u ec2-user -i <<'EOF'
unset SUDO_UID
# Configure common package managers to use CodeArtifact
aws codeartifact login --tool pip --domain my-org --domain-owner <000000000000> --repository my-shared-python-repository --endpoint-url https://vpce-xxxxx.api.codeartifact.us-east-1.vpce.amazonaws.com
# Install a separate conda installation via Miniconda
WORKING_DIR=/home/ec2-user/SageMaker/custom-miniconda
mkdir -p "$WORKING_DIR"
wget https://repo.anaconda.com/miniconda/Miniconda3-4.6.14-Linux-x86_64.sh -O "$WORKING_DIR/miniconda.sh"
bash "$WORKING_DIR/miniconda.sh" -b -u -p "$WORKING_DIR/miniconda"
rm -rf "$WORKING_DIR/miniconda.sh"
# Create a custom conda environment
source "$WORKING_DIR/miniconda/bin/activate"
# remove default channel from the .condarc
conda config --remove channels 'defaults'
# add the conda channels to the .condarc file
conda config --add channels 's3://user-conda-repository/main/'
conda config --add channels 's3://user-conda-repository/condaforge/'
KERNEL_NAME="custom_python"
PYTHON="3.6"
conda create --yes --name "$KERNEL_NAME" python="$PYTHON"
conda activate "$KERNEL_NAME"
pip install --quiet ipykernel
# Customize these lines as necessary to install the required packages
conda install --yes numpy
pip install --quiet boto3
EOF
The on-start script uses the custom Conda environment created in the on-create script, and uses the ipykernel package to add that as a kernel in Jupyter, so that they appear in the drop-down list in the Jupyter New menu. It also logs in to CodeArtifact to enable installing the packages from the custom repository. See the following code:
#!/bin/bash
set -e
sudo -u ec2-user -i <<'EOF'
unset SUDO_UID
# Get pip artifact
/home/ec2-user/SageMaker/aws/aws codeartifact login --tool pip --domain <my-org> --domain-owner <xxxxxxxxx> --repository <my-shared-python-repository. --endpoint-url <https://vpce-xxxxxxxx.api.codeartifact.us-east-1.vpce.amazonaws.com>
WORKING_DIR=/home/ec2-user/SageMaker/custom-miniconda/
source "$WORKING_DIR/miniconda/bin/activate"
for env in $WORKING_DIR/miniconda/envs/*; do
BASENAME=$(basename "$env")
source activate "$BASENAME"
python -m ipykernel install --user --name "$BASENAME" --display-name "Custom ($BASENAME)"
done
EOF
echo "Restarting the Jupyter server.."
restart jupyter-server
CodeArtifact authorization tokens are valid for a default period of 12 hours. You can add a cron job to the on-start script to refresh the token automatically, or log in to CodeArtifact again in the Jupyter notebook terminal.
Using SageMaker Studio notebooks
You can create your own custom Amazon SageMaker images in your private dev environment in SageMaker Studio. You can add the custom kernels, packages, and any other files required to run a Jupyter notebook in your image. It gives you the control and flexibility to do the following:
- Install your own custom packages in the image
- Configure the images to be integrated with your custom repositories for package installation by users
For example, you can install a selection of R or Python packages when building the image:
# Dockerfile
RUN conda install --quiet --yes
'r-base=4.0.0'
'r-caret=6.*'
'r-crayon=1.3*'
'r-devtools=2.3*'
'r-forecast=8.12*'
'r-hexbin=1.28*'
Or you can set up the Conda in the image to just use your own custom channels in Amazon S3 to install packages by changing the configuration of Conda channels:
# Dockerfile
RUN
# add the conda channels to the .condarc file
conda config --add channels 's3://my-conda-repository/_conda-forge/' &&
conda config --add channels 's3://my-conda-repository/main/' &&
# remove defaults from the .condarc
conda config --remove channels 'defaults'
You should use the CodeArtifact login command in SageMaker Studio to fetch credentials for use with pip:
# PyPIconfig.py
# Configure common package managers to use CodeArtifact
aws codeartifact login --tool pip --domain my-org --domain-owner <000000000000> --repository my-shared-python-repository --endpoint-url https://vpce-xxxxx.api.codeartifact.us-east-1.vpce.amazonaws.com
CodeArtifact needs authorization tokens. You can add a cron job into the image to run the above command periodically. Alternatively, you can execute it manually when the notebooks get started. To make it simple for your users, you can add the preceding command to a shell script (such as PyPIConfig.sh) and copy the file into to the image to be loaded in SageMaker Studio. In your Dockerfile, add the following command:
# Dockerfile
COPY PyPIconfig.sh /home/PyPIconfig.sh
For ease of use, the PyPIconfig.sh is available in /home on SageMaker Studio. You can easily run it to configure your pip client in SageMaker Studio and fetch an authorization token from CodeArtifact using your AWS credentials.
