Collaborators: Less Wright, Howard Huang, Chien-Chin Huang, Crusoe: Martin Cala, Ethan Petersen
tl;dr: we used torchft and torchtitan to train a model in a real-world environment with extreme synthetic failure rates to prove reliability and correctness of fault tolerant training
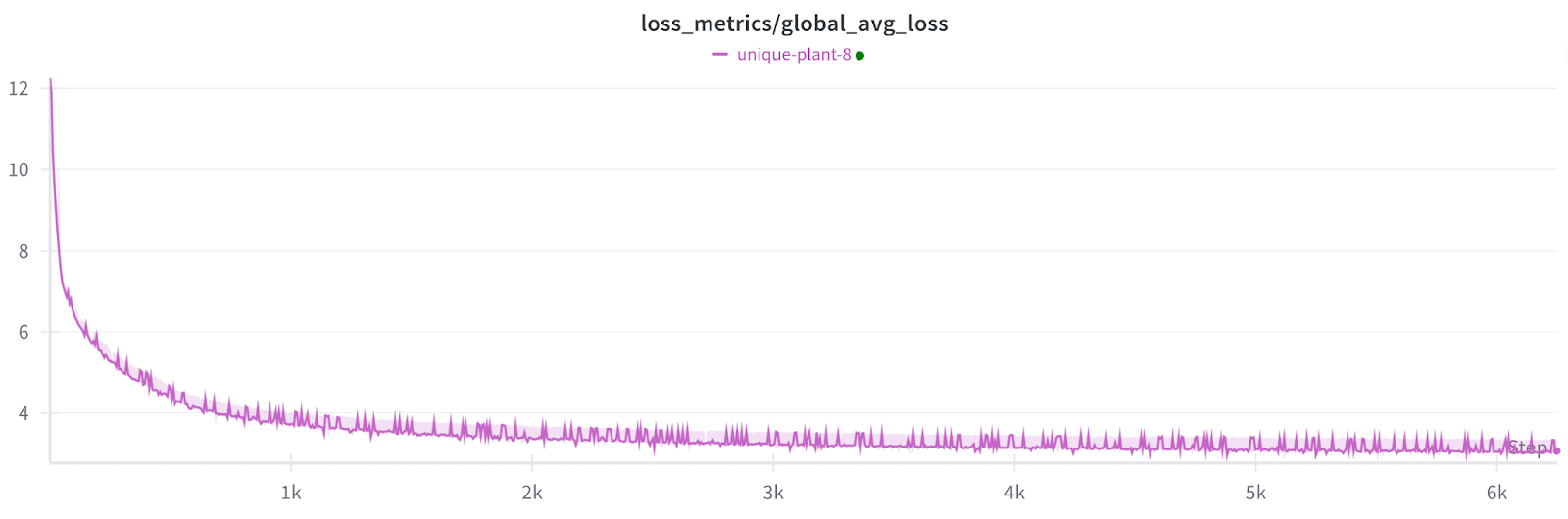
Training loss across 1200 failures with no checkpoints.
NOTE: Each small spike is a non-participating worker recovering which affects the metrics but not the model
Introduction
We want to demonstrate torchft in worst case scenarios by running a training job with the most extreme failure rates possible.
Most LLM pre-training uses sharded models using FSDP. torchft supports sharded models using HSDP2, which combines a sharded model with the fault tolerant DDP all reduce from