Cloud Intelligence/AIOps blog series
In the first blog post in this series, Cloud Intelligence/AIOps – Infusing AI into Cloud Computing Systems, we presented a brief overview of Microsoft’s research on Cloud Intelligence/AIOps (AIOps), which innovates AI and machine learning (ML) technologies to help design, build, and operate complex cloud platforms and services effectively and efficiently at scale. As cloud computing platforms have continued to emerge as one of the most fundamental infrastructures of our world, both their scale and complexity have grown considerably. In our previous blog post, we discussed the three major pillars of AIOps research: AI for Systems, AI for Customers, and AI for DevOps, as well as the four major research areas that constitute the AIOps problem space: detection, diagnosis, prediction, and optimization. We also envisioned the AIOps research roadmap as building toward creating more autonomous, proactive, manageable, and comprehensive cloud platforms.
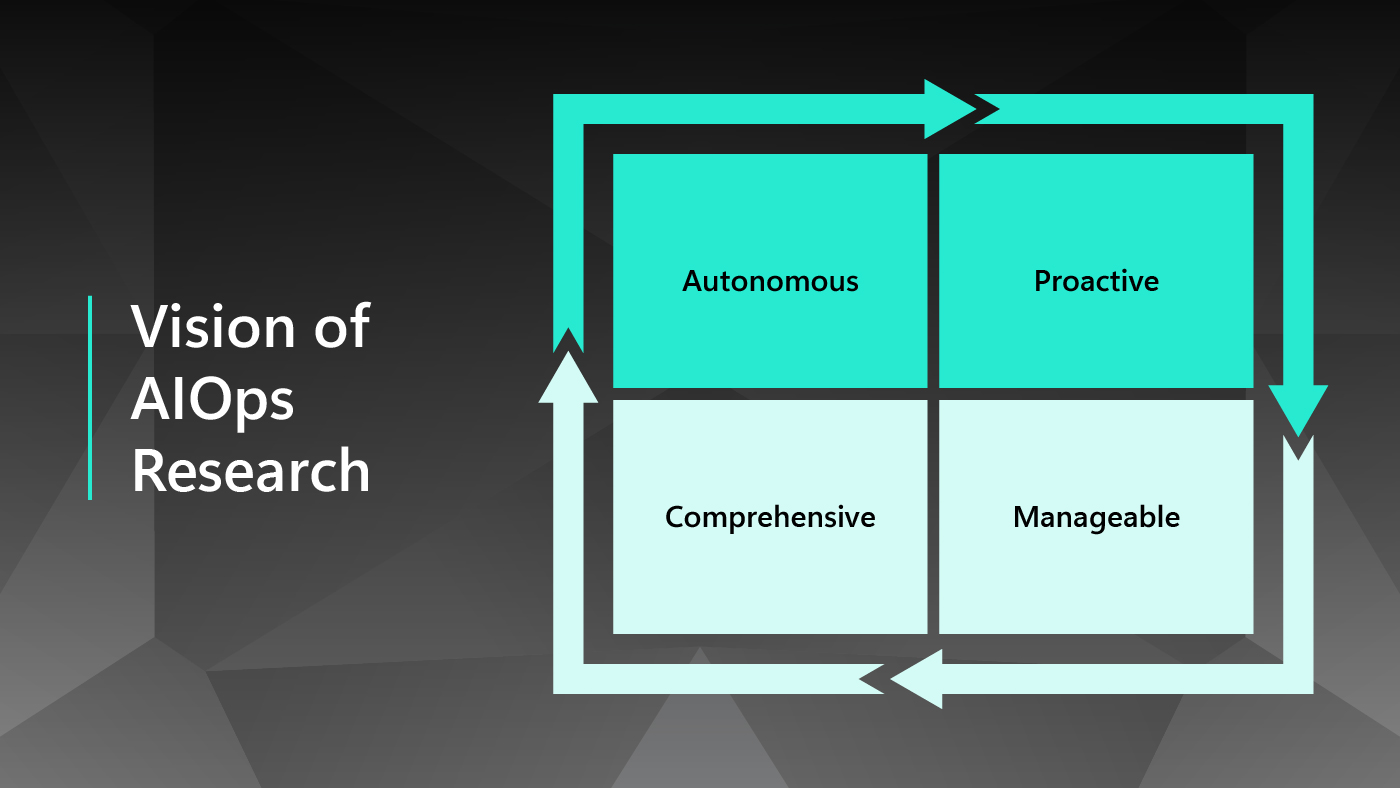
Vision of AIOps Research
| Autonomous | Proactive | Manageable | Comprehensive |
| Fully automate the operation of cloud systems to minimize system downtime and reduce manual efforts. | Predict future cloud status, support proactive decision-making, and prevent bad things from happening. | Introduce the notion of tiered autonomy for infusing autonomous routine operations and deep human expertise. | Span AIOps to the full cloud stack for global optimization/management and extend to multi-cloud environments. |
Starting with this blog post, we will take a deeper dive into Microsoft’s vision for AIOps research and the ongoing efforts to realize that vision. This blog post will focus on how our researchers leveraged state-of-the-art AIOps research to help make cloud technologies more autonomous and proactive. We will discuss our work to make the cloud more manageable and comprehensive in future blog posts.
