Introduction
We integrate mixed and low-precision training with Opacus to unlock increased throughput and training with larger batch sizes. Our initial experiments show that one can maintain the same utility as with full precision training by using either mixed or low precision. These are early-stage results, and we encourage further research on the utility impact of low and mixed precision with DP-SGD.
Opacus is making significant progress in meeting the challenges of training large-scale models such as LLMs and bridging the gap between private and non-private training. In 2024, we introduced Fast Gradient Clipping to Opacus to reduce the memory footprint of the hooks-based implementation of DP-SGD. Recently, the added capability of fully sharded data parallelism (FSDP) scales training of large models across devices.
Mixed precision training, which combines different numerical precisions, has been effective in speeding up training and reducing memory usage while maintaining model utility. By using low-precision (e.g., BF16) operations alongside single-precision (FP32) operations, larger models can be trained with larger batch sizes and faster matrix operations. As an example, Llama 3 models were trained using a mix of FP32 and BF16, whereas Llama 4 used BF16 and FP8. We invite developers and researchers to experiment with scaling Opacus training to larger models by taking advantage of mixed precision and other recently introduced techniques.
Mixed and low precision training
Single-precision floating-point numbers are represented by 32 bits. Newer GPUs support high-throughput arithmetic operations with floating-point representations of 16 or 8 bits. These efficiency gains have been adopted in deep learning applications where, generally, lower precision does not harm model performance.
In low precision training, forward and backward passes and weight updates are all performed in a low precision data type (e.g., BF16 or FP8). However, weight updates in low precision can be numerically unstable.
As an alternative, mixed precision training maintains weight updates in high precision (FP32) and only uses low precision (e.g., BF16) for the forward and backward passes. Additionally, some layers, such as normalization layers, also perform operations in FP32 to maintain numerical stability.
To enable mixed precision training with Opacus, we add logic to handle the computation of per-sample gradients when activations and backprops have different precision types (as happens with the two green boxes in Figure 1). This logic is implemented inside the functions that calculate per-sample gradients (e.g., here).
Figure 1. Forward and backward pass with mixed precision training. LayerNorm forward pass happens in full precision. Linear layer operations (and most other layers) are in low precision. The output of one layer is the input to the next layer.

Figure 2. Weight update with mixed precision. Weights are always stored in full precision. Backprops are cast up to full precision.

How to use mixed and low precision training with Opacus
Low and mixed precision training with Opacus is achieved with just a few extra lines of code. It looks very similar to non-private training. Recall that Opacus wraps training components, such as model, optimizer, and dataloaders, into the PrivacyEngine, the main interface of the library. Thereafter, the training loop is identical to native PyTorch.
Low precision training
Compared to full precision training with Opacus, we only need to:
- cast model weights to the lower precision before training starts, and
- cast inputs to lower precision.
from opacus import PrivacyEngine # cast model weights to lower precision before training model = model.to(torch.bfloat16) model.train() privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # cast input to lower precision # integer inputs should stay as integers # (if y is a float, y should also be cast) if x.is_floating(): x = x.to(torch.bfloat16) # proceed with training step as usual output = model(x) optimizer.zero_grad() loss = criterion(output, y) loss.backward() optimizer.step()
Mixed precision training
PyTorch supports mixed-precision training through the torch.amppackage, which we also leverage. The forward pass and loss computation are within the context, whereas the backward pass should be outside of the context. The main change here is the addition of the torch.amp context.
from opacus import PrivacyEngine privacy_engine = PrivacyEngine() model, optimizer, dataloader = privacy_engine.make_private( module=model, optimizer=optimizer, data_loader=dataloader, noise_multiplier=noise_multiplier max_grad_norm=max_grad_norm ) for x, y in train_loader: # mixed precision training context for forward pass with torch.amp.context("cuda", dtype=torch.bfloat16): output = model(x) optimizer.zero_grad() loss = criterion(output, y) # backward pass is outside of amp context loss.backward() optimizer.step()
BERT fine-tuning task
We experiment with fine-tuning a pre-trained BERT-base model with the SNLI dataset (similar to this Opacus tutorial). We consider two common fine-tuning setups for DP-SGD:
- fine-tuning only the last few layers of the model, while freezing all other layers, or
- fine-tuning all layers with LoRA (low-rank adaptation).
In the first case, ghost clipping improves memory usage given the large width of linear layers. In the second case, ghost clipping is not useful since the effective layer width with LoRA is very small.
We use either FP32 only, BF16 only, or mixed-precision for training.
We find that while non-private training has the same utility across all precision settings, DP-SGD fine-tuning of the last few layers with BF16 has a drop in performance. Mixed precision training recovers this utility loss. With LoRA fine-tuning, DP-SGD maintains the same utility across all precision settings. We hypothesize that low precision training with DP-SGD performs best when fine-tuning only linear layers, as is the case with LoRA. However, it harms utility when other types of layers are involved (e.g., normalization layers), which typically require high precision operations. Thus, LoRA is our recommended fine-tuning setting for DP-SGD with low/mixed precision.
