Introduction
In recent years, scaling model sizes has become a promising area of research. In the field of NLP, language models have gone from hundreds of millions of parameters (BERT) to hundreds of billions of parameters (GPT-3) demonstrating significant improvements on downstream tasks. The scaling laws for large scale language models have also been studied extensively in the industry. A similar trend can be observed in the vision field, with the community moving to transformer based models (like Vision Transformer, Masked Auto Encoders) as well. It is clear that individual modalities – text, image, video – have benefited massively from recent advancements in scale, and frameworks have quickly adapted to accommodate larger models.
At the same time, multimodality is becoming increasingly important in research with tasks like image-text retrieval, visual question-answering, visual dialog and text to image generation gaining traction in real world applications. Training large scale multimodal models is the natural next step and we already see several efforts in this area like CLIP from OpenAI, Parti from Google and CM3 from Meta.
In this blog, we present a case study demonstrating the scaling of FLAVA to 10B params using techniques from PyTorch Distributed. FLAVA is a vision and language foundation model, available in TorchMultimodal, which has shown competitive performance on both unimodal and multimodal benchmarks. We also give the relevant code pointers in this blog. The instructions for running an example script to scale FLAVA can be found here.
Scaling FLAVA Overview
FLAVA is a foundation multimodal model which consists of transformer based image and text encoders followed by a transformer-based multimodal fusion module. It is pretrained on both unimodal and multimodal data with a diverse set of losses. This includes masked language, image and multimodal modeling losses that require the model to reconstruct the original input from its context (self-supervised learning). It also uses image text matching loss over positive and negative examples of aligned image-text pairs as well as CLIP style contrastive loss. In addition to multimodal tasks (like image-text retrieval), FLAVA demonstrated competitive performance on unimodal benchmarks as well (GLUE tasks for NLP and image classification for vision).
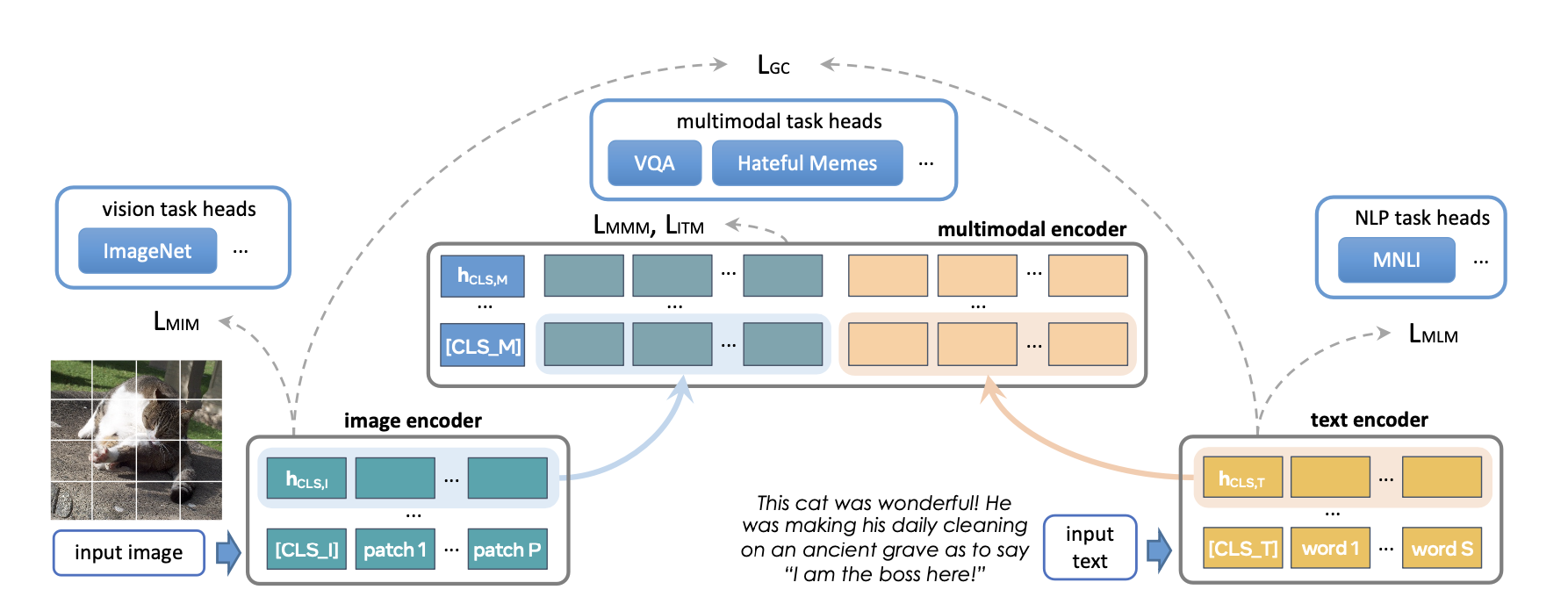
The original FLAVA model has ~350M parameters and uses ViT-B16 configurations (from the Vision Transformer paper) for image and text encoders. The multimodal fusion transformer follows the unimodal encoders but with half the number of layers. We explore increasing the size of each encoder to larger ViT variants.
