In the last three years, the largest trained dense models have increased in size by over 1,000 times, from a few hundred million parameters to over 500 billion parameters in Megatron-Turing NLG 530B (MT-NLG). Improvements in model quality with size suggest that this trend will continue, with larger model sizes bringing better model quality. However, sustaining the growth in model size is getting more difficult due to the increasing compute requirements.
There have been numerous efforts to reduce compute requirements to train large models without sacrificing model quality. To this end, architectures based on Mixture of Experts (MoE) have paved a promising path, enabling sub-linear compute requirements with respect to model parameters and allowing for improved model quality without increasing training cost.
However, MoE models have their own challenges. First, the scope of MoE models is primarily limited on encoder-decoder models and sequence-to-sequence tasks. Second, MoE models require more parameters to achieve the same model quality as their dense counterparts, which requires more memory for training and inference even though MoE models require less compute. Lastly, a critical consideration is that MoE models’ large size makes inference difficult and costly.
To address these above challenges, the DeepSpeed team, as part of Microsoft’s AI at Scale initiative, has been exploring new applications and optimizations for MoE models at scale. These can lower the training and inference cost of large models, while also enabling the ability to train and serve the next generation of models affordably on today’s hardware. Here, we are happy to share our findings and innovations for MoE models and systems that 1) reduce training cost by 5x, 2) reduce MoE parameter size by up to 3.7x and 3) reduce MoE inference latency by 7.3x at an unprecedented scale and offer up to 4.5x faster and 9x cheaper inference for MoE models compared to quality-equivalent dense models:
- 5x reduction in training cost for natural language generation (NLG) models: We extend the scope of MoE models to beyond just encoder-decoder models and sequence-to-sequence tasks, demonstrating that MoE can reduce the training cost of NLG models like those in the GPT family or MT-NLG by 5x while obtaining the same model quality. Data scientists can now train models of superior quality previously only possible with 5x more hardware resources.
- Reduced model size and improved parameter efficiency with Pyramid-Residual-MoE (PR-MoE) Architecture and Mixture-of-Students (MoS): The training cost reduction of MoE is not free and comes at the expense of increasing the total number of parameters required to achieve the same model quality as dense models. PR-MoE is a hybrid dense and MoE model created using residual connections, applying experts only where they are most effective. PR-MoE reduces MoE model parameter size by up to 3x with no change to model quality. In addition, we leverage staged knowledge distillation to learn a Mixture-of-Students model that further leads to up to 3.7x model size reduction while retaining similar model quality.
- Fast and economical MoE inference at unprecedented scale: The DeepSpeed-MoE (DS-MoE) inference system enables efficient scaling of inference workloads on hundreds of GPUs, providing up to 7.3x reduction in inference latency and cost when compared with existing systems. It offers ultra-fast inference latencies (25 ms) for trillion-parameter MoE models. DS-MoE also offers up to 4.5x faster and 9x cheaper inference for MoE models compared to quality-equivalent dense models by combining both system and model optimizations.
Each of these advances is explored further in the blog post below. For more about the technical details, please read our paper.
DeepSpeed-MoE for NLG: Reducing the training cost of language models by five times
While recent works like GShard and Switch Transformers have shown that the MoE model structure can reduce large model pretraining cost for encoder-decoder model architecture, their impact on the much more compute-intensive transformer-based autoregressive NLG models has been mostly unknown.
Given the tremendous compute and energy requirements for training NLG models, we explore opportunities where MoE can reduce their training cost. We show that MoE can be applied to NLG models to significantly improve their model quality with the same training cost. Also, MoE can achieve 5x reduction in training cost to achieve the same model quality of a dense NLG model. For example, we achieved the quality of a 6.7B-parameter dense NLG model at the cost of training a 1.3B-parameter dense model. Our observation about MoE training cost savings aligns with parallel explorations from Du et al. and Artetxe et al., where they also demonstrated the savings for models with bigger sizes.
Our MoE-based NLG model architecture
To create an MoE-based NLG model, we studied a transformer-based NLG model similar to those of the GPT family. To complete training in a reasonable timeframe, the following models were selected: 350M (24 layers, 1024 hidden size, 16 attention heads), 1.3B (24 layers, 2048 hidden size, 16 attention heads), and 6.7B (32 layers, 4096 hidden size, 32 attention heads). We use “350M+MoE-128” to denote a MoE model that uses 350M dense model as the base model and adds 128 experts on every other feedforward layer.
MoE training infrastructure and dataset
We pretrained both the dense and MoE versions of the above models using DeepSpeed on 128 NVIDIA Ampere A100 GPUs (Azure ND A100 instances). These Azure instances are powered by the latest Azure HPC docker images that provide a fully optimized environment and best performing library versions of NCCL, Mellanox OFED, Sharp, and CUDA. DeepSpeed uses a combination of data-parallel and expert-parallel training to effectively scale MoE model training and is capable of training MoE models with trillions of parameters on hundreds of GPUs.
We used the same training data as described in the MT-NLG blog post. For a fair comparison, we use 300 billion tokens to train both dense and MoE models.
MoE leads to better quality for NLG models
Figure 1 shows that the validation loss for the MoE versions of the model is significantly better than their dense counterparts. Furthermore, validation loss of the 350M+MoE-128 model is on par validation loss of the 1.3B dense model with 4x larger base. This is also true for 1.3B+MoE-128 in comparison with 6.7B dense model with 5x larger base. Furthermore, the model quality is on par not only with the validation loss but also with six zero-shot evaluation tasks as shown in Table 1, demonstrating that these models have very similar model quality.
