We recently published the Berkeley Crossword Solver (BCS), the current state of the art for solving American-style crossword puzzles. The BCS combines neural question answering and probabilistic inference to achieve near-perfect performance on most American-style crossword puzzles, like the one shown below:

Figure 1: Example American-style crossword puzzle
An earlier version of the BCS, in conjunction with Dr.Fill, was the first computer program to outscore all human competitors in the world’s top crossword tournament. The most recent version is the current top-performing system on crossword puzzles from The New York Times, achieving 99.7% letter accuracy (see the technical paper, web demo, and code release).
Crosswords are challenging for humans and computers alike. Many clues are vague or underspecified and can’t be answered until crossing constraints are taken into account. While some clues are similar to factoid question answering, others require relational reasoning or understanding difficult wordplay.
Here are a handful of example clues from our dataset (answers at the bottom of this post):
- They’re given out at Berkeley’s HAAS School (4)
- Winter hrs. in Berkeley (3)
- Domain ender that UC Berkeley was one of the first schools to adopt (3)
- Angeleno at Berkeley, say (8)
Our Approach
The BCS uses a two-step process to solve crossword puzzles. First, it generates a probability distribution over possible answers to each clue using a question answering (QA) model; second, it uses probabilistic inference, combined with local search and a generative language model, to handle conflicts between proposed intersecting answers.
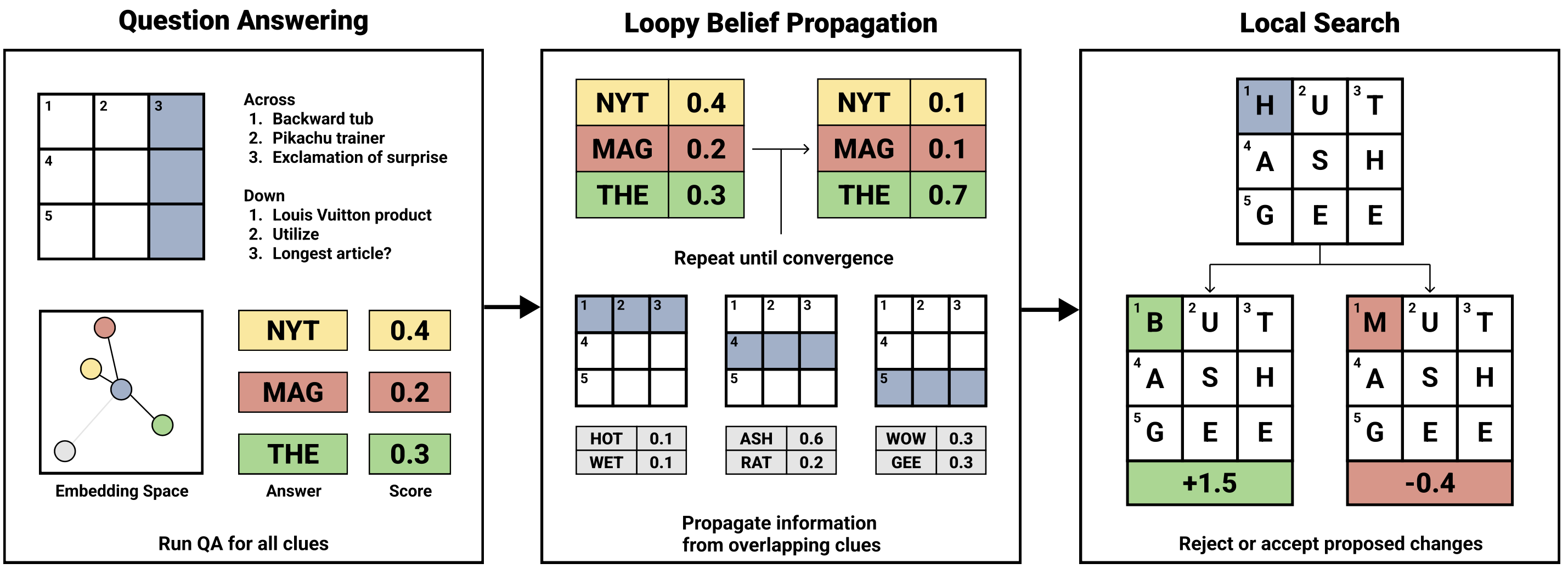
Figure 2: Architecture diagram of the Berkeley Crossword Solver
The BCS’s question answering model is based on DPR (Karpukhin et al., 2020), which is a bi-encoder model typically used to retrieve passages that are relevant to a given question. Rather than passages, however, our approach maps both questions and answers into a shared embedding space and finds answers directly. Compared to the previous state-of-the-art method for answering crossword clues, this approach obtained a 13.4% absolute improvement in top-1000 QA accuracy. We conducted a manual error analysis and found that our QA model typically performed well on questions involving knowledge, commonsense reasoning, and definitions, but it often struggled to understand wordplay or theme-related clues.
