By MSR Editor
Compilation is an important process in program development, in which a program called a compiler translates source code written in a programming language into machine code executable on computer hardware. As AI technology and large-scale AI models become increasingly prevalent across the digital world, their unique characteristics are posing new challenges for compilers.
As AI models have evolved from early versions like recurrent neural networks (RNN) and convolutional neural networks (CNN) to more recent iterations like Transformer, their fundamental architecture is also constantly evolving. Meanwhile, the underlying hardware accelerators, such as graphics processing units (GPUs) and neural processing units (NPUs), are iterating rapidly as well, with some designs disrupting previous architectures. Therefore, an AI compiler plays a critical role in helping new AI models run efficiently on new hardware.
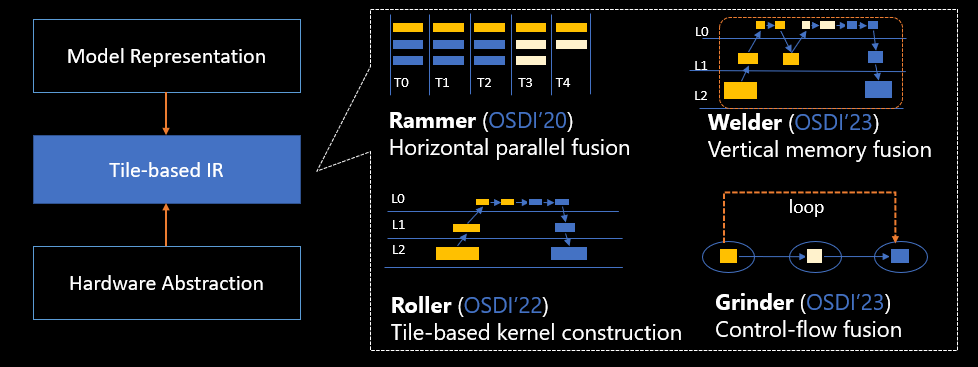
In response, researchers from Microsoft Research, in collaboration with academic colleagues, conducted a series of research and released the “heavy-metal quartet” of AI compilers: Rammer, Roller, Welder, and Grinder[1]. This quartet provides systematic and innovative solutions for current mainstream AI models and hardware compilation.
Microsoft Research Podcast

AI Frontiers: The future of causal reasoning with Emre Kiciman and Amit Sharma
Emre Kiciman and Amit Sharma discuss their paper “Causal Reasoning and Large Language Models: Opening a New Frontier for Causality” and how it examines the causal capabilities of large language models (LLMs) and their implications.
AI compilation “Rammer” improves hardware parallel utilization
Deep neural networks (DNNs) are widely adopted in image classification, natural language processing, and many other intelligence tasks. Because of their importance, many computing devices such as CPUs, GPUs, and specially designed DNN accelerators are being used to perform DNN computations. One key variable for DNN computation efficiency is scheduling, which determines the order in which computational tasks are performed on hardware. Conventional AI compilers typically treat DNN computation as a data flow graph where each node represents a DNN operator. These operators are implemented as opaque library functions and are scheduled to run on the accelerator separately. At the same time, this process also relies on another layer of schedulers, usually implemented in hardware, to take advantage of the parallelism available in operators. This two-level approach incurs significant scheduling overhead and often does not fully utilize hardware resources.
To address this issue, researchers proposed a new DNN compiler, Rammer, which can optimize the execution of DNN workloads on massive-parallel units of accelerators. Rammer imagines the scheduling space for AI compilation as a two-dimensional plane, where computational tasks are “bricks” that can be divided into different shapes and sizes. The purpose of scheduling in Rammer is to arrange these bricks tightly—as if building a wall—on the computational units of the two-dimensional plane. The arrangement should not leave any gaps, which would hurt hardware utilization and thus reduce execution speed. Rammer works like a compactor in this two-dimensional space: when a DNN program is translated into bricks, Rammer can place them on different computing units of the accelerator to compact them.
