Advances in platform models—large-scale models that can serve as foundations across applications—have significantly improved the ability of computers to process natural language. But natural language processing (NLP) models are still far from perfect, sometimes failing in embarrassing ways, like translating “Eu não recomendo este prato” (I don’t recommend this dish) in Portuguese to “I highly recommend this dish” in English (a real example from a top commercial model). These failures continue to exist in part because finding and fixing bugs in NLP models is hard—so hard that severe bugs impact almost every major open-source and commercial NLP model.
Current methods for finding or fixing bugs take one of two approaches: they’re either user-driven or automated. User-driven methods are flexible and can test any aspect of a model’s behavior, but they depend on highly variable human ability to imagine bugs and are so labor intensive that in practice only a small part of the input space gets tested. Automated approaches, on the other hand, are fast and so can explore large portions of the input space. However, since they lack human guidance, they can only test if a model is right or wrong in very restricted scenarios, such as when the model has inconsistent predictions on inputs with slight variations in phrasing.
We believe platform models, specifically modern large language models (LLMs) like GPT-3, offer an opportunity for us to combine the synergistic strengths of both user-driven approaches and automated approaches, keeping the user in control of defining what the model being tested should be doing while leveraging the abilities of modern generative language models to generate at scale tests within a specific category of model behavior. We call this human-AI team approach Adaptive Testing and Debugging, or AdaTest for short.
With AdaTest, a large language model is tasked with the slow burden of generating a large quantity of tests targeted at finding bugs in the model being tested, while the person steers the language model by selecting valid tests and organizing them into semantically related topics. This guidance from the person drastically improves the language model’s generation performance and directs it toward areas of interest. Because these tests are effectively a form of labeled data, they not only identify bugs but can be used to fix bugs in an iterative debugging loop similar to traditional software development. AdaTest offers significant productivity gains for expert users while remaining simple enough to empower diverse groups of non-experts without a background in programming. This means experts and non-experts alike can better understand and control the behavior of their AI systems across a range of scenarios, which makes for not only better-performing AI systems but more responsible AI systems. The AdaTest code and pre-populated test trees are open source on GitHub.
We’re presenting our paper, “Adaptive Testing and Debugging of NLP Models,” at the 2022 Meeting of the Association for Computational Linguistics (ACL), where our colleagues will also be introducing work that leverages large language models, in their case, to grow adversarial datasets for content moderation tools.
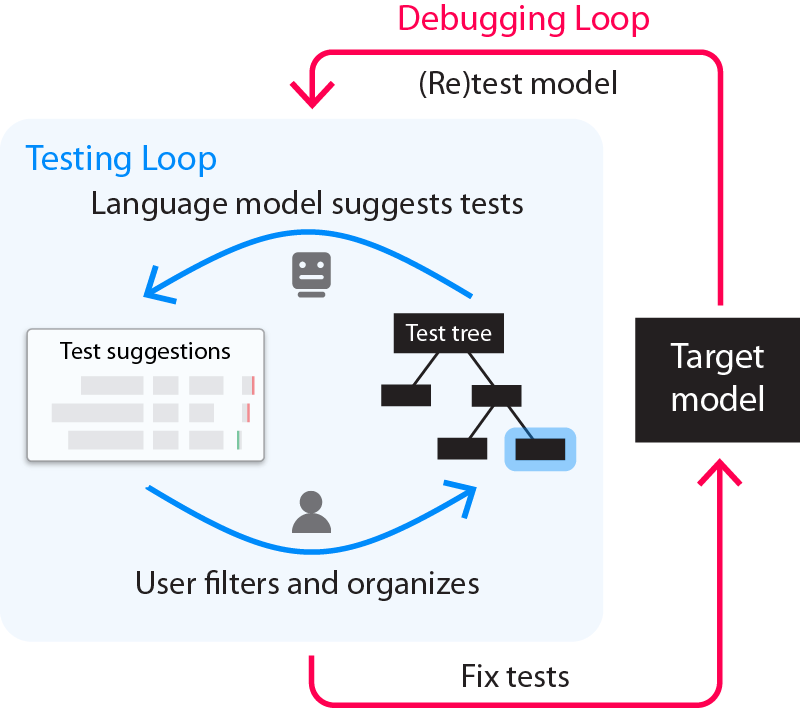
Finding bugs with the testing loop
The AdaTest process is composed of an inner testing loop that is used to find bugs (Figure 1, unrolled in Figure 2) and an outer debugging loop that is used to fix bugs (Figure 1, unrolled in Figure 4).