After running the QA model on each clue, the BCS runs loopy belief propagation to iteratively update the answer probabilities in the grid. This allows information from high confidence predictions to propagate to more challenging clues. After belief propagation converges, the BCS obtains an initial puzzle solution by greedily taking the highest likelihood answer at each position.
The BCS then refines this solution using a local search that tries to replace low confidence characters in the grid. Local search works by using a guided proposal distribution in which characters that had lower marginal probabilities during belief propagation are iteratively replaced until a locally optimal solution is found. We score these alternate characters using a character-level language model (ByT5, Xue et al., 2022), that handles novel answers better than our closed-book QA model.
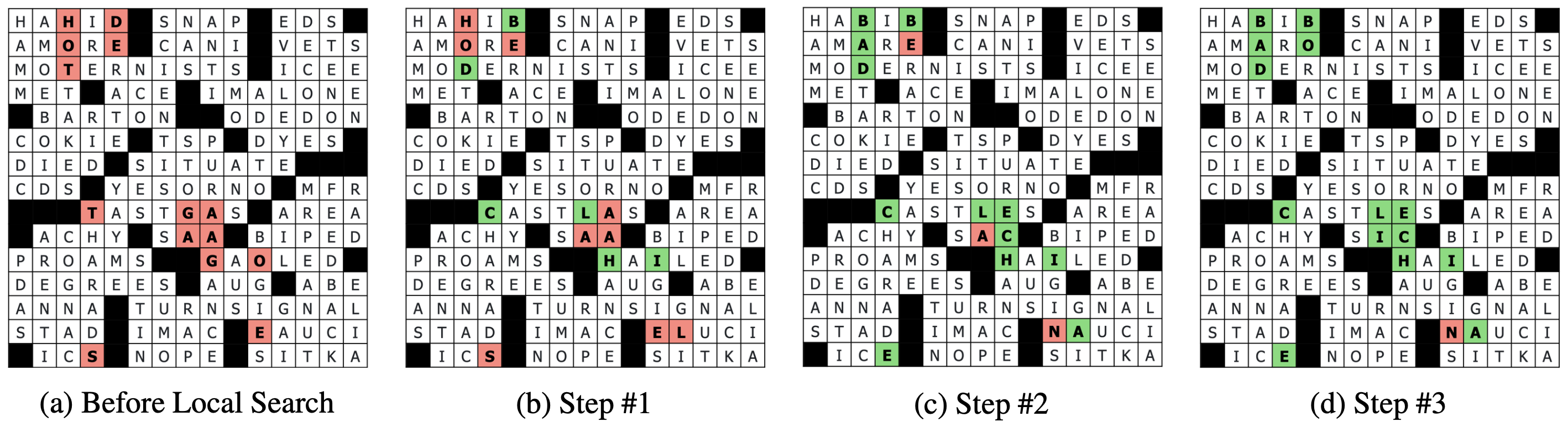
Figure 3: Example changes made by our local search procedure
Results
We evaluated the BCS on puzzles from five major crossword publishers, including The New York Times. Our system obtains 99.7% letter accuracy on average, which jumps to 99.9% if you ignore puzzles that involve rare themes. It solves 81.7% of puzzles without a single mistake, which is a 24.8% improvement over the previous state-of-the-art system.