Another aspect of scaling is adding the ability to increase the batch size. FLAVA makes use of contrastive loss over in-batch negatives, which typically benefits from large batch size (as studied here). The largest training efficiency or throughput is also generally achieved when operating near maximum possible batch sizes as determined by the amount of GPU memory available (also see the experiments section).
The following table displays the different model configurations we experimented with. We also determine the maximum batch size that was able to fit in memory for each configuration in the experiments section.
| Approx Model params | Hidden size | MLP size | Heads | Unimodal layers | Multimodal layers | Model size (fp32) |
|---|---|---|---|---|---|---|
| 350M (original) | 768 | 3072 | 12 | 12 | 6 | 1.33GB |
| 900M | 1024 | 4096 | 16 | 24 | 12 | 3.48GB |
| 1.8B | 1280 | 5120 | 16 | 32 | 16 | 6.66GB |
| 2.7B | 1408 | 6144 | 16 | 40 | 20 | 10.3GB |
| 4.8B | 1664 | 8192 | 16 | 48 | 24 | 18.1GB |
| 10B | 2048 | 10240 | 16 | 64 | 40 | 38GB |
Optimization overview
PyTorch offers several native techniques to efficiently scale models. In the following sections, we go over some of these techniques and show how they can be applied to scale up a FLAVA model to 10 billion parameters.
Distributed Data Parallel
A common starting point for distributed training is data parallelism. Data parallelism replicates the model across each worker (GPU), and partitions the dataset across the workers. Different workers process different data partitions in parallel and synchronize their gradients (via all reduce) before model weights are updated. The figure below showcases the flow (forward, backward, and weight update steps) for processing a single example for data parallelism:
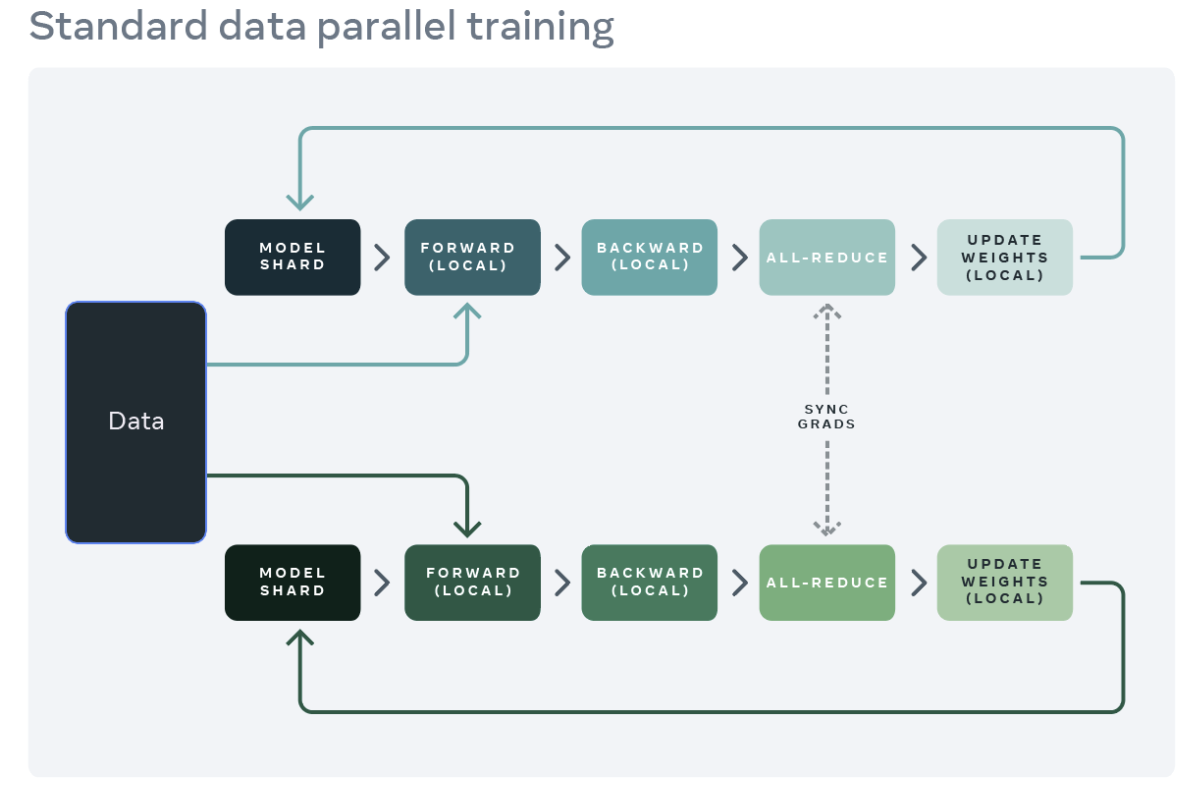
Source: https://engineering.fb.com/2021/07/15/open-source/fsdp/
PyTorch provides a native API, DistributedDataParallel (DDP) to enable data parallelism which can be used as a module wrapper as showcased below. Please see PyTorch Distributed documentation for more details.
from torchmultimodal.models.flava.model import flava_model_for_pretraining
import torch
import torch.distributed as dist
model = flava_model_for_pretraining().cuda()
# Initialize PyTorch Distributed process groups
# Please see https://pytorch.org/tutorials/intermediate/dist_tuto.html for details
dist.init_process_group(backend=”nccl”)
# Wrap model in DDP
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[torch.cuda.current_device()])
Fully Sharded Data Parallel
GPU memory usage of a training application can roughly be broken down into model inputs, intermediate activations (needed for gradient computation), model parameters, gradients, and optimizer states. Scaling a model will typically increase each of these elements. Scaling a model with DDP can eventually result in out-of-memory issues when a single GPU’s memory becomes insufficient since it replicates the parameters, gradients, and optimizer states on all workers.
To reduce this replication and save GPU memory, we can shard the model parameters, gradients, and optimizer states across all workers with each worker only managing a single shard. This technique was popularized by the ZeRO-3 approach developed by Microsoft. A PyTorch-native implementation of this approach is available as FullyShardedDataParallel (FSDP) API, released as a beta feature in PyTorch 1.12. During a module’s forward and backward passes, FSDP unshards the model