Now, you can build and push your image into Amazon Elastic Container Repository (Amazon ECR). Finally, attach the image to multiple users (by attaching to a domain) or a single user (by attaching to the user’s profile) in SageMaker Studio. The following screenshot shows the configuration on the SageMaker Studio control panel.

For more information about building a custom image and attaching it to SageMaker Studio, see Bring your own custom SageMaker image tutorial.
Installing the packages
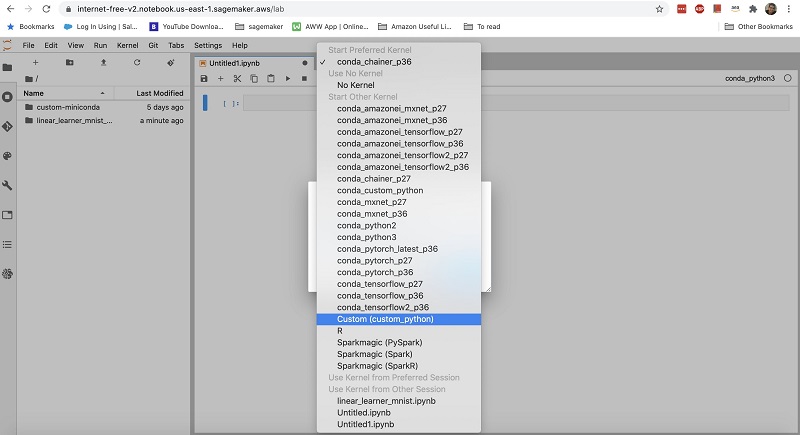
In Amazon SageMaker notebook instances, as soon as you start the Jupyter notebook, you see a new kernel in Jupyter in the drop-down list of kernels (see the following screenshot). This environment is isolated from other default Conda environments.
In your notebook, when you use pip install <package name>, the Python package manager client connects to your custom repository instead of the public repositories. Also, if you use conda install <package name>, the notebook instance uses the packages in your Amazon S3 channels to install it. See the following screenshot of this code.

In SageMaker Studio, the custom images appear in the image selector dialog box of the SageMaker Studio Launcher. As soon as you select your own custom image, the kernel you installed in the image appears in the kernel selector dialog box. See the following screenshot.
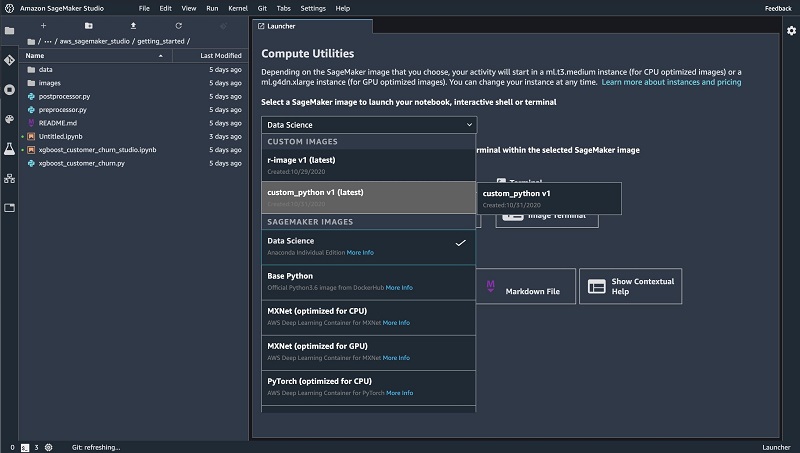
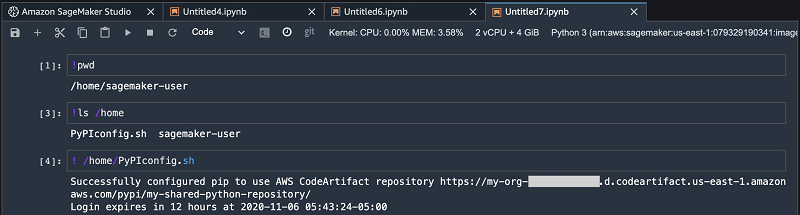
As mentioned before, CodeArtifact authorization tokens are valid for a default period of 12 hours. If you’re using CodeArtifact, you can open a terminal or notebook in SageMaker Studio and run the PyPIconfig.sh file to configure your client or refresh your expired token:
# Configure PyPI package managers to use CodeArtifact
/home/pyPIconfig.sh
The following screenshot shows your view in SageMaker Studio.
