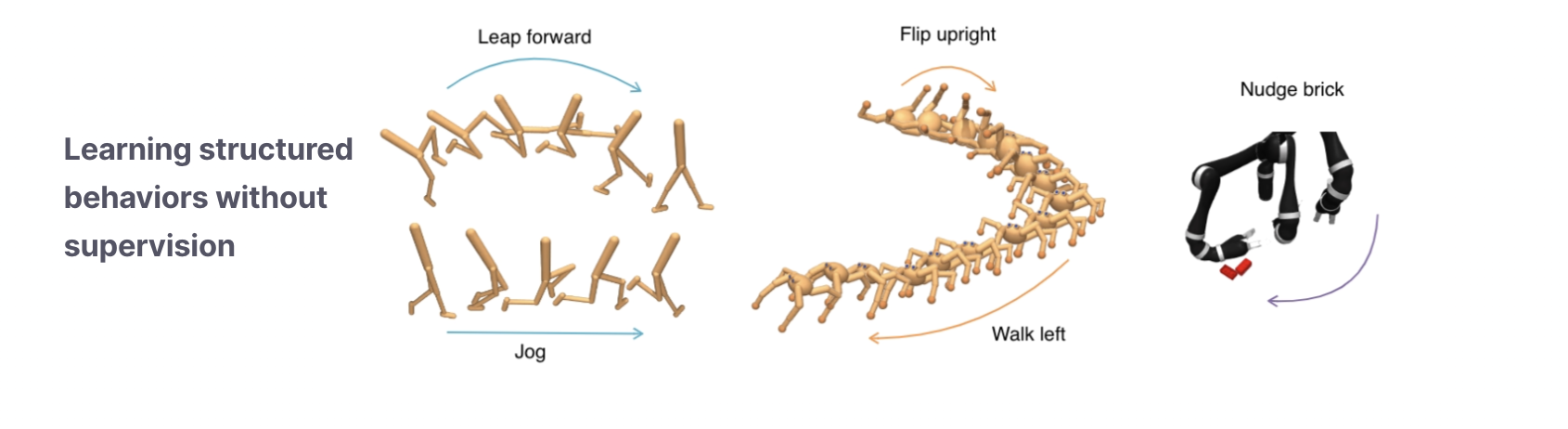
Unsupervised Reinforcement Learning (RL), where RL agents pre-train with self-supervised rewards, is an emerging paradigm for developing RL agents that are capable of generalization. Recently, we released the Unsupervised RL Benchmark (URLB) which we covered in a previous post. URLB benchmarked many unsupervised RL algorithms across three categories — competence-based, knowledge-based, and data-based algorithms. A surprising finding was that competence-based algorithms significantly underperformed other categories. In this post we will demystify what has been holding back competence-based methods and introduce Contrastive Intrinsic Control (CIC), a new competence-based algorithm that is the first to achieve leading results on URLB.
Results from benchmarking unsupervised RL algorithms
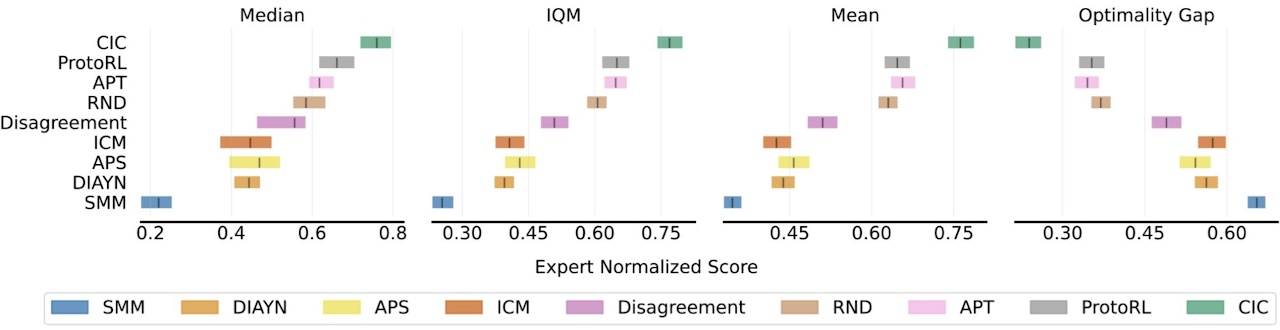
To recap, competence-based methods (which we will cover in detail) maximize the mutual information between states and skills (e.g. DIAYN), knowledge-based methods maximize the error of a predictive model (e.g. Curiosity), and data-based methods maximize the diversity of observed data (e.g. APT). Evaluating these algorithms on URLB by reward-free pre-training for 2M steps followed by 100k steps of finetuning across 12 downstream tasks, we previously found the following stack ranking of algorithms from the three categories.