Memory and speed improvements
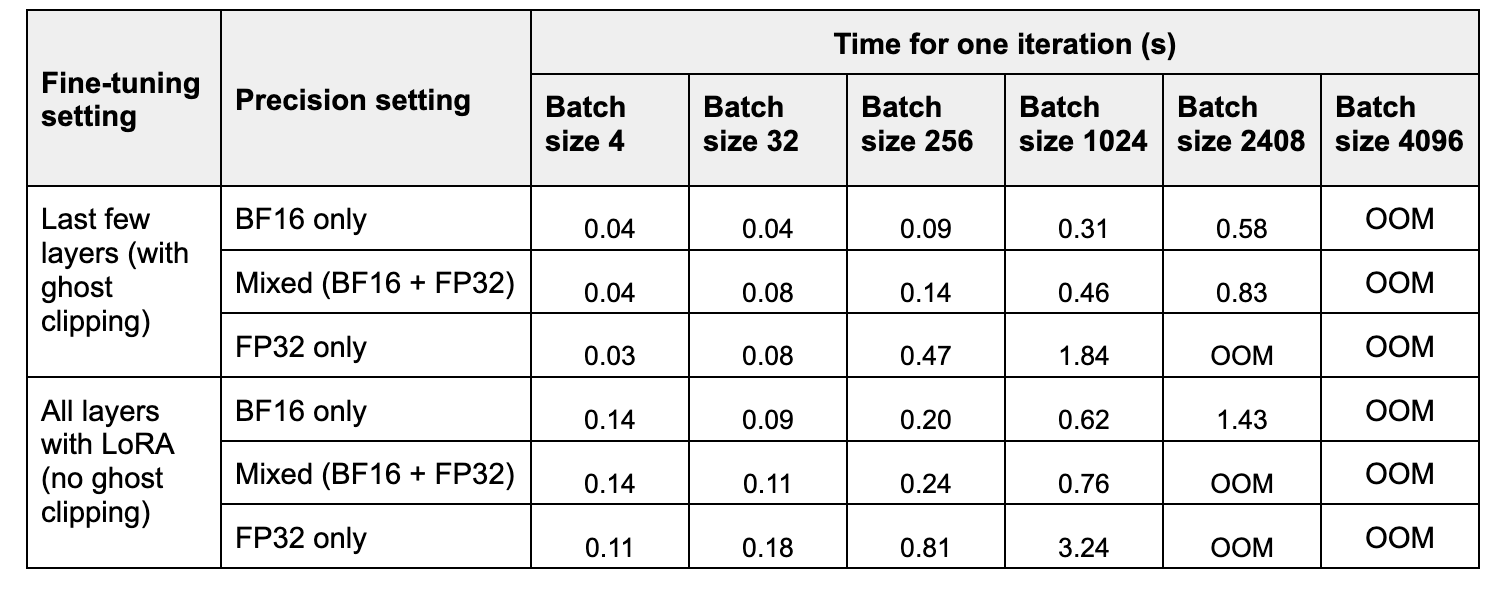
In Table 2, we compare peak memory and time taken for one forward and backward pass for three precision settings. BF16 improves peak memory ~2x, compared to FP32, whereas mixed precision improves it ~1.2-1.4x. Note that at small batch sizes, mixed precision can use more memory than FP32 as model weights are stored twice, in low and high precision.
In Table 2, we compare time for one training step for the three precision settings. BF16 speedup compared to FP32 increases with the batch size, ranging from ~2x to ~6x. Mixed precision training speedups range from ~1x-~4x.
Experiments were performed on a A100 GPU with 40GB of memory.
Table 1. Peak memory for one iteration (forward+backward pass) with increasing batch size.
