
Welcome to Research Focus, a new series of blog posts that highlights notable publications, events, code/datasets, new hires and other milestones from across the research community at Microsoft.
Microsoft Turing Universal Language Representation model, T-ULRv6, tops both XTREME and GLUE leaderboards with a single model
Barun Patra, Saksham Singhal, Shaohan Huang, Zewen Chi, Li Dong, Furu Wei, Vishrav Chaudhary, Xia Song
The most recent addition to Microsoft’s Turing Universal Language Representation Model family (T-ULRv6) has achieved the top position on both the Google XTREME and GLUE leaderboards, the first time that a single multilingual model has demonstrated state-of-the-art capabilities in both English and multilingual understanding tasks. The result of a collaboration between the Microsoft Turing team and Microsoft Research, the T-ULRv6 XXL model is based on “XY-LENT,” which leverages X-Y (non-English Centric) bitexts and incorporates the key innovations of XLM-E, the improved training data and vocabulary, and the advanced fine-tuning technique of XTune. Furthermore, to enable scaling to XXL sized models, T-ULRv6 leverages the memory optimization benefits afforded by ZeRO. To effectively utilize X-Y bitexts, the team adopted a novel sampling strategy and reconstructed the vocabulary using VoCap, which ensures an efficient distribution of data across languages and helps mitigate sparse sampling distributions from previous works. The XXL model variant outperforms both XLM-R XXL and mT5 XXL while being ~2x and ~3x smaller, respectively.
T-ULRv6 powers the language universalization of Microsoft Bing, enabling users to search and discover information across languages and domains. T-ULRv6 will soon enhance other Microsoft products with its multilingual capabilities.