Autonomous cloud
Motivation
Cloud platforms require numerous actions and decisions every second to ensure that computing resources are properly managed and failures are promptly addressed. In practice, those actions and decisions are either generated by rule-based systems constructed upon expert knowledge or made manually by experienced engineers. Still, as cloud platforms continue to grow in both scale and complexity, it is apparent that such solutions will be insufficient for the future cloud system. On one hand, rigid rule-based systems, while being knowledge empowered, often involve huge numbers of rules and require frequent maintenance for better coverage and adaptability. Still, in practice, it is often unrealistic to keep such systems up to date as cloud systems expand in both size and complexity, and even more difficult to guarantee consistency and avoid conflicts between all the rules. On the other hand, engineering efforts are very time-consuming, prone to errors, and difficult to scale.
Spotlight: Microsoft Research Podcast

AI Frontiers: The Physics of AI with Sébastien Bubeck
What is intelligence? How does it emerge and how do we measure it? Ashley Llorens and machine learning theorist Sébastian Bubeck discuss accelerating progress in large-scale AI and early experiments with GPT-4.
To break the constraints on the coverage and scalability of the existing solutions and improve the adaptability and manageability of the decision-making systems, cloud platforms must shift toward a more autonomous management paradigm. Instead of relying solely on expert knowledge, we need suitable AI/ML models to fuse operational data and expert knowledge together to enable efficient, reliable, and autonomous management decisions. Still, it will take many research and engineering efforts to overcome various barriers for developing and deploying autonomous solutions to cloud platforms.
Toward an autonomous cloud
In the journey towards an autonomous cloud, there are two major challenges. The first challenge lies in the heterogeneity of cloud data. In practice, cloud platforms deploy a huge number of monitors to collect data in various formats, including telemetry signals, machine-generated log files, and human input from engineers and users. And the patterns and distributions of those data generally exhibit a high degree of diversity and are subjected to changes over time. To ensure that the adopted AIOps solutions can function autonomously in such an environment, it is essential to empower the management system with robust and extendable AI/ML models capable of learning useful information from heterogeneous data sources and drawing right conclusions in various scenarios.
The complex interaction between different components and services presents another major challenge in deploying autonomous solutions. While it can be easy to implement autonomous features for one or a few components/services, how to construct end-to-end systems capable of automatically navigating the complex dependencies in cloud systems presents the true challenge for both researchers and engineers. To address this challenge, it is important to leverage both domain knowledge and data to optimize the automation paths in application scenarios. Researchers and engineers should also implement reliable decision-making algorithms in every decision stage to improve the efficiency and stability of the whole end-to-end decision-making process.
Over the past few years, Microsoft research groups have developed many new models and methods for overcoming those challenges and improving the level of automation in various cloud application scenarios across the AIOps problem spaces. Notable examples include:
- Detection: Gandalf and ATAD for the early detection of problematic deployments; HALO for hierarchical faulty localization; and Onion for detecting incident-indicating logs.
- Diagnosis: SPINE and UniParser for log parsing; Logic and Warden for regression and incident diagnosis; and CONAN for batch failure diagnosis.
- Prediction: TTMPred for predicting time to mitigate incidents; LCS for predicting the low-capacity status in cloud servers; and Eviction Prediction for predicting the eviction of spot virtual machines.
- Optimization: MLPS for optimizing the reallocation of containers; and RESIN for the management of memory leak in cloud infrastructure.