parameters as needed for computation (using all-gather) and reshards them after computation. It synchronizes gradients using the reduce-scatter collective to ensure sharded gradients are globally averaged. The forward and backward pass flow of a model wrapped in FSDP are detailed below:
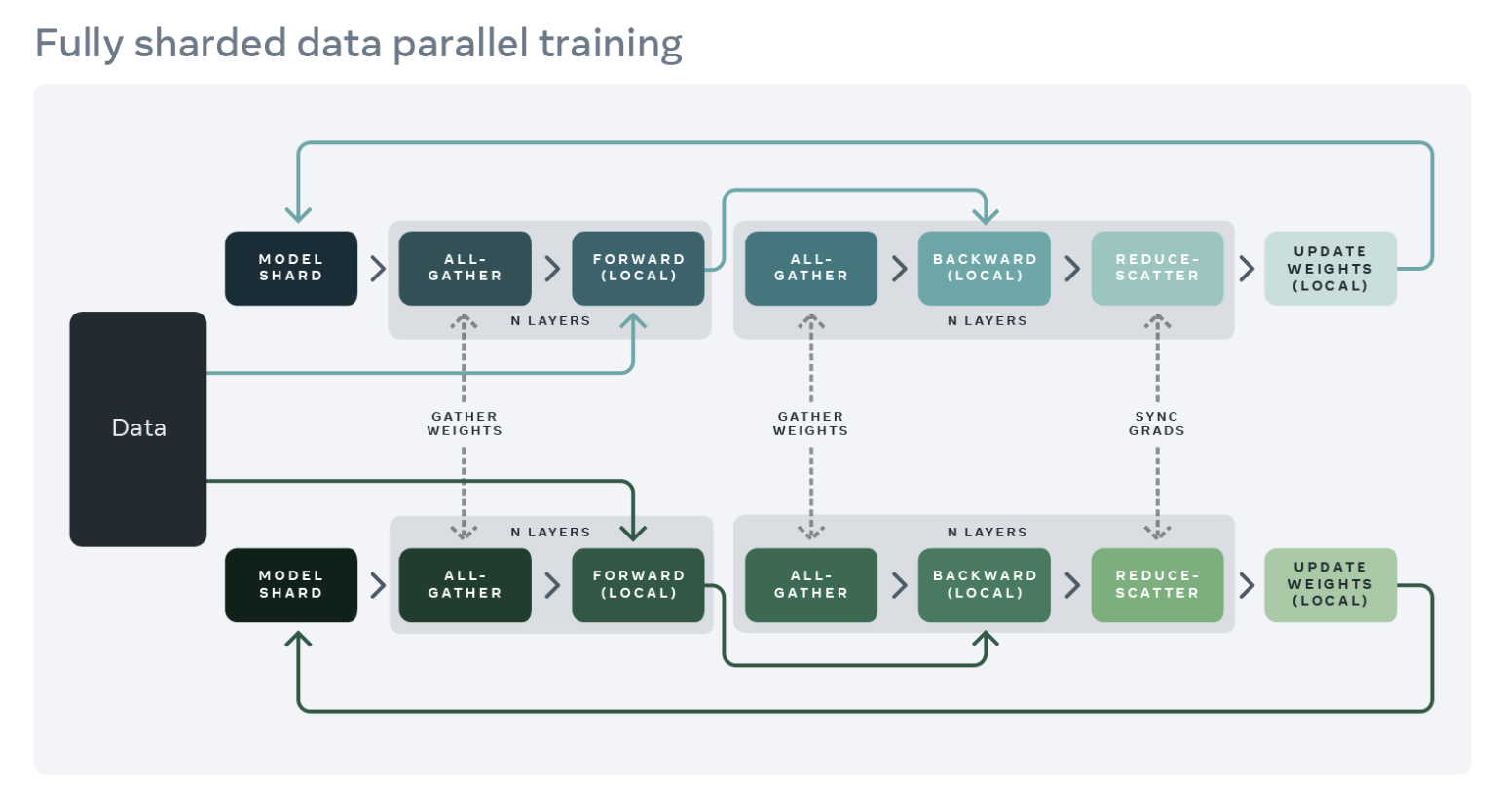
Source: https://engineering.fb.com/2021/07/15/open-source/fsdp/
To use FSDP, the submodules of a model need to be wrapped with the API to control when specific submodules are sharded or unsharded. FSDP provides an auto-wrapping API (see the auto_wrap_policy argument) that can be used out of the box as well as several wrapping policies and the ability to write your own policy.
The following example demonstrates wrapping the FLAVA model with FSDP. We specify the auto-wrapping policy as transformer_auto_wrap_policy. This will wrap individual transformer layers (TransformerEncoderLayer), the image transformer (ImageTransformer), text encoder (BERTTextEncoder) and multimodal encoder (FLAVATransformerWithoutEmbeddings) as individual FSDP units. This uses a recursive wrapping approach for efficient memory management. For example, after an individual transformer layer’s forward or backward pass is finished, its parameters are discarded, freeing up memory thereby reducing peak memory usage.
FSDP also provides a number of configurable options to tune the performance of applications. For example, in our use case, we illustrate the use of the new limit_all_gathers flag, which prevents all-gathering model parameters too early thereby alleviating memory pressure on the application. We encourage users to experiment with this flag which can potentially improve the performance of applications with high active memory usage.