torchft. We’ve integrated torchft into torchtitan so you can use fault tolerance out of the box. torchft+titan also support other sharding/parallelisms within each replica group, such as tensor parallelism (TP), pipeline parallelism (PP) and more.
Here’s the structure of a training job with torchft:
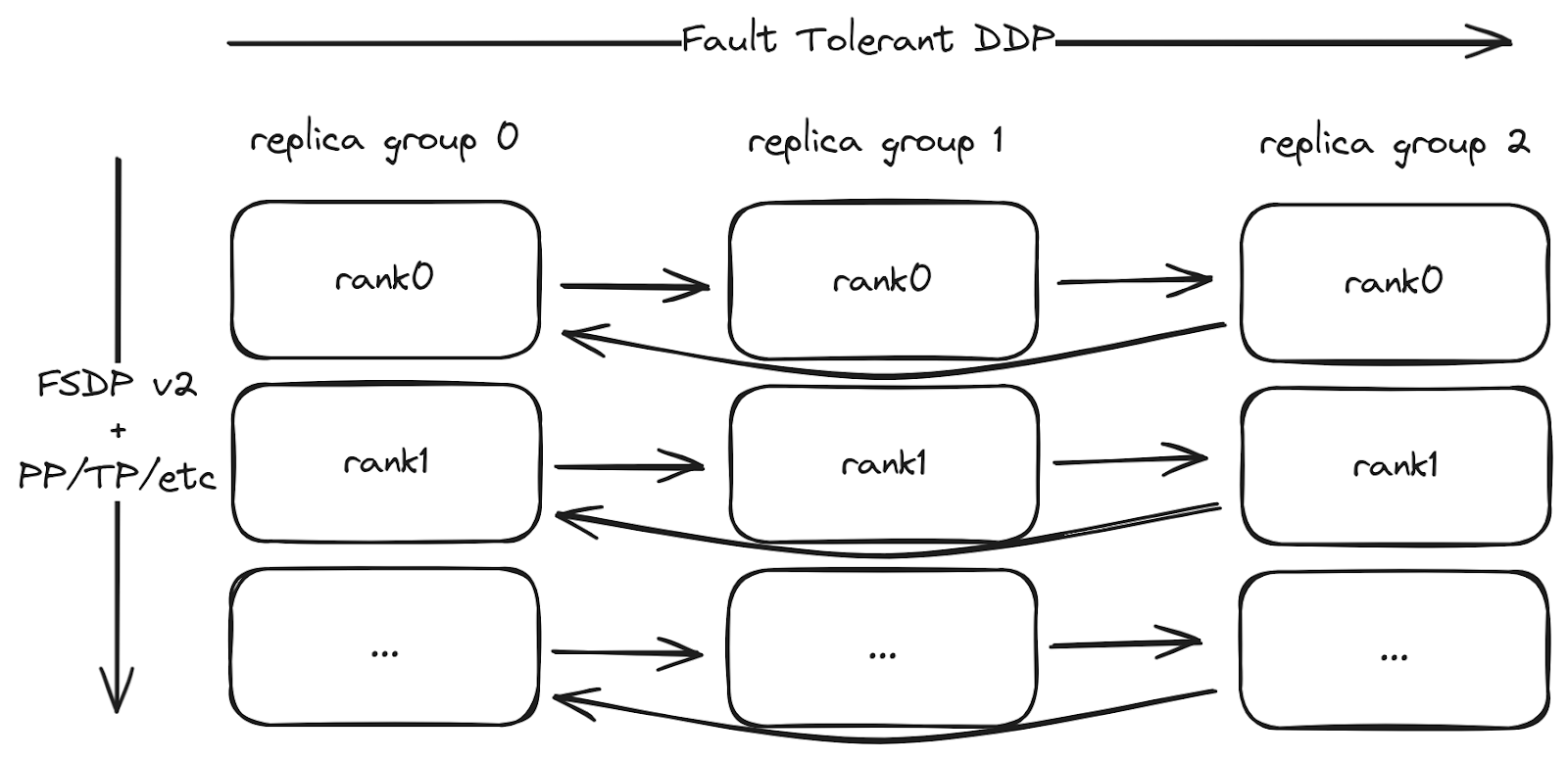
The structure of the training job. torchft’s fault tolerant DDP implementation is used across the replica groups to synchronize the gradients. Standard FSDP2 and other parallelisms are used within each replica group.
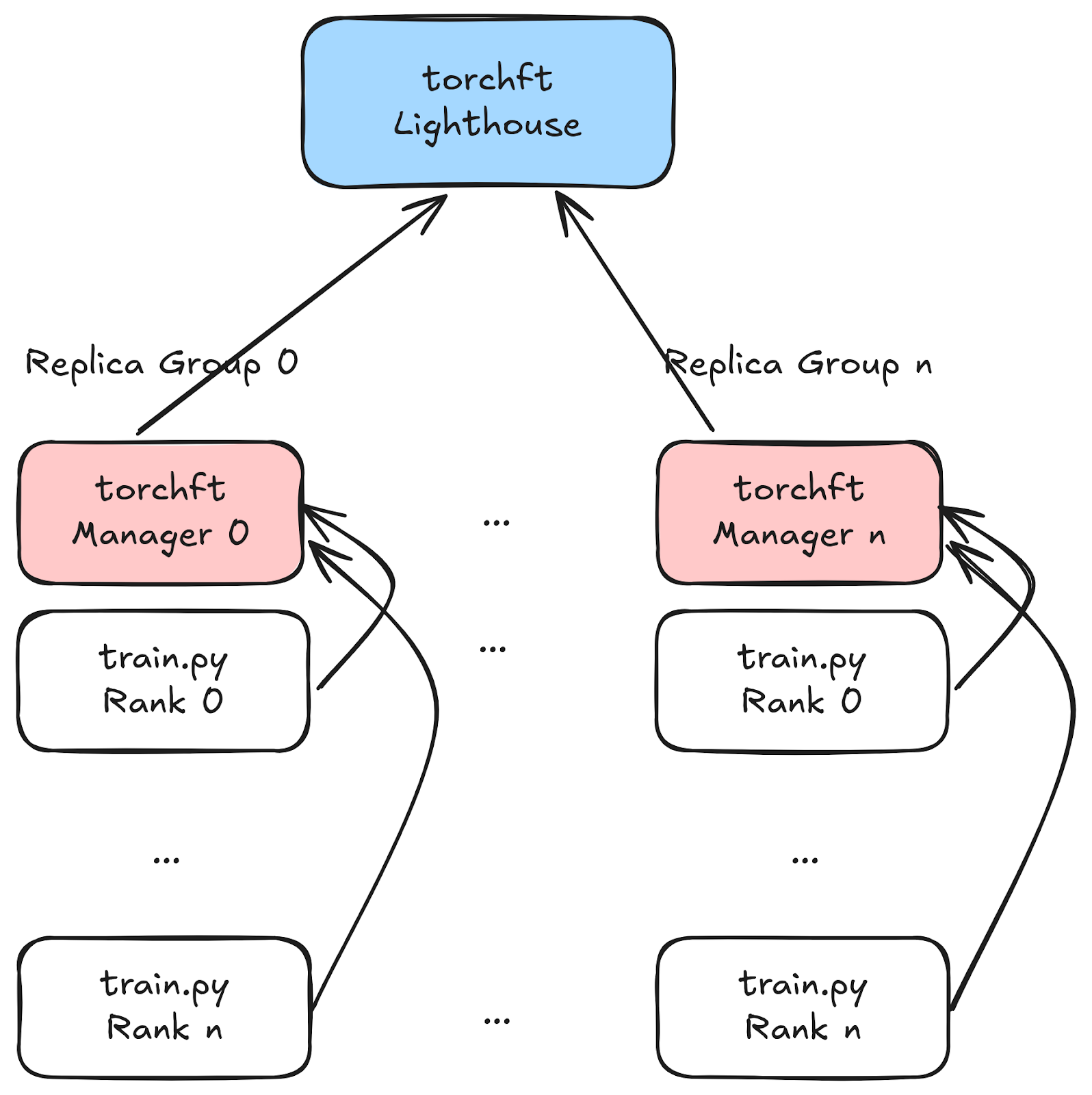
torchft uses a global Lighthouse server and per replica group Managers to do the real time coordination of workers. The Lighthouse knows the state of all workers and which ones are healthy via heartbeats.
