

Humans manipulate 2D deformable structures such as fabric on a daily basis,
from putting on clothes to making beds. Can robots learn to perform similar
tasks? Successful approaches can advance applications such as dressing
assistance for senior care, folding of laundry, fabric upholstery, bed-making,
manufacturing, and other tasks. Fabric manipulation is challenging, however,
because of the difficulty in modeling system states and dynamics, meaning that
when a robot manipulates fabric, it is hard to predict the fabric’s resulting
state or visual appearance.
In this blog post, we review four recent papers from two research labs (Pieter
Abbeel’s and Ken Goldberg’s) at Berkeley AI Research (BAIR) that
investigate the following hypothesis: is it possible to employ learning-based
approaches to the problem of fabric manipulation?
We demonstrate promising results in support of this hypothesis by using a
variety of learning-based methods with fabric simulators to train smoothing
(and even folding) policies in simulation. We then perform sim-to-real transfer
to deploy the policies on physical robots. Examples of the learned policies in
action are shown in the GIFs above.
We show that deep model-free methods trained from exploration or from
demonstrations work reasonably well for specific tasks like smoothing, but it
is unclear how well they generalize to related tasks such as folding. On the
other hand, we show that deep model-based methods have more potential for
generalization to a variety of tasks, provided that the learned models are
sufficiently accurate. In the rest of this post, we summarize the papers,
emphasizing the techniques and tradeoffs in each approach.
Model-Free Methods
Model-Free Learning without Demonstrations
- Yilin Wu*, Wilson Yan*, Thanard Kurutach, Lerrel Pinto, Pieter Abbeel.
Learning to Manipulate Deformable Objects Without Demonstrations
Robotics: Science and Systems, 2020. Project Website with Code.
In this paper we present a model-free deep reinforcement learning approach
for smoothing cloth. We use a DM Control environment with MuJoCo.
We emphasize two key innovations that help us accelerate training: a factorized
pick-and-place policy, along with learning the place policy conditioned on
random pick points, and then choosing pick point by maximum value. The figure
below shows a visualization.

As opposed to directly learning both the pick and place policy (a), our method
learns each component of a factorized pick-and-place model independently by
first training with a place policy with random pick locations, and then
learning the pick policy.
Jointly training the pick and place policies may result in inefficient
learning. Consider the degenerate scenario when the pick policy collapses into
a suboptimal restrictive set of points. This would inhibit exploration of the
place policy since rewards come only after the pick and place actions are
executed. In order to solve this problem, our method proposes to first use
Soft Actor Critic (SAC), a state-of-the-art model-free deep reinforcement
learning algorithm, to learn a place policy conditioned on pick points sampled
uniformly from valid pick points on the cloth. Then, we characterize the pick
policy by selecting the point with the highest value from the approximated
value estimator learned when training the place policy, thus Maximal Value
under Placing (MVP). We note that our approach is not tied to SAC, and can work
with any off-policy learning algorithm.

An example of real robot cloth smoothing experiments with varying starting
states and cloth colors. Each row shows a different episode from a start state
to the achieved cloth smoothness. We observe that the robot can reach the goal
state from complex start states, and generalizes outside the training data
distribution.
The figure above shows different episodes on a real robot using a
pick-and-place policy learned with our method. The policy is trained in
simulation, and then transferred to a real robot using domain randomization on
cloth physics, color, and lighting. We can see that the learned policy is able
to successfully smooth cloth starting from many different complexities of
state, and for different cloth colors.
The advantages of this paper’s model-free reinforcement learning approach is
that all training can be done in simulation without any demonstrations, and
that training can readily be applied using off-the-shelf algorithms and is
faster due to the pick-and-place structure we present which (as discussed
earlier) can avoid mode collapse. The tradeoff is that it trains a policy that
can only do smoothing, and must be re-trained for other tasks. In addition, the
actions may take relatively short pulls and might be inefficient when it comes
to more difficult cloth tasks such as folding.
Model-Free Learning with Simulated Demonstrations
- Daniel Seita, Aditya Ganapathi, Ryan Hoque, Minho Hwang, Edward Cen, Ajay Kumar Tanwani, Ashwin Balakrishna, Brijen Thananjeyan, Jeffrey Ichnowski, Nawid Jamali, Katsu Yamane, Soshi Iba, John Canny, Ken Goldberg.