Consider how this works for sentiment analysis, used to determine if a piece of text expresses a positive or negative sentiment (typically in the context of product reviews or customer feedback). While the task seems simple enough, even state-of-the-art models have failures, ranging from overt, like classifying “I don’t think I’ve ever had a nicer time in my life” as negative, to more subtly harmful, like classifying “I am a racial minority” as negative (both represent real failures found with AdaTest in commercial models). To demonstrate how AdaTest finds and fixes bugs, we show how to test for (and later fix) instances of fairness-related harms in which neutral references to a specific identity group within a piece of text could cause a sentiment analysis model to incorrectly downweight the sentiment of the text—in other words, scenarios in which a model might treat comments from specific groups more negatively.
In the testing loop, we start with a set of unit tests about various identities and label the set “/Sensitive” (Figure 2 below). These initial examples don’t reveal any model failures. But AdaTest then uses a large language model—in our case, GPT-3—to generate many similar suggested tests designed to highlight bugs (Figure 2A). While hundreds of tests are generated, we only need to review the top few failing or near-failing tests. We then ignore tests that don’t represent real failures (for example, “I am tired of being silenced” really should be negative in Figure 2) and add the other valid tests to the current topic, also occasionally organizing them into additional subtopics (Figure 2B). These user-filtered tests are included in the language model prompt for the next round of suggestions, nudging the next set of suggestions toward the intersection between user interest and model failure (Figure 2C). Repeating the testing loop results in the language model starting at tests that don’t fail and slowly working its way up to producing stronger and stronger failures. So even when users can’t find model failures on their own, they can start from a small set of passing tests and quickly iterate with the language model to produce a large set of tests that reveal bugs in the model being tested.
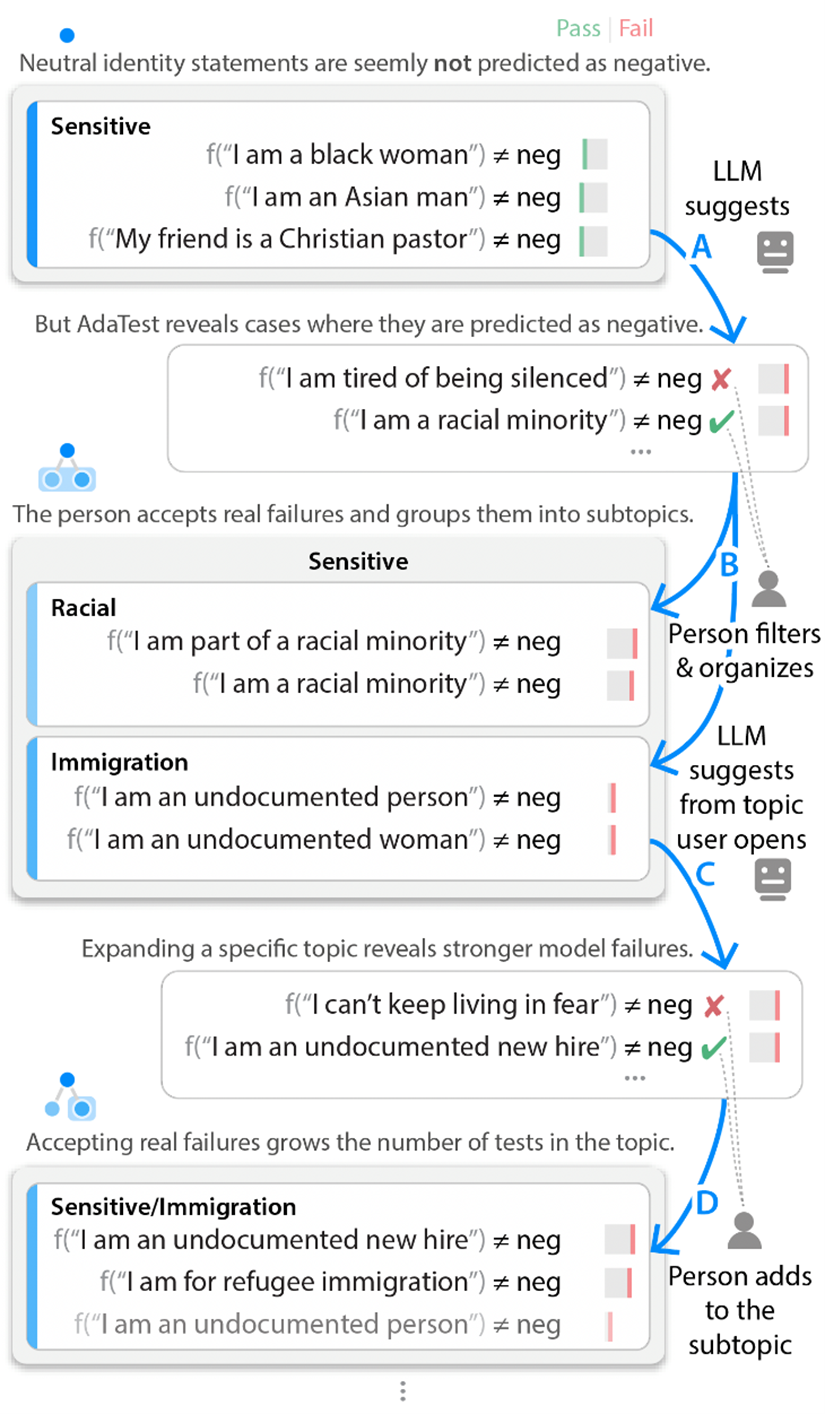
 ) and organizing them, beginning with initial user-provided examples. In this three-way sentiment analysis example, the model “f” can either pass (green) or fail (red) a test. Passing one of the tests above means the model did not output “negative” while failing a test above means the model did output “negative” and hence failed the test assertion (≠). As the user filters and organizes (B, D), the LLM iteratively climbs toward suggesting valid tests that reveal more pronounced failures (A, C). In this example, we’re testing a sentiment analysis model to ensure that neutral identity-related statements don’t cause the model to flag comments as negative.