torchft implements a few different algorithms for fault tolerance. The two most primary ones are:
- Fault Tolerant HSDP: An extension of FSDPv2 that uses a fault tolerant all-reduce. This exactly emulates standard HSDP training with per step all_reduce of the gradients and per step fault tolerance. This works best for large scale training with fast backend networks such as infiniband.
- LocalSGD/DiLoCo: A fault tolerant implementation of semi-sync training. These algorithms minimize communication overhead by synchronizing at specified intervals instead of every step like HSDP. This is often used in communication limited training scenarios such as over ethernet/TCP or in geographically separate locations (federated learning or multidatacenter training).
We’re always keeping an eye out for new algorithms, such as our upcoming support for streaming DiLoCo. If you have a new use case you’d like to collaborate on, please reach out!
Cluster Setup
Crusoe graciously lent us a cluster of 300 L40S GPUs. The GPUs were split up across 30 hosts, each with 10 NVIDIA L40S GPUs.
For the model, we used torchtitan with a Llama 3 model with 1B parameters to match the hardware available.
NVIDIA L40S GPUs are typically used for inference and thus gave us an opportunity to test torchft in a non-traditional environment where things such as DiLoCo really shine due to the lower TCP-only (no infiniband/nvlink) network bottleneck. The L40S has 48GB of VRAM (closer to consumer GPUs) so we used a smaller model and batch size. The average step time for training was ~9s each.
To maximize performance with the limited network, we trained the model in a 30x1x10 configuration. We had 30 replica groups (fault tolerant domains), each with 1 host and 10 gpus/workers. torchft can have many, many hosts in each replica group, but for this cluster, a single host/10 gpus per replica group had the best performance due to limited network bandwidth. We ran with 30 replica groups, as more groups stressed the coordination and reconfiguration algorithms more.
For network communication, we used NCCL for all communication (i.e., FSDP) within each replica group and Gloo for communication across replica groups. Gloo, while often not as performant, initializes much faster and can also fail much faster, which is important for quick detection of failures. torchft does support fault tolerance using NCCL for IB clusters with some caveats but wasn’t used in this demo. Since we wanted to maximize the total number of failures and recoveries, we used Gloo since it can reinitialize in <1s for our use case, and we were able to set the timeout on all operations at 5s.
For the fault tolerance algorithms, we did the bulk of the testing with Fault Tolerant HSDP, as it stresses the communication and quorum layers the most. For the final test, we used DiLoCo, which is a better fit for the ethernet based cluster.
Recovering with No Checkpoints
Traditional machine learning achieves “fault tolerance” by reloading from checkpoints when an error occurs. This involves a complete stop-the-world operation where all workers restart and load from the most recently persisted checkpoint.
With torchft, we instead focus on isolating failures to an individual group of GPUs. When an error occurs within that group we can restart that group asynchronously and all other groups can reconfigure and continue training without that group.
When that group recovers through a restart or the scheduler replaces the machines, those workers no longer have a valid copy of the weights and optimizer states. If we tried to recover from a checkpoint, the other groups would have already moved on. Instead, we rely on an asynchronous weight transfer at runtime. This does a peer-to-peer transfer of the weights from a healthy replica.
Since we’re always recovering from another worker – it turns out that we actually don’t need any checkpoints as long as we can guarantee that at least one group is healthy. For this demonstration, we turned off checkpointing entirely as a persistent checkpoint save and load is much longer than our P2P recovery time.
