
Humans have the fundamental cognitive ability to perceive the environment through multimodal sensory signals and utilize this to accomplish a wide variety of tasks. It is crucial that an autonomous agent can similarly perceive the underlying state of an environment from different sensors and appropriately consider how to accomplish a task. For example, localization (or “where am I?”) is a fundamental question that needs to be answered by an autonomous agent prior to navigation, often addressed via visual odometry. Highly dynamic tasks, such as vehicle racing, necessitate collision avoidance and understanding of the temporal evolution of their state with respect to the environment. Agents must learn perceptual representations of geometric and semantic information from the environment so that their actions can influence the world.
Task-driven approaches are appealing, but learning representations that are suitable only for a specific task limits their ability to generalize to new scenarios, thus confining their utility. For example, as shown in Figure 1, to achieve tasks of drone navigation and vehicle racing, people usually need to specifically design different models to encode representations from very different sensor modalities, e.g., different environments, sensory signals, sampling rate, etc. Such models must also cope with different dynamics and controls for each application scenario. Therefore, we ask the question if it is possible to build general-purpose pretrained models for autonomous systems that are agnostic to tasks and individual form factor.
In our recent work, COMPASS: Contrastive Multimodal Pretraining for Autonomous Systems, we introduce a general-purpose pretraining pipeline, built to overcome such limitations arising from task-specific models. The code can be viewed on GitHub.
COMPASS features three key aspects:
- COMPASS is a general-purpose large-scale pretraining pipeline for perception-action loops in autonomous systems. Representations learned by COMPASS generalize to different environments and significantly improve performance on relevant downstream tasks.
- COMPASS is designed to handle multimodal data. Given the prevalence of multitudes of sensors in autonomous systems, the framework is designed to utilize rich information from different sensor modalities.
- COMPASS is trained in a self-supervised manner which does not require manual labels, and hence can leverage large scale data for pretraining.
We demonstrate how COMPASS can be used to solve various downstream tasks across three different scenarios: Drone Navigation, Vehicle Racing, and Visual Odometry tasks.
Challenges in learning generic representations for autonomous systems
Although general-purpose pretrained models have made breakthroughs in natural language processing (NLP) and in computer vision, building such models for autonomous systems has its own challenges.
- Autonomous systems deal with complex perception-action interplay. The target learning space is highly variable due to a wide range of environmental factors and application scenarios. This is in stark contrast to language models, which focus on underlying linguistic representations, or visual models, which focus on object-centric semantics. These aspects make existing pretraining approaches inadequate for autonomous systems.
- The environments are usually perceived through multimodal sensors, so the model must be able to make sense of multimodal data. Existing multimodal learning approaches focus primarily on mapping multimodal data into joint latent spaces. Though they have shown promising results in applications of video, audio, and text, they are suboptimal for autonomous systems. Approaches that learn a single joint latent space fail to respect different properties of multimodal data, such as sampling rate and temporal dynamics. On the other hand, mapping into disjoint latent spaces loses the connection among the modalities and limits the usage in complex autonomous systems, because different autonomous systems can be equipped with a wide variety of sensor configurations.
- Unlike NLP and computer vision, there is scarcity of multimodal data that can be used to train large pretrained representations for autonomous systems.
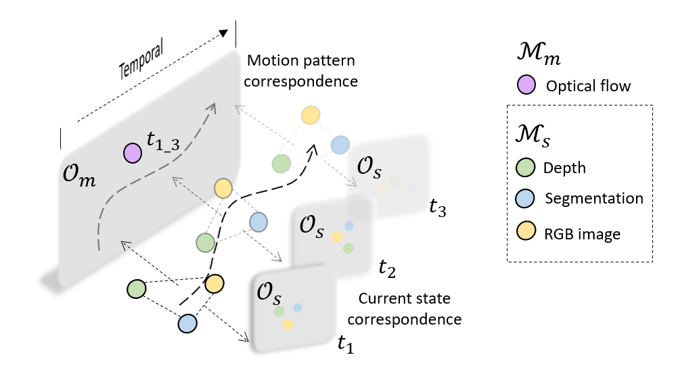
Factorized spatiotemporal latent spaces for learning representations
COMPASS is a multimodal pretraining framework for perception and action in autonomous systems. COMPASS builds general-purpose multimodal representations that can generalize to different environments and tasks.