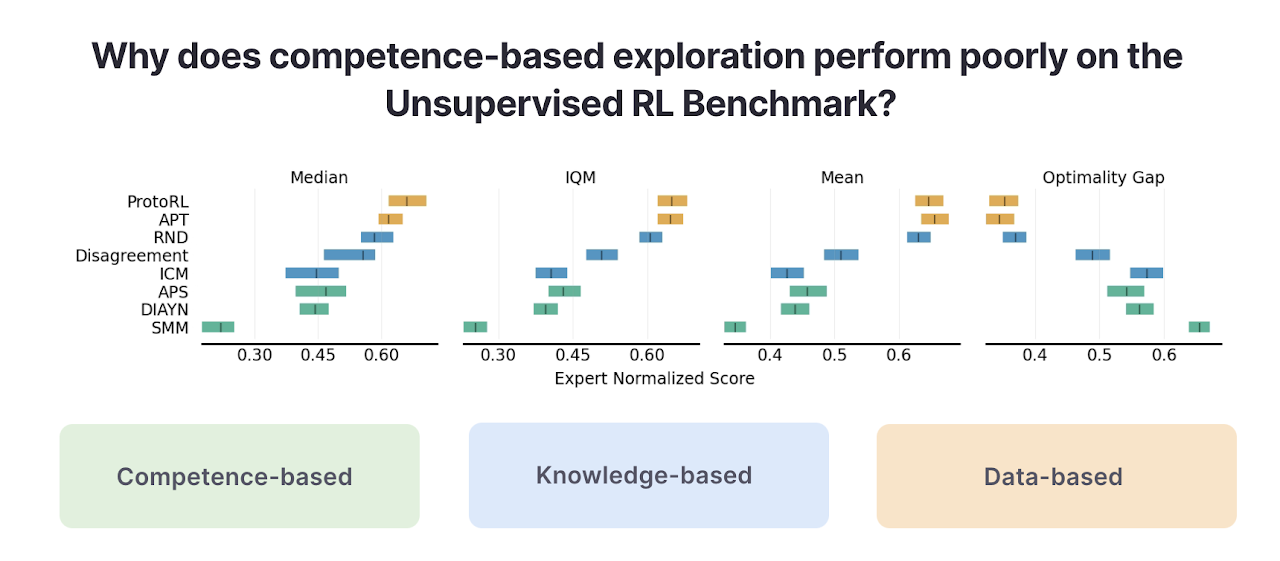
In the above figure competence-based methods (in green) do substantially worse than the other two types of unsupervised RL algorithms. Why is this the case and what can we do to resolve it?
Competence-based exploration
As a quick primer, competence-based algorithms maximize the mutual information between some observed variable such as a state and a latent skill vector, which is usually sampled from noise.