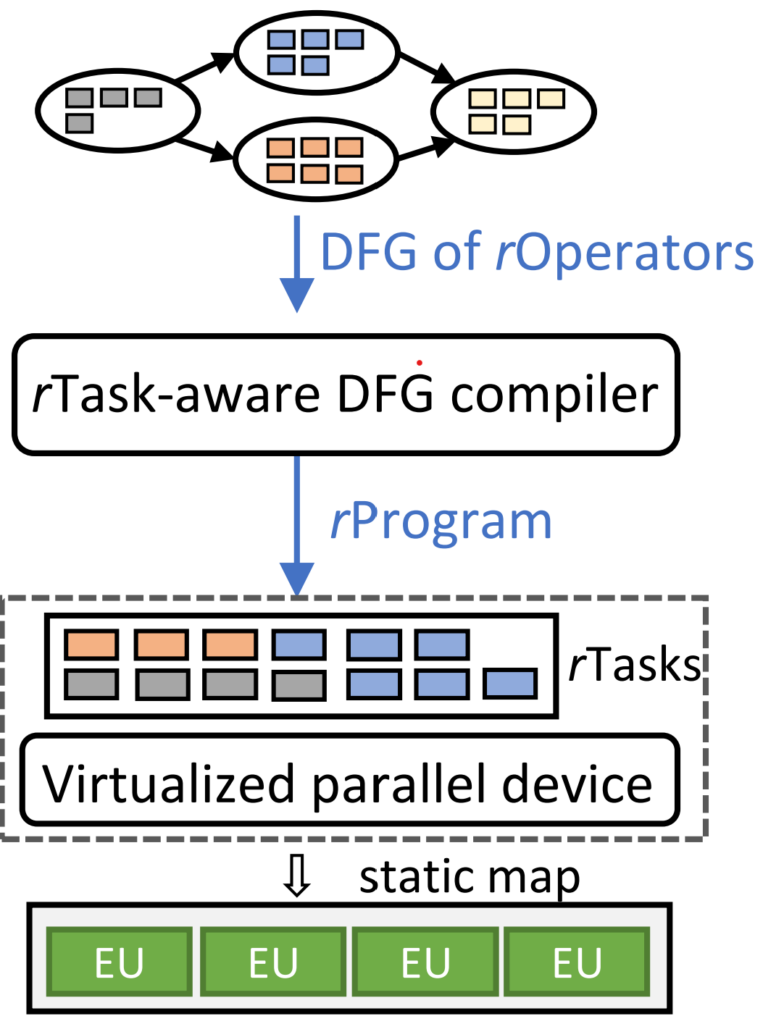
In other words, Rammer generates an efficient static spatiotemporal schedule for DNNs ahead of time (during compilation), minimizing runtime scheduling overhead. Meanwhile, through new hardware-independent abstractions for computing tasks and hardware accelerators, Rammer exposes a larger scheduling space and provides a novel way to implement cooperative intra- and inter-operator scheduling. This allows Rammer to find more efficient schedules, thereby greatly improving hardware utilization.
Researchers evaluated Rammer on multiple devices, including NVIDIA GPUs, AMD GPUs, and Graphcore intelligence processing units (IPUs). Experiments have shown that Rammer significantly outperforms state-of-the-art compilers, such as XLA and TVM, on NVIDIA and AMD GPUs, achieving a speedup of up to 20.1 times. And compared to TensorRT, NVIDIA’s proprietary DNN inference library, Rammer achieves a speedup of up to 3.1 times.
AI compilation “Roller” improves compilation efficiency
An accelerator is equipped with parallel computing units and multiple layers of memory hierarchy. The data needs to be passed upwards layer by layer from the bottom memory layer before computation. At each layer, the data is divided into smaller bricks. Eventually, these smaller bricks are handed over to the top-level processor for computation. The challenge lies in how to partition the data and fill the memory space with large bricks, so as to better utilize available memory and improve efficiency. The current approach involves using machine learning to identify better strategies for partitioning these bricks. However, this typically requires thousands of search steps, each of which is evaluated on the accelerator, in order to find a satisfactory solution. As a result, the process can take days or even weeks to compile a full AI model.
Given the computational logic and the specification of each memory layer, which present a holistic view on the software and hardware information, it is possible to formulate the best strategy for partitioning the bricks, as well as the best brick sizes. This enables faster compilation with good computation efficiency. And it is the key idea behind Roller. Like a road roller, the system lays down high-dimensional tensor data onto two-dimensional memory like tiling a floor, finding the optimal tile sizes given the memory characteristics. At the same time, it encapsulates the tensor shape that aligns with the hardware characteristics of the underlying accelerator, achieving efficient compilation by limiting the choices for shapes.