Two questions inform our design choices in COMPASS:
- What essential pieces of information are common for all tasks of autonomous systems?
- How can we effectively learn representations from complex multimodal data to capture the desired information?
The network architecture design must adhere to the spatiotemporal constraints of autonomous systems. The representation needs to account for the motion (ego-motion or environmental) and its temporal aspects as well as the spatial, geometric, and semantic cues perceived through the sensors. Therefore, we propose a multimodal graph that captures the spatiotemporal properties of the modalities (Fig. 2). The graph is designed to map each of the modalities into two factorized spatiotemporal latent subspaces: 1) the motion pattern space and 2) the current state space. The self-supervised training then uses multimodal correspondence to associate the modality to the different latent spaces. Such a factorized representation further allows systems equipped with different sensors to use the same pretrained model.
While plenty of sensor modalities are rich in spatial and semantic cues, such as RGB images, depth sensors), we note that certain modalities primarily contain information about the temporal aspect, such as IMU, Optical Flow). Given such a partition of modalities between spatially informative ((mathcal{M}_{s})) and temporally informative (mathcal{M}_{m}) data, we jointly learn two latent spaces, a “motion pattern space” (mathcal{O}_{m}) and a “current state space” (mathcal{O}_{s}).
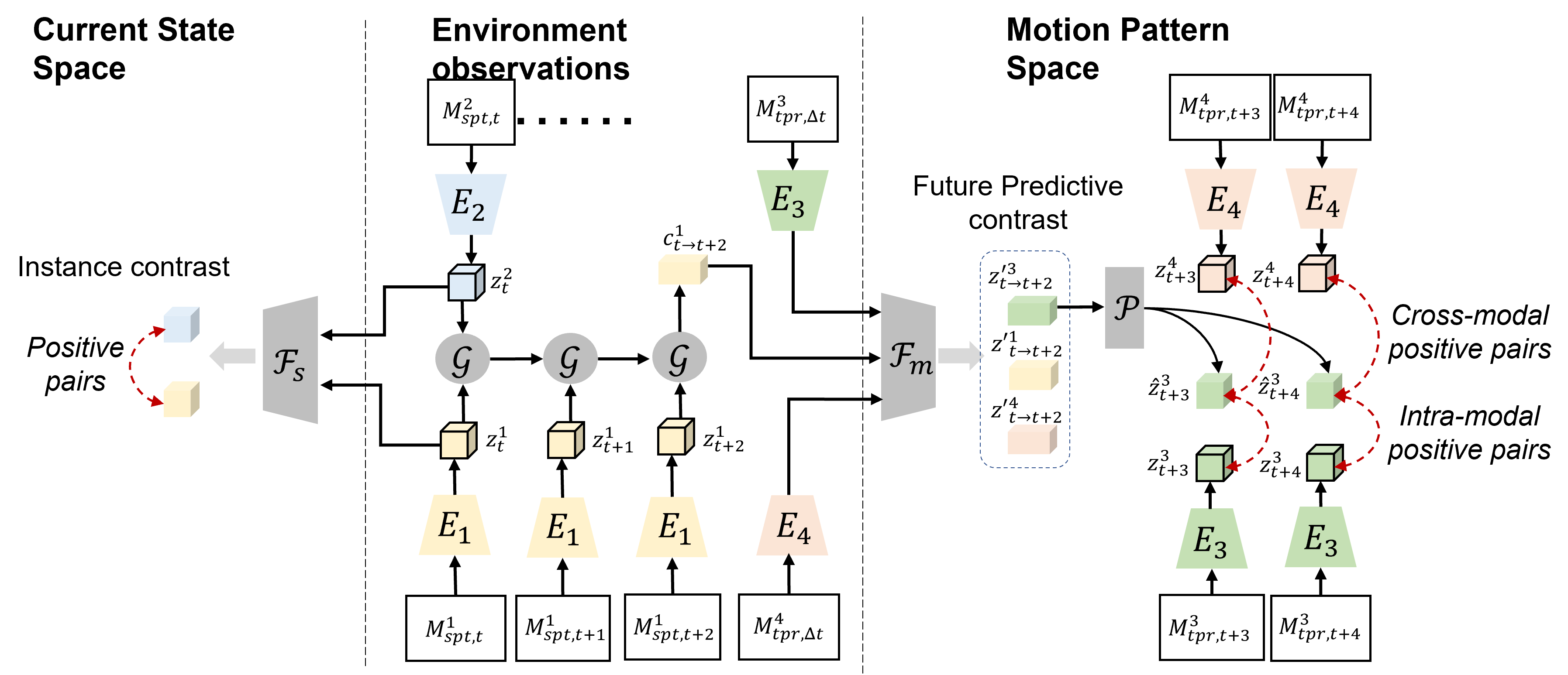
Contrastive learning via multimodal graph connections
The key intuition behind the self-supervised objective for training COMPASS is that if the representation successfully captures spatiotemporal information across multiple modalities, then each modality should have some predictive capacity both for itself as well as the others. We formulate this intuition into a contrastive learning objective. Figure 3 graphically depicts the idea where the modality-specific encoders (E) extract embeddings from each modality. These are then mapped to the common motion pattern space (mathcal{O}_{m}) through the motion pattern projection head (mathcal{F}_m). A prediction head (mathcal{P}) is added on top to perform future prediction. The contrastive loss is computed between the predicted future representations and their corresponding encoded true representations. Similarly, the contrastive objective also associates the data between distinct spatial modalities (mathcal{M}_{s}) projected onto the current state space (mathcal{O}_s) at every time step.
Note that modalities that are primarily temporal are projected to the motion pattern space through (mathcal{F}_m) only. Modalities that are only spatial are first projected onto the current state space by (mathcal{F}_s). To better associate spatial modalities with the temporal ones, we introduce a spatiotemporal connection where spatial modalities from multiple timesteps are aggregated via an aggregator head (mathcal{G}) and projected into the motion pattern space. Such as multimodal graph with spatial, temporal, and spatiotemporal connections serves as a framework for learning multimodal representations by encoding the underlying properties of modalities (such as static, dynamic) as well as any common information shared between them (for example, geometry, motion).
Finally, we tackle the challenge of data scarcity by resorting to simulation. In particular, we build upon our previous work in high-fidelity simulation with AirSim and use the TartanAir dataset (TartanAir: A Dataset to Push the Limits of Visual SLAM – Microsoft Research) to train the model.
Deploying COMPASS to downstream tasks
After pretraining, the COMPASS model can be finetuned for several downstream tasks. Based on the sensor modalities available for the task of interest, we connect the appropriate pretrained COMPASS encoders to small neural network modules responsible for task-specific predictions such as robot actions, camera poses etc. This combined model is then finetuned given data and objectives from the specific task.
We demonstrate the effectiveness of COMPASS as a general-purpose pretraining approach on three downstream tasks: simulated drone navigation, simulated vehicle racing, and visual odometry. Figure 4 and Table 1 show some details about both our pretraining as well as downstream task datasets.