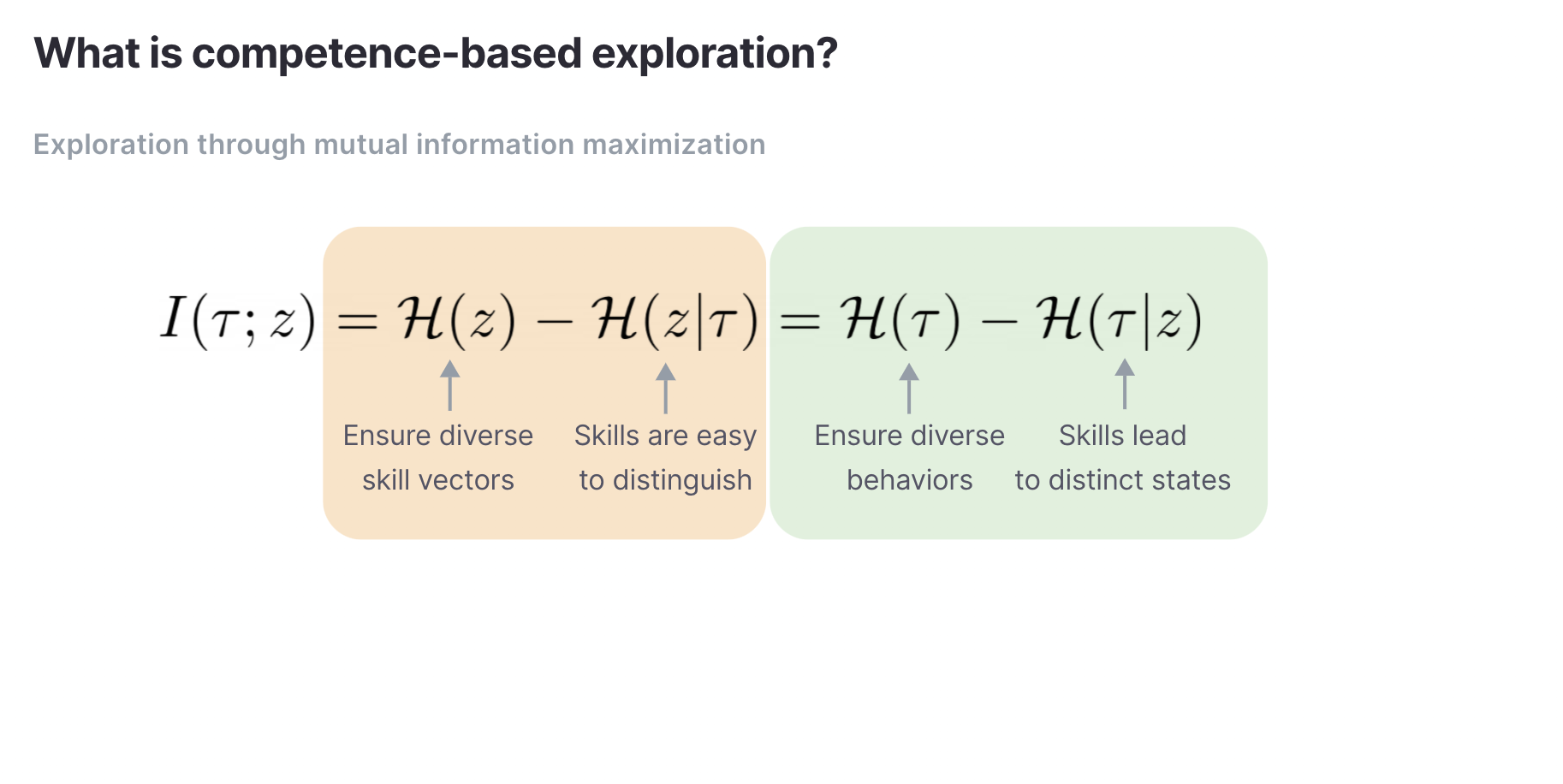
The mutual information is usually an intractable quantity and since we want to maximize it, we are usually better off maximizing a variational lower bound.

The quantity q(z|tau) is referred to as the discriminator. In prior works, the discriminators are either classifiers over discrete skills or regressors over continuous skills. The problem is that classification and regression tasks need an exponential number of diverse data samples to be accurate. In simple environments where the number of potential behaviors is small, current competence-based methods work but not in environments where the set of potential behaviors is large and diverse.