Deep Imitation Learning of Sequential Fabric Smoothing From an Algorithmic Supervisor
arXiv 2019. Project Website with Code.
We now present an alternative approach for smoothing fabrics. Like the
prior paper, we use a model-free method and we create an environment for fabric
manipulation using a simulator. Instead of MuJoCo, we use a custom-built
simulator that represents fabric as a $25 times 25$ grid of points. We’ve
open sourced this simulator for other researchers to use.
In this project, we consider a fabric plane as a white background square of
the same size as a fully smooth fabric. The performance metric is coverage,
or how much of the background plane gets covered by the fabric, which
encourages the robot to cover a specific location. We terminate an episode if
the robot attains at least 92% coverage.
One way to smooth fabric is to pull at fabric corners. Since this policy is
easy to define, we code an algorithmic supervisor in simulation and perform
imitation learning using Dataset Aggregation (DAgger). As briefly covered
in a prior BAIR Blog post, DAgger is an algorithm to correct for
covariate shift. It continually queries a supervisor agent to get corrective
actions for states. This is normally a downside for DAgger, but is not a
problem in this case, as we have a simulator with full access to state
information (i.e., the grid of $25times 25$ points) and can determine the
optimal pull action efficiently.
In addition to using color images, we use depth images, which provide a
“height scale.” In a prior BAIR Blog post, we discussed how depth was
useful for various robotics tasks. To obtain images, we use Blender, an
open-source computer graphics toolkit.
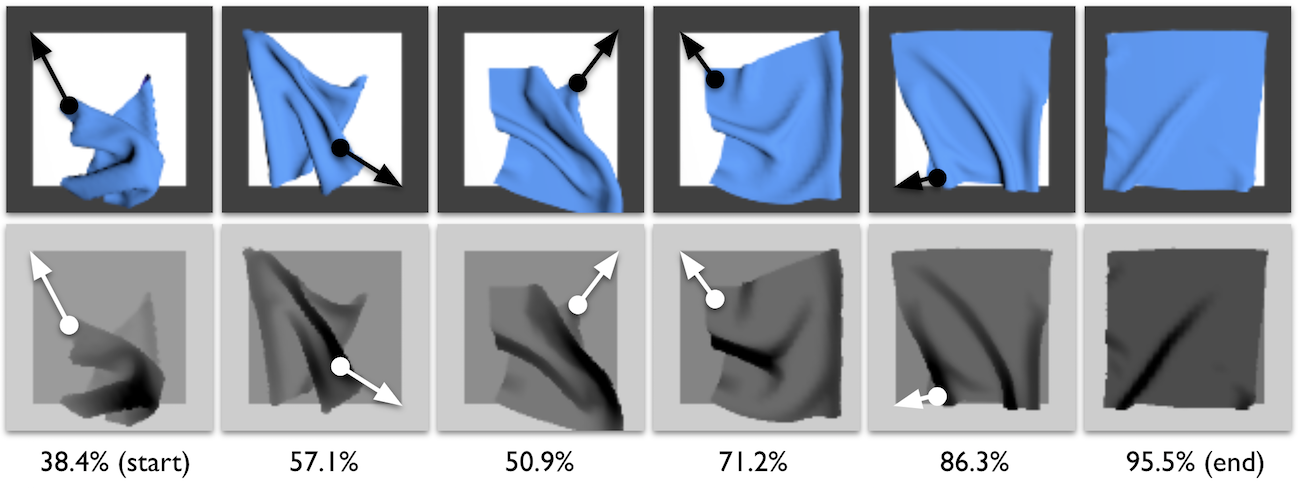
An example episode of our simulated corner-pulling supervisor policy. Each
column of images shows one action, represented by the overlaid white arrows.
While we domain-randomize these images for training, for visualization purposes
in this figure, we leave images at their “default” settings. The starting
state, represented to the left, is highly wrinkled and only covers 38.4% of the
fabric plane. Through a sequence of five pick-and-pull actions, the policy
eventually gets 95.5% coverage.
The figure above visualizes the supervisor’s policy. The supervisor chooses the
fabric corner to pull based on its distance from a known target on the
background plane. Even though fabric corners are sometimes hidden by a top
layer, as in the second time step, the pick-and-pull actions are eventually
able to get sufficient coverage.