import torch
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torchmultimodal.models.flava.text_encoder import BertTextEncoder
from torchmultimodal.models.flava.image_encoder import ImageTransformer
from torchmultimodal.models.flava.transformer import FLAVATransformerWithoutEmbeddings
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining().cuda()
dist.init_process_group(backend=”nccl”)
model = FSDP(
model,
device_id=torch.cuda.current_device(),
auto_wrap_policy=partial(
transformer_auto_wrap_policy,
transformer_layer_cls={
TransformerEncoderLayer,
ImageTransformer,
BERTTextEncoder,
FLAVATransformerWithoutEmbeddings
},
),
limit_all_gathers=True,
)
Activation Checkpointing
As discussed above, intermediate activations, model parameters, gradients, and optimizer states contribute to the overall GPU memory usage. FSDP can reduce memory consumption due to the latter three but does not reduce memory consumed by activations. Memory used by activations increases with increase in batch size or number of hidden layers. Activation checkpointing is a technique to decrease this memory usage by recomputing the activations during the backward pass instead of holding them in memory for a specific checkpointed module. For example, we observed ~4x reduction in the peak active memory after forward pass by applying activation checkpointing to the 2.7B parameter model.
PyTorch offers a wrapper based activation checkpointing API. In particular, checkpoint_wrapper allows users to wrap an individual module with checkpointing, and apply_activation_checkpointing allows users to specify a policy with which to wrap modules within an overall module with checkpointing. Both these APIs can be applied to most models as they do not require any modifications to the model definition code. However, if more granular control over checkpointed segments, such as checkpointing specific functions within a module, is required, the functional torch.utils.checkpoint API can be leveraged, although this requires modification to the model code. The application of the activation checkpointing wrapper to individual FLAVA transformer layers (denoted by TransformerEncoderLayer) is shown below. For a thorough description of activation checkpointing, please see the description in the PyTorch documentation.
from torchmultimodal.models.flava.model import flava_model_for_pretraining
from torch.distributed.algorithms._checkpoint.checkpoint_wrapper import apply_activation_checkpointing, checkpoint_wrapper, CheckpointImpl
from torchmultimodal.modules.layers.transformer import TransformerEncoderLayer
model = flava_model_for_pretraining()
checkpoint_tformer_layers_policy = lambda submodule: isinstance(submodule, TransformerEncoderLayer)
apply_activation_checkpointing(
model,
checkpoint_wrapper_fn=checkpoint_wrapper,
check_fn=checkpoint_tformer_layers_policy,
)
Used together, wrapping FLAVA transformer layers with activation checkpointing and wrapping the overall model with FSDP as demonstrated above, we are able to scale FLAVA to 10B parameters.
Experiments
We conduct an empirical study about the impact of the different optimizations from the previous section on system performance. For all our experiments, we use a single node with 8 A100 40GB GPUs and run the pretraining for 1000 iterations. All runs also used PyTorch’s automatic mixed precision with the bfloat16 data type. TensorFloat32 format is also enabled to improve matmul performance on the A100. We define throughput as the average number of items (text or image) processed per second (we ignore the first 100 iterations while measuring throughput to account for warmup). We leave training to convergence and its impact on downstream task metrics as an area for future study.
Figure 1 plots the throughput for each model configuration and optimization, both with a local batch size of 8 and then with the maximum batch size possible on 1 node. Absence of a data point for a model variant for an optimization indicates that the model could not be trained on a single node.
Figure 2 plots the maximum possible batch size per worker for each optimization. We observe a few things:
- Scaling model size: DDP is only able to fit the 350M and 900M model on a node. With FSDP, due to memory savings, we are able to train ~3x bigger models compared to DDP (i.e. the 1.8B and 2.7B variants). Combining activation checkpointing (AC) with FSDP enables training even bigger models, on the order of ~10x compared to DDP (i.e. 4.8B and 10B variants)
- Throughput:
- For smaller model sizes, at a constant batch size of 8, the throughput for DDP is slightly higher than or equal to FSDP, explainable by the additional communication required by FSDP. It is lowest for FSDP and AC combined together. This is because AC re-runs checkpointed forward passes during the backwards pass, trading off additional computation for memory savings. However, in the case of the 2.7B model, FSDP + AC actually has higher throughput compared to FSDP alone. This is because the 2.7B model with FSDP is operating close to the memory limit even at batch size 8 triggering CUDA malloc retries which tend to slow down training. AC helps with reducing the memory pressure and leads to no retries.
- For DDP and FSDP + AC, the throughput increases with an increase in batch size for each model. For FSDP alone, this is true for smaller variants. However, with the 1.8B and 2.7B parameter models, we observe throughput degradation when increasing batch size. A potential reason for this, as noted above also, is that at the memory limit, PyTorch’s CUDA memory management may have to retry cudaMalloc calls and/or run expensive defragmentation steps to find free memory blocks to handle the workload’s memory requirements which can result in training slowdown.