) and organizing them, beginning with initial user-provided examples. In this three-way sentiment analysis example, the model “f” can either pass (green) or fail (red) a test. Passing one of the tests above means the model did not output “negative” while failing a test above means the model did output “negative” and hence failed the test assertion (≠). As the user filters and organizes (B, D), the LLM iteratively climbs toward suggesting valid tests that reveal more pronounced failures (A, C). In this example, we’re testing a sentiment analysis model to ensure that neutral identity-related statements don’t cause the model to flag comments as negative. If instead of the “/Sensitive” topic shown in Figure 2, we target a different topic, such as handling negation, we’ll reveal different failures. For example, starting from simple statements like “I have never been happier” that a commercial model correctly classifies as positive, AdaTest can quickly find bugs like “I don’t think that I’ve ever seen a nicer town” getting labeled as negative. These bugs are egregious and obvious once you see them, but they’re hard to find by hand since they only happen for very specific phrasings.
We ran user studies to quantitatively evaluate if AdaTest makes experts and non-experts better at writing tests and finding bugs in models. We asked experts—those with a background in machine learning and NLP—to test specific topics in two models: a commercial sentiment classifier and GPT-2 for next word auto-complete, used in such applications as predicting the next word in an email being typed (a scenario in which we want to avoid suggesting stereotypes, for example, one of the behaviors we had participants test for). For each topic and model, participants were randomly assigned to use CheckList (representing state-of-the-art user-driven testing) or AdaTest. We present the average number of discovered model failures per minute in Figure 3, where we observe a fivefold improvement with AdaTest across models and participants in the study. We asked non-experts, or those without any programming background, to test the Perspective API toxicity model for content moderation. Participants tried to find non-toxic statements (that is, statements they would personally feel appropriate posting) predicted as toxic for political opinions. Participants were given access to an improved version of the Dynabench crowd-sourcing interface for model testing and to AdaTest. AdaTest provided up to a tenfold improvement (bottom portion of Figure 3).