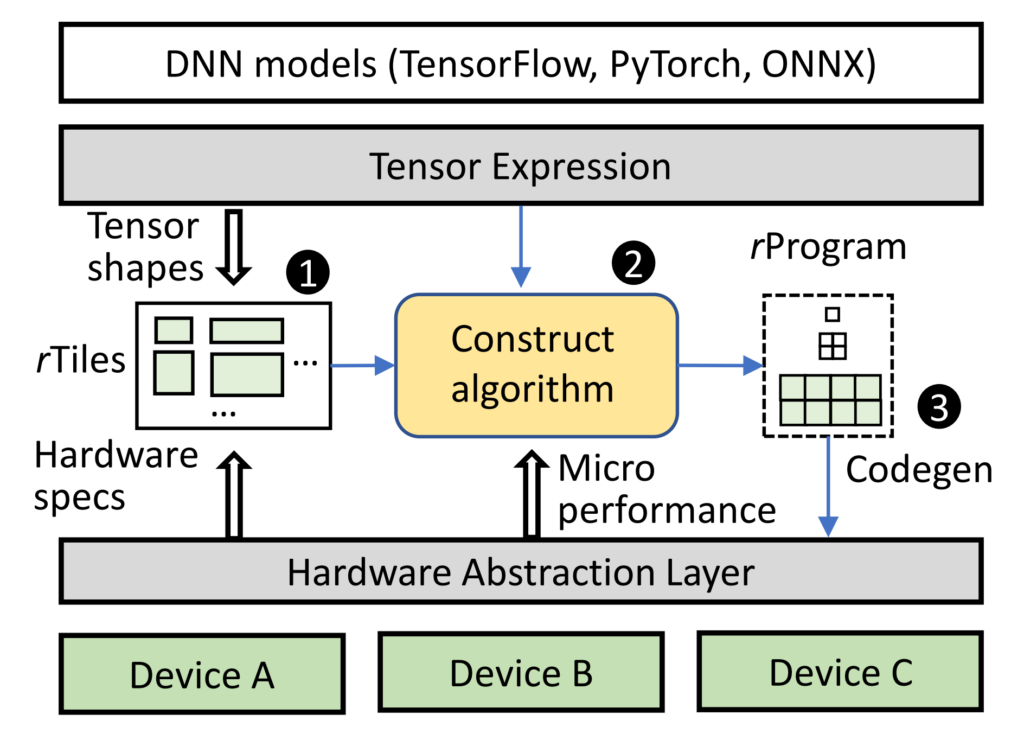
Evaluations on six mainstream DNN models and 119 popular DNN operators demonstrated that Roller can generate highly optimized kernels in seconds, especially for large and expensive custom operators. Roller achieves a three-orders-of-magnitude improvement in compilation time compared to existing compilers. The performance of the kernels generated by Roller is comparable to that of state-of-the-art tensor compilers, including DNN libraries, with some operators performing even better. Roller has also been used in customizing DNN kernels internally, which has demonstrated its real improvement in development agility.
AI compilation “Welder” optimizes memory access and improves computing efficiency
With the growing demand for processing higher fidelity data and the use of faster computing cores in newer hardware accelerators, modern DNN models are becoming increasingly memory intensive. A disparity between underutilized computing cores and saturated memory bandwidth has been observed in various popular DNN models.
For example, profiling on a state-of-the-art DNN benchmark shows that the memory bandwidth utilization can be as high as 96.7% while the average utilization of computing cores is only 51.6%. Even more seriously, the continuous evolution of hardware and DNN models continues to increase this gap. Modern AI models tend to process high-fidelity data, such as larger images, longer sentences, and higher-resolution graphics. Such data demands higher memory bandwidth during computation. Additionally, the introduction of more efficient specialized computing cores (such as NVIDIA Tensor Cores or AMD Matrix Cores) further increases memory pressure.
To address this issue, the researchers proposed the Welder deep learning compiler, which holistically optimizes the memory access efficiency of the end-to-end DNN model. Represented as a data flow graph, the end-to-end DNN computation involves multiple stages, where the input data is divided into blocks that flow through different operators. These blocks are transferred to processor cores for computation and then transferred back to memory. This results in significant overhead due to data movement across memory layers. Since it includes multiple stages, the entire process can be envisioned as a scenario where “workers” are moving bricks upwards layer by layer. The first worker takes the bricks up, processes them, and then puts them back in their original location. The second worker takes them up again, sculpts them, and then once again puts them back. The process continues with the third worker, the fourth worker, and so on, repeatedly moving the bricks. However, this leads to significant overhead. Would it be possible for the first worker to finish a part of the subtask and then directly hand it over to the next worker at the top level? These tasks can then be “welded” together to achieve a pipelined operation with higher efficiency. Welder plays the role of such a welding tool. By connecting (welding) different operators, data blocks are processed in the manner of an assembly line, greatly reducing memory access traffic at lower-level memory layers. With AI models imposing increasingly high requirements for memory efficiency in recent years, Welder helps to significantly improve computational efficiency.