Conclusion
This post demonstrated how to build a private environment for Amazon SageMaker notebook instances and SageMaker Studio to have better control over the dependencies in your environments. To build the private environment, we used the lifecycle configuration feature in notebook instances. The sample lifecycle config scripts are available on the GitHub repo. To install custom packages in SageMaker Studio, we built a custom image and attached it to SageMaker Studio. For more information about this feature, see Bringing your own custom container image to Amazon SageMaker Studio notebooks. For this solution, we used CodeArtifact, which makes it easy to build a PyPI repository for approved Python packages across the organization. For more information, see Software Package Management with AWS CodeArtifact.
Give the CodeArtifact a try, and share your feedback and questions in the comments.
About the Author
 Saeed Aghabozorgi Ph.D. is senior ML Specialist in AWS, with a track record of developing enterprise level solutions that substantially increase customers’ ability to turn their data into actionable knowledge. He is also a researcher in the artificial intelligence and machine learning field.
Saeed Aghabozorgi Ph.D. is senior ML Specialist in AWS, with a track record of developing enterprise level solutions that substantially increase customers’ ability to turn their data into actionable knowledge. He is also a researcher in the artificial intelligence and machine learning field.
 Stefan Natu is a Sr. Machine Learning Specialist at AWS. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Stefan Natu is a Sr. Machine Learning Specialist at AWS. He is focused on helping financial services customers build end-to-end machine learning solutions on AWS. In his spare time, he enjoys reading machine learning blogs, playing the guitar, and exploring the food scene in New York City.
Read More
 delivers massive computing performance to handle demanding vision and perception workloads at the edge. Our collaboration with AWS on the AWS Panorama Appliance powered by the NVIDIA Jetson platform accelerates time to market for enterprises and developers by providing a fully managed service to deploy computer vision from cloud to edge in an easily extensible and programmable manner.”
delivers massive computing performance to handle demanding vision and perception workloads at the edge. Our collaboration with AWS on the AWS Panorama Appliance powered by the NVIDIA Jetson platform accelerates time to market for enterprises and developers by providing a fully managed service to deploy computer vision from cloud to edge in an easily extensible and programmable manner.” As a Product Manager on the AWS AI Devices team, Shardul Brahmbhatt currently focuses on AWS Panorama. He is deeply passionate about building products that drive adoption of AI at the Edge.
As a Product Manager on the AWS AI Devices team, Shardul Brahmbhatt currently focuses on AWS Panorama. He is deeply passionate about building products that drive adoption of AI at the Edge. Kamal Garg leads strategic hardware partnerships for AWS AI Devices. He is deeply passionate about incubating technology ecosystems that optimize the customer and developer experience . Over the last 5+ years, Kamal has developed strategic relationships with leading silicon and connected device manufacturers for next generation services like Alexa, A9 Visual Search, Prime Video, AWS IoT, Sagemaker Neo, Sagemaker Edge, and AWS Panorama.