| Case | Model size | LAMBADA: completion prediction | PIQA: commonsense reasoning | BoolQ: reading comprehension | RACE-h: reading comprehension | TriviaQA: question answering | WebQs: question answering |
| Dense NLG: | |||||||
| (1) 350M | 350M | 0.5203 | 0.6931 | 0.5364 | 0.3177 | 0.0321 | 0.0157 |
| (2) 1.3B | 1.3B | 0.6365 | 0.7339 | 0.6339 | 0.3560 | 0.1005 | 0.0325 |
| (3) 6.7B | 6.7B | 0.7194 | 0.7671 | 0.6703 | 0.3742 | 0.2347 | 0.0512 |
| Standard MoE NLG: | |||||||
| (4) 350M+MoE-128 | 13B | 0.6270 | 0.7459 | 0.6046 | 0.3560 | 0.1658 | 0.0517 |
| (5) 1.3B+MoE-128 | 52B | 0.6984 | 0.7671 | 0.6492 | 0.3809 | 0.3129 | 0.0719 |
| PR-MoE NLG: | |||||||
| (6) 350M+PR-MoE-32/64 | 4B | 0.6365 | 0.7399 | 0.5988 | 0.3569 | 0.1630 | 0.0473 |
| (7) 1.3B+PR-MoE-64/128 | 31B | 0.7060 | 0.7775 | 0.6716 | 0.3809 | 0.2886 | 0.0773 |
| PR-MoE NLG + MoS: | |||||||
| (8) 350M+PR-MoE-32/64 + MoS-21L | 3.5B | 0.6346 | 0.7334 | 0.5807 | 0.3483 | 0.1369 | 0.0522 |
| (9) 1.3B+PR-MoE-64/128 + MoS-21L | 27B | 0.7017 | 0.7769 | 0.6566 | 0.3694 | 0.2905 | 0.0822 |
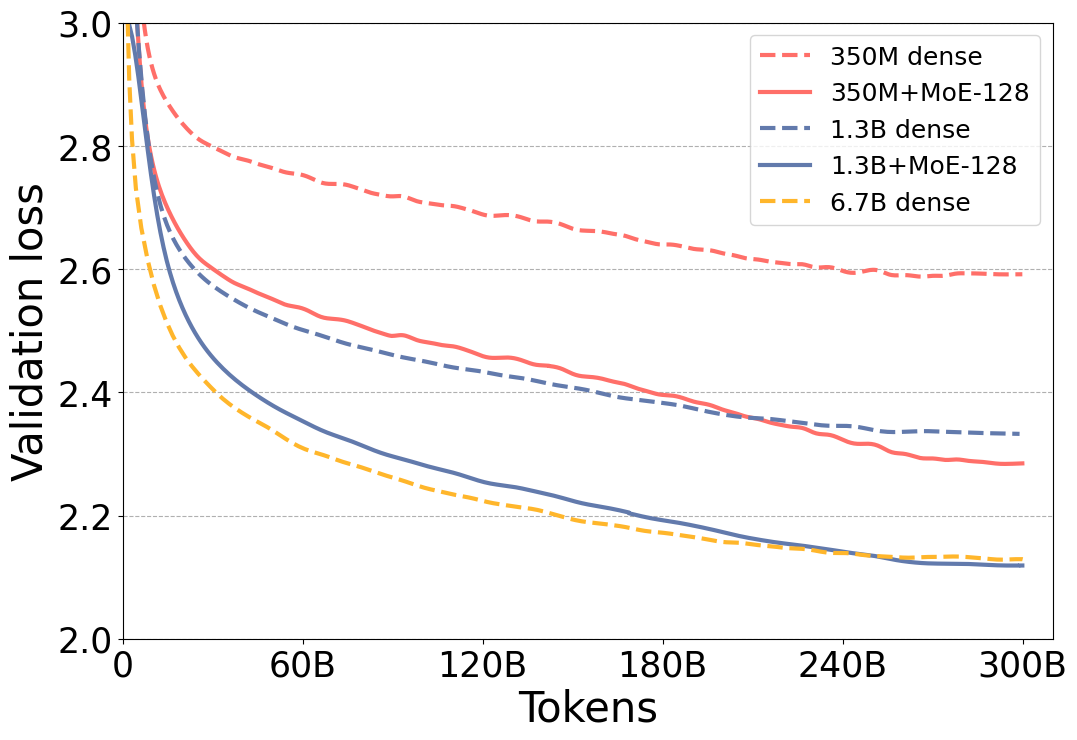
Same quality with 5x less training cost
As shown in the results above, adding MoE with 128 experts to the NLG model significantly improves its quality. However, these experts do not change the compute requirements of the model as each token is only processed by a single expert. Therefore, the compute requirements for a dense model and its corresponding MoE models with the same base are similar.
More concretely, training 1.3B+MoE-128 requires roughly the same amount of compute operations as a 1.3B dense model while offering much better quality. Our results show that by applying MoE, the model quality of a 6.7B-parameter dense model can be achieved at the training cost of a 1.3B-parameter dense model, resulting in an effective training compute reduction of 5x.
This compute cost reduction can directly be translated into throughput gain, training time and training cost reduction by leveraging the efficient DeepSpeed MoE training system. Table 2 shows the training throughput of 1.3B+MoE-128 compared with the 6.7B dense model on 128 NVIDIA A100 GPUs.
| Training samples per sec | Throughput gain/ Cost Reduction | |
|---|---|---|
| 6.7B dense | 70 | 1x |
| 1.3B+MoE-128 | 372 | 5x |
PR-MoE and Mixture-of-Students: Reducing the model size and improving parameter efficiency
While MoE-based models achieve the same quality with 5x training cost reduction in the NLG example, the resulting model has roughly 8x the parameters of the corresponding dense model. For example, a 6.7B dense model has 6.7 billion parameters and 1.3B+MoE-128 has 52 billion parameters. Training such a massive MoE model requires significantly more memory; inference latency and cost could also increase since the primary inference bottleneck is often the memory bandwidth needed to read model weights.
To reduce model size and improve parameter efficiency, we’ve made innovations in the MoE model architecture that reduce the overall model size by up to 3 times without affecting model quality. We also leverage knowledge distillation to learn a Mixture-of-Students (MoS) model, with a smaller model capacity as the teacher PR-MoE but preserve the teacher model accuracy.
Two intuitions for improving MoE architecture
Intuition-I: The standard MoE architecture has the same number and structure of experts in all MoE layers. This relates to a fundamental question in the deep learning community, which has been well-studied in computer vision: do all the layers in a deep neural network learn the same representation? Shallow layers learn general representations and deep layers learn more objective-specific representations. This also leads transfer learning in computer vision to freeze shallow layers for fine-tuning. This phenomenon, however, has not been well-explored in natural language processing (NLP), particularly for MoE.
To investigate the question, we compare the performance of two different half-MoE architectures. More specifically, we put MoE layers in the first half of the model and leave the second half’s layers identical to the dense model. We switch the MoE layers to the second half and use dense at the first half. The results show that deeper layers benefit more from large number of experts. This confirms that not all MoE layers learn the same level of representations.
Intuition-II: To improve the generalization performance of MoE models, there are two common methods: 1) increasing the number of experts while keeping the capacity (that is, for each token, the number of experts it goes through) to be the same; 2) doubling the capacity at the expense of slightly more computation (33%) while keeping the same number of experts. However, for method 1, the memory requirement for training resources needs to be increased due to larger number of experts. For method 2, higher capacity also doubles the communication volume which can significantly slow down training and inference. Is there a way to keep the training and inference efficiency while getting generalization performance gain?
One intuition of why larger capacity helps accuracy is that those extra experts can help correct the “representation” of the first expert. However, does this first expert need to be changed every time? Or can we fix the first and only assign different extra experts to different tokens?
To investigate this, we perform a comparison in two ways: doubling the capacity and fixing one expert while varying the second expert across different experts. For the latter, a token will always pass a dense multilayer perceptron (MLP) module and an expert from MoE module. Therefore, we can achieve the benefit of using two experts per layer but still use one communication. We find out that the generalization performance of these two is on-par with each other. However, the training/inference speed of our new design is faster.
