As AI becomes more deeply integrated into every aspect of our lives, it is essential that AI systems perform appropriately for their intended use. We know AI models can never be perfect, so how do we decide when AI performance is ‘good enough’ for use in a real life application? Is level of accuracy a sufficient gauge? What else matters? These are questions Microsoft Research tackles every day as part of our mission to follow a responsible, human-centered approach to building and deploying future-looking AI systems.
To answer the question, “what is good enough?”, it becomes necessary to distinguish between an AI model and an AI system as the unit of performance assessment. An AI model typically involves some input data, a pattern-matching algorithm, and an output classification. For example, a radiology scan of the patient’s chest might be shown to an AI model to predict whether a patient has COVID-19. An AI system, by contrast, would evaluate a broader range of information about the patient, beyond the COVID-19 prediction, to inform a clinical decision and treatment plan.
Research has shown that human-AI collaboration can increase the accuracy of AI models alone (reference). In this blog, we share key learnings from the recently retired Project Talia, the prior collaboration between Microsoft Research and SilverCloud Health to understand how thinking about the AI system as a whole—beyond the AI model—can help to more precisely define and enumerate ‘good enough’ for real-life application.
In Project Talia, we developed two AI models to predict treatment outcomes for patients receiving human-supported, internet-delivered cognitive behavioral treatment (iCBT) for symptoms of depression and anxiety. These AI models have the potential to assist the work practices of iCBT coaches. These iCBT coaches are practicing behavioral health professionals specifically trained to guide patients on the use of the treatment platform, recommend specific treatments, and help the patient work through identified difficulties.
Project Talia offers an illustration of the distinction between the AI model produced during research and a resulting AI system that could potentially get implemented to support real-life patient treatment. In this scenario, we demonstrate every system element that must be considered to ensure effective system outcomes, not just AI model outcomes.
Project Talia: Improving Mental Health Outcomes
SilverCloud Health (acquired by Amwell in 2021) is an evidence-based, digital, on-demand mental health platform that delivers iCBT-based programs to patients in combination with limited but regular contact from the iCBT coach. The platform offers more than thirty iCBT programs, predominantly for treating mild-to-moderate symptoms of depression, anxiety, and stress.
Patients work through the program(s) independently and with regular assistance from the iCBT coach, who provides guidance and encouragement through weekly reviews and feedback on the treatment journey.
Previous research (reference) has shown that involving a human coach within iCBT leads to more effective treatment outcomes for patients than unsupported interventions. Aiming to maximize the effects and outcomes of human support in this format, AI models were developed to dynamically predict the likelihood of a patient achieving a reliable improvement[1] in their depression and anxiety symptoms by the end of the treatment program (typically 8 to 14 weeks in length).
Existing literature on feedback-informed therapy (reference) and Project Talia research (reference) suggest that having access to these predictions could provide reassurance for those patients ‘on track’ toward achieving a positive outcome from treatment, or prompt iCBT coaches to make appropriate adjustments therein to better meet those patients’ needs.
AI Model vs. AI System
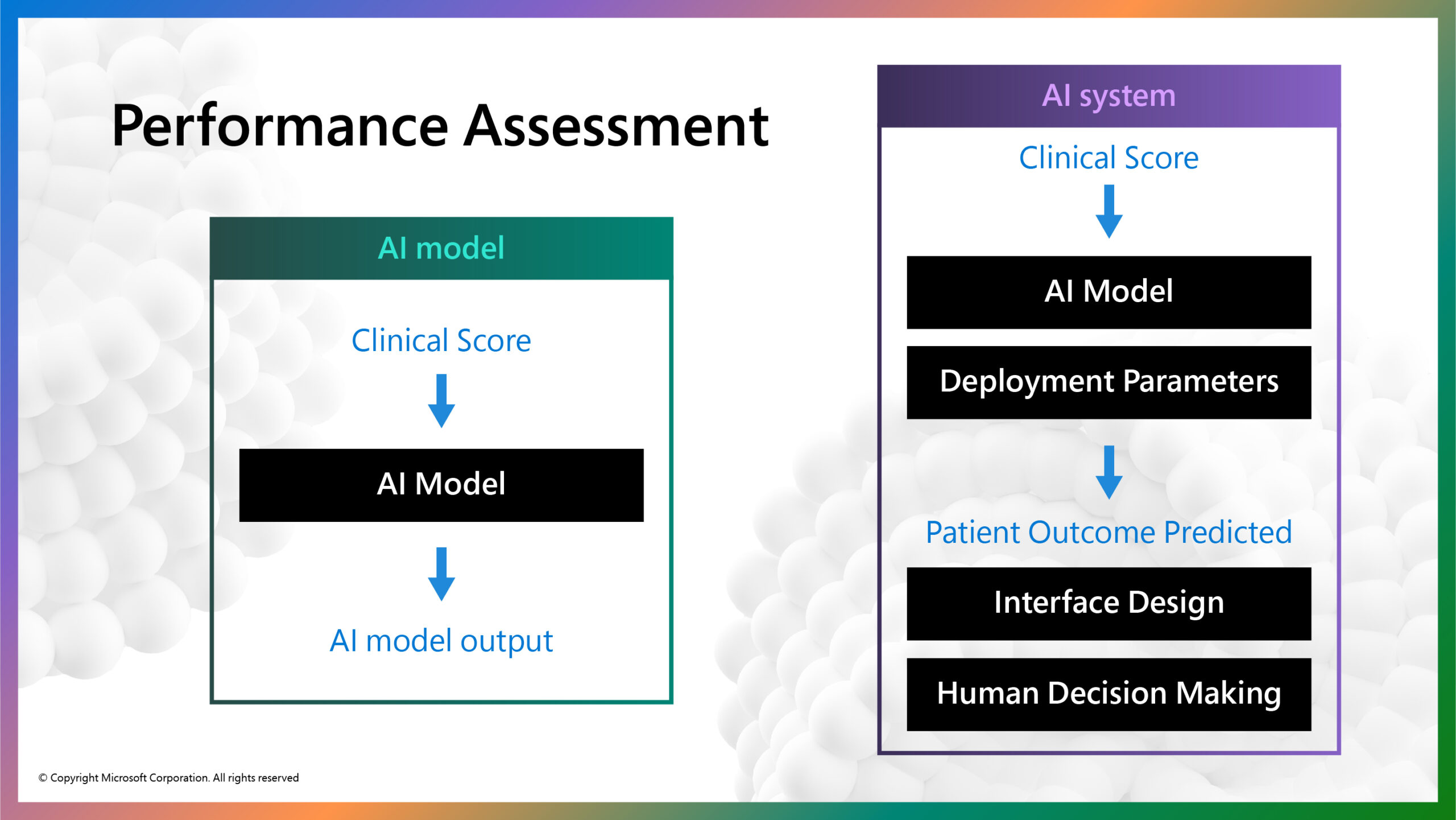