These solutions not only improve service efficiency and reduce management time with more automatous design, but also result in higher performance and reliability with fewer human errors. As an illustration of our work toward a more autonomous cloud, we will discuss our exploration for supporting automatic safe deployment services below.
Exemplary scenario: Automatic safe deployment
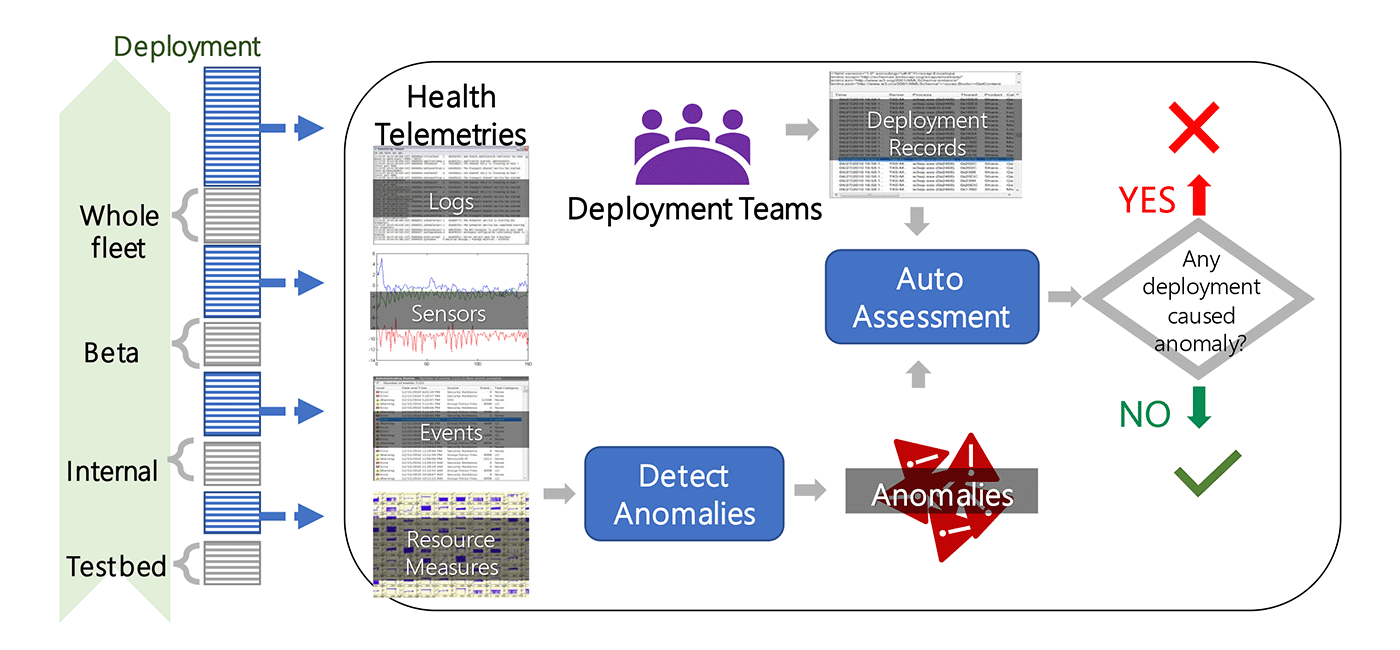
In online services, the continuous integration and continuous deployment (CI/CD) of new patches and builds are critical for the timely delivery of bug fixes and feature updates. Because new deployments with undetected bugs or incompatible issues can cause severe service outages and create significant customer impact, cloud platforms enforce strict safe-deployment procedures before releasing each new deployment to the production environments. Such procedures typically involve multi-stage testing and verification in a sequence of canary environments with increasing scopes. When a deployment-related anomaly is identified in one of these stages, the responsible deployment is rolled back for further diagnosis and fixing. Owing to the challenges of identifying deployment-related anomalies with heterogeneous patterns and managing a huge number of deployments, safe-deployment systems administrated manually can be extremely costly and error prone.
To support automatic and reliable anomaly detection in safe deployment, we proposed a general methodology named ATAD for the effective detection of deployment-related anomalies in time-series signals. This method addresses the challenges of capturing changes with various patterns in time-series signals and the lack of labeled anomaly samples due to the heavy cost of labeling. Specifically, this method combines ideas from both transfer learning and active learning to make good use of the temporal information in the input signal and reduce the number of labeled samples required for model training. Our experiments have shown that ATAD can outperform other state-of-the-art anomaly detection approaches, even with only 1%-5% of labeled data.