XTREME, or Cross-lingual TRansfer Evaluation of Multilingual Encoders, is a benchmark covering 40 typologically diverse languages across 12 language families, with nine tasks that require reasoning about syntax or semantics.
GLUE – or the General Language Understanding Evaluation benchmark – is a collection of resources for training, evaluating, and analyzing natural language understanding systems.
Skip slideshow for:
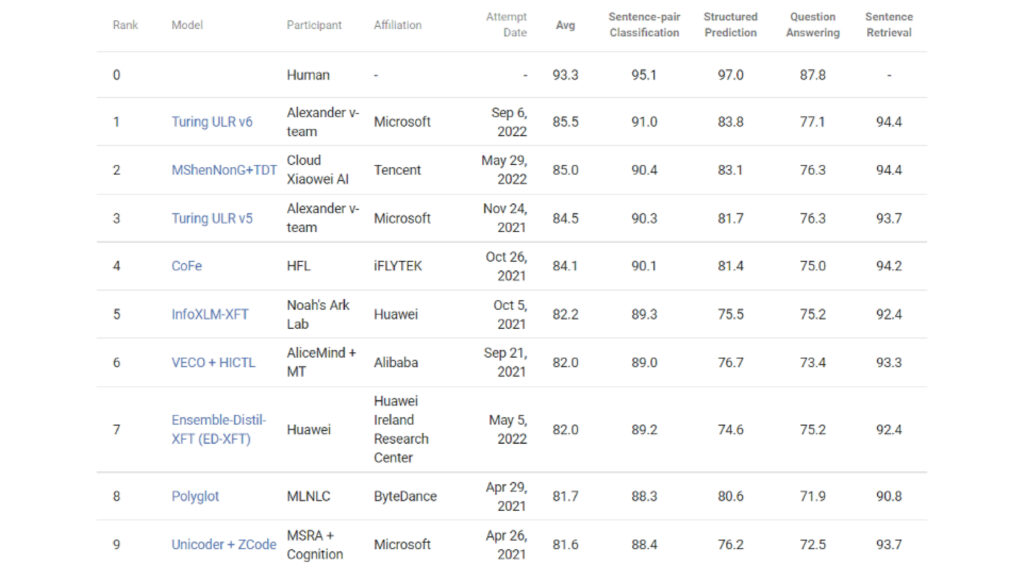
Microsoft’s TULR v6 sits at the top of the XTREME leader board as of Nov. 4, 2022
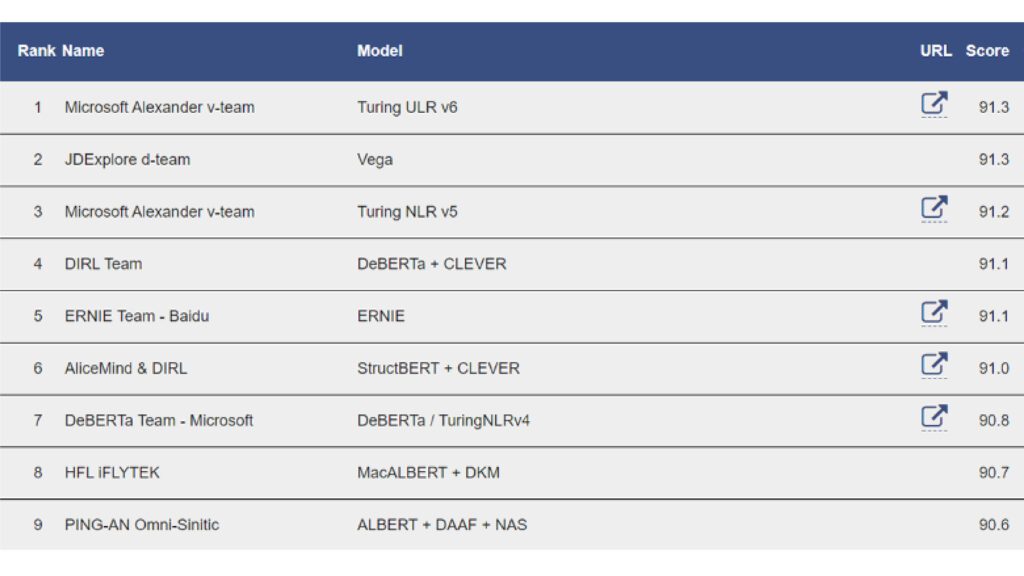
Microsoft’s TULR v6 sits at the top of the XTREME/GLUE leader board as of Nov. 4, 2022
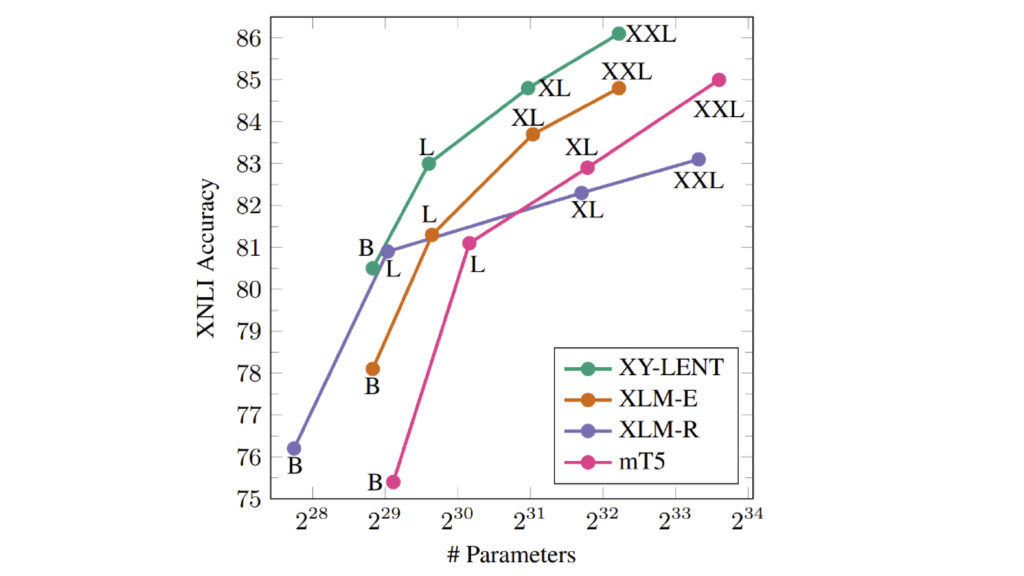
T-ULRv6 (XY-LENT) is state of the art within model size bands while being parameter efficient
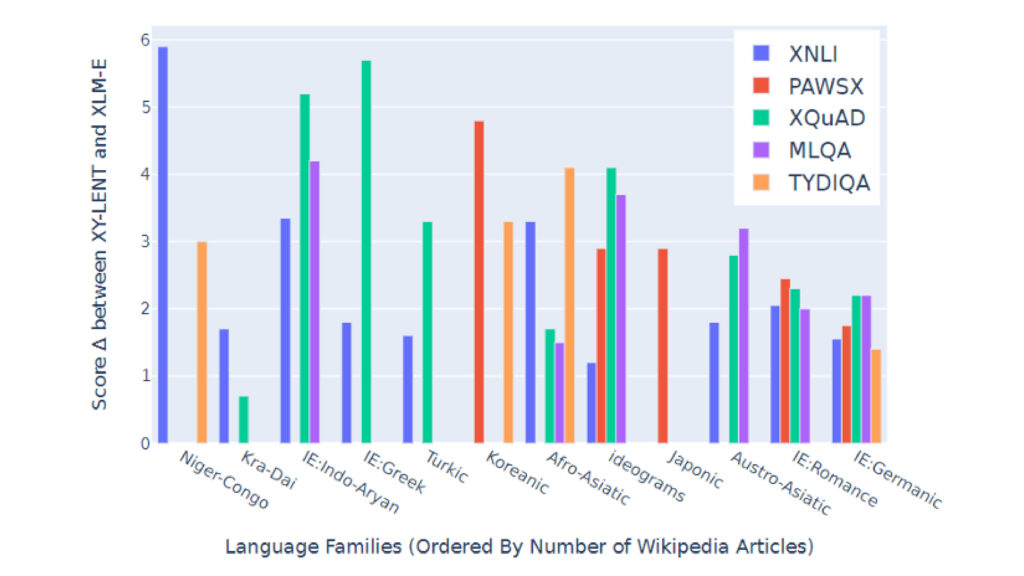
T-ULRv6 (XY-LENT) demonstrating strong performance across language families for a variety of tasks
PACT: Perception-Action Causal Transformer for autoregressive robotics pretraining
Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Frujeri, Shuhang Chen, Ashish Kapoor
Recent advances in machine learning architectures have induced a paradigm shift from task-specific models towards large general-purpose networks. For instance, in the past few years we have witnessed a revolution in the domains of natural language and computer vision with models such as GPT-3, BERT and DALL-E. The field of robotics is still mostly riddled with single-purpose systems architectures whose modules and connections, whether traditional or learning-based, require significant human design expertise. Inspired by these large pre-trained models, this work introduces a general-purpose robotics representation that can serve as a starting point for multiple tasks for a mobile agent, such as navigation, mapping and localization.