The figure above illustrates the distinction between the AI model and AI system in this example (figure 1). The AI model takes in a clinical score calculated by a patient’s responses to standardized clinical questionnaires that assess symptoms of depression and anxiety at each treatment session. After three treatment sessions, the AI model predicts whether or not the patient will achieve a clinically significant reduction in mental health symptoms at completion of the treatment program. The AI model itself is trained on fully anonymized clinical scores of nearly 50,000 previous SilverCloud Health patients and achieved an acceptable accuracy of 87% (reference).
The outcome prediction could then be embedded into the clinical management interface that guides iCBT coaches in their efforts to make more informed decisions about that patient’s treatment journey (i.e., increase level and frequency of support from the coach).
When AI models are introduced into human contexts such as this, they rarely work in isolation. In this case, the clinical score is entered into a model with parameters tuned to a particular healthcare context. This example illustrates how AI model performance metrics are not sufficient to determine whether an AI system is ‘good enough’ for real-life application. We must examine challenges that arise throughout every element of the AI system.
Following are two specific examples of how AI system performance can be altered while retaining the same model: contextual model parameters and user interface and workflow integration.
Contextual Model Parameters: Which Error Type is Most Costly
Examining overall performance metrics exclusively can limit visibility into the different types of errors an AI model can make, which can have (potentially negative) implications on the AI system as a whole. For example, an AI model’s false positive and false negative errors can impact the AI system differently. A false positive error could mean a patient who needed extra help might not receive it; a false negative would mean a patient may receive unnecessary care. In this case, false positive errors would have a much bigger impact on a patient than false negative errors. But false negative errors can also be problematic when they cause unnecessary resource allocation.
Contextual model parameters can be tuned to change the balance between error types while maintaining the overall accuracy of the model. The clinical team could define these contextual model parameters to minimize false positive errors that could be more detrimental to patients, by specifying the model to produce only 5% false positives errors. Choosing this parameter could come, however, at the expense of a higher false negative rate, which would require monitoring how AI model performance might then impact service costs or staff burn-out.
This example illustrates the challenging decisions domain experts, who may know little about the details of AI, must make and the implications these decisions can have on AI system performance. In this example, we provided a prototype visualization tool to help the clinical team in their understanding of the implications of their choices across different patient groups.
We are moving into a world in which domain experts and business decision makers, who embed AI into their work practices, will bear increasing responsibility in assessing and debugging AI systems to improve quality, functionality, and relevance to their work.
User Interface and Workflow Integration
AI model predictions need to be contextualized for a given workflow. Research on iCBT coaches has shown that listing the predictions for all patients of a coach in a single screen outside the normal patient-centered workflow can be demotivating (reference). If a coach saw that the majority of their patients were predicted to not improve, or if their patients’ outcomes were predicted to be worse for than those of their colleagues, this could lead coaches to question their own competence or invite competitive thoughts about their colleagues’ performances—both unhelpful in this context.
Displaying the AI model prediction inside the individual patient’s profile, as in the illustration below (figure 2), provides a useful indicator of how well the person is doing and therefore can guide clinical practice. It also deliberately encourages the use of the AI model prediction within the context of other relevant clinical information.