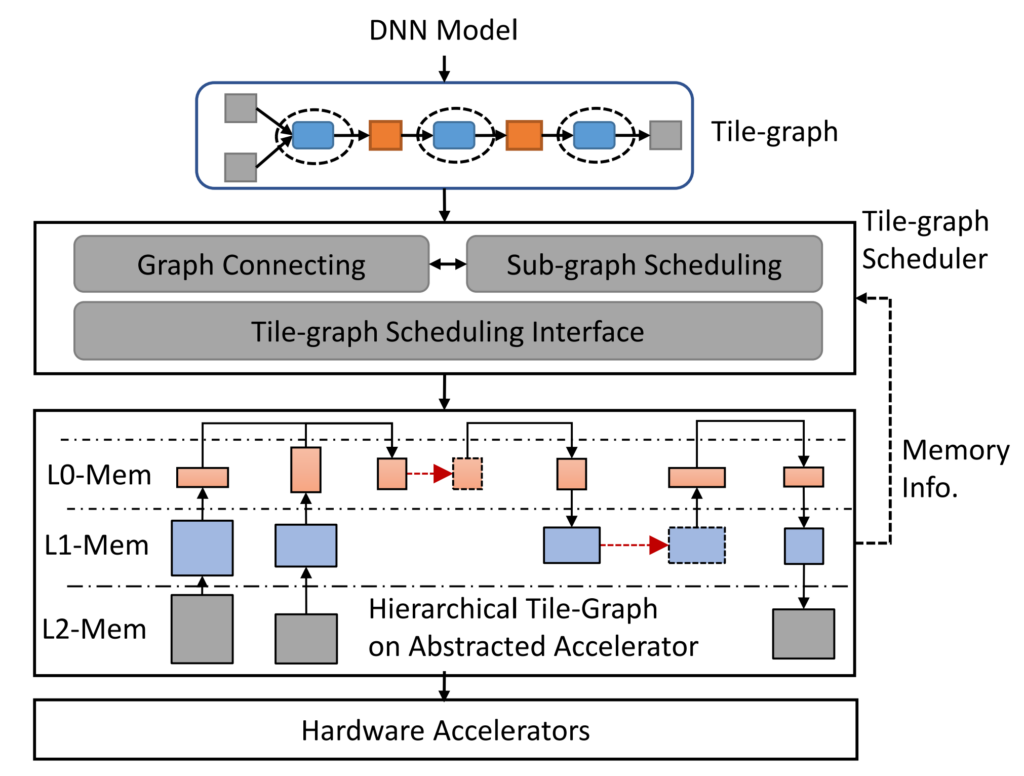
Evaluations on 10 mainstream DNN models, (including classic and the latest AI model structures for various tasks, such as vision, natural language processing, 3D graphics, etc.), demonstrated that Welder significantly exceeds the performance of existing mainstream frameworks and compilers on both NVIDIA and AMD GPUs. For example, it outperforms PyTorch, ONNXRuntime, and Ansor by up to 21.4 times, 8.7 times, and 2.8 times, respectively. Welder’s automatic optimization surpasses even TensorRT and Faster Transformer (a hand-crafted library), achieving speedups of up to 3.0 times and 1.7 times, respectively. Furthermore, when running these models on hardware with faster computing cores such as TensorCore, performance is improved even more, underscoring the significance of memory optimization for future AI accelerators.
AI compilation “Grinder” allows efficient control flow execution on accelerators
In AI computation, the movement of data blocks sometimes requires more complex control logic, i.e., control flow code. For example, a program could iteratively traverse each word in a sentence or dynamically determine which part of a program to execute based on input. Currently, most AI compilers focus on addressing data flow execution efficiency and do not provide efficient support for control flow. As a result, models with more complex control flow cannot effectively utilize accelerator performance. The researchers realized that control flow and data flow can be segmented and reorganized in order to execute more efficiently. Their solution is Grinder, which acts like a portable grinding and cutting machine. After cutting the data flow into parallel computing blocks of different sizes, it then integrates (grinds) control flow into data flow, so that control flow can also be executed efficiently on the accelerator.
