TorchAO brings high-performance low-bit linear and embedding operators to Arm CPUs. In this update, we’re excited to share three major improvements: dynamic kernel selection, integration with Arm’s KleidiAI library, and support for quantized tied embeddings — all designed to boost performance and extend coverage for low-bit inference in PyTorch, including ExecuTorch, PyTorch’s solution for efficient on-device execution.
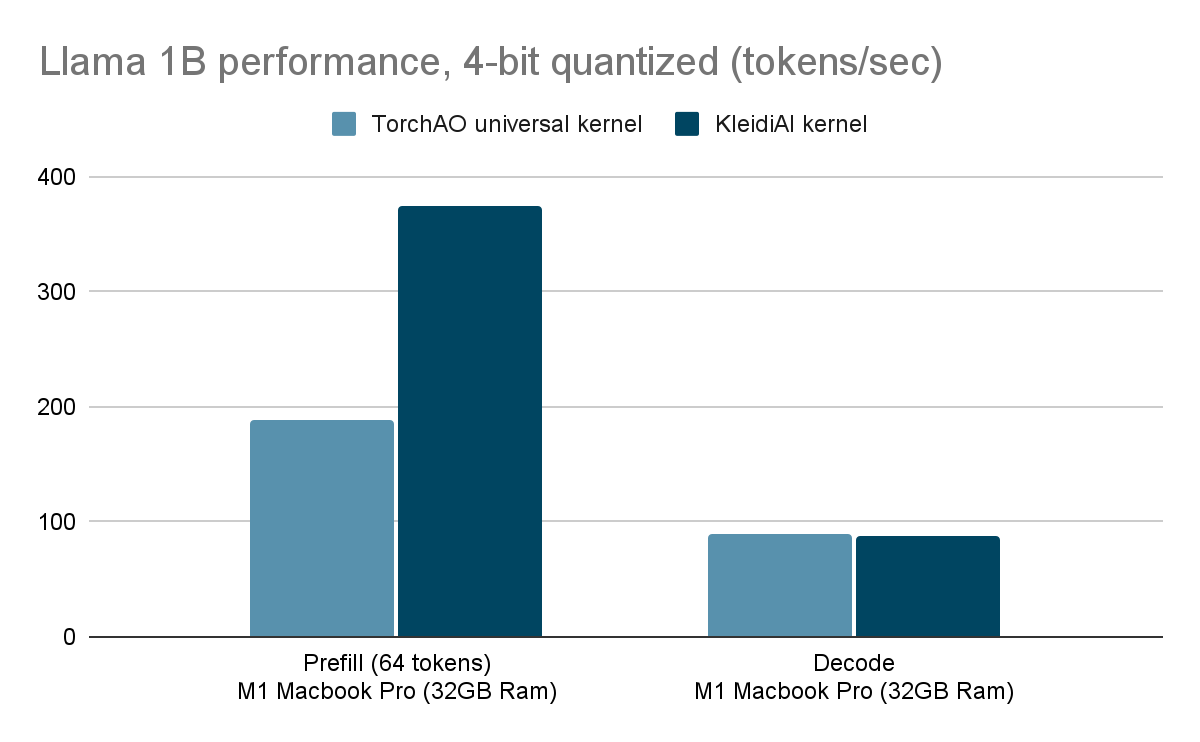
Indeed, with KleidiAI kernels, we see more than 2x improvement in prefill performance on 4-bit quantized Llama1B on M1 Mac (373 tokens/sec)!
Dynamic Kernel Selection
TorchAO low-bit operators now automatically select the best available kernel based on:
- The format of packed weights,
- CPU features such as
has_arm_neon_dotandhas_arm_i8mm, and - The shape of the activation tensor.
This dynamic dispatch allows us to tailor execution to the hardware and workload characteristics.
How it works?
Quantized model weights can be packed into a format optimized for a specific linear kernel. These packed weights include headers that describe their format. When a linear operator is called with packed weights, we first inspect the weight format and the current CPU capabilities. Based on this information, we determine a set of compatible kernels that can operate on the weights and cache function pointers to these kernels in a registration table.
For example, weights packed in format1might support both GEMV and GEMM kernels (e.g., gemv_kernel1 andgemm_kernel1), while weights in format2 may only support a GEMV kernel (e.g.,gemv_kernel2). In this case, the kernel registration table might look like this:

The next time we encounter packed weights withformat1, we can quickly retrieve the compatible kernels from the table and dispatch to the appropriate one based on the shape of the activations. If the activations form a vector, we would usegemv_kernel1; if they form a matrix, we would use gemm_kernel1.
Want to see what kernels are active? Set TORCH_CPP_LOG_LEVEL=INFOto get a detailed view.
KleidiAI Integration
KleidiAI is an open source library from Arm that provides highly optimized microkernels for Arm CPUs. We now integrate KleidiAI into our dynamic kernel selection system. Where supported (e.g., 8-bit dynamic activation with 4-bit weights), KleidiAI kernels are registered and used automatically. When coverage gaps arise (e.g., non-4-bit weights or tied embedding layers), we fall back to our in-house GEMV neondot kernels — no configuration required. This is all done using the packed weight formats discussed previously.