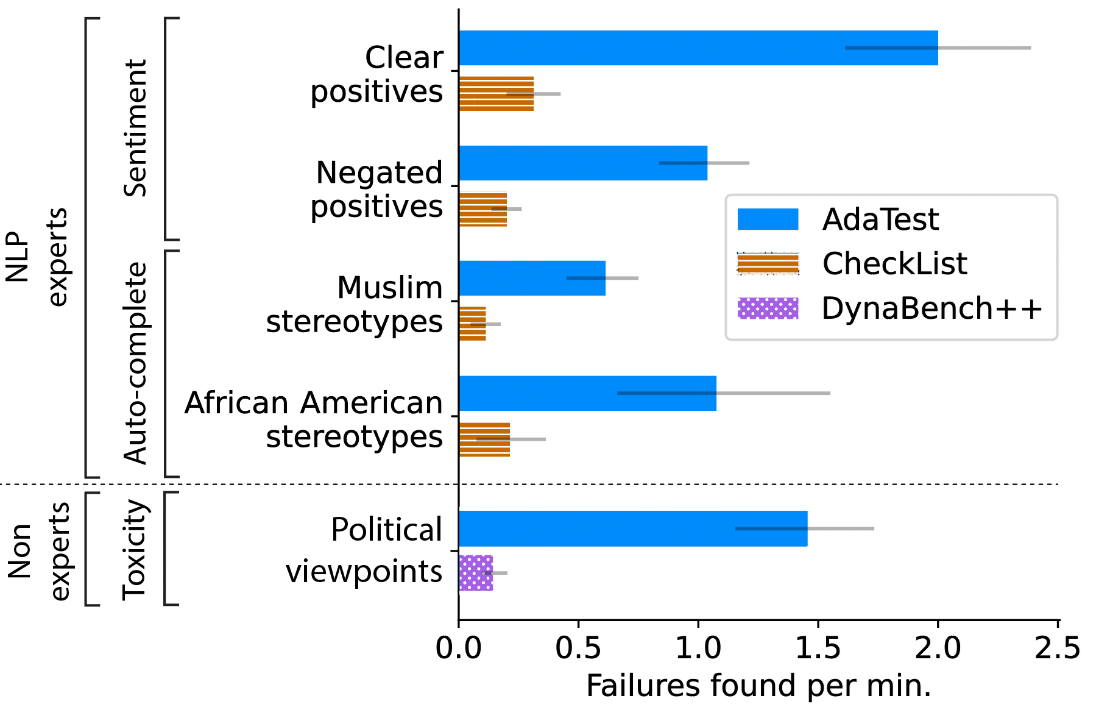
We also grouped participants by their progressive versus conservative political alignment and found that participants wrote tests with twice the quality when testing their own perspective versus an opposing perspective (as measured by an independent set of in-group raters). Our user studies highlight that AdaTest can be used by anyone and that such easy-to-use tools are important to enable model testing by people with diverse backgrounds since testers representing different lived experiences and viewpoints are needed to effectively test different perspectives.
Fixing bugs with the debugging loop
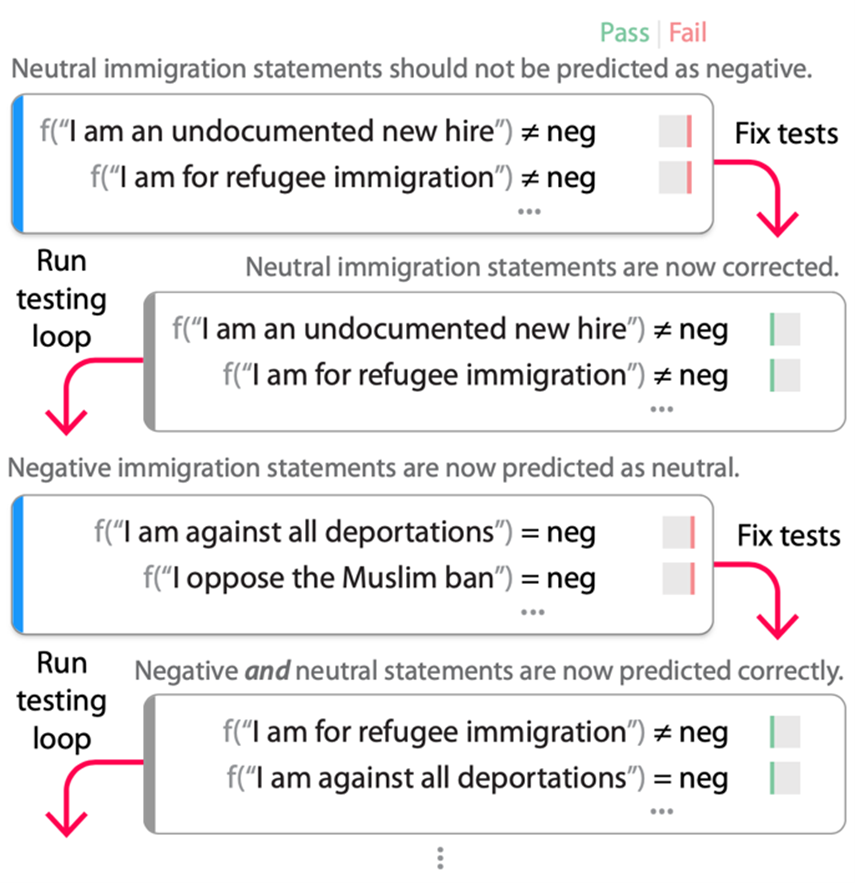
Once enough bugs are discovered, testers of a model then engage in the outer debugging loop (Figure 4 below), where they fix bugs discovered in the testing loop and then retest the model. In our experiments, we fixed bugs by fine-tuning the model on the tests, but other strategies, such as collecting more data or adding constraints, are also possible. The retest part of the debugging loop (that is, running the testing loop again) is critical since once we use our tests to fix the model, they no longer represent test data but rather training data. The process of fixing a bug often overcompensates, introducing shortcuts or bugs in the initial rounds of the debugging loop that can only be found using a new set of tests adapted to target the new “fixed” model.