At the same time, we collaborated with product teams in Azure to develop and deploy Gandalf, an end-to-end automatic safe deployment system that reduces deployment time and increases the accuracy of detecting bad deployment in Azure. As a data-driven system, Gandalf monitors a large array of information, including performance metrics, failure signals and deployment records. It also detects anomalies in various patterns throughout the entire safe-deployment process. After detecting anomalies, Gandalf applies a vote-veto mechanism to reliably determine whether each detected anomaly is caused by a specific new deployment. Gandalf then automatically decides whether the relevant new deployment should be stopped for a fix or if it’s safe enough to proceed to the next stage. After rolling out in Azure, Gandalf has been effective at helping to capture bad deployments, achieving more than 90% precision and near 100% recall in production over a period of 18 months.
Proactive cloud
Motivation
Traditional decision-making in the cloud focuses on optimizing immediate resource usage and addressing emerging issues. While this reactive design is not unreasonable in a relatively static system, it can lead to short-sighted decisions in a dynamic environment. In cloud platforms, both the demand and utilization of computing resources are undergoing constant changes, including regular periodical patterns, unexpected spikes, and gradual shifts in both temporal and spatial dimensions. To improve the long-term efficiency and reliability of cloud platforms, it is critical to adopt a proactive design that takes the future status of the system into account in the decision-making process.
A proactive design leverages data-driven models to predict the future status of cloud platforms and enable downstream proactive decision-making. Conceptually, a typical proactive decision-making system consists of two modules: a prediction module and a decision-making module, as displayed in the following diagram.
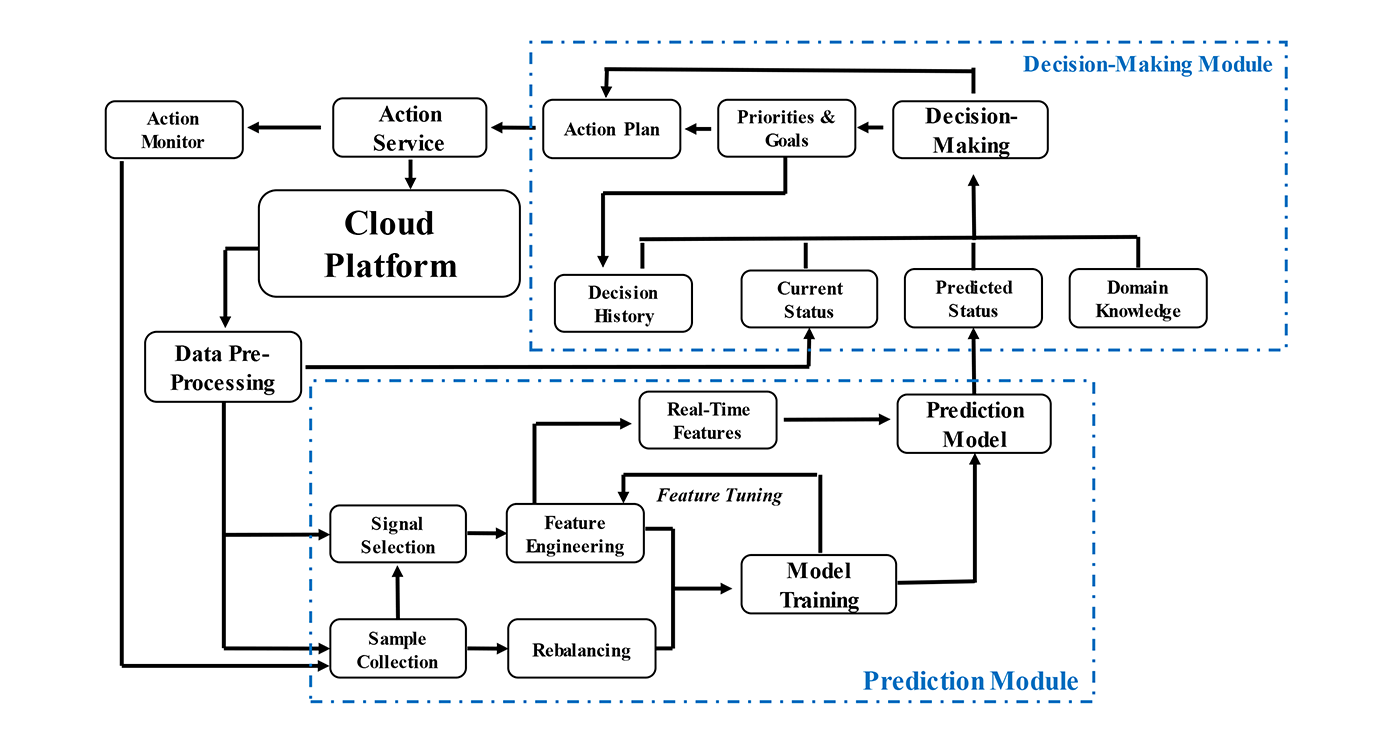
In the prediction module, historical data are collected and processed for training and fine-tuning the prediction model for deployment. The deployed prediction model takes in the online data stream and generates prediction results in real time. In the decision-making module, both the current system status and the predicted system status, along with other information such as domain knowledge and past decision history, is considered for making decisions that balance both present and future benefits.