This hybrid approach gives us the best of both worlds: top-tier performance from KleidiAI, and broad operator support from torchao’s kernels.
With KleidiAI, we observe decoding performance comparable to the existing torchao kernels. However, since we don’t have in-house GEMM kernels, using KleidiAI delivers a significant boost in prefill performance—achieving over 2x speedup, with rates exceeding 373 tokens/sec on an M1 Mac using ExecuTorch!
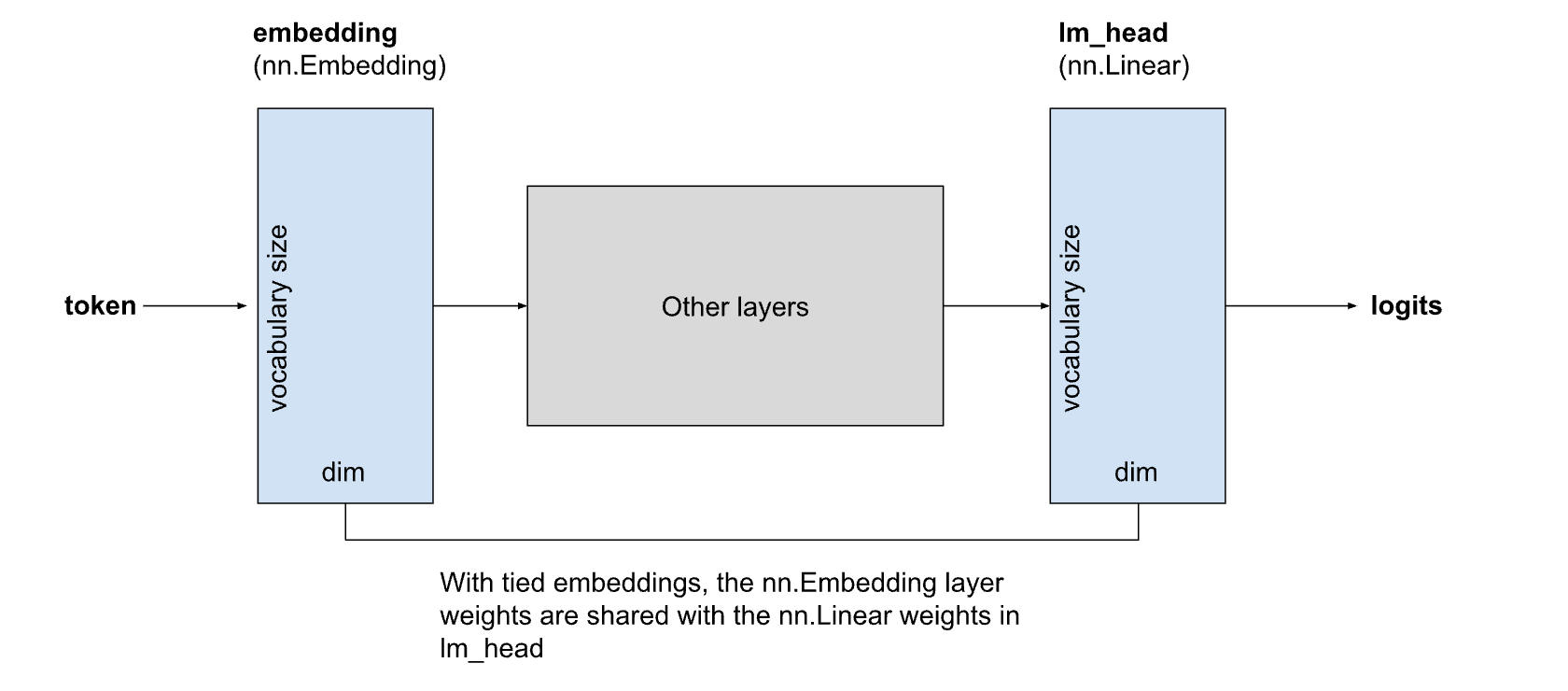
Quantized tied embedding and lm_head kernels
Tied embeddings are widely used in compact LLMs such as LLaMA 3.2 and Phi-4 Mini. In tied embeddings, the weights for the embedding layer are shared with the weights for the final linear layer that computes logits (lm_head):
Recent models often use vocabulary sizes exceeding 100,000 tokens, and in smaller models, the embedding and lm_head layers can account for a significant portion of the total model size.
However, on mobile devices, these weights are sometimes duplicated anyway. This is because efficient linear kernels and embedding kernels require the weights to be packed in different formats, making weight sharing impractical without sacrificing performance.
To solve this, we developed efficient quantized kernels for both embedding and linear operations that use a unified weight format. We expose this through the new SharedEmbeddingQuantizer, which allows the same quantized weights to be reused for both the input embedding and output lm_head. This reduces model size without compromising performance. The quantizer supports a wide range of configurations, including:
- 8-bit dynamic activations
- x-bit weights, where x ranges from 1 to 8
Try it out and contribute!
All these enhancements are available today via torchao’s quantization APIs — and they’re already integrated into ExecuTorch for efficient deployment of quantized models to mobile and edge devices.
We’d love for you to try it out, share feedback, and contribute!
And if you’re interested in low-bit quantization and mobile deployment, join the ExecuTorch community on discord and github.