The PyTorch Ecosystem goes back several years, with some of its earliest projects like Hugging Face, Fast.ai, and PyTorch Lightning going on to grow incredible communities of their own. The goal from the beginning was to bring together innovative open source AI projects that extend, integrate with, or build upon PyTorch. Some of the key aspects we looked at were, for example, that they were well tested and maintained (including CI), were easy to onboard as a user, and there was a growing community. Fast forward several years, and the ecosystem continues to thrive with a vibrant landscape of dozens of projects spanning privacy, computer vision, to reinforcement learning. Enter the PyTorch Ecosystem Working Group.
In early 2025, the PyTorch Foundation created the PyTorch Ecosystem Working Group to showcase projects that could be of interest to the community and represent projects that are mature and healthy, standing out in their respective domain. The working group, composed of members across the ecosystem, was tasked with defining a clear bar including functional requirements (e.g., CI, licensing…), measurable requirements (e.g., commits and contributors), and the implementation of best practices for how to structure their repos. The working group also implemented a streamlined submission and review process and a transparent lifecycle. It’s still very early, but the reception from the community has been great, with 21 submissions so far and a strong pipeline of projects in review. You can learn more about this working group’s goals here, including the requirements and application process.
As part of this new blog series, every quarter we will update the community on new entries in the PyTorch Ecosystem, as well as highlight up and coming projects that are in consideration that will benefit from more eyes and contributors.
Ecosystem Project Spotlights
We’re happy to welcome SGlang and docTR to the PyTorch Ecosystem. Here’s a short intro to both.
SGLang
SGLang is a fast-serving engine for large language models and vision language models. It makes the interaction with models faster and more controllable by co-designing the backend runtime and frontend language.
The core features include:
- Fast Backend Runtime: Provides efficient serving with RadixAttention for prefix caching, zero-overhead CPU scheduler, continuous batching, token attention (paged attention), speculative decoding, tensor parallelism, chunked prefill, structured outputs, and quantization (FP8/INT4/AWQ/GPTQ).
- Flexible Frontend Language: Offers an intuitive interface for programming LLM applications, including chained generation calls, advanced prompting, control flow, multi-modal inputs, parallelism, and external interactions.
- Extensive Model Support: Supports a wide range of generative models (Llama, Gemma, Mistral, Qwen, DeepSeek, LLaVA, etc.), embedding models (e5-mistral, gte, mcdse) and reward models (Skywork), with easy extensibility for integrating new models.
- Active Community: SGLang is open source and backed by an active community with industry adoption.
SGLang is famous for its fast speed. It can often significantly outperform other state-of-the-art frameworks in terms of serving throughput and latency. Learn more.
docTR
docTR is an Apache 2.0 project developed and distributed by Mindee to help developers integrate OCR capabilities into applications with no prior knowledge required.
To quickly and efficiently extract text information, docTR uses a two-stage approach:
- First, it performs text detection to localize words.
- Then, it conducts text recognition to identify all characters in a word.
Detection and recognition are performed by state-of-the-art models written in PyTorch. Learn more.
Up and Coming Project Spotlights
As part of this series, we highlight projects that are in consideration for the PyTorch Ecosystem, and that we believe will benefit from more eyes and contributors. This time it’s the turn of EIR and torchcvnn.
EIR
EIR is a comprehensive deep learning framework built on PyTorch that enables researchers and developers to perform supervised modeling, sequence generation, image/array generation, and survival analysis across multiple data modalities. EIR specializes in handling complex data types, including genotype, tabular, sequence, image, array, and binary inputs. While it has particular strengths in genomics and biomedical applications, its versatile handling of these diverse data types allows for broader applications across various sectors. For example, EIR’s multi-modal approach can enhance tasks such as detecting manufacturing defects by linking images with equipment readings (e.g., for an imperfect silicon wafer), monitoring infrastructure by analyzing site photos along with operational logs (e.g., to identify cracks in a pipeline), or improving retail insights by combining product images with their descriptions and sales figures. This demonstrates how EIR’s multi-modal capabilities can bring value to a wide range of industries.
The framework provides a high-level, yet modular API that reduces the amount of boilerplate code and pre-processing required to train models, allowing users to focus on their end goals rather than implementation details. To learn more and explore practical examples, please refer to the documentation.
Key features include:
- Multi-modal inputs: Seamless integration of genotype, tabular, sequence, image, array, and binary data.
- Varied modeling options: Use any of the input modalities above for supervised learning, sequence generation, image/array generation, and survival analysis.
- Scaling: Capabilities for custom data streaming for model training.
- Explainability: Built-in explainability functionality for when performing supervised learning and survival analysis.
- Model Deployment: Serve any of your trained models with just one command, allowing you or others to interact with your models via web services.