After training using DAgger on domain randomized data, we transfer the policy
to a da Vinci Surgical Robot without any further training. The figure
below represents an example episode of the da Vinci pulling and smoothing
fabric.

An example seven-action episode taken by a policy trained only on simulated
RGB-D images. The top row has screenshots of the video of the physical robot,
with overlaid black arrows to visualize the action. The second and third rows
show the color and depth images that are processed as input to be passed
through the learned policy. Despite the highly wrinkled starting fabric, along
with hidden fabric corners, the da Vinci is able to adjust the fabric from
40.1% to 92.2% coverage.
To summarize, we learn fabric smoothing policies using imitation learning with
a supervisor that has access to true state information of the fabrics. We
domain randomize the colors, brightness, and camera orientation on simulated
images to transfer policies to a physical da Vinci surgical robot. The
advantage of the approach is that the robot can efficiently smooth fabric in
relatively few actions and does not require a large workspace, as the training
data consists of long pulls constrained in the workspace. In addition,
implementing and debugging DAgger is relatively easy compared to model-free
reinforcement learning methods as DAgger is similar to supervised learning and
one can inspect the output of the teacher. The primary limitations are that we
need to know how to implement the supervisor’s policy, which can be difficult
for tasks beyond smoothing, and that the learned policy is a smoothing
“specialist” that must be re-trained for other tasks.
Model-Based Methods
Planning Over Image States
- Ryan Hoque*, Daniel Seita*, Ashwin Balakrishna, Aditya Ganapathi, Ajay Kumar
Tanwani, Nawid Jamali, Katsu Yamane, Soshi Iba, Ken Goldberg.
VisuoSpatial Foresight for Multi-Step, Multi-Task Fabric Manipulation.
Robotics: Science and Systems, 2020. Project Website with Code.
While the previous two approaches give us solid performance on the smoothing
task on real robotic systems, the learned policies are “smoothing specialists”
and must be re-trained from scratch for a new task, such as fabric folding. In
this paper, we consider the more general problem of goal-conditioned
fabric manipulation: given a single goal image observation of a desired
fabric state, we want a policy that can perform a sequence of pick-and-place
actions to get from an arbitrary initial configuration to that state.
To do so, we decouple the problem into first learning a model of fabric
dynamics directly from image observations and then re-using that dynamics model
for different fabric manipulation tasks. For the former, we apply the Visual
Foresight framework proposed by our BAIR colleagues, a model-based
reinforcement learning technique that trains a video prediction model to
predict a sequence of images from the image observation of the current state as
well as an action sequence. With such a model, we can predict the results of
taking various action sequences, and can then use planning techniques such as
the cross-entropy method and model-predictive control to plan actions that
minimize some cost function. We use Euclidean distance to the goal image for
the cost function in our experiments.
We generate roughly 100,000 images from an entirely random policy, executed
entirely in simulation. Using the same fabric simulator as in (Seita et al.,
2019), we use Stochastic Variational Video Prediction (SV2P) as the
video prediction model. We leverage both RGB and depth modalities, which we
find in our experiments to outperform either modality alone, and thus call the
algorithm VisuoSpatial Foresight (VSF).
While prior work on Visual Foresight includes some fabric manipulation
results, the tasks considered are typically short horizon and have a wide range
of goal states, such as covering a spoon with a pant leg. In contrast, we focus
on longer horizon tasks that require a sequence of precise pick points. See
the image below for typical test-time predictions from the visual dynamics
model. The data is domain-randomized in color, camera angle, brightness, and
noise, to facilitate transfer to a da Vinci Surgical Robot.

We show the ground truth images as a result of fabric manipulation, each paired
with predictions from the trained video prediction model. Given only a starting
image (not shown), along with the next four actions, the video prediction model
must predict the next four images, shown above.
The predictions are accurate enough for us to plan toward a variety of goal
images. Indeed, our resulting policy rivals the performance of the smoothing
specialists, despite only seeing random images at training time.






We execute a sequence of pick-and-place actions to manipulate fabric toward
some goal image. The top row has three different goal images: smooth, folded,
and doubly folded, which has three layers of fabric stacked in the center in a
particular order. In the bottom row, we show simulated rollouts (shown here as
time-lapses of image observations) of our VSF policy manipulating fabric toward
each of the goal images. The bottom side of the fabric is a darker shade
(slightly darker in the second and much darker in the third column), and the
light patches within the dark are due to self-collisions in the simulator that
are difficult to model.
