ICLR (International Conference on Learning Representations) is recognized as one of the top conferences in the field of deep learning. Many influential papers on artificial intelligence, statistics, and data science—as well as important application fields such as machine vision, speech recognition, and text understanding—have been published and presented at this conference. The following selection of papers accepted at ICLR 2022 showcases the latest research from Microsoft and its collaborators on vision pre-training, periodic time series forecasting, differential privacy, code completion, table pre-training, and online reinforcement learning.
As research into deep learning continues to grow and change, Microsoft researchers and collaborators are broadening their approach to the field. As several papers highlighted in this post demonstrate, research teams continue to refine their thinking about how various machine learning techniques can best be implemented for real-world applications—whether for specialized applications in industry or a more generalized approach to improving decision-making in models overall. They are also gaining a deeper understanding of how different modalities, like computer vision, can extend applications of machine learning beyond language.
In parallel with exploring real-world applications and multimodality, researchers are looking to the future of machine learning techniques, further exploring uncharted areas in deep online and offline reinforcement learning. In subfields such as the latter, the fundamentals of how models learn from and interact with data are evolving—and so are the ways that researchers think about optimizing those processes and reworking them for situations where data is scarce or unavailable in real-world settings.
This post is a sampling of the work that researchers at Microsoft Research Asia and their collaborators presented at ICLR 2022, which reflects the broad scope of the company’s machine learning research. You can learn more about the work accepted at this year’s event on the “Microsoft at ICLR 2022” event page. On the Microsoft Research Blog, you can dive deeper into two papers accepted at the conference—one on MoLeR, a model that represents molecules as graphs to improve drug discovery, and the other on Path Predictive Elimination (PPE), a reinforcement learning method that is robust enough to remove noise from continuously changing environments.
DEPTS: Deep expansion learning for periodic time series forecasting
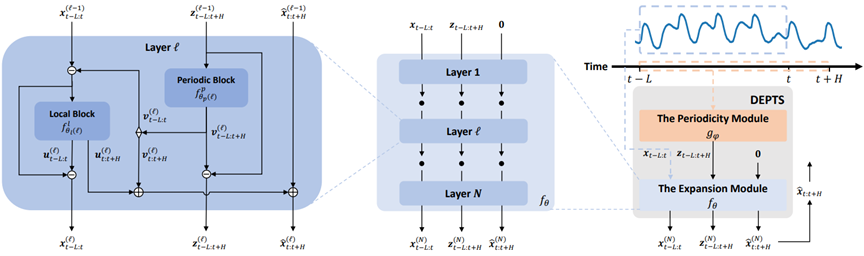
People and organizations involved: Shun Zheng, Xiaohan Yi, Wei Cao, Jian Bian, and Tie-Yan Liu from Microsoft Research Asia; Wei Fan and Yanjie Fu from the University of Central Florida.
According to the paper: Periodic time series (PTS, or time series with apparent periodic oscillations) is widespread across industries such as transportation, electric power generation and transmission, sustainability, and others. PTS forecasting plays a crucial role in these industries because it can help businesses with many critical tasks, including early warning, pre-planning, and resource scheduling. However, PTS forecasting performance can be affected by dependencies on its inherent periodic nature and the complexity of individual periods.
This paper introduces DEPTS, a deep expansion learning framework for PTS forecasting. DEPTS begins with a novel decoupled formulation by introducing the periodic state as a hidden variable, which allows the researchers to create custom modules to tackle the two challenges mentioned above. To address the first challenge, the researchers develop an expansion module on top of residual learning to perform a layer-by-layer expansion of those complicated dependencies. To address the second, they introduce a periodicity module with a parameterized periodic function that has the capacity to capture diversified periods.
The researchers conduct experiments on both synthetic and real-world data that show DEPTS is effective at PTS forecasting and significantly reduces errors compared to baseline—an improvement of up to 20 percent for some cases.
Towards deployment-efficient reinforcement learning: Lower bound and optimality
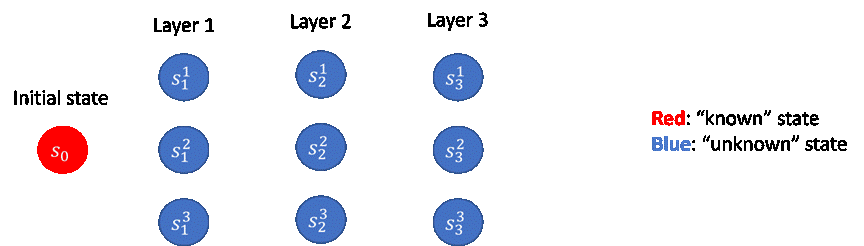
People and organizations involved: Li Zhao, Tao Qin, and Tie-Yan Liu from Microsoft Research Asia; Jiawei Huang, Jinglin Chen, and Nan Jiang from the University of Illinois at Urbana-Champaign.