- For larger models that can only be trained with FSDP (1.8B, 2.7B, 4.8B) the setting with highest throughput achieved is with FSDP + AC scaling to the maximum batch size. For 10B, we observe nearly equal throughput for smaller and maximum batch size. This might be counterintuitive as AC results in increased computation and maxing out batch size potentially leads to expensive defragmentation operations due to operating at CUDA memory limit. However, for these large models, the increase in batch size is large enough to mask this overhead.
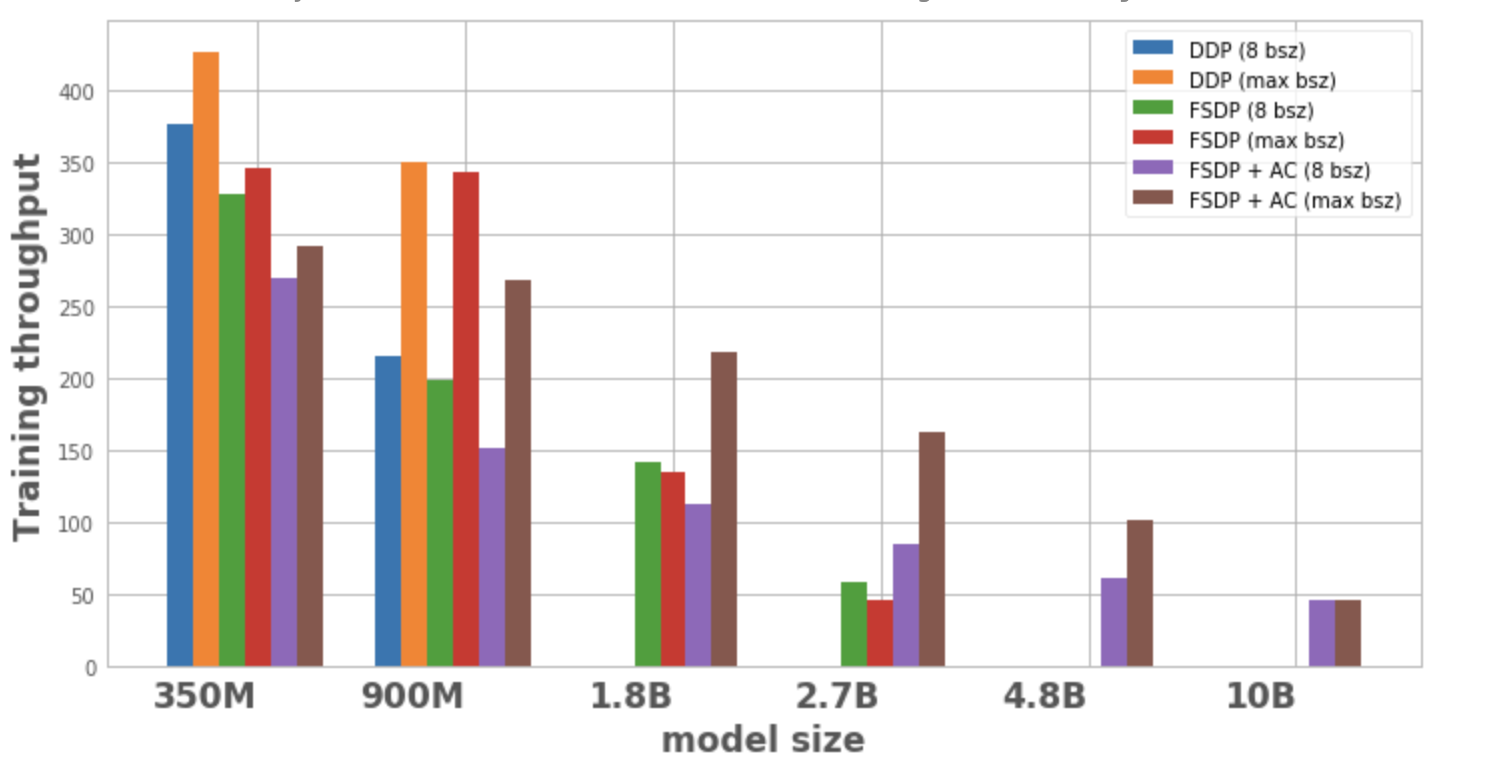
Figure 1: Training throughput for different configurations
- Batch size: FSDP alone enables slightly higher batch sizes compared to DDP. Using FSDP + AC enables ~3x batch size compared to DDP for the 350M param model and ~5.5x for 900M param model. Even for 10B, a max batch size of ~20 which is fairly decent. This essentially enables larger global batch size using fewer GPUs which is especially useful for contrastive learning tasks.