Situating the AI output with other patient information can nurture a more balanced relationship between AI-generated insight and coaches’ own patient assessments, which can counterbalance effects of over-reliance and over-trust in potentially fallible AI predictions (also referred to as automation bias).
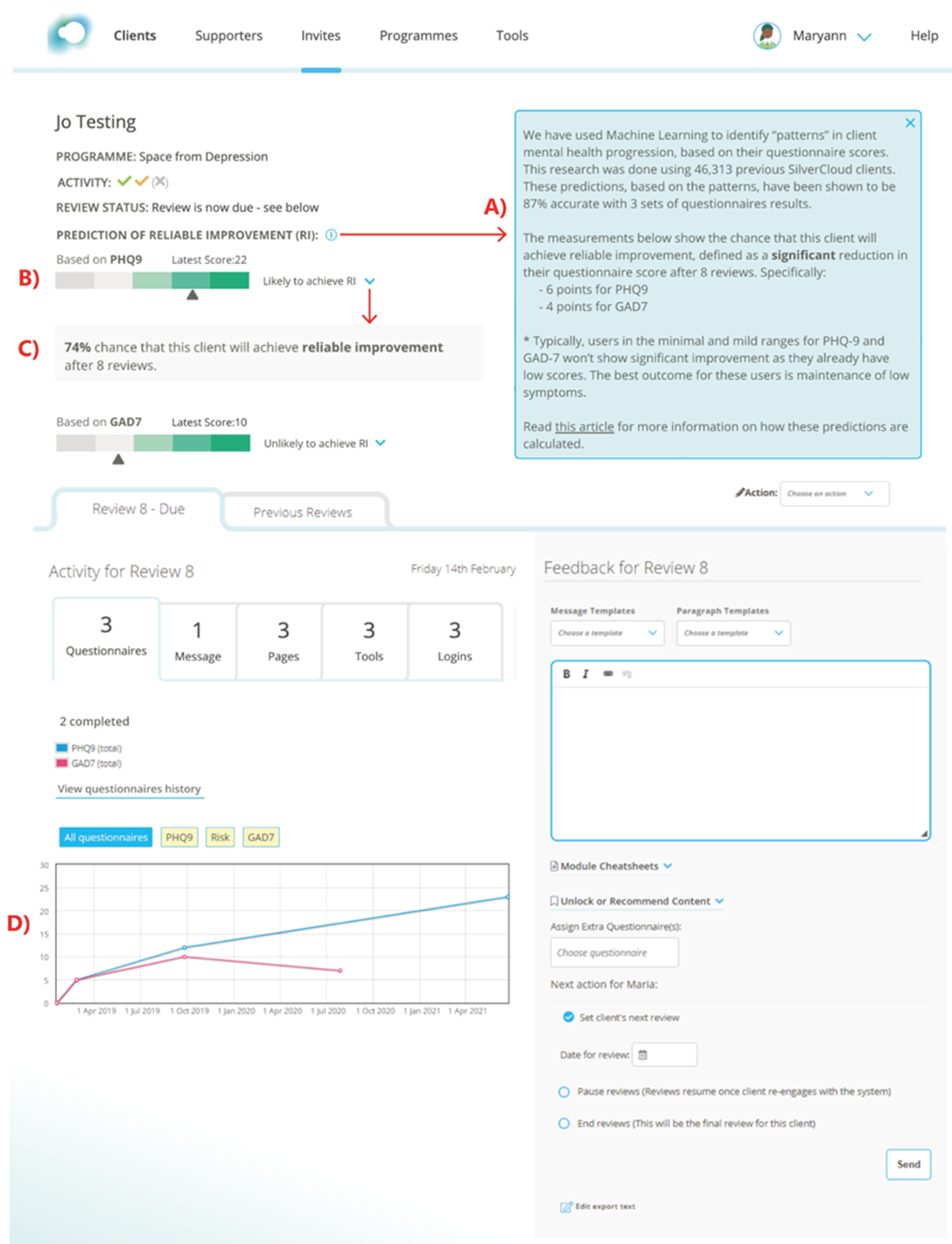
This example illustrates the importance of user interface design and workflow integration in how well AI model predictions are understood and can contribute to the success or failure of an AI system as a whole. Domain experts, user research, and service designers start to play a far more important role in the development of AI systems than the typical focus on data scientists.
Final Thoughts
Aggregate performance metrics, such as accuracy, area-under-the-curve (AUC) scores, or mean square error, are easy to calculate on an AI model, but they indicate little about the utility or function of the entire AI system in practice. So, how do we decide when AI system performance is ‘good enough’ for use in real-life application? It is clear that high levels of AI model performance alone are not sufficient—we must consider every element of the AI system.
Contextual model parameters and interface and workflow design present just two examples of how preparing domain experts with expectations, skills, and tools are necessary for optimal benefit from the incorporation of AI systems into human contexts.
[1] Defined as an improvement of 6 or more points on the PHQ-9 depression scale, or 4 or more points on the Gad-7 anxiety scale.
The post AI Models vs. AI Systems: Understanding Units of Performance Assessment appeared first on Microsoft Research.