| Dataset | Usage | Scale | Env. |
|---|---|---|---|
| TartanAIR | Pretraining | 1M | 16 |
| Soccer-gate | Drone Navigation. | 3k | 1 |
| KITTI | Visual Odometry | 23K | 11 |
| AirSim-Car | Car racing | 17K | 9 |
Drone Navigation
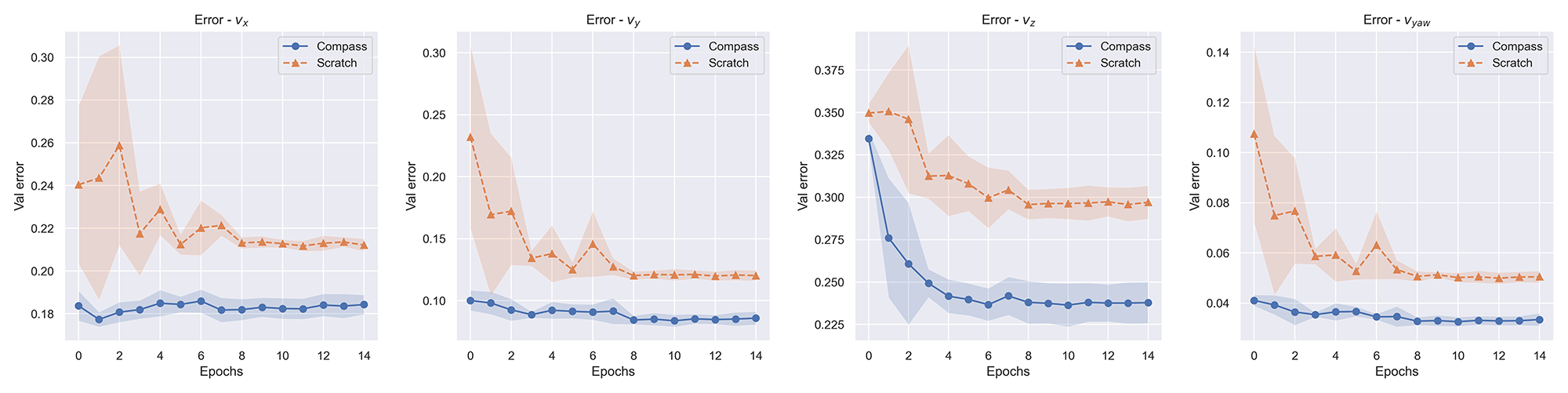
The goal of this task is to enable a quadrotor drone to navigate through a series of gates whose locations are unknown to it a priori. The simulated environment contains a diverse set of gates varying in shape, sizes, color, and texture. Given RGB images from the camera onboard the drone in this environment, the model is asked to predict velocity commands to make the drone successfully go through a series of gates. Figure 5 highlights that finetuning COMPASS for this velocity prediction task results in better performance than training a model from scratch.
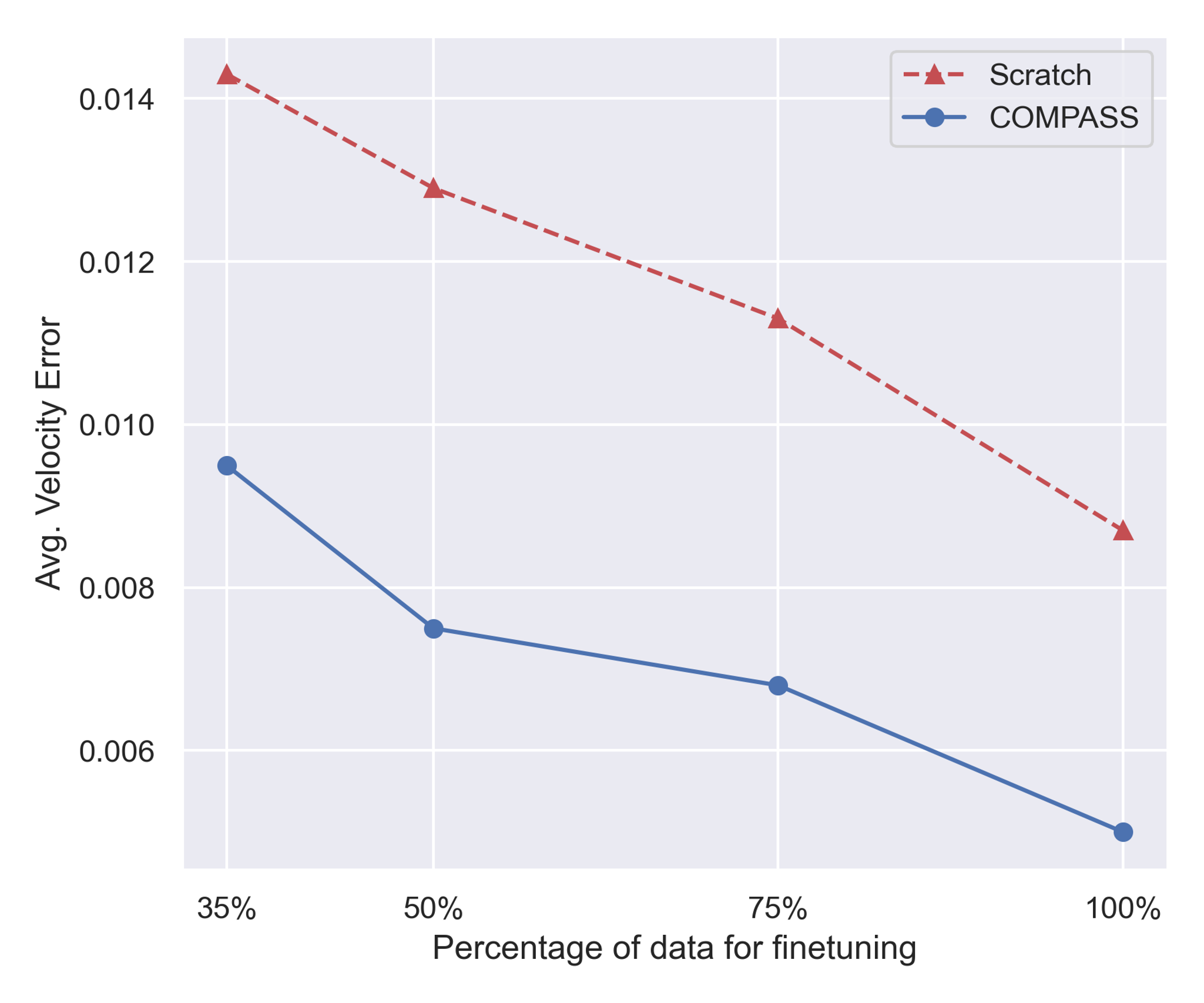
COMPASS can improve data efficiency. Furthermore, finetuning over pretrained COMPASS models exhibits more data efficient learning than training models from scratch. Figure 6 compares finetuning performance with different amounts of data to training from scratch. We see that COMPASS finetuning consistently produces fewer errors than training from scratch, even with less data.
Visual Odometry
Visual odometry (VO) aims to estimate camera motion from consecutive image frames. This is a fundamental component in visual SLAM which is widely used for localization in robotics. We evaluate COMPASS for the VO task on a widely used real-world dataset (The KITTI Vision Benchmark Suite (cvlibs.net)). We first use an off-the-shelf optical flow model (PWC-Net) to generate optical flow data given consecutive image frames, which are then inputted to the optical flow encoder of COMPASS, eventually resulting in predicted camera motion.
| Methods | Sequence 9 | Sequence 10 | ||
| (t_{rel}) | (r_{rel}) | (t_{rel}) | (r_{rel}) | |
| ORB-SLAM2 | 15.3 | 0.26 | 3.71 | 0.3 |
| DVSO | 0.83 | 0.21 | 0.74 | 0.21 |
| D3VO | 0.78 | – | 0.62 | – |
| VISO2-M | 4.04 | 1.43 | 25.2 | 3.8 |
| DeepVO | N/A | N/A | 8.11 | 8.83 |