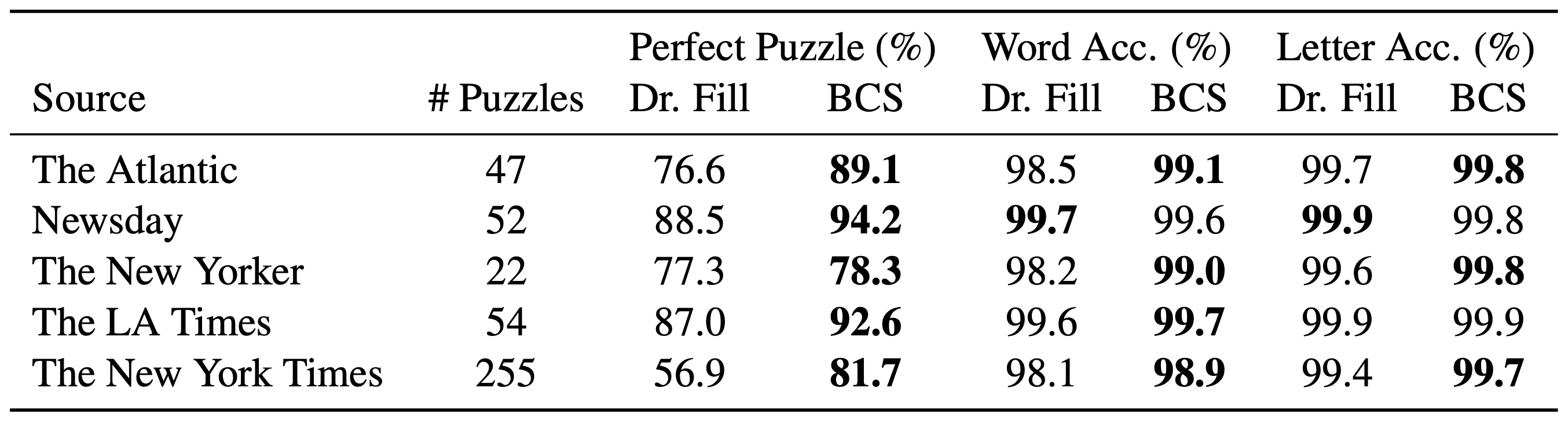
Figure 4: Results compared to previous state-of-the-art Dr.Fill
Winning The American Crossword Puzzle Tournament
The American Crossword Puzzle Tournament (ACPT) is the largest and longest-running crossword tournament and is organized by Will Shortz, the New York Times crossword editor. Two prior approaches to computer crossword solving gained mainstream attention and competed in the ACPT: Proverb and Dr.Fill. Proverb is a 1998 system that ranked 213th out of 252 competitors in the tournament. Dr.Fill’s first competition was in ACPT 2012, and it ranked 141st out of 650 competitors. We teamed up with Dr.Fill’s creator Matt Ginsberg and combined an early version of our QA system with Dr.Fill’s search procedure to outscore all 1033 human competitors in the 2021 ACPT. Our joint submission solved all seven puzzles in under a minute, missing just three letters across two puzzles.
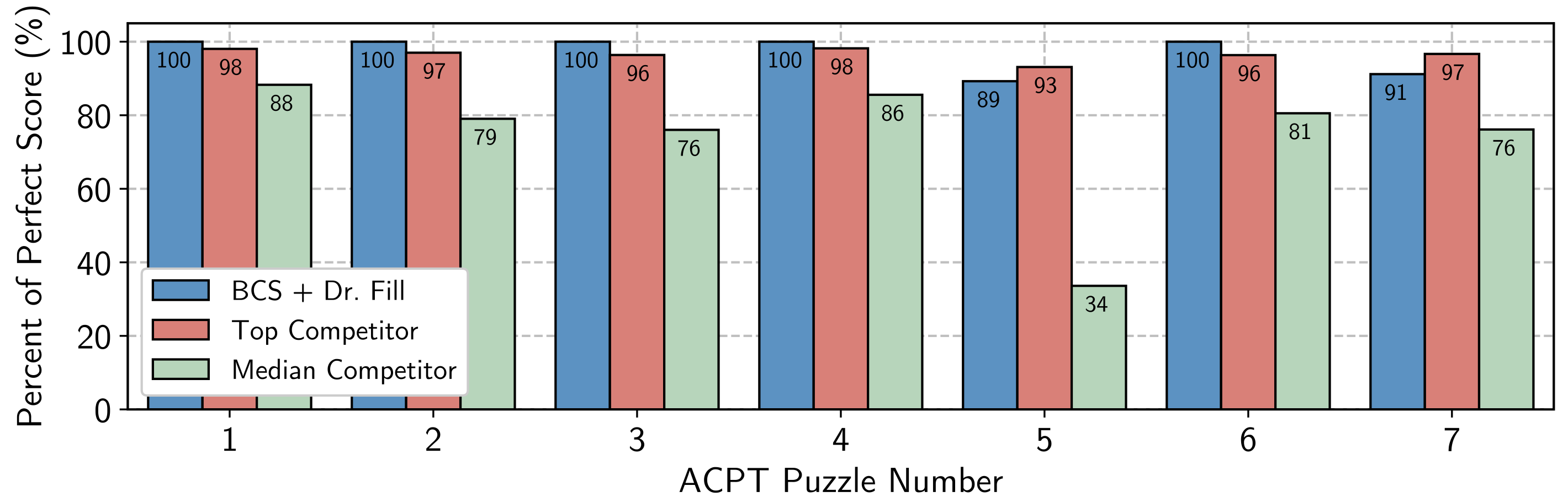
Figure 5: Results from the 2021 American Crossword Puzzle Tournament (ACPT)
We are really excited about the challenges that remain in crosswords, including handling difficult themes and more complex wordplay. To encourage future work, we are releasing a dataset of 6.4M question answer clues, a demo of the Berkeley Crossword Solver, and our code at http://berkeleycrosswordsolver.com.
Answers to clues: MBAS, PST, EDU, INSTATER