Here’s a diagram showing how a recovering replica (replica 1) can join the quorum and recover from a healthy peer (replica 0) without having any downtime or impacting the healthy worker training:
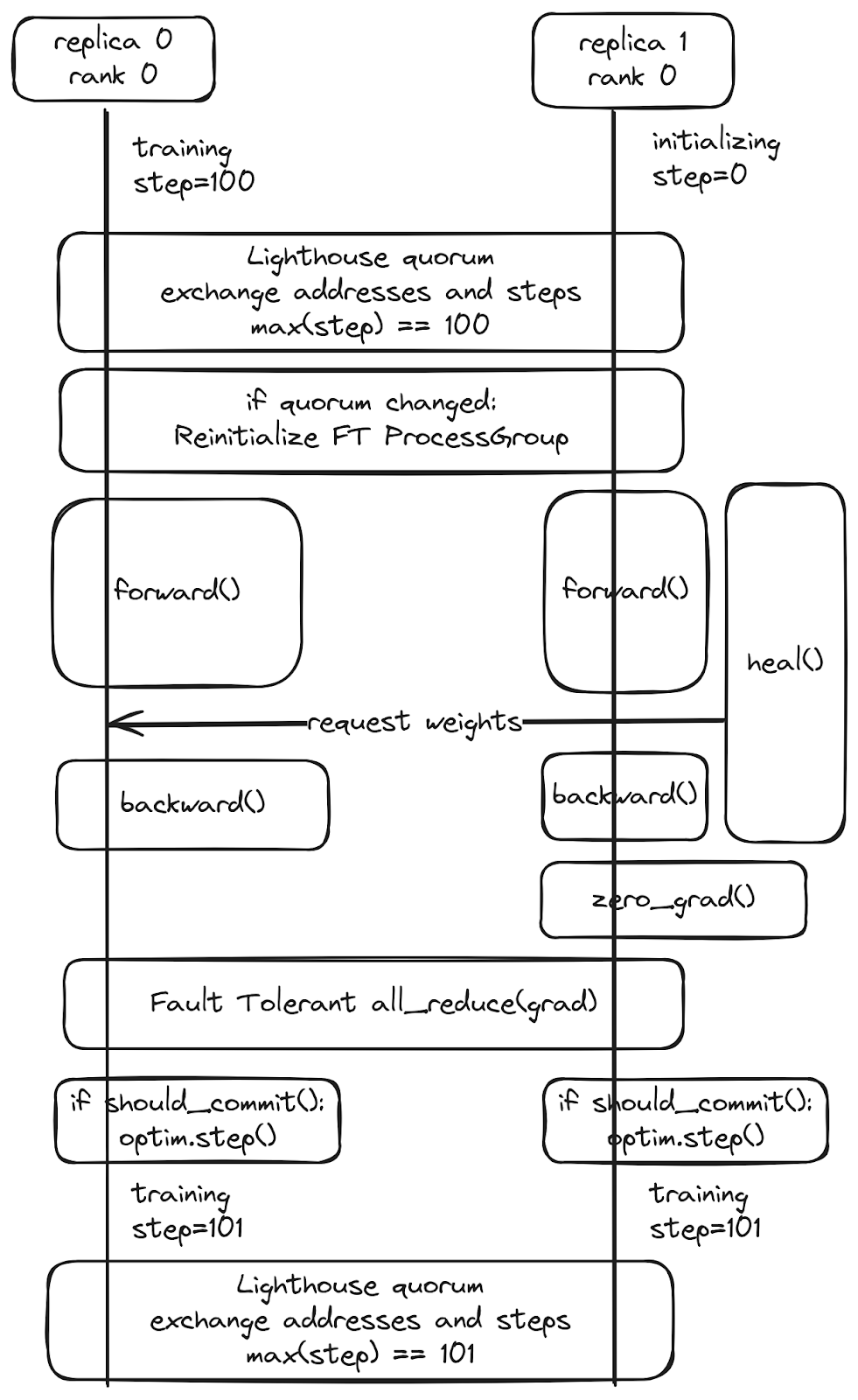
torchft adapts a number of concepts from distributed databases:
- The quorum operation determines which workers are healthy using frequent heartbeats and guarantees that we can quickly determine which workers are alive, exchange metadata in a fault tolerant way, and enforce no split-brain conditions.
- To ensure consistency and identify when we need to recover a worker, we effectively treat training with traditional database semantics. Traditional databases use “transactions” where each operation is either committed (entirely applied) or rolledback (discarded). torchft treats each training step the same way. Each training step within a replica group is handled as a distributed transaction, where we ensure all workers commit the step by stepping the optimizer or if an error occurs they all rollback by discarding the gradients.
For more details, please see the torchft README, which has links to the documentation, design docs, and presentations.
Training Loop Integration
TorchFT has already been integrated with TorchTitan, and thus, enabling it is just a matter of setting a configuration flag. For a typical model, torchft provides wrappers which automatically call hooks into torchft’s Manager to provide fault tolerance.
from torchft import Manager, DistributedDataParallel, Optimizer, ProcessGroupGloo # Instantiate your model and optimizer as normal m = nn.Linear(2, 3) optimizer = optim.AdamW(m.parameters()) # Setup torchft Manager and wrap the model and optimizer. manager = Manager( pg=ProcessGroupGloo(), load_state_dict=lambda state_dict: m.load_state_dict(state_dict), state_dict=lambda: m.state_dict(), ) m = DistributedDataParallel(manager, m) optimizer = Optimizer(manager, optimizer) for batch in dataloader: # When you call zero_grad, we start the asynchronous quorum operation # and perform the async weights recovery if necessary. optimizer.zero_grad() out = m(batch) loss = out.sum() # The gradient allreduces will be done via torchft's fault tolerant # ProcessGroupGloo wrapper. loss.backward() # The optimizer will conditionally step depending on if any errors occured. # The batch will be discarded if the gradient sync was interrupted. optimizer.step()
Fault Tolerant Scheduling
We can use standard ML job schedulers such as Slurm since the semantics for the workers within a replica group are the same as a normal job. If an error occurs on any of the workers within a group we expect the entire group to restart simultaneously. Within each replica group, the application is a completely standard training job using standard non-fault tolerant operations.