Toward proactive design
Proactive design, while creating new opportunities for improving the long-term efficiency and reliability of cloud systems, does expose the decision-making process to additional risks. On one hand, thanks to the inherent randomness in the daily operation of cloud platforms, proactive decisions are always subjected to the uncertainty risk from the stochastic elements in both running systems and the environments. On the other hand, the reliability of prediction models adds another layer of risks in making proactive decisions. Therefore, to guarantee the performance of proactive design, engineers must put mechanisms in place to address those risks.
To manage uncertainty risk, engineers need to reformulate the decision-making in proactive design to account for the uncertainty elements. They can often use methodological frameworks, such as prediction+optimization and optimization under chance-constraints, to incorporate uncertainties into the target functions of optimization problems. Well-designed ML/AL models can also learn uncertainty from data for improving proactive decisions against uncertainty elements. As for risks associated with the prediction model, modules for improving data quality, including quality-aware feature engineering, robust data imputation, and data rebalancing, should be applied to reduce prediction errors. Engineers should also make continuous efforts to improve and update the robustness of prediction models. Moreover, safeguarding mechanisms are essential to prevent decisions that may cause harm to the cloud system.
Microsoft’s AIOps research has pioneered the transition from reactive decision-making to proactive decision-making, especially in problem spaces of prediction and optimization. Our efforts not only lead to significant improvement in many application scenarios traditionally supported by reactive decision-making, but also create many new opportunities. Notable proactive design solutions include Narya and Nenya for hardware failure mitigation, UAHS and CAHS for the intelligent virtual machine provisioning, CUC for the predictive scheduling of workloads, and UCaC for bin packing optimization under chance constraints. In the discussion below, we will use hardware failure mitigation as an example to illustrate how proactive design can be applied in cloud scenarios.
Exemplary scenario: Proactive hardware failure mitigation
A key threat to cloud platforms is hardware failure, which can cause interruptions to the hosted services and significantly impact the customer experience. Traditionally, hardware failures are only resolved reactively after the failure occurs, which typically involves temporal interruptions of hosted virtual machines and the repair or replacement of impacted hardware. Such a solution provides limited help in reducing negative customer experiences.
Narya is a proactive disk-failure mitigation service capable of taking mitigation actions before failures occur. Specifically, Narya leverages ML models to predict potential disk failures, and then make decisions accordingly. To control risks associated with uncertainty, Narya evaluates candidate mitigation actions based on the estimated impacts to customers and chooses actions with minimum impact. A feedback loop also exists for collecting follow-up assessments to improve prediction and decision modules.
Hardware failures in cloud systems are often highly interdependent. Therefore, to reduce the impact of predictions errors, Narya introduces a novel dependency-aware model to encode the dependency relationship between nodes to improve the failure prediction model. Narya also implements an adaptive approach that uses A/B testing and bandit modeling to improve the ability to estimate the impacts of actions. Several safeguarding mechanisms in different stages of Narya are also in place to eliminate the chance of making unsafe mitigation actions. Implementation of Narya in Azure’s production environment has reduced the node hardware interruption rate for virtual machines by more than 26%.