How environment design influences performance
To illustrate this point, let’s run three algorithms on the OpenAI Gym and DeepMind Control (DMC) Hopper. Gym Hopper resets when the agent loses balance while DMC episodes have fixed length regardless if the agent falls over. By resetting early, Gym Hopper constrains the agent to a small number of behaviors that can be achieved by remaining balanced. We run three algorithms — DIAYN and ICM, popular competence-based and knowledge-based algorithms, as well as a “Fixed” agent which gets a reward of +1 for each timestep, and measure the zero-shot extrinsic reward for hopping during self-supervised pre-training.
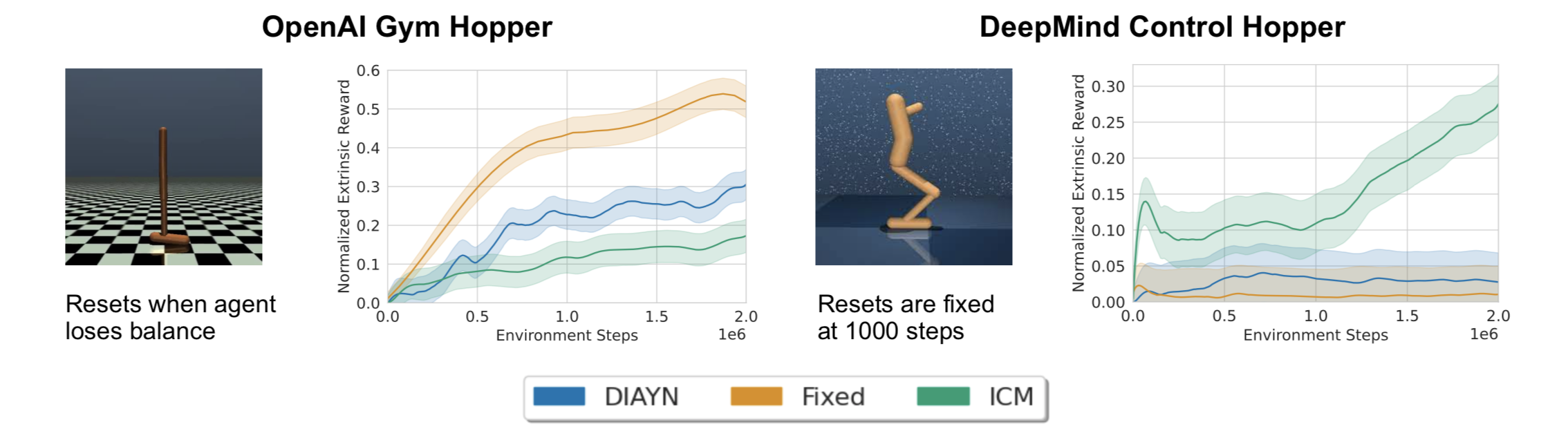
On OpenAI Gym both DIAYN and the Fixed agent receive higher extrinsic rewards relative to ICM, but on the DeepMind Control Hopper both algorithms collapse. The only significant difference between the two environments is that OpenAI Gym resets early whereas DeepMind Control does not. This supports the hypothesis that when an environment supports many behaviors prior competence-based approaches struggle to learn useful skills.
Indeed, if we visualize behaviors learned by DIAYN on other DeepMind Control environments, we see that it learns a small set of static skills.
Prior methods fail to learn diverse behaviors






Skills learned by DIAYN after 2M steps of training.
Effective competence-based exploration with Contrastive Intrinsic Control (CIC)
As illustrated in the above example – complex environments support a large number of skills and we therefore need discriminators capable of supporting large skill spaces. This tension between the need to support large skill spaces and the limitation of current discriminators leads us to propose Contrastive Intrinsic Control (CIC).
Contrastive Intrinsic Control (CIC) introduces a new contrastive density estimator to approximate the conditional entropy (the discriminator). Unlike visual contrastive learning, this contrastive objective operates over state transitions and skill vectors. This allows us to bring powerful representation learning machinery from vision to unsupervised skill discovery.
