
In the race to accelerate large language models across diverse AI hardware, FlagGems delivers a high-performance, flexible, and scalable solution. Built on Triton language, FlagGems is a plugin-based PyTorch operator and kernel library designed to democratize AI compute. Its mission: to enable a write-once, JIT-everywhere experience, so developers can deploy optimized kernels effortlessly across a wide spectrum of hardware backends. FlagGems recently joined the PyTorch Ecosystem upon acceptance by the PyTorch Ecosystem Working Group.
With over 180 operators already implemented—spanning native PyTorch ops and widely used custom ops for large models—FlagGems is evolving fast to keep pace with the generative AI frontier.
To view the PyTorch Ecosystem, see the PyTorch Landscape and learn more about how projects can join the PyTorch Ecosystem.
Key Features
- Extensive Operator Library: 180+ PyTorch-compatible operators and growing
- Performance Optimized: Select operators hand-tuned for speed
- Torch.compile Independent: Fully functional in eager mode
- Pointwise Operator Codegen: Auto-generates kernels for arbitrary input types and layouts
- Fast Kernel Dispatching: Per-function runtime dispatch logic
- C++ Triton Dispatcher: In development for even faster execution
- Multi-Backend Ready: Works across 10+ hardware platforms with a backend-neutral runtime API
Architecture
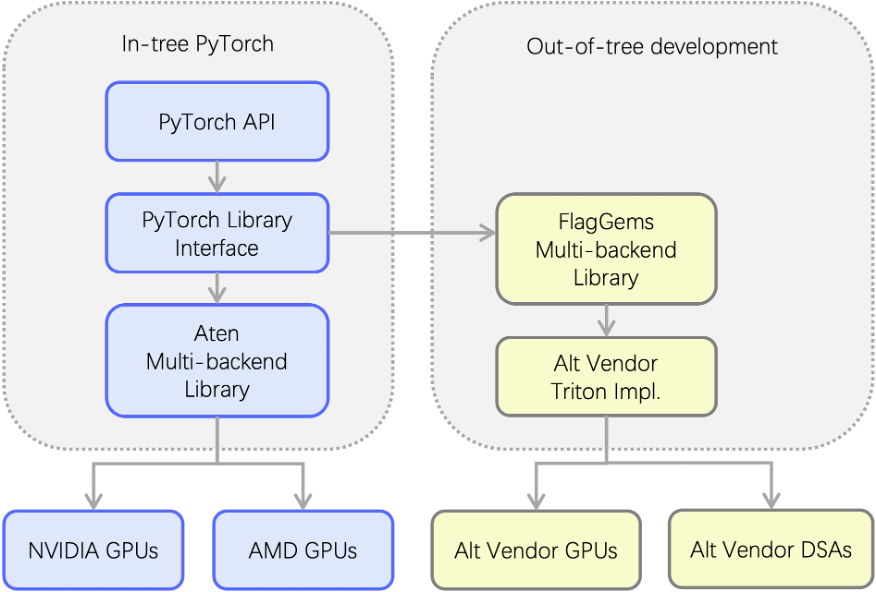
FlagGems extends the PyTorch dispatch system out-of-tree through a multi-backend library powered by Triton. It intercepts ATen operator calls and provides backend-specific Triton implementations, making it easy to support alternative GPUs and domain-specific accelerators (DSAs).
Plug-and-Play
- Registers with PyTorch’s dispatch system
- Intercepts ATen operator calls
- Seamlessly replaces CUDA operator implementations
Write Once, Compile Anywhere
- Unified operator library code
- Compilable on any backend with Triton support
- Supports GPUs and heterogeneous chips like DSAs
Getting Started in 3 Steps
- Install dependencies
pip install torch>=2.2.0 # 2.6.0 preferred pip install triton>=2.2.0 # 3.2.0 preferred
- Install FlagGems
git clone https://github.com/FlagOpen/FlagGems.git cd FlagGems pip install --no-build-isolation . or editable install: pip install --no-build-isolation -e .
- Enable FlagGems in your project
import flag_gems flag_gems.enable() # Replaces supported PyTorch ops globally
Prefer finer control? Use a managed context:
with flag_gems.use_gems(): output = model.generate(**inputs)
Need explicit ops?
out = flag_gems.ops.slice_scatter(inp, dim=0, src=src, start=0, end=10, step=1)
Automatic Codegen for Pointwise Ops
With the @pointwise_dynamic decorator, FlagGems can auto-generate efficient kernels with broadcast, fusion, and memory layout support. Here’s an example implementing fused GeLU and element-wise multiplication:
@pointwise_dynamic(promotion_methods=[(0, 1, “DEFAULT”)]) @triton.jit
def gelu_tanh_and_mul_kernel(x, y): x_fp32 = x.to(tl.float32) x_gelu = 0.5 * x_fp32 * (1 + tanh(x_fp32 * 0.79788456 * (1 + 0.044715 * pow(x_fp32, 2)))) return x_gelu * y
Performance Validation
FlagGems includes built-in testing and benchmarking:
- Accuracy Testing
cd tests pytest test_<op_name>_ops.py --ref cpu
- Performance Benchmarks
cd benchmark pytest test_<op_name>_perf.py -s # CUDA microbenchmarks pytest test_<op_name>_perf.py -s --mode cpu # End-to-end comparison
Benchmark Results
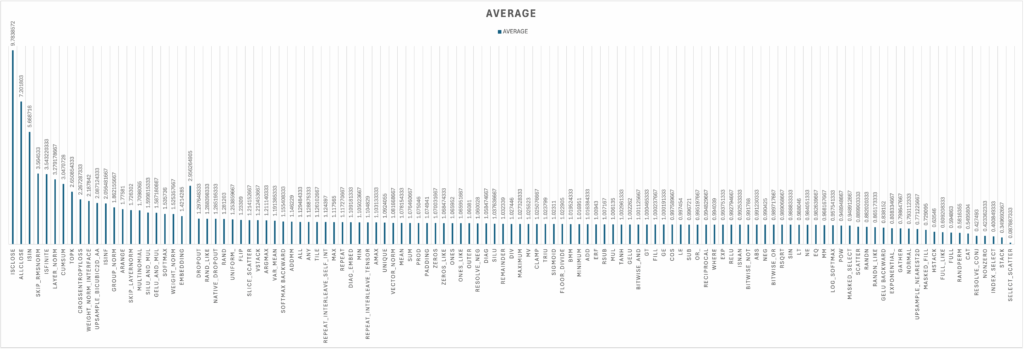
Initial benchmark results of FlagGems showcase its performance against PyTorch’s native operator implementations. The results represent the average measured speedups, a value greater than 1 indicating that FlagGems is faster than the native PyTorch operator. For a vast majority of operators, FlagGems either matches or significantly surpasses the performance of PyTorch’s native implementations.
For a significant portion of the 180+ operators, FlagGems achieves a speedup close to 1.0, indicating performance on par with the native PyTorch implementations.
Some of the core operations like LAYERNORM, CROSS_ENTROPY_LOSS, ADDMM and SOFTMAX also show impressive speedups.
Multi-Backend Support
FlagGems is vendor-flexible and backend-aware:
Set the desired backend with:
export GEMS_VENDOR=<vendor>
Check active backend in Python:
import flag_gems print(flag_gems.vendor_name)

Summary
FlagGems delivers a unified kernel library for large models acceleration that bridges software portability and hardware performance. With broad backend support, a growing op set, and advanced codegen features, it’s your go-to Triton playground for pushing the limits of AI compute.