| Wang et al. | 8.04 | 1.51 | 6.23 | 0.97 |
| TartanVO | 6.00 | 3.11 | 6.89 | 2.73 |
| UnDeepVO | N/A | N/A | 10.63 | 4.65 |
| GeoNet | 26.93 | 9.54 | 20.73 | 9.04 |
| COMPASS (ours) | 2.79 | 0.98 | 2.41 | 1.00 |
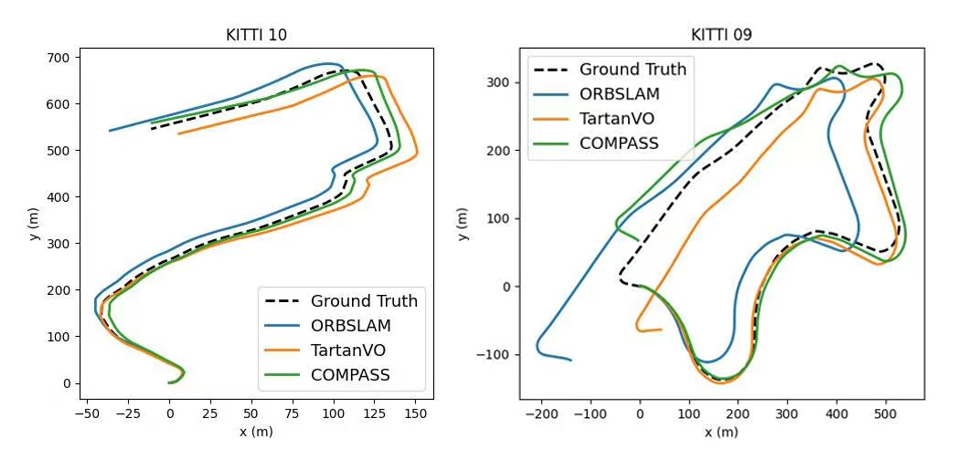
COMPASS can adapt to real-world scenarios. In this experiment, we finetune the model on sequence 00-08 of KITTI and test it on sequence 09 and 10. For comprehensive investigation, we compare COMPASS with both SLAM methods and visual odometry methods. The results are shown in Table 2, where we list the relative pose error (RPE), which is the same metric used on KITTI benchmark. Using the pretrained flow encoder from COMPASS within this VO pipeline achieves better results than several other VO methods and is even comparable to SLAM methods. Figure 7 shows the predicted trajectories of sequences 09 and 10 compared to ground truth. For clarity, we also select one representative model from the geometry-based and learning-based approaches each. We can see that, although pretrained purely on simulation data, COMPASS adapts well to finetuning on real-world scenarios.
Vehicle Racing
The goal here is to enable autonomous vehicles to drive in a competitive Formula racing environment. The simulated environment contains visual distractors such as advertising signs, tires, grandstands, and fences, which help add realism and increase task difficulty. Given RGB images from the environment as input, the control module must predict the steering wheel angle for a car to successfully maneuver around the track and avoid obstacles.
| Model | Seen env. | Unseen env. |
|---|---|---|
| SCRATCH | 0.085 ± 0.025 | 0.120 ± 0.009 |
| CPC | 0.037 ±0.012 | 0.101 ± 0.017 |
| CMC | 0.039 ± 0.013 | 0.102 ± 0.012 |
| JOINT | 0.055 ± 0.016 | 0.388 ± 0.018 |
| DISJOINT | 0.039 ± 0.017 | 0.131 ± 0.016 |
| COMPASS | 0.041 ± 0.013 | 0.071 ± 0.023 |