According to the paper: Traditional online reinforcement learning (RL) can be abstracted as the loop of two elements: learning a policy from collected data and deploying the policy to collect new data by interacting with environments. The overall objective of RL is to finish the exploration of the entire environment and obtain a near-optimal policy.
However, in many real-world applications, policy deployment can be quite costly while data collection with a fixed policy is relatively convenient. For example, in recommendation systems, the policy is the recommendation strategy, and a good policy can accurately make suggestions to users based on their preferences. To guarantee the service quality, before launching a new policy, companies usually need to conduct multiple internal tests for evaluation, which require a lot of time (up to several months). Due to large customer bases, however, companies can gather thousands or millions of pieces of feedback for further policy learning in a short time once a system is deployed. In those applications, organizations prefer RL algorithms that can learn good policy after only a few switches or deployments. Yet, a gap still remains between existing algorithms and the practical scenarios above (please refer to the paper for more discussion).
To close the gap, the researchers propose a new setting called Deployment-Efficient Reinforcement Learning (DE-RL)—an abstracted model for applications that value deployment efficiency. A new idea called deployment complexity, an analogue of sample complexity, provides a way to measure the deployment efficiency of an algorithm. Deployment complexity is the number of policy deployments required before the algorithm returns a near-optimal policy.
Under this framework, researchers study linear Markov decision processes (MDPs) as a concrete example and conduct theoretical analysis to answer two important questions. First, what is the best deployment complexity we can achieve (lower bound)? Second, how can we design algorithms to achieve the best deployment complexity (optimality)? Additionally, because most of the previous related literature just studied algorithms constrained to deploy only deterministic policy, these researchers separately consider two cases with and without such constraints. They show that removing such constraints can significantly improve deployment efficiency.
For the first question above, researchers contribute the construction of hard instances and establish information theoretical lower bounds for two cases, which are dH and H, respectively. For the second question, researchers propose algorithms to achieve those lower bounds with a layer-by-layer exploration strategy (as shown in Figure 2), where the researchers contribute a new algorithm framework based on a novel covariance matrix estimation method and several innovations on a technical level. Finally, the researchers discuss extended settings based on the formulation of DE-RL, which may be an interesting subject for future investigation.
Gradient information matters in policy optimization by back-propagating through model

People and organizations involved: Yue Wang, Tie-Yan Liu from Microsoft Research Asia; Chongchong Li, Yuting Liu from Beijing Jiaotong University; Wei Chen from the Institute of Computing Technology, Chinese Academy of Sciences, Zhi-Ming Ma from the Academy of Mathematics and Systems Science, Chinese Academy of Sciences
According to the paper: Model-based reinforcement learning provides an efficient mechanism to find the optimal policy by interacting with the learned environment. In this paper, researchers investigate a mismatch in model learning and model using. Specifically, to get the policy update direction, an effective way is to leverage the model’s differentiability by using the model gradient. However, most of the commonly used methods just treat the model learning task as a supervised learning task and minimize its prediction error while not considering the gradient error. In other words, the algorithm requires an accurate model gradient, but we only learn to decrease the prediction error, which results in an objective mismatch.
This paper first theoretically justifies that the model gradient error matters in the policy optimization phase. Specifically, the bias of the estimated policy gradient is not only introduced by the prediction error of the learned model but also introduced by the gradient error of the learned model. These errors will eventually influence the convergence rate of the policy optimization process.
Next, the paper proposes a two-model-based learning method to control both the prediction and the gradient error. The paper separates the different roles of these two models at the model learning phase and coordinates them at the policy optimization phase. By designing a practical way to compute the gradient error, the paper can use it to guide the gradient model learning. By leveraging both the prediction and gradient models, we can first roll out the trajectory and then compute the model gradient to get the policy gradient. The proposed algorithm is called directional derivative projection policy optimization (DDPPO). Finally, several experiments in benchmark continuous control tasks demonstrate that the proposed algorithm has better sample efficiency.