To achieve fault tolerance on a traditional scheduler, we run multiple of these jobs. Each replica group ran on Slurm as a separate training job with the Lighthouse and a monitoring script running on the head node. All the cross-group communication is done via torchft’s managed ProcessGroup and quorum APIs. To restart groups on failure and inject failures we used a small script using the torchx Python API.
The monitoring script looks something like this:
from torchx.runner import get_runner NUM_REPLICA_GROUPS = 30 with get_runner() as runner: while True: jobs = runner.list(scheduler) active_replicas = { parse_replica_id(job.name) for job in jobs if not job.is_terminal() } missing_replicas = set(range(NUM_REPLICA_GROUPS)) - active_replicas for replica_id in missing_replicas: app_def = make_app_def(replica_id=replica_id) app_handle = runner.run( app_def, scheduler="slurm", cfg={"partition": "batch"}, ) print("launched:", replica_id, app_handle) time.sleep(5.0)
The failures were injected by cancelling the specific replica group’s Slurm job using scancel. In a real world scenario we would expect the failure to be triggered by an error in the training process which would crash that replica group in isolation rather than an external failure.
Metrics and Logs
To ensure we had a consistent view of the job, we avoided injecting failures into one replica group to make it simpler to track metrics and quorum events for the job. That one group was able to consistently log the number of participants, step success/failures, and the loss.
Since we’re doing per step fault tolerance, the number of participants and thus batch size changes per step depending on which workers are healthy.
The loss is averaged across all workers/replica groups in the job using an allreduce across replica groups.
Note: the small little spikes in the loss graphs below are due to how we average the loss across all hosts, including recovering workers, which have out of date weights, which leads to incorrectly higher loss on those steps.
Runs
We ran three different runs showcasing various failure scenarios and features of torchft.
Run 1: Injected Failure Every 60s for 1100 Failures
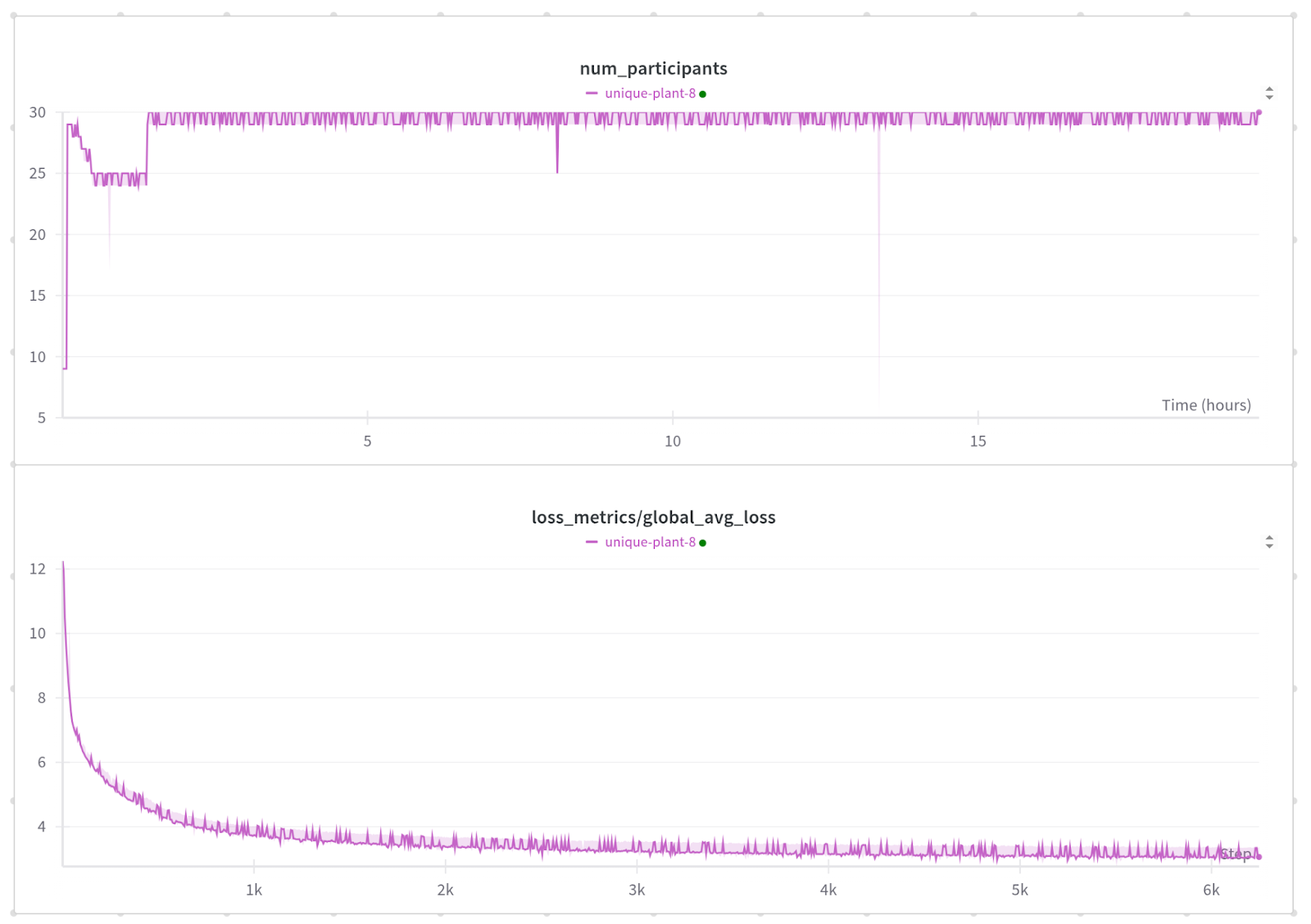
This run lasted a little over 19 hours and 6249 steps. On average, each step took 10.9 seconds.