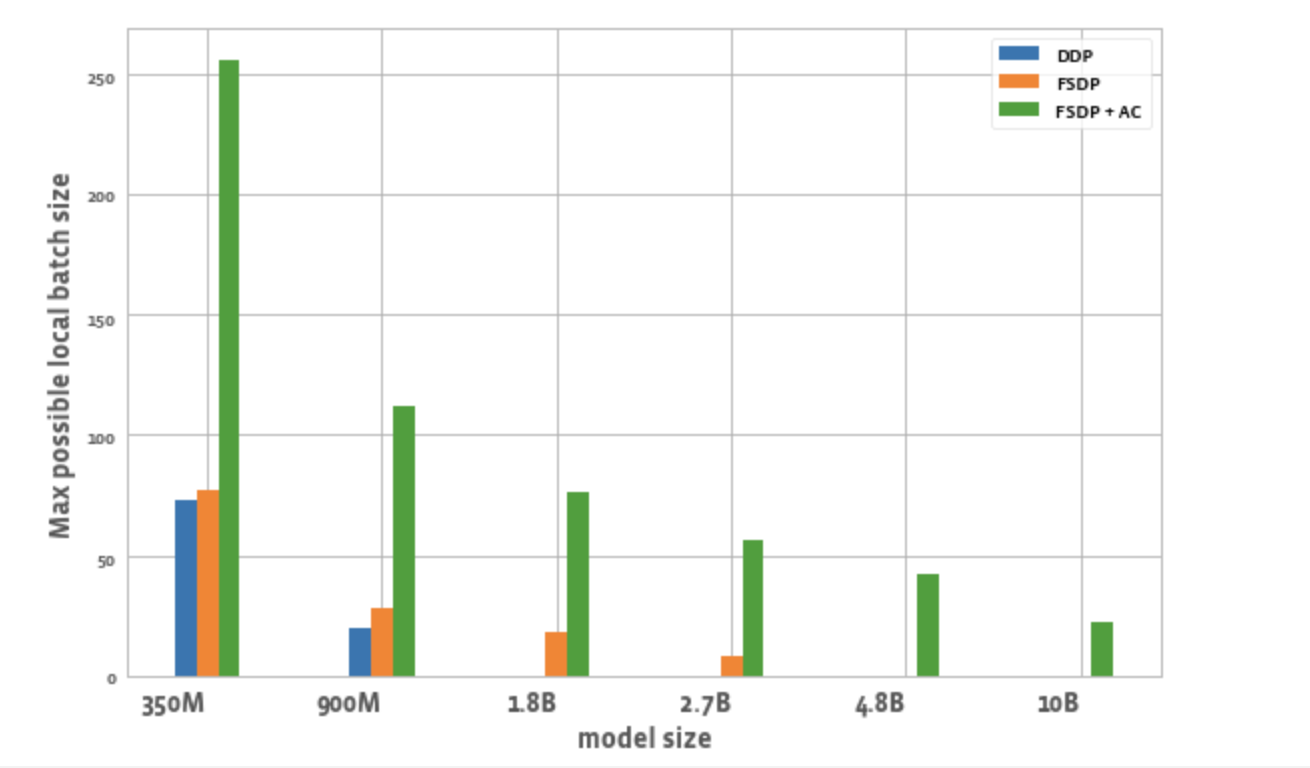
Figure 2: Max local batchsize possible for different configurations
Conclusion
As the world moves towards multimodal foundation models, scaling model parameters and efficient training is becoming an area of focus. The PyTorch ecosystem aims to accelerate innovation in this field by providing different tools to the research community, both for training and scaling multimodal models. With FLAVA, we laid out an example of scaling a model for multimodal understanding. In the future, we plan to add support for other kinds of models like the ones for multimodal generation and demonstrate their scaling factors. We also hope to automate many of these scaling and memory saving techniques (such as sharding and activation checkpointing) to reduce the amount of user experimentation needed to achieve the desired scale and maximum training throughput.