The main advantage of this approach is that we can train a single neural
network policy to be used for a variety of tasks, each of which are set by
providing a goal image of the target fabric configuration. For example, we can
do folding tasks, for which it may be challenging to hand-code an algorithmic
supervisor, unlike the case of smoothing. The main downsides are that
training a video prediction model is difficult due to the high dimensional
nature of images, and that we typically require more actions than the imitation
learning agent to complete smoothing tasks as the data consists of
shorter-magnitude actions.
Planning Over Latent States
- Wilson Yan, Ashwin Vangipuram, Pieter Abbeel, Lerrel Pinto.
Learning Predictive Representations for Deformable Objects Using Contrastive Estimation.
arXiv 2020. Project Website with Code.
In this paper, we similarly consider a model-based method, but instead of
training a video prediction model to plan in pixel space, we instead plan in a
learned lower-dimensional latent space since learning a video prediction model
can be challenging, as the learned model must capture every detail of the
environment. In addition, it is also difficult to learn proper pixel dynamics
in the cases when we use frame-by-frame domain randomization to transfer to the
real world.
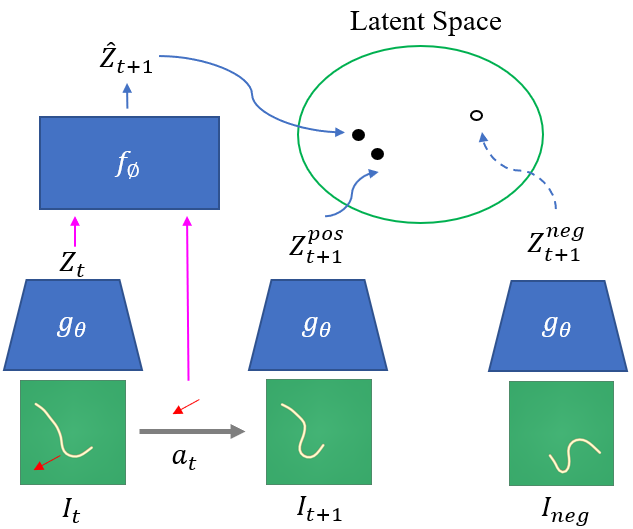
A visual depiction of the contrastive learning framework. Given positive
current-next state pairs and randomly sampled negative observations, we learn
an encoder and forward model such that the estimated next states lie closer
than the negative observations in the latent space.
We jointly learn an encoder and a latent forward model using contrastive
estimation methods. The encoder maps raw images into a lower dimensional latent
space. The latent forward model will take this latent variable, along with the
action, and produce an estimate of the next state.
We train our models by minimizing a variant of the InfoNCE contrastive
loss, which encourages learning latents that maximize mutual information
between encoded latents and their respective future observations. In practice,
this training method will bring current and subsequent latent encodings closer
(in $L_2$ distance), while making other sampled non-next latent encodings to be
further apart. As a result, we are able to use the learned encoder and learned
forward model to effectively predict the future, similar to the image-based
approach presented in the prior paper (Hoque et al., 2020), except we are
not predicting images but latent variables, which are potentially easier to
work with.
In our cloth experiments, we apply random actions to collect 400,000 samples in
a DM Control simulator with added domain randomization on cloth physics,
lighting, and cloth color. We use the learned encoder and forward model to
perform model predictive control (MPC) with one-step prediction to plan towards
a desired goal state image. The figure below shows examples of smoothing out
different colored cloths on a real PR2 robot. Note that the same blue cloth is
used as the goal image regardless of the actual cloth being manipulated. This
indicates that the learned latents have learned to ignore unnecessary
properties of cloth such as color when performing manipulation tasks.