We present the Perception-Action Causal Transformer (PACT), a generative transformer-based architecture that aims to build representations directly from robot data in a self-supervised fashion. Through autoregressive prediction of states and actions over time, our model implicitly encodes dynamics and behaviors for a particular robot. This representation can then function as a single starting point to achieve distinct tasks through fine-tuning with minimal data.
Microsoft Research and NHS Scotland conduct world’s first clinical trials of Holoportation -based 3D telemedicine system to increase access to healthcare
-based 3D telemedicine system to increase access to healthcare
Steven Lo, Spencer Fowers, Kwame Darko, Thiago Spina, Catriona Graham, Andrea Britto, Anna Rose, David Tittsworth, Aileen McIntyre, Chris O’Dowd, Roma Maguire, Wayne Chang, David Young, Amber Hoak, Robin Young, Mark Dunlop, Levi Ankrah, Martina Messow, Opoku Ampomah, Ben Cutler, Roma Armstrong, Ruchi Lalwani, Ruairidh Davison, Sophie Bagnall, Whitney Hudson, Mike Shepperd, Jonny Johnson, 3DTM (3D Telemedicine) Collaborative research group
The Covid pandemic has increased the usage of remote health consultations and underscored the need for a better system. Current 2D telemedicine engagements fail to replicate the fluency or authenticity of in-person consultations. Real-time 3D telemedicine has previously been proposed within a research setting only, with constraints on complexity, bandwidth and technology.
This research reports on an international collaboration on the participatory development and first validated clinical use of a novel, real-time 360-degree 3D telemedicine system worldwide. NHS Greater Glasgow and Clyde have been working with Microsoft since 2019 to assess how health care could leverage Microsoft’s 3D telemedicine, focusing on plastic surgery patients and leveraging Microsoft’s Holoportation communication technology.
This research was designed to compare validated outcome measures of a patient-centered 3D telemedicine system with a 2D system, assess alignment with an in-person consultation, and to ensure safety, reliability and clinical concordance. In three separate studies, the 3D system improved patient metrics in comparison to 2D telemedicine, suggesting that remote consultations could get closer to the experience of face-to-face consultations.
Interactive code generation via test-driven user-intent formalization
Shuvendu Lahiri, Aaditya Naik, Georgios Sakkas, Piali Choudhury, Curtis von Veh, Madan Musuvathi, Jeevana Priya Inala, Chenglong Wang, Jianfeng Gao
Automatic code generation from natural language intent using large language models is disrupting coding. However, the correctness of the resulting code with respect to user intent expressed in natural language is difficult to establish because natural language lacks formal semantics. In this project, we investigate the problem of neural specification generation (i.e., generating partial formal specifications that match the intent expressed in natural language), and incorporating such specifications during the coding process to improve trust in human-written or AI-generated code.
We instantiate this framework starting with unit tests; tests serve as weak yet formal specifications of a module. We can leverage the abundance of human-written unit tests to train models. Further, these specifications (tests) can be checked using concrete execution without the need for more sophisticated abstract interpreters. In prior work on TOGA, we demonstrated a neural model for synthesizing test oracles for a method and illustrated its use in finding functional bugs in code. In this work on TiCoder, we describe an interactive workflow to formalizing the informal user-intent through such model-generated tests and improving the accuracy, correctness and understanding of generated code.
The post Research Focus: Week of November 7, 2022 appeared first on Microsoft Research.