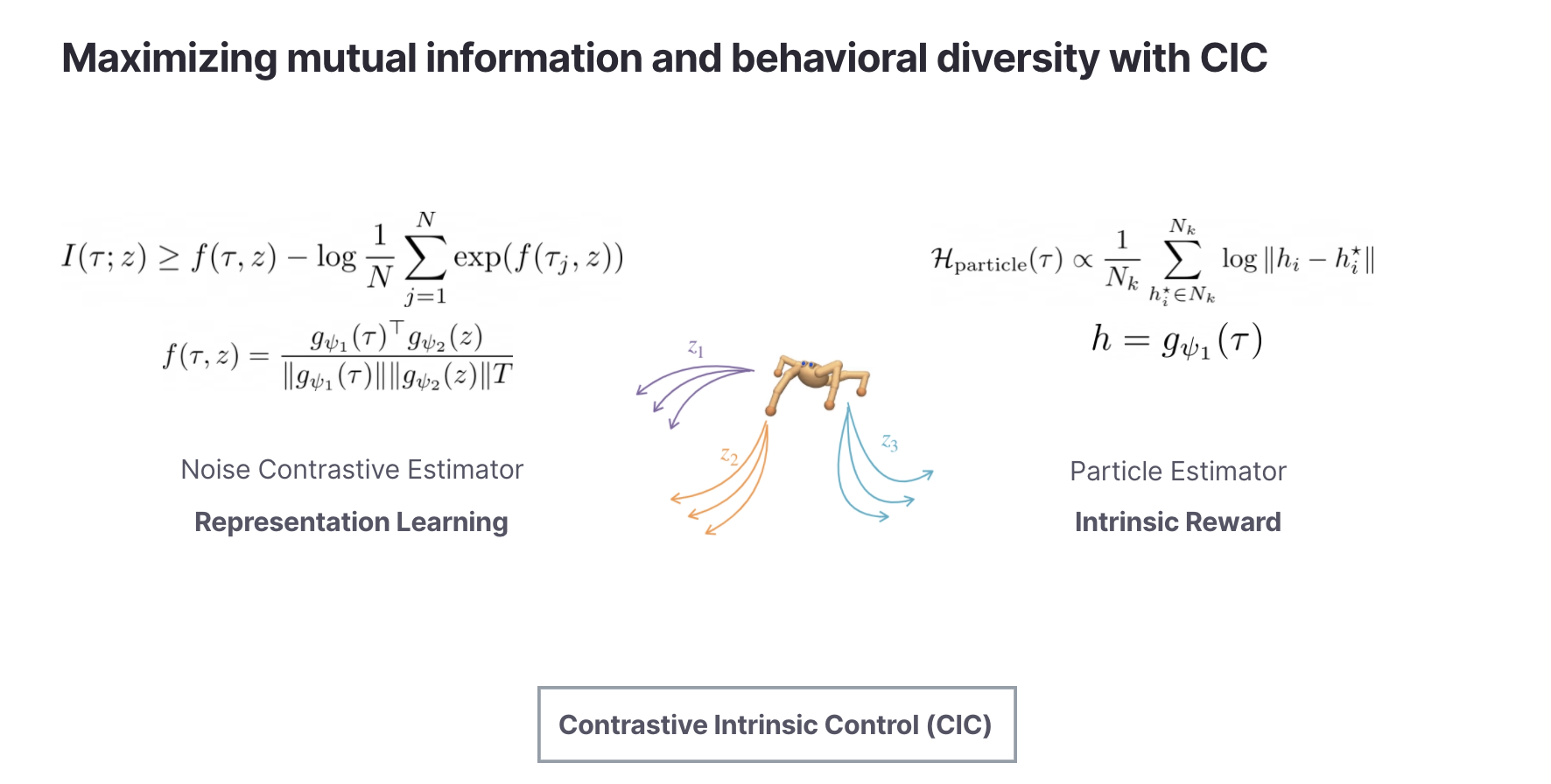
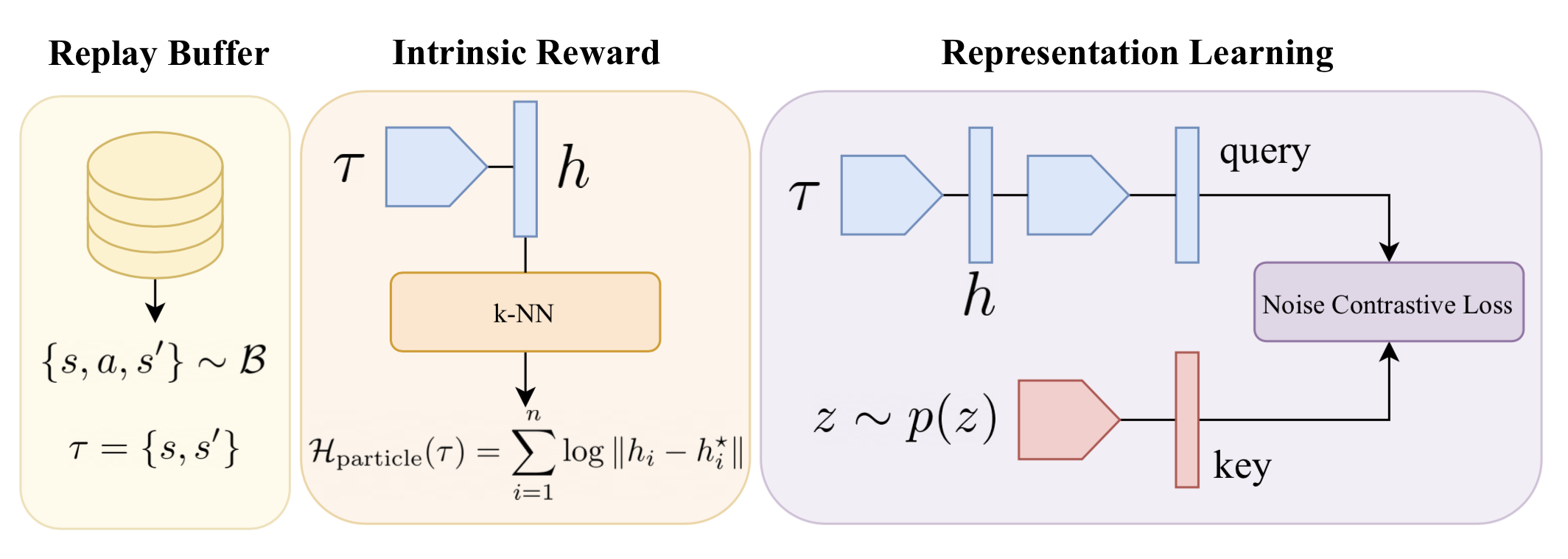
For a practical algorithm, we use the CIC contrastive skill learning as an auxiliary loss during pre-training. The self-supervised intrinsic reward is the value of the entropy estimate computed over the CIC embeddings. We also analyze other forms of intrinsic rewards in the paper, but this simple variant performs well with minimal complexity. The CIC architecture has the following form:
Qualitatively the behaviors from CIC after 2M steps of pre-training are quite diverse.
Diverse Behaviors learned with CIC






Skills learned by CIC after 2M steps of training.
With explicit exploration through the state-transition entropy term and the contrastive skill discriminator for representation learning CIC adapts extremely efficiently to downstream tasks – outperforming prior competence-based approaches by 1.78x and all prior exploration methods by 1.19x on state-based URLB.
We provide more information in the CIC paper about how architectural details and skill dimension affect the performance of the CIC paper. The main takeaway from CIC is that there is nothing wrong with the competence-based objective of maximizing mutual information. However, what matters is how well we approximate this objective, especially in environments that support a large number of behaviors. CIC is the first competence-based algorithm to achieve leading performance on URLB. Our hope is that our approach encourages other researchers to work on new unsupervised RL algorithms
Links
Paper: CIC: Contrastive Intrinsic Control for Unsupervised Skill Discovery
Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, Pieter Abbeel