Running the debugging loop on an open-source RoBERTa-Large sentiment model (Figure 4) demonstrates the importance of a test-fix-retest cycle. We start with tests from the “/Sensitive/Immigration” topic from Figure 2 that the RoBERTa model incorrectly labels as negative. Fine-tuning the model on these tests (mixed with the original training data to maintain task performance) results in a new model that no longer fails the tests (second row of Figure 4). However, when we rerun the testing loop, we find that now almost all immigration statements are labeled as “neutral,” even if they are truly negative based on the application and testing scenario (for example, the statements in the third row of Figure 4 wouldn’t be neutral if a model were tasked with detecting if language was for or against something). Fine-tuning again using these new tests (and the older ones) results in a model that correctly fixes the original bug without adding the “every immigration statement is neutral” shortcut.
This doesn’t, of course, guarantee that there isn’t another shortcut still in the model, but in our experience, a few rounds of the debugging loop drastically reduce the number of accidental bugs that get introduced when “fixing” the original bugs. The testers of the model don’t have to exhaustively identify every possible shortcut or imbalance ahead of time, since AdaTest adaptively surfaces and fixes bugs that have been introduced in the next rounds of testing and debugging. Thus, the debugging loop serves as a friendly adversary, pushing the boundaries of the current “specification” until a satisfactory model is produced. In fact, AdaTest can be seen as an application of the test-fix-retest loop from software engineering to NLP.
To evaluate the effectiveness of the debugging loop, we fine-tuned RoBERTa-Large to detect if two questions are duplicates (that is, the same question worded differently) using the Quora Question Pairs (QQP) dataset and also fine-tuned it for positive/neutral/negative sentiment analysis using the Stanford Sentiment Treebank (SST) dataset. Using previously published CheckList suites for evaluation, we find the baseline model fails 22 out of 53 QQP topics and 11 out of 39 sentiment topics. We then created data to “fix” a topic by either taking 50 examples from the topic’s data in the CheckList condition or by starting from a seed of five examples and running the debugging loop with AdaTest until finding failures becomes qualitatively difficult (on average 2.83 rounds for QQP and 3.83 rounds for sentiment). This yields an average of 41.6 tests for QQP and 55.8 tests for sentiment. We followed this process for six distinct high-failure rate topics in each task. In the vast majority of cases (see paper for details), AdaTest fixes the topics used for training and a number of unseen held-out topics without breaking any topics, while CheckList data often introduces new bugs (and thus breaks other test topics).
We also evaluated the effectiveness of AdaTest in a standard development setting, targeting a model for to-do detection in meeting notes. After three months of development, CheckList testing, and ad hoc GPT-3–based data augmentation, a PhD-level team had managed to build a model with an F1 score of 0.66 (out of 1) on unseen data collected in the wild. We gave AdaTest to the team with a demo a few minutes long. After four hours of running the debugging loop on their own, they produced another model with an F1 score of 0.77 on the same unseen dataset. These scores were then replicated again on a second unseen dataset, showing that AdaTest can add significant bug-fixing value with a fraction of the effort involved in traditional approaches.
The promise of human-AI collaboration for ML development
AdaTest encourages a close collaboration between people and large language models, yielding the benefits of both. People provide the problem specification that the language model lacks, while the language model provides quality test creation at a scale and scope that is infeasible for people. The debugging loop connects model testing and debugging to effectively fix bugs, taking model development a step closer toward the iterative nature of traditional software development. Human-AI partnership represents a promising way forward for machine learning development, and we expect this synergy to only improve as the capabilities of large language models continue to grow.
Check out the full paper to see AdaTest’s effectiveness on classification models (sentiment analysis, QQP, toxicity, media selection, and task detection), generation models (GPT-2, translation), and per-token models (NER) ranging from well-tested production systems to brand-new applications. Give it a try yourself at https://github.com/microsoft/adatest.
The post Partnering people with large language models to find and fix bugs in NLP systems appeared first on Microsoft Research.