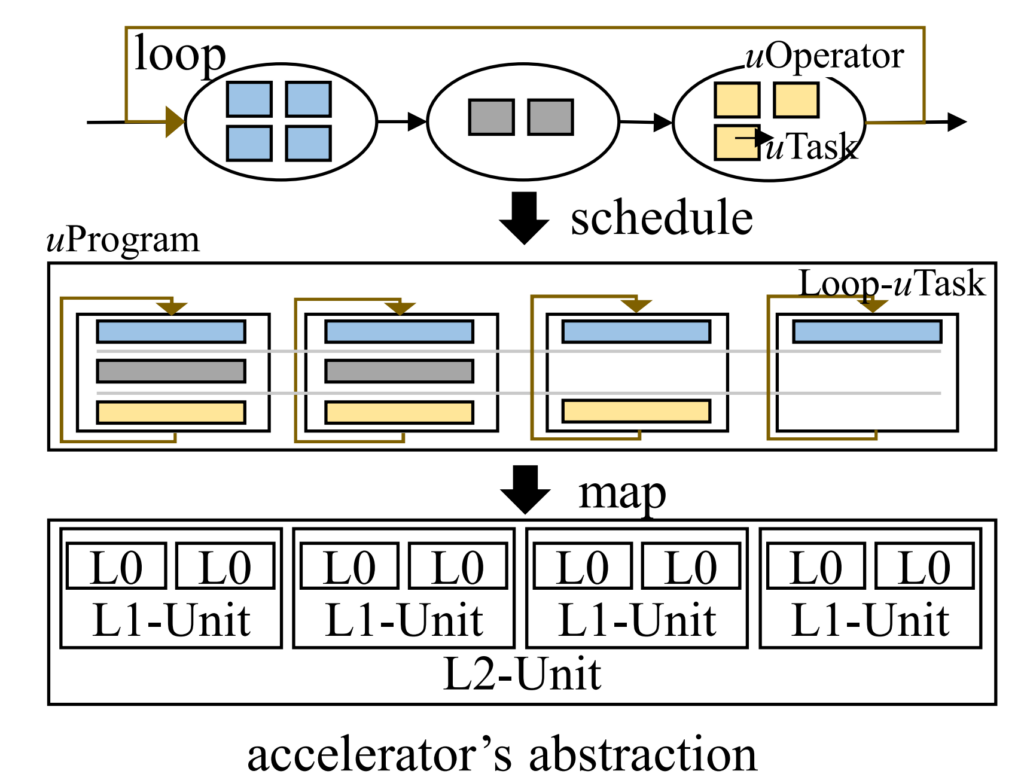
Grinder can jointly optimize the execution of control flow and data flow on hardware accelerators and unify the representation of AI models, including both control flow and data flow, through uTask, a new abstraction. This allows Grinder to expose the overall scheduling space for rescheduling control flow to lower levels of hardware parallelism. Grinder uses a heuristic strategy to find an effective scheduling scheme and can automatically move control flow into device kernels, thereby achieving optimizations across control flow boundaries. Experiments have shown that Grinder can achieve up to an 8.2x speedup on control flow-intensive DNN models, making it the fastest among DNN frameworks and compilers for control flow.
These four AI compilers, based on a common compiler abstraction and unified intermediate representation (IR), solve multiple fundamental problems in current AI compilers, including parallelism, compilation efficiency, memory, and control flow. Together they constitute a comprehensive set of solutions for compilation. and have played an important role in the customization and optimization of new AI models within Microsoft Research.
Jilong Xue, Principal Researcher at MSR Asia, summed up the project this way:
“On one hand, AI compilers must perform extreme optimizations like operator fusion and kernel specialization tailored for hardware resources. On the other hand, they must also provide systematic compilation support for new, large-scale hardware architectures, such as AI chips featuring on-chip network interconnection (NoC) or hybrid memory architectures, and even guiding hardware design using white-box compilation technologies. The AI compilers we developed have demonstrated a substantial improvement in AI compilation efficiency, thereby facilitating the training and deployment of AI models. At the same time, the evolution of large-scale models also presents opportunities for the next generation AI compiler. In the future, these large-scale models themselves may inherently assist in achieving optimization and compilation.”
The following researchers have contributed to this project:
(In alphabetical order) Wei Cui, Yuxiao Guo, Wenxiang Hu, Lingxiao Ma, Youshan Miao, Ziming Miao, Yuqing Xia, Jilong Xue, Fan Yang, Mao Yang, Lidong Zhou
[1] Grinder is the research project name. However, this system is referred to as Cocktailer in the paper.
The post Building a “heavy metal quartet” of AI compilers appeared first on Microsoft Research.