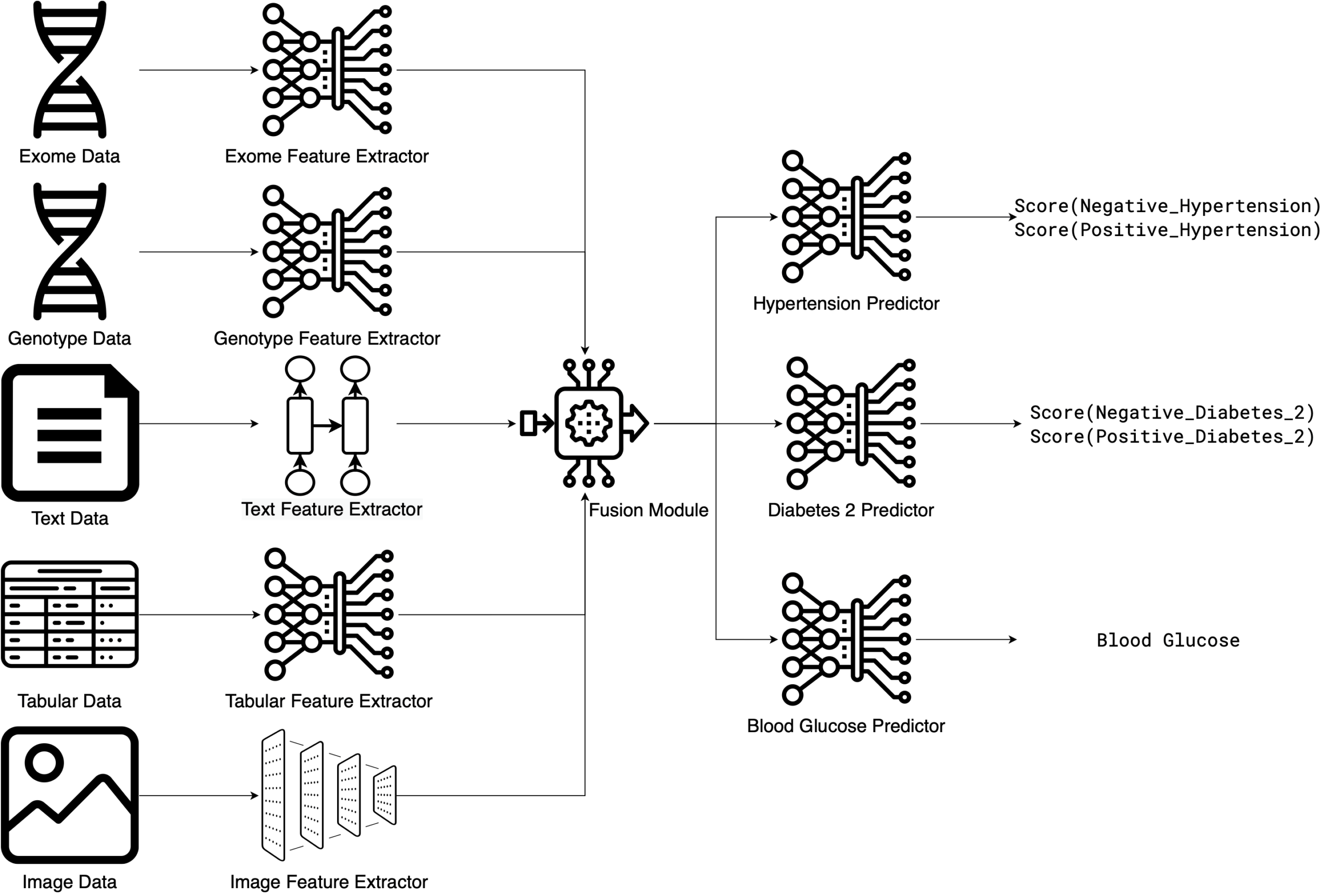
To explore EIR and consider how it might enhance your work with multi-modal data:
- Install: Installation is simple:
- pip install eir-dl
- Please refer to the README for more information.
- Explore tutorials: Documentation available at eir.readthedocs.io, examples include:
- Genetic ancestry prediction: Explore the basics of how EIR works by training a model to predict genetic ancestry.
- Multi-modal training: Combine tabular, text, and image data for pet adoption prediction.
- Sequence generation: Train and serve an image captioning model.
- Image Generation: Use guided diffusion for image generation.
- Scaling: Implement custom data streaming for GPT-style training.
- Contribute: Please visit our GitHub repository.
torchcvnn
torchcvnn is a library that helps researchers, developers, and organizations to easily experiment with Complex-valued Neural Networks (CVNNs)! In several domains, data are naturally represented in real-imaginary form, for instance, remote sensing, MRI, and many more. These domains would benefit from direct complex-valued computations, giving understanding about critical physical characteristics to the neural networks during the learning process.


torchcvnn gives you easy access to:
- Standard datasets for both remote sensing (SLC and ALOS2 formats) and MRI, and for different tasks (classification, segmentation, reconstruction, super-resolution)
- Various activation functions, either operating independently on the real/imaginary components or fully exploiting the complex nature of the representations,
- Normalization layers with the complex-valued BatchNorm of Trabelsi et al.(2018), LayerNorm, RMSNorm,
- Complex-valued attention layer as introduced in Eilers et al. (2023),
PyTorch already supports optimization of complex-valued neural networks by implementing Wirtinger Calculus. However, there are still complex-valued building blocks missing to really be able to explore the capabilities of complex-valued neural networks. The objective of torchcvnn is to fill in this gap and to provide a library helping the PyTorch users to dig into the realm of complex-valued neural networks.
torchcvnn warmly welcomes contributions to both the core torchcvnn library or to the examples’ repository for whether spotting a bug, having suggestions for improvements, or even wanting to contribute to the source code. All the components are described in the documentation of the project. The torchcvnn team will be present at IJCNN 2025 in July in Rome during the special session on “Complex- and Hypercomplex-valued Neural Networks.”
How to Join the PyTorch Ecosystem
If you’re developing a project that supports the PyTorch community, you’re welcome to apply for inclusion in the Ecosystem. Please review the PyTorch Ecosystem review process to ensure that you meet the minimum expectations before applying.
Cheers!
The PyTorch Ecosystem Working Group