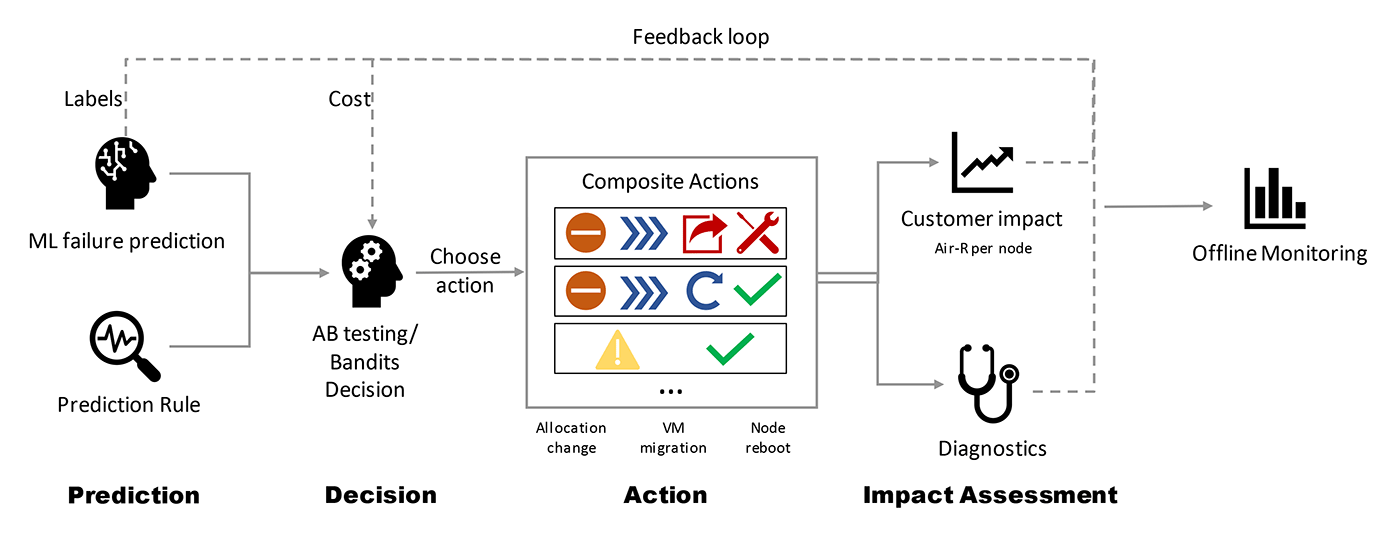
Our recent work, Nenya, is another example for proactive failure mitigation. Under a reinforcement learning framework, Nenya fuses prediction and decision-making modules into an end-to-end proactive decision-making system. It can weigh both mitigation costs and failure rates to better prioritize cost-effective mitigation actions against uncertainty. Moreover, the traditional failure mitigation method usually suffers from data imbalance issues; cases of failure form only a very small portion of all cases, which have mostly healthy situations. Such data imbalance would introduce bias to both the prediction and decision-making process. To address this problem, Nenya adopts a cascading framework to ensure that mitigation decisions are not made with heavy costs. Experiments with Microsoft 365 data sets on database failure have proved that Nenya can reduce both mitigation costs and database failure rates compared with existing methods.
Future work
As management systems become more automated and proactive, it is important to pay special attention to both the safety of cloud systems and the responsibility to cloud customers. The autonomous and proactive decision system will depend heavily on advanced AI/ML models with little manual effort. How to ensure that the decisions made by those approaches are both safe and responsible is an essential question that future work should answer.
The autonomous and proactive cloud relies on the effective data usage and feedback loop across all stages in the management and operation of cloud platforms. On one hand, high-quality data on the status of cloud systems are needed to enable downstream autonomous and proactive decision-making systems. On the other hand, it is important to monitor and analyze the impact of each decision on the entire cloud platform in order to improve the management system. Such feedback loops can exist simultaneously for many related application scenarios. Therefore, to better support an autonomous and proactive cloud, a unified data plane responsible for the processing and feedback loop can take a central role in the whole system design and should be a key area of investment.
As such, the future of cloud relies not only on adopting more autonomous and proactive solutions, but also on improving the manageability of cloud systems and the comprehensive infusion of AIOps technologies over all stacks of cloud systems. In future blog posts, we will discuss how to work toward a more manageable and comprehensive cloud.
Stay tuned!
The post Building toward more autonomous and proactive cloud technologies with AI appeared first on Microsoft Research.