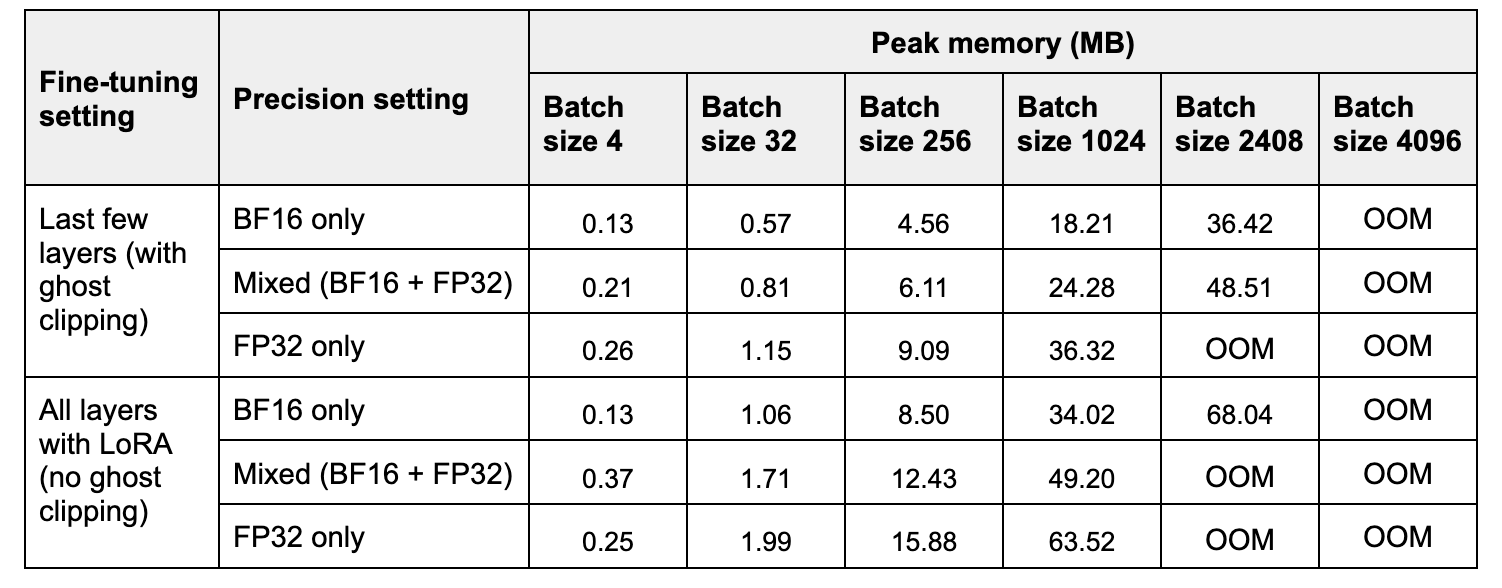
Table 2. Running time of one iteration (averaged over 10 runs), with increasing batch size.
Impact on utility
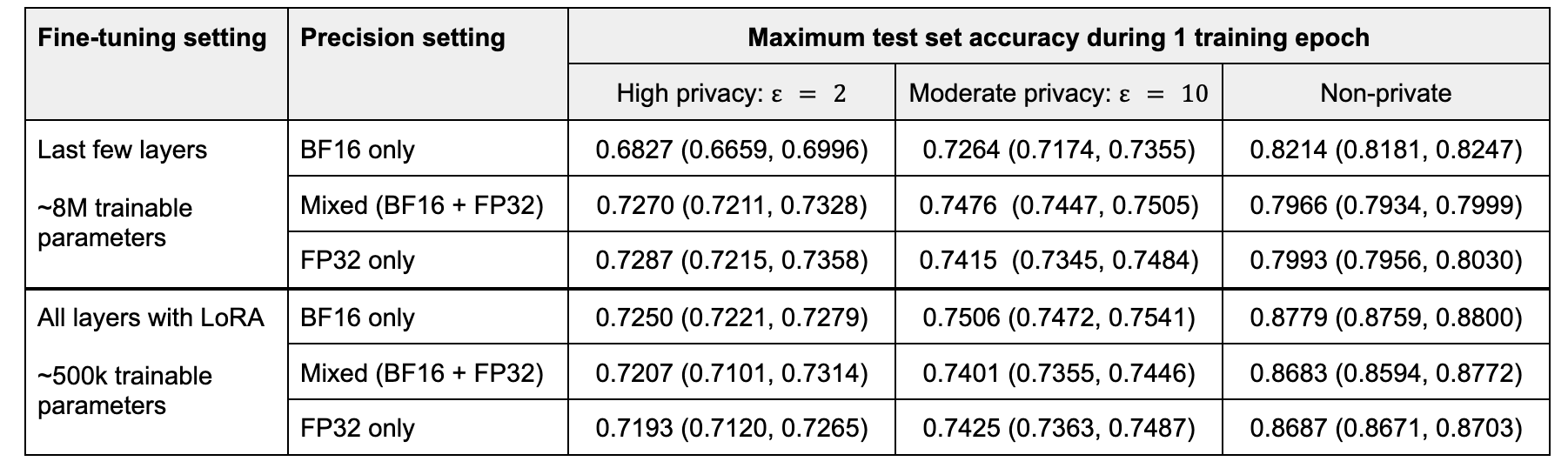
We train for one epoch and measure the maximum test set accuracy achieved during the epoch. We average the maximum accuracy over 5 runs.
When fine-tuning the last few layers, mixed precision and FP32 training achieve on par performance, while low precision training incurs a significant decrease in utility. The utility gap shrinks as the privacy budget increases. In the non-private case, low precision training seems to help performance, likely due to a regularization effect from the noisier matrix operations that counters overfitting.
With LoRA fine-tuning, the highest accuracy is achieved with BF16, with the advantage of BF16 increasing as the privacy budget increases. Mixed and high-precision training are on par.
We hypothesize that low precision training with DP-SGD performs best when