Kamal Garg leads strategic hardware partnerships for AWS AI Devices. He is deeply passionate about incubating technology ecosystems that optimize the customer and developer experience . Over the last 5+ years, Kamal has developed strategic relationships with leading silicon and connected device manufacturers for next generation services like Alexa, A9 Visual Search, Prime Video, AWS IoT, Sagemaker Neo, Sagemaker Edge, and AWS Panorama.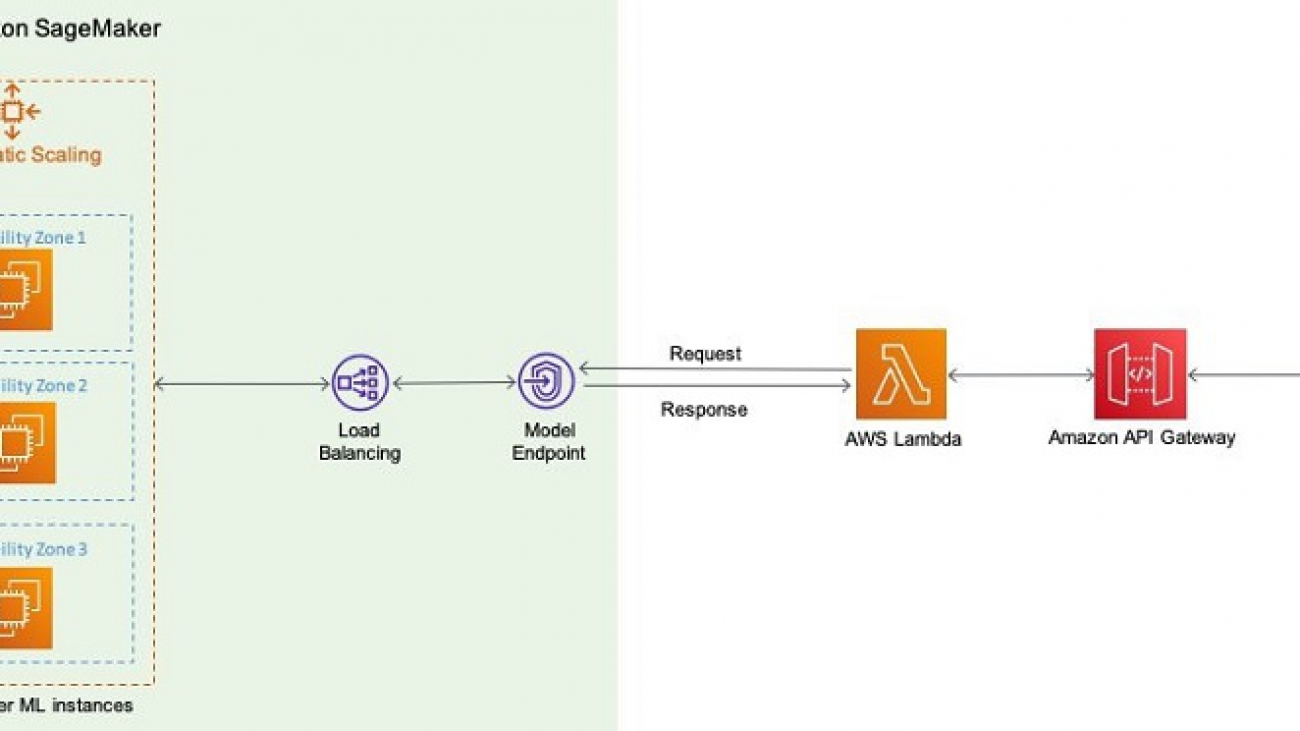

 Chaitanya Hazarey is a Machine Learning Solutions Architect with the Amazon SageMaker Product Management team. He focuses on helping customers design and deploy end-to-end ML pipelines in production on AWS. He has set up multiple such workflows around problems in the areas of NLP, Computer Vision, Recommender Systems, and AutoML Pipelines.
Chaitanya Hazarey is a Machine Learning Solutions Architect with the Amazon SageMaker Product Management team. He focuses on helping customers design and deploy end-to-end ML pipelines in production on AWS. He has set up multiple such workflows around problems in the areas of NLP, Computer Vision, Recommender Systems, and AutoML Pipelines. Pavan Kumar Sunder is a Senior R&D Engineer with Amazon Web Services. He provides technical guidance and helps customers accelerate their ability to innovate through showing the art of the possible on AWS. He has built multiple prototypes around AI/ML, IoT, and Robotics for our customers.
Pavan Kumar Sunder is a Senior R&D Engineer with Amazon Web Services. He provides technical guidance and helps customers accelerate their ability to innovate through showing the art of the possible on AWS. He has built multiple prototypes around AI/ML, IoT, and Robotics for our customers. Rama Thamman is a Software Development Manager with the AI Platforms team, leading the ML Migrations team.
Rama Thamman is a Software Development Manager with the AI Platforms team, leading the ML Migrations team.
 Dan McCorriston is a Senior Product Marketing Manager for AWS Machine Learning. He is passionate about technology, collaborating with developers, and creating new methods of expanding technology education. Out of the office he likes to hike, cook and spend time with his family.
Dan McCorriston is a Senior Product Marketing Manager for AWS Machine Learning. He is passionate about technology, collaborating with developers, and creating new methods of expanding technology education. Out of the office he likes to hike, cook and spend time with his family.












 ) icon to progressively run the cells in the example notebook.
) icon to progressively run the cells in the example notebook.










 James Sun is a Senior Solutions Architect with Amazon Web Services. James has over 15 years of experience in information technology. Prior to AWS, he held several senior technical positions at MapR, HP, NetApp, Yahoo, and EMC. He holds a PhD from Stanford University.
James Sun is a Senior Solutions Architect with Amazon Web Services. James has over 15 years of experience in information technology. Prior to AWS, he held several senior technical positions at MapR, HP, NetApp, Yahoo, and EMC. He holds a PhD from Stanford University. Graham Zulauf is a Senior Solutions Architect. Graham is focused on helping AWS’ strategic customers solve important problems at scale.
Graham Zulauf is a Senior Solutions Architect. Graham is focused on helping AWS’ strategic customers solve important problems at scale.