COMPASS can generalize to unseen environments. We hypothesize that better perception, enabled by pretraining, improves generalization to unseen environments. To show this, we evaluate models in two settings: 1) trained and evaluated on all nine scenarios (“seen”); 2) trained on eight scenarios and evaluated on one scenario (“unseen”). Table 3 shows that the performance degradation in the unseen environment is relatively marginal with (texttt{COMPASS}), which suggests its effectiveness compared to the other pretraining approaches.
COMPASS can benefit from multimodal training regime. We investigate the effectiveness of pretraining on multimodal data by analyzing loss curves from different pretrained models on the same ‘unseen’ environments. Figure 8(b) compares the validation loss curves of (texttt{COMPASS}), (texttt{RGB}), and (texttt{Scratch}), where (texttt{RGB}) is the model that is pretrained only with RGB images. As we can see, by pretraining on multimodal data, COMPASS achieves the best performance overall. Also, both of these pretraining models show large gaps when compared to a model trained from scratch ((texttt{Scratch})). When comparing Figure 8(a) to Figure 8(b), we see that (texttt{Scratch}) suffers more from the overfitting issue than the other two models.
Conclusion
We introduce COntrastive Multimodal pretraining for AutonomouS Systems (COMPASS), a ‘general’ pretraining framework that learns multimodal representations to tackle various downstream autonomous system tasks. In contrast to existing task-specific approaches in autonomous systems, COMPASS is trained entirely agnostic to any downstream tasks, with the primary goal of extracting information that is common to multiple scenarios. COMPASS learns to associate multimodal data with respect to their properties, allowing it to encode the spatio-temporal nature of data commonly observed in autonomous systems. We demonstrated that COMPASS generalizes well to different downstream tasks—drone navigation, vehicle racing and visual odometry—even in unseen environments, real-world environments and in the low-data regime.
The post COMPASS: COntrastive Multimodal Pretraining for AutonomouS Systems appeared first on Microsoft Research.