For the initial run, we injected a failure every 60 seconds with a very repeatable pattern. We initially had a bad machine in the cluster, so we briefly shrunk the world size to 25 hosts until the machine was replaced, and we scaled the job back up with zero downtime.
With the failure every 60s we expected to be able to do ~5 steps between each failure without any issue. Looking at the results, we see that there were 6249 steps and 5145 successful commits. torchft is designed to be as safe as possible, and if any errors occurred, it will discard the step via “should_commit” prior to running the optimizer.
For the overall step efficiency, we have:
5145 successful steps / 6249 total steps = 82.3%
With a step time of ~11 seconds and a failure every 60 seconds we should be able to complete 5 out of every 6 steps (83.3%) and that matches almost exactly with the measured performance.
We averaged 29.6 participating replica groups per step, so the total training efficiency of this was 81.2%. Not bad for over 1000 failures.
Run 2: Injected Failure Every 15s for 1015 Failures
We wanted to see how much further we could push this and also make it even more challenging. For the second run, we ran with a failure injected between 0-30 seconds with a failure on average every 15 seconds.
This failure rate is extreme compared to training jobs, which typically have mean time between failures in the 10s of minutes to hours range, but lets us validate that we can recover no matter when the error happens and lets us run a huge amount of test cycles to gain confidence in our implementation.
By randomizing the failure interval, we cause failures to happen while workers are still initializing rather than in steady state and are much more likely to hit edge cases. We’re happy to report that torchft behaved as expected with no unrecoverable errors.
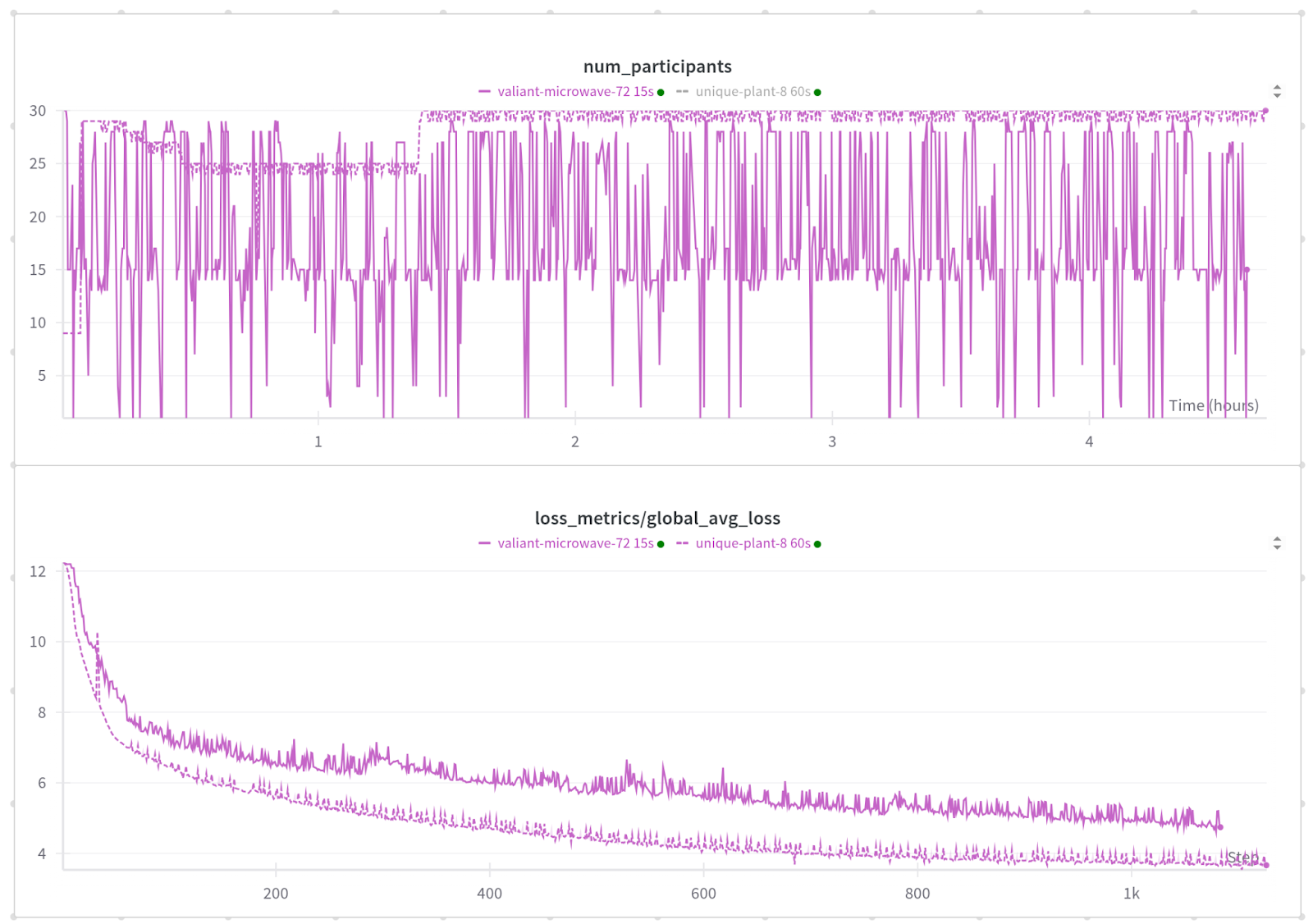
As you can see, this job is behaving much more erratically. Rather than the very close to 30 machines we had with a 60 second failure rate, with a failure every 15 seconds we’re anywhere from 1 machine to 30 machines available on each step.