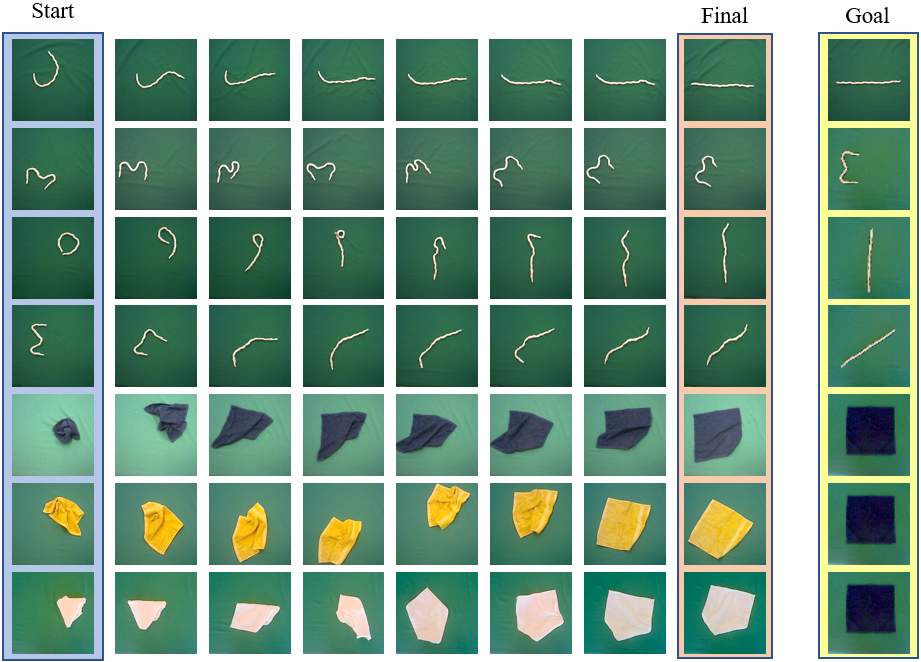
Several episodes of both manipulating rope and cloth using our method, with
different start and goal states. Note that the same blue cloth is used as the
goal state irrespective of the color of the cloth being manipulated
Similar to (Hoque et al., 2020), this method is able to solve multi-task goal
states, as shown in the example episodes above run on a real robot. Using
contrastive methods to learn a latent space, we also achieve better sample
complexity in model learning compared to direct video prediction models,
because the latter require more samples to predict high dimensional images. In
addition, planning directly in latent spaces is easier compared to planning
with a visual model. In our paper, we show that using a simple one-step
model-predictive control to plan in latent spaces works substantially better
than one-step planning with a learned visual forward model, perhaps because the
latents learn to ignore irrelevant aspects of the images. Although planning
allows for cloth spreading and rope orientation manipulation, our models fail
to perform long horizon manipulation since the models are trained on offline
random actions.
Discussion
To recap, we presented four related papers which present different approaches
for robot manipulation of fabrics. Two use model-free approaches (one with
reinforcement learning and one with imitation learning) and two use model-based
reinforcement learning approaches (with either images or latent variables).
Based on what we’ve covered in this blog post, let’s consider possibilities for
future work.
One option is to combine these methods, as done in recent or concurrent work.
For example, (Matas et al., 2018) used model-free reinforcement learning
with imitation learning (through demonstrations) for cloth manipulation tasks.
It is also possible to add other tools from the robotics and computer vision
literature, such as state estimation strategies to enable better
planning. Another potential tool might be dense object descriptors
which indicate correspondence among pixels in two different images. For
example, we have shown the utility of descriptors for a variety of rope
and fabric manipulation tasks.
Techniques such as imitation learning, reinforcement learning,
self-supervision, visual foresight, depth sensing, dense object descriptors,
and particularly the use of simulators, have been useful tools. We believe they
will continue to play an increasing role in robot manipulation of fabrics, and
could be used for more complex tasks such as wrapping items or fitting fabric
to 3D objects.
Reflecting back on our work, another direction to explore could be using these
methods to train six degree-of-freedom grasping. We restricted our setting to
planar pick-and-place policies, and noticed that the robots often had
difficulty with top-down grasps when fabric corners were not clearly exposed.
In these cases, more flexible grasps may be better for smoothing or folding.
Finally, another direction for future work is to address the mismatches we
observed between simulated and physical policy performance. This may be due to
imperfections in the fabric simulators, and it might be possible to use data
from the physical robot to fine-tune the parameters of the fabric simulators to
improve performance.
We thank Ajay Kumar Tanwani, Lerrel Pinto, Ken Goldberg, and Pieter Abbeel for
providing extensive feedback on this blog post.
This research was performed in affiliation with the Berkeley AI Research (BAIR)
Lab, Berkeley Deep Drive (BDD), and the CITRIS “People and Robots” (CPAR)
Initiative. The authors were supported in part by Honda, and by equipment
grants from Intuitive Surgical and Willow Garage.