Variational oracle guiding for reinforcement learning
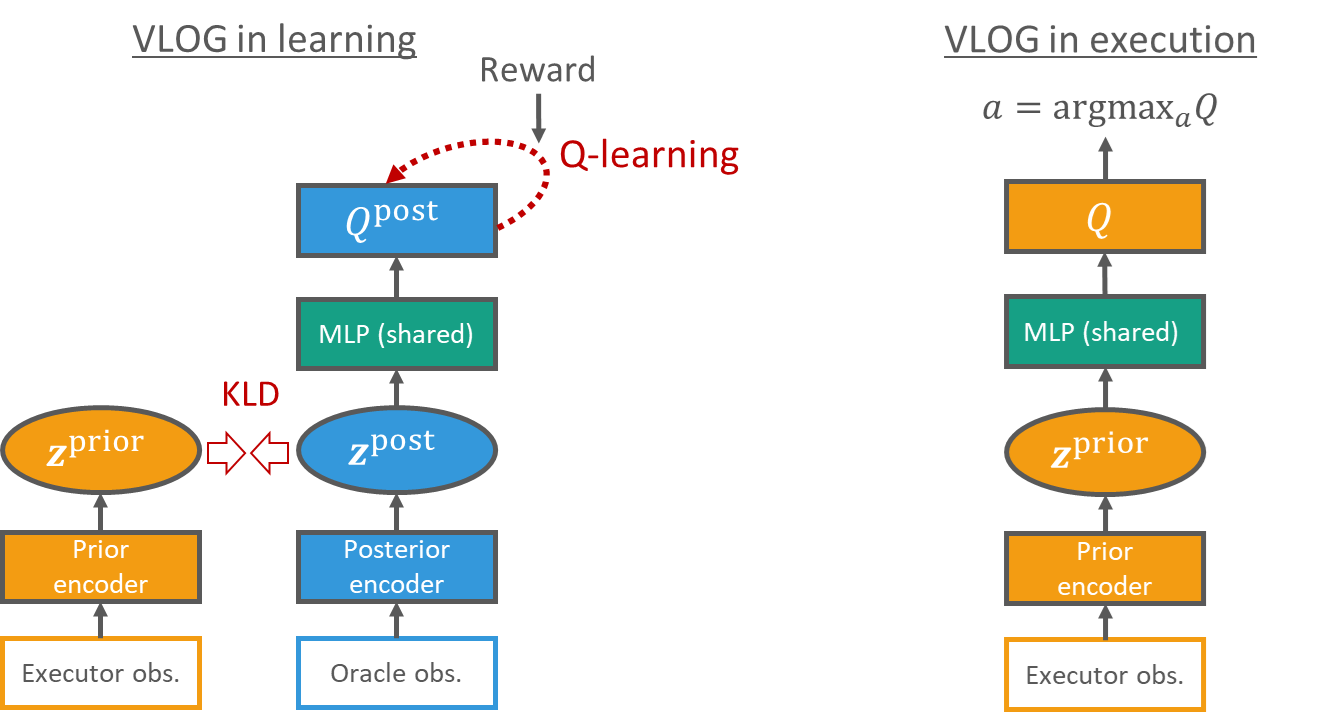
People and organizations involved: Dongqi Han, Xufang Luo, Yuqing Yang and Dongsheng Li from Microsoft Research Asia; Tadashi Kozuno from the University of Alberta; Zhaoyun Chen from the Institute of Artificial Intelligence, Hefei Comprehensive National Science Center; Kenji Doya from the Okinawa Institute of Science and Technology.
According to the paper: Despite recent successes of deep reinforcement learning (DRL) in various decision-making problems, an important but underexplored aspect is how to leverage oracle observation (the information that is invisible during online decision making but is available during offline training) to facilitate learning. For example, human experts will look at the replay after a poker game, so they can check the opponents’ hands and use the visible information (executor observation to improve their gameplay strategy). Such problems are known as oracle guiding.
In this work, the researchers study the oracle guiding problems based on Bayesian theory and derive an objective to leverage oracle observation in RL using variational methods. The key contribution is to propose a general learning framework referred to as variational latent oracle guiding (VLOG) for DRL. VLOG is featured with preferable properties such as its robust and promising performance and its versatility to incorporate with any value-based DRL algorithm.
The paper empirically demonstrates the effectiveness of VLOG in online and offline RL domains with tasks ranging from video games to mahjong, a challenging tile-based game. Furthermore, the authors publish the mahjong environment and an offline RL dataset as a benchmarking task to facilitate future research on oracle guiding, game AI, and related topics.
The post ICLR 2022 highlights from Microsoft Research Asia: Expanding the horizon of machine learning techniques and applications appeared first on Microsoft Research.