New MoE Architecture: Pyramid-Residual MoE
We propose a novel MoE architecture, Pyramid-Residual MoE (PR-MoE). Figure 2 (right) shows its architecture. Following Intuition-I, PR-MoE utilizes more experts in the last few layers as compared to previous layers, which gives a reverse pyramid design. Following Intuition II, we propose a Residual-MoE structure, where each token separately passes one fixed MLP layer and one chosen expert. Combining them results in the PR-MoE model, where all standard MoE layers are replaced by the new PR-MoE layer.
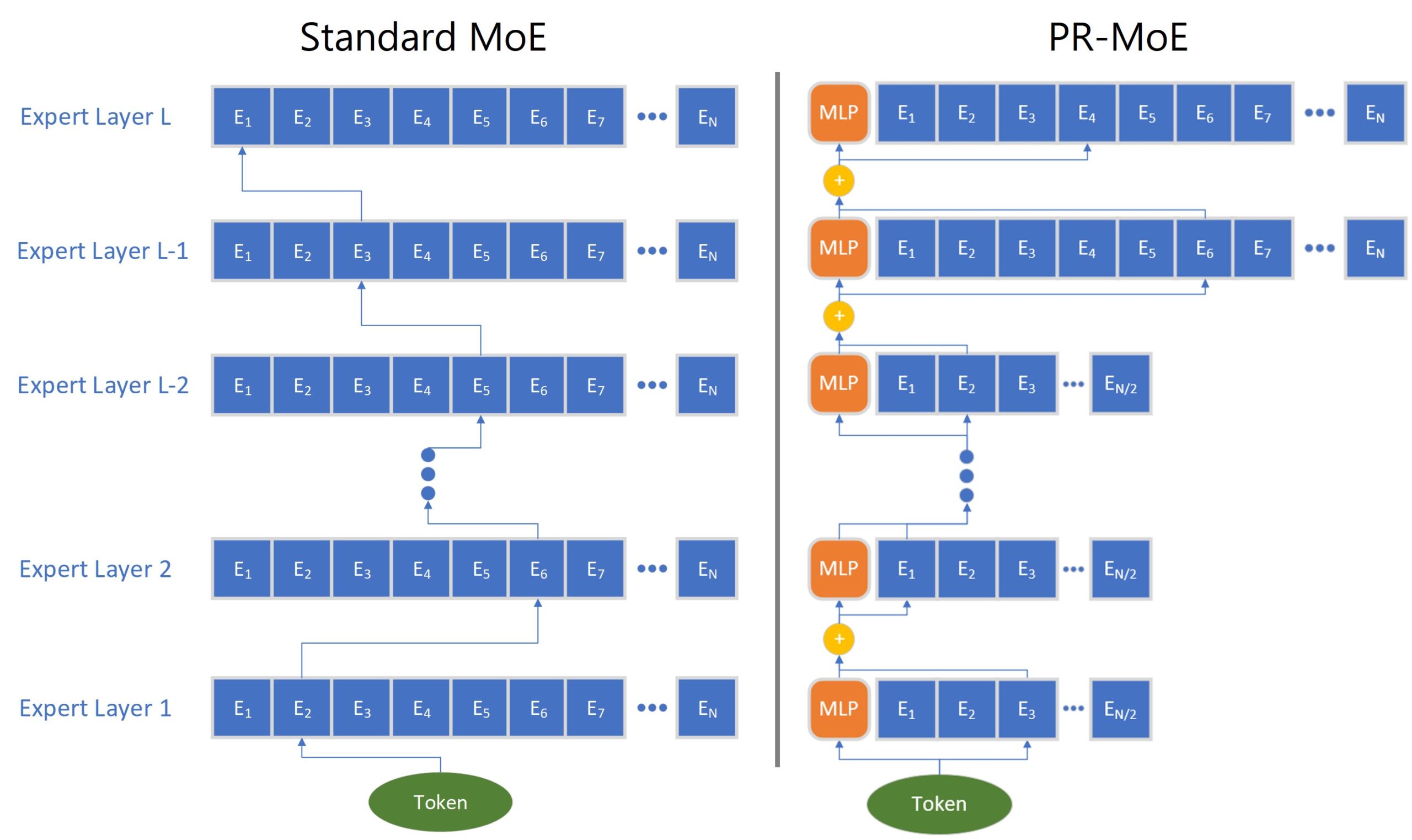
Same quality as standard models with up to 3x model size reduction: We evaluate PR-MoE on two model sizes, with bases of 350M and 1.3B parameters, and compare the performance with larger standard MoE architectures. The results are shown in Table 1 above. For both cases, PR-MoE uses much fewer experts but achieves comparable accuracy as standard MoE models. In the 350M model, PR-MoE only uses less than one third of the parameters that the standard MoE uses. In the 1.3B case, PR-MoE only uses about 60 percent of the parameters required for standard MoE.
Mixture-of-Students: Distillation for even smaller model size and faster inference
Model compression and distillation present additional opportunities to improve inference performance further. While there are many ways for model compression, such as quantization and pruning, we focus on reducing the number of layers of each expert in MoE and using knowledge distillation to compress the resulting student model to achieve a similar performance to the teacher MoE.
Since MoE structure brings significant benefits by enabling sparse training and inference, our task-agnostic distilled MoE model, which we call Mixture of Students (MoS), inherits these benefits while still providing the flexibility to compress into a dense model. We note that while existing work primarily considers small transformers (a few hundred parameters) and dense encoder-based LM models (like BERT), we focus on studying knowledge distillation for sparse MoE-based auto-generative language models on a multi-billion parameter scale. Furthermore, given the excellent performance of PR-MoE, we combine PR-MoE with MoS to further reduce the MoE model size.
To apply knowledge distillation for MoE, we first train a teacher MoE model using the same training hyperparameters and datasets as in the previous section. The teacher model is 350M+PR-MoE-32/64 and 1.3B+PR-MoE-64/128, respectively. We reduce the depth of the teacher model to 21 (12.5%) to obtain a student model, and we force the student to imitate the outputs from the teacher MoE on the training dataset.
In particular, we take the knowledge distillation loss as a weighted sum of the cross-entropy loss between predictions and the given hard label and the Kullback–Leibler (KL) divergence loss between the predictions and the teacher’s soft label. In practice, we observe that distillation may adversely affect MoS accuracy. In particular, while knowledge distillation loss improves validation accuracy initially, it begins to hurt accuracy towards the end of training.
We hypothesize that because the PR-MoE already reduces the capacity compared with the standard MoE by exploiting the architecture change (for example, reducing experts in lower layers), further reducing the depth of the model causes the student to have insufficient capacity, making it fall into the underfitting regime. Therefore, we take a staged distillation approach, where we decay the impact from knowledge distillation gradually in the training process.
Our study shows that it is possible to reach similar performance—such as in zero-shot evaluation on many downstream tasks—for a smaller MoE model pretrained with knowledge distillation. The MoS achieve comparable accuracy to the teacher MoE model, retaining 99.3% and 99.1% of the performance despite having 12.5% fewer layers. This enables an additional 12.5% model size reduction. When combined with PR-MoE, it leads to up to 3.7x model size reduction.