On average, we had 18.9 (18.9/30 = 63%) workers healthy and participating on any given step and an average step time of 15.46 seconds.
Out of the first 888 steps, 268 of those steps were committed successfully, which gives us a 30.2% step efficiency.
This gives us training efficiency of just 13.4%, which in any normal training job would be terrible but it’s remarkable that the model is converging despite a crash every 15 seconds! Just loading a model from a checkpoint often takes longer than 1 minute.
The loss converges slower as compared to our 60s MTBF run, but that’s expected as many more batches are being discarded due to errors.
We do see some bigger spikes in the loss, which are correlated with times when only 1 participant is healthy and thus has 1/30th the batch size. This is easily avoided by adjusting the minimum number of replicas. We had it set to 1 for this test.
Run 3: Semi-synchronous Training
TorchFT also supports semi-synchronous training algorithms, including LocalSGD and DiLoCo, with plans to add more in the future. Unlike HSDP2, these algorithms do not synchronize at every step. Instead, they perform local training for several steps before synchronizing weights through averaging parameters or gradients. This approach enhances performance by reducing communication costs to once every N steps (a configurable hyperparameter), rather than at every step. Our tests on the cluster demonstrate a noticeable improvement in throughput. When synchronizing every 40 steps, we minimize the communication overhead, resulting in higher overall throughput. Below is a comparison of DiLoCo’s throughput (yellow), averaging around 4000 tps, compared with that of regular HSDP2 (purple), which averages around 1200 tps.
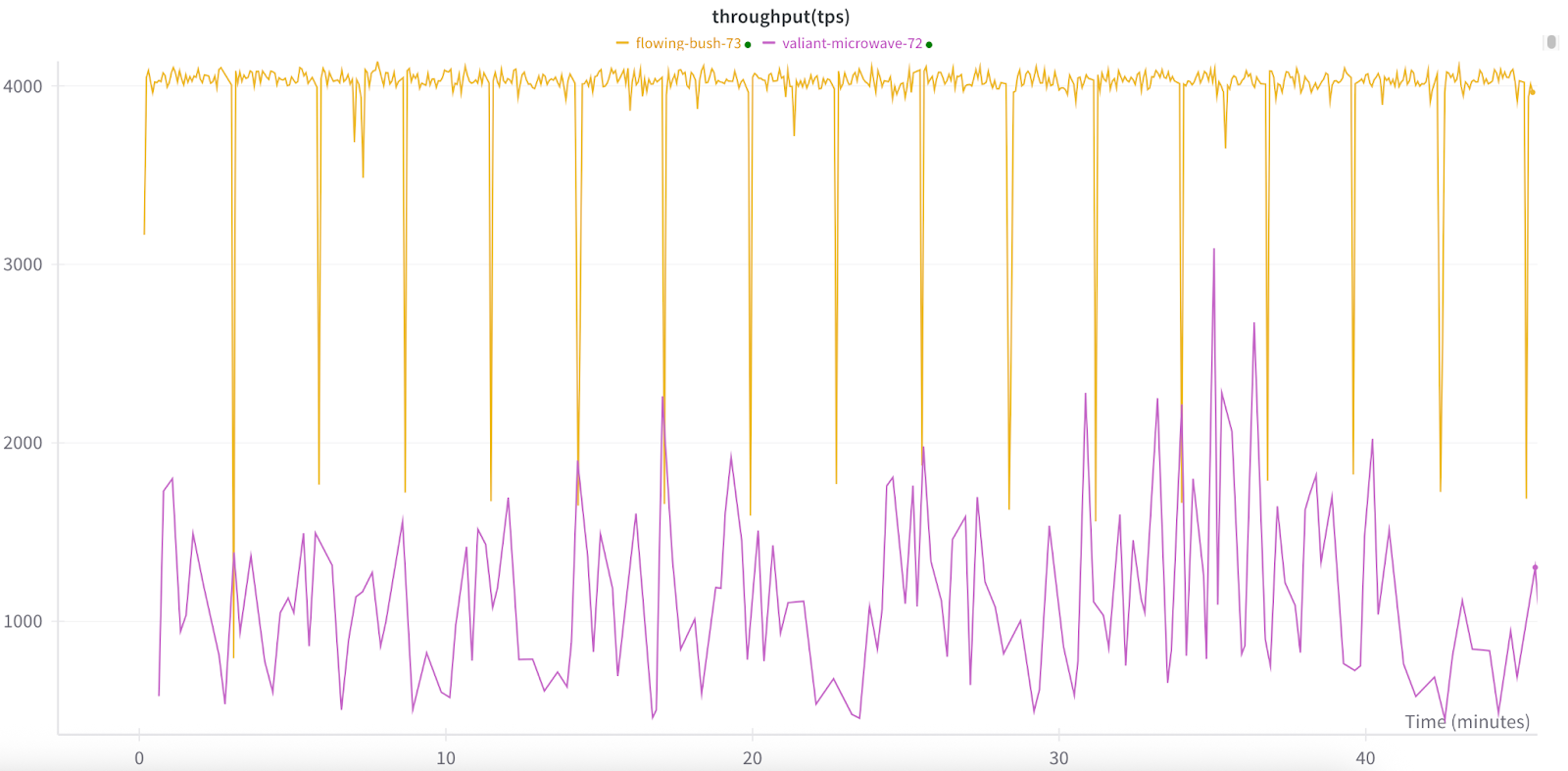
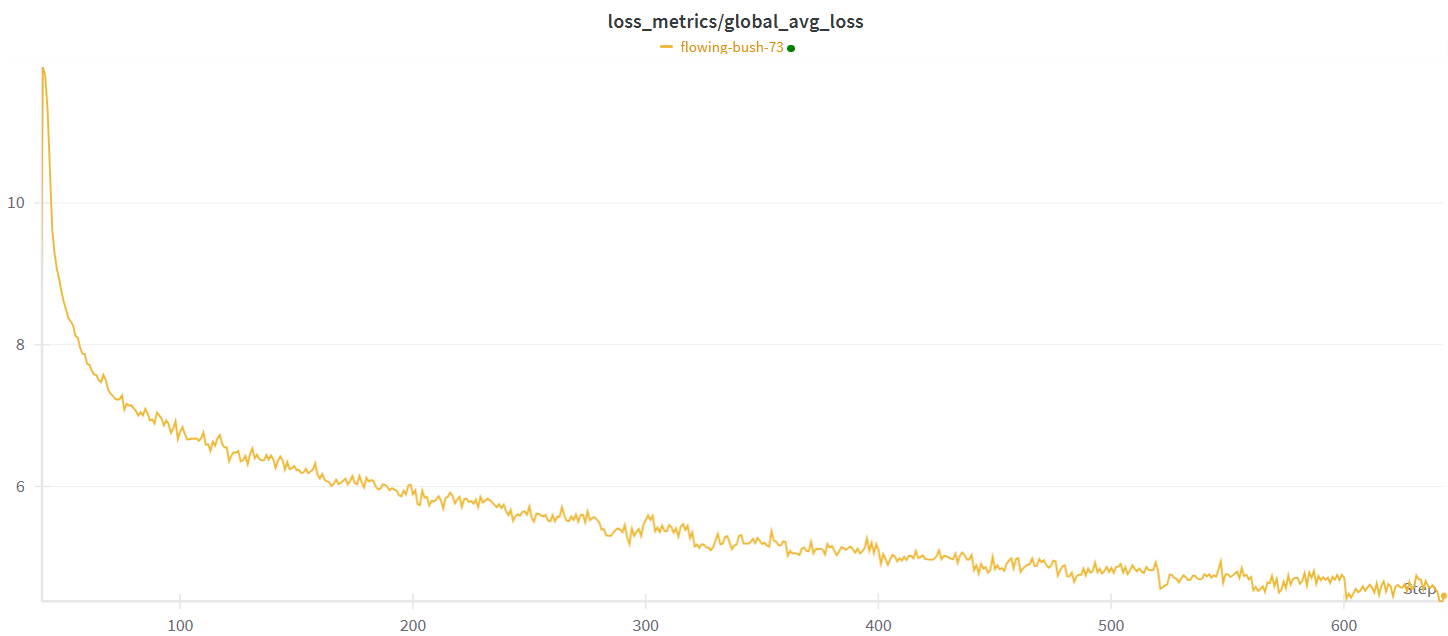
Naturally, the longer the interval between synchronizations, the more the models within replica groups will diverge. This divergence can potentially impact the convergence of the model. However, in our testing, we observed that the model was still able to train effectively and reach convergence despite these longer synchronization intervals. This resilience is beneficial in dynamic environments where replicas might leave the group unexpectedly. Even in such scenarios, the model demonstrated the ability to continue training without significant disruption.
Next Steps
torchft is under active development, and we have a lot of planned improvements around newer algorithms such as streaming DiLoCo, making PyTorch Distributed more robust to failures (even on infiniband/nvlink!), and even more efficient.
If you’re interested in using torchft please take a look at torchft README and torchft Documentation. We’d also love to chat with you, so feel free to reach out directly via GitHub, LinkedIn, or Slack.