DeepSpeed-MoE inference: Serving MoE models at unprecedented scale and speed
Optimizing for MoE inference latency and cost is crucial for MoE models to be useful in practice. During inference the batch size is generally small, so the inference latency of an MoE model depends primarily on time it takes to load the model parameters from main memory, contrasting with the conventional belief that lesser compute should lead to faster inference. So, inference performance mainly depends on two factors: the overall model size and the overall achievable memory bandwidth.
In the previous section, we presented PR-MoE and distillation to optimize the model size. This section presents our solution to maximize the achievable memory bandwidth by creating a multi-GPU MoE inferencing system that can leverage the aggregated memory bandwidth across dozens of distributed GPUs to speed up inference. Together, DeepSpeed offers an unprecedented scale and efficiency to serve massive MoE models with 7.3x better latency and cost compared to baseline MoE systems, and up to 4.5x faster and 9x cheaper MoE inference compared to quality-equivalent dense models.
MoE inference performance is an interesting paradox
From the best-case view, each token of an MoE model only activates a single expert at each MoE layer, resulting in a critical data path that is equivalent to the base model size, orders-of-magnitude smaller than the actual model size. For example, when inferencing with a 1.3B+MoE-128 model, each input token needs just 1.3 billion parameters, even though the overall model size is 52 billion parameters.
From the worst-case view, the aggregate parameters needed to process a group of tokens can be as large as the full model size, in the example, the entire 52 billion parameters, making it challenging to achieve short latency and high throughput.
Design goals for the DS-MoE inference system
The design goal of our optimizations is to steer the performance toward the best-case view. This requires careful orchestration and partitioning of the model to group and route all tokens with the same critical data path together to reduce data access per device and achieve maximum aggregate bandwidth. An overview of how DS-MoE tackles this design goal by embracing multi-dimensional parallelism inherent in MoE models is illustrated in Figure 3.

DS-MoE inference system is centered around three well-coordinated optimizations:
The DS-MoE Inference system is designed to minimize the critical data path per device and maximize the achievable aggregate memory bandwidth across devices, which is achieved by: 1) expert parallelism and expert-slicing on expert parameters and 2) data parallelism and tensor-slicing for non-expert parameters.
Expert parallelism and expert-slicing for expert parameters: We partition experts across devices, group all tokens of using the same experts under the same critical data path, and parallelize processing of the token groups with different critical paths among different devices using expert parallelism.
In the example of 1.3B+MoE-128, when expert parallelism is equal to 128, each GPU only processes a single token group corresponding to the experts on that device. This results in a sequential path that is 1.3 billion parameters per device, 5x smaller than its quality-equivalent dense model with 6.7B parameters. Therefore, in theory, an MoE-based model has the potential to run up to 5x faster than its quality-equivalent dense model using expert parallelism assuming no communication overhead, a topic we discuss in the next section.
In addition, we propose “expert-slicing” to leverage the concept of tensor-slicing for the parameters within an expert. This additional dimension of parallelism is helpful for latency stringent scenarios that we scale to more devices than the number of experts.
Data parallelism and Tensor-slicing for non-expert parameters: Within a node, we use tensor-slicing to partition the non-expert parameters, leveraging aggregate GPU memory bandwidth of all GPUs to accelerate the processing. While it is possible to perform tensor-slicing across nodes, the communication overhead of tensor-slicing along with reduced compute granularity generally makes inter-node tensor-slicing inefficient. To scale non-expert parameters across multiple nodes, we use data parallelism by creating non-expert parameter replicas processing different batches across nodes that incurs no communication overhead or reduction in compute granularity.
Figure 3 above shows an example scenario for distributed MoE inference highlighting different parts of the MoE model, how the model and data are partitioned, and what form of parallelism is used to deal with each piece.
-
GITHUB
Synthesized Collective Communication Library
Microsoft Collective Communication Library (MSCCL) is a platform to execute custom collective communication algorithms for multiple accelerators supported by Microsoft Azure.
Expert parallelism requires all-to-all communication between all expert parallel devices. By default, DS-MoE uses NCCL for this communication via torch. distributed interface, but we observe major overhead when it is used at scale. To optimize this, we develop a custom communication interface to use Microsoft SCCL and achieve better performance than NCCL. Despite the plug-in optimizations, it is difficult to scale expert parallelism to many devices as the latency increases linearly with the increase in devices. To address this critical scaling challenge, we design two new communication optimization strategies that exploit the underlying point-to-point NCCL operations and custom CUDA kernels to perform necessary data-layout transformations.
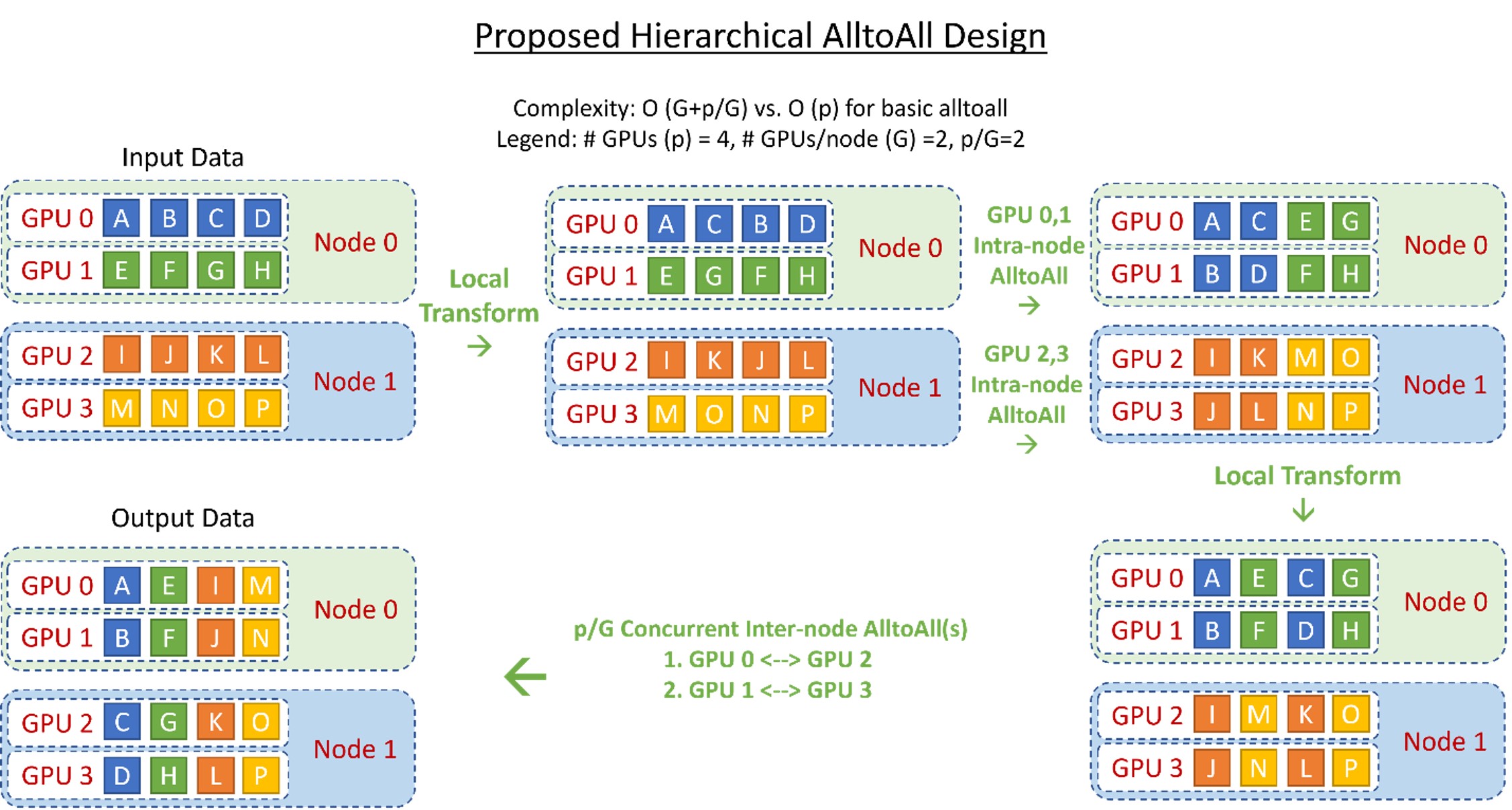
Hierarchical All-to-All: We implement a hierarchical all-to-all as a two-step process with a data-layout transformation, followed by an intra-node all-to-all, followed by a second data-layout transformation and a final inter-node all-to-all. This reduces the communication hops from O (p) to O (G+p/G), where G is the number of GPUs in a node and p is the total number of GPU devices. Figure 4 shows the design overview of this implementation. Despite the 2x increase in communication volume, this hierarchical implementation allows for better scaling for small batch sizes as communication at this message size is more latency-bound than bandwidth-bound.
Parallelism Coordinated Communication Optimization: Combining expert parallelism and tensor-slicing with data parallelism within a single model is non-trivial. Tensor-slicing splits individual operators across GPUs and requires all-reduce between them, while expert parallelism places expert operators across GPUs without splitting them and requires all-to-all between them. By design, a naïve approach to handle these communication steps will be inefficient.

To this end, we propose a novel design, as shown in Figure 5, that performs all-to-all only on a subset of devices that share the same tensor-slicing rank instead of all expert-parallel processes. As a result, the latency of all-to-all can be reduced to O(p/L) instead of O(p) where L is the tensor-slicing parallelism degree. This reduced latency enables us to scale inference to hundreds of GPU devices.
DS-MoE inference system consists of highly optimized kernels targeting both transformer and MoE-related operations. These kernels aim for maximizing the bandwidth utilization by fusing the operations that work in producer-consumer fashion. In addition to computation required for the transformer layers (explained in this blog post), MoE models require the following additional operations:
- a gating function that determines the assignment of tokens to experts, where the result is represented as a sparse tensor.
- a sparse einsum operator, between the one-hot tensor and all the tokens, which sorts the ordering of the tokens based on the assigned expert ID.
- a final einsum that scales and re-sorts the tokens back to their original ordering.
The gating function includes numerous operations to create token-masks, select top-k experts, and perform cumulative-sum and sparse matrix-multiply, all of which are not only wasteful due to the sparse tenor representation, but also extremely slow due to many kernel call invocations. Moreover, the sparse einsums have a complexity of SxExMxc (number of tokens S, number of experts E, model dimension M, and expert capacity c that is typically 1), but E-1 out of E operators for each token are multiplication and addition with zeros.
We optimize these operators using dense representation and kernel-fusion. First, we fuse the gating function into a single kernel, and use a dense token-to-expert mapping table to represent the assignment from tokens to experts, greatly reducing the kernel launch overhead, as well as memory and compute overhead from the sparse representation.
Second, to optimize the remaining two sparse einsums, we implement them as data layout transformations using the above-mentioned mapping table, to first sort them based on the expert id and then back to its original ordering without requiring any sparse einsum, reducing the complexity of these operations from SxExMxc to SxMxc. Combined, these optimizations result in over 6x reduction in MoE kernel related latency.
Low latency and high throughput at unprecedented scale
In modern production environments, powerful DL models are often served using hundreds of GPU devices to meet the traffic demand and deliver low latency. Here we demonstrate the performance of DS-MoE Inference System on a 256 A100 with 40 GB GPUs. Table 3 shows various model configurations used for performance comparisons in this section.
| Model | Size (billions) | # of Layers | Hidden size | Model-Parallel degree | Expert-Parallel degree |
|---|---|---|---|---|---|
| 2.4B+MoE-128 | 107.7 | 16 | 3,584 | 1 | 128 |
| 8B+MoE-128 | 349.0 | 40 | 4,096 | 4 | 128 |
| 24B+MoE-128 | 1,046.9 | 30 | 8,192 | 8 | 128 |
| 47B+MoE-128 | 2,024.0 | 58 | 8,192 | 8 | 128 |
We scale MoE models from 107 billion parameters to 2 trillion parameters. To offer a strong baseline for comparison, we utilize a full-featured distributed PyTorch implementation that is capable of both tensor-slicing and expert-parallelism. Figure 6 shows the results for all these model configurations:
- DeepSpeed MoE achieves up to 7.3x reduction in latency while achieving up to 7.3x higher throughput compared to the baseline.
- By effectively exploiting hundreds of GPUs in parallel, DeepSpeed MoE achieves an unprecedented scale for inference at incredibly low latencies – a staggering trillion parameter MoE model can be inferenced under 25ms.

By combining the system optimizations offered by the DS-MoE inference system and model innovations of PR-MoE and MoS, DeepSpeed MoE delivers two more benefits:
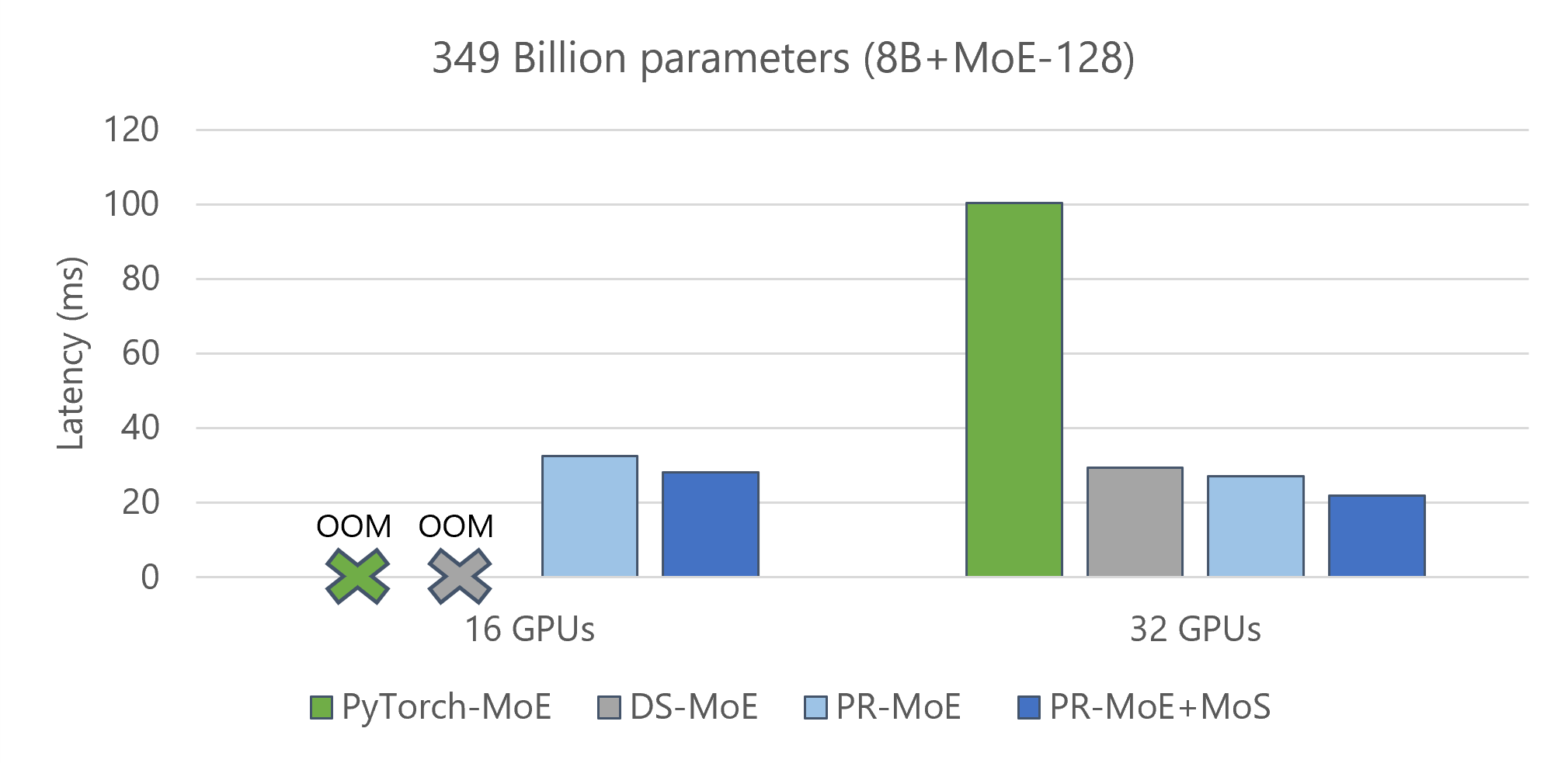
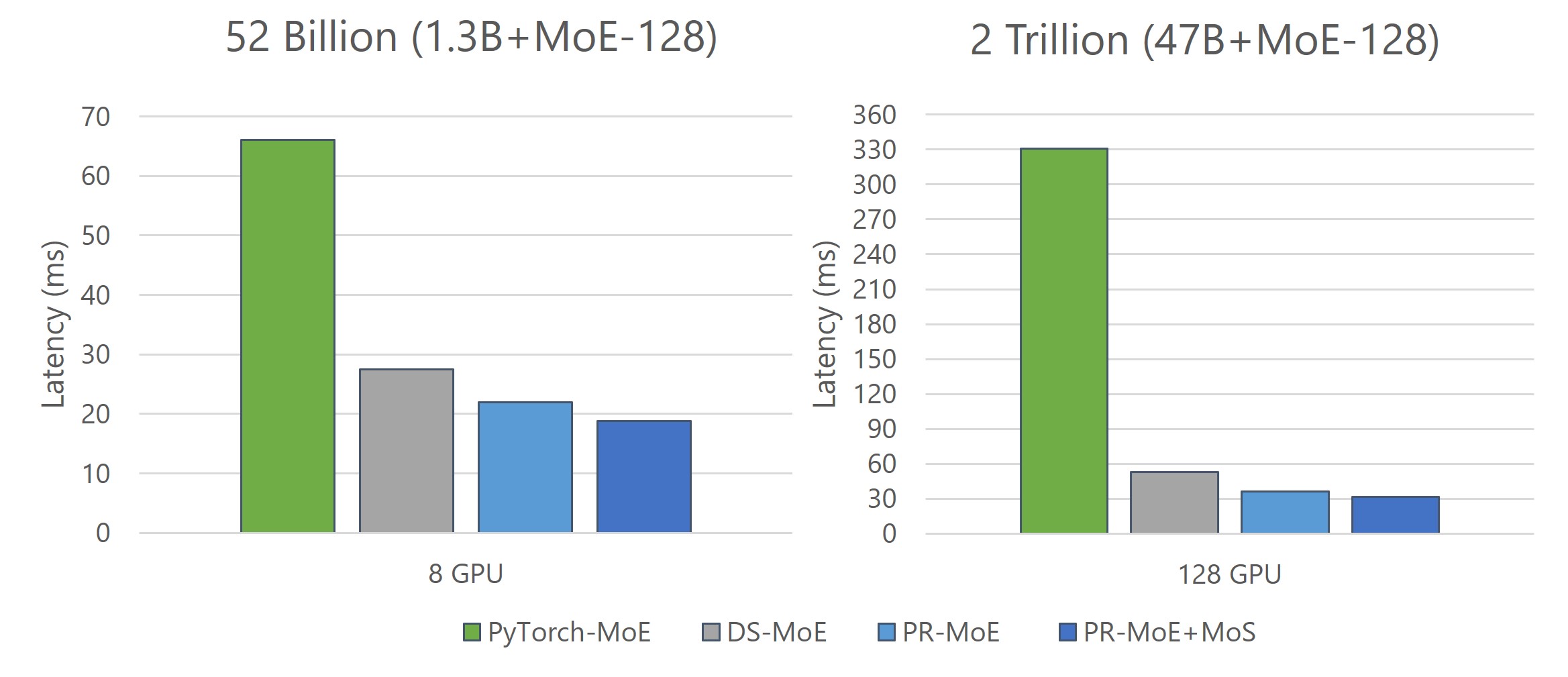
- Reduce the minimum number of GPUs required to perform inference on these models. Figure 7 shows a comparison of three model variants along with the baseline: 1) standard MoE Model (8b-MoE-128), 2) PR-MoE model, and 3) PR-MoE+MoS model. The PR-MoE+MoS model performs the best as expected. The key observation is that the PR-MoE and MoS optimizations allow us to use 16 GPUs instead of 32 GPUs to perform this inference.
- Further improve both latency and throughput of various MoE model sizes (as shown in Figure 8).
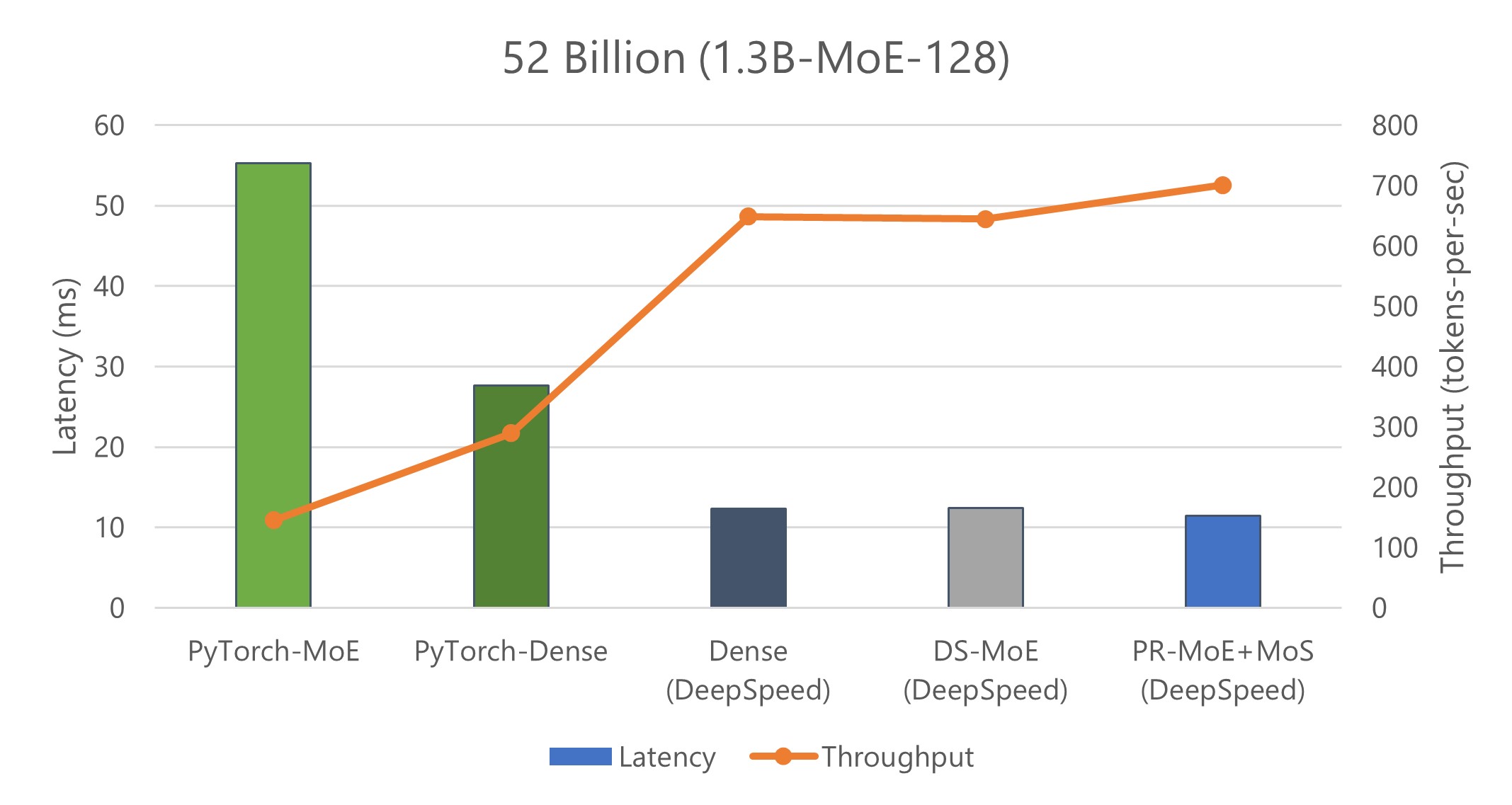
Better inference latency and throughput than quality-equivalent dense models
To better understand the inference performance of MoE models compared to quality-equivalent dense models, it is important to note that although MoE models are 5x faster and cheaper to train, that may not be true for inference. Inference performance has different bottlenecks and its primary factor is the amount of data read from memory instead of computation.
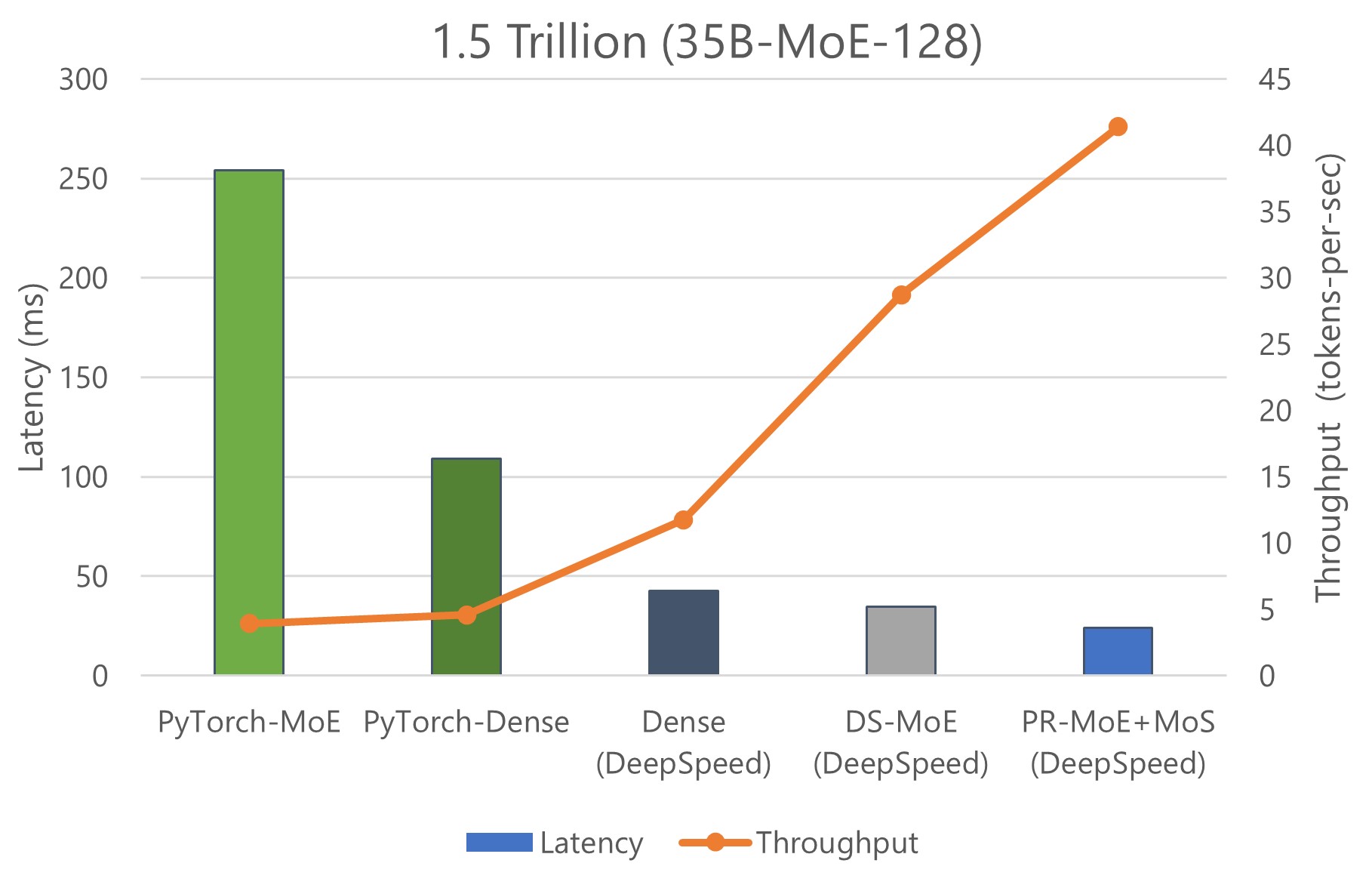
We show inference latency and throughput for two MoE models compared to their quality-equivalent dense models: a) 52 billion-parameter MoE (1.3B-MoE-128) model compared to a 6.7 billion-parameter dense model and b) 1.5 trillion-parameter MoE model compared to a 175 billion-parameter dense model in Figures 9 and 10, respectively.
When using PyTorch, MoE model inference is more expensive and slower compared to its quality-equivalent dense models. This is true for both model sizes. However, the optimizations in DS-MoE reverse this trend and make MoE model inference both faster and cheaper compared to quality-equivalent dense models. This is a critical result, showing MoE’s benefits over dense beyond training but also on inference latency and cost, which is important to real-world deployments.
When comparing the results of Figure 9 with Figure 10, we observe that the benefits of MoE models over dense models become even larger with the increase of model size. While the 52 billion-parameter MoE model is 2.4x faster and cheaper than the 6.7 billion-parameter dense model, the 1.5 trillion-parameter MoE model is 4.5x faster and 9x cheaper than the 175 billion-parameter dense model. The benefits increase for larger models because DS-MoE leverages parallelism-coordinated optimization to reduce communication overhead when using tensor-slicing on non-expert part of model. Furthermore, we can take advantage of expert-slicing at this scale, which enables us to scale to a higher number of GPUs compared to the PyTorch baseline. In addition, for the larger 1.5 trillion-parameter MoE model, we observed 2x additional improvement in throughput over latency as shown in Figure 10. This is because MoE models can run with half the tensor-slicing degree of the dense model (8-way vs. 16-way) and thus two times higher batch size.
Overall, DeepSpeed MoE delivers up to 4.5x faster and up to 9x cheaper MoE model inference compared to serving quality-equivalent dense models using PyTorch. With benefits that scale with model size and hardware resources, as shown from these results, it makes us believe that MoE models will be crucial to bring the next generation of advances in AI scale.
Looking forward to the next generation of AI Scale
With the exponential growth of model size recently, we have arrived at the boundary of what modern supercomputing clusters can do to train and serve large models. It is no longer feasible to achieve better model quality by simply increasing the model size due to insurmountable requirements on hardware resources. The choices we have are to wait for the next generation of hardware or to innovate and improve the training and inference efficiency using current hardware.
We, along with recent literature, have demonstrated how MoE-based models can reduce the training cost of even the largest NLG models by several times compared to their quality-equivalent dense counterparts, offering the possibility to train the next scale of AI models on current generation of hardware. However, prior to this blog post, to our knowledge there have been no existing works on how to serve the MoE models (with many more parameters) with latency and cost better than the dense models. This is a challenging issue that blocks practical use.
To enable practical and efficient inference for MoE models, we offer novel PR-MoE model architecture and MoS distillation technique to significantly reduce the memory requirements of these models. We also offer an MoE inference framework to achieve incredibly low latency and cost at an unprecedented model scale. Combining these innovations, we are able to make these MoE models not just feasible to serve but able to be used for inference at lower latency and cost than their quality-equivalent dense counterparts.
As a whole, the new innovations and infrastructures offer a promising path towards training and inference of the next generation of AI scale, without requiring an increase in compute resources. A shift from dense to sparse MoE models can open a path to new directions in the large model landscape, where deploying higher-quality models is widely possible with fewer resources and is more sustainable by reducing the environmental impact of large-scale AI.
Software: The best place to train and serve models using DeepSpeed is the Microsoft Azure AI platform. To get started with DeepSpeed on Azure, follow the tutorial and experiment with different models using our Azure ML examples. You can also measure your model’s energy consumption using the latest Azure Machine Learning resource metrics.
With this release of DeepSpeed, we are releasing a generic end-to-end framework for training and inference of MoE-based models. The MoE training support and optimizations are made available in full. The MoE inference optimizations will be released in two phases. The generic flexible parallelism framework for MoE inference is being released today. Optimizations related to computation kernels and communication will be released in future.
-
GITHUB
DeepSpeed
DeepSpeed is a deep learning optimization library that makes distributed training easy, efficient, and effective.
To enable experimentation with DeepSpeed MoE optimizations, we are also releasing two extensions of the NLG example that enables 5x reduction in training cost for MT-NLG like models: 1) PR-MoE model extension to enable 3x improvement in parameter efficiency and model size reduction and 2) Model code extensions so users can easily experiment with MoE inference at scale. Please find the code, tutorials, and documents at DeepSpeed GitHub and website.
About our great collaborators
This work was done in collaboration with Brandon Norick, Zhun Liu, and Xia Song from the Turing Team, Young Jin Kim, Alex Muzio, and Hany Hassan Awadalla from the Z-Code Team, and both Saeed Maleki and Madan Musuvathi from the SCCL team.
About the DeepSpeed Team
We are a group of system researchers and engineers—Samyam Rajbhandari, Ammar Ahmad Awan, Jeff Rasley, Reza Yazdani Aminabadi, Minjia Zhang, Zhewei Yao, Conglong Li, Olatunji Ruwase, Elton Zheng, Shaden Smith, Cheng Li, Du Li, Yang Li, Xiaoxia Wu, Jeffery Zhu (PM), Yuxiong He (team lead)—who are enthusiastic about performance optimization of large-scale systems. We have recently focused on deep learning systems, optimizing deep learning’s speed to train, speed to convergence, and speed to develop! If this type of work interests you, the DeepSpeed team is hiring both researchers and engineers! Please visit our careers page.
The post DeepSpeed: Advancing MoE inference and training to power next-generation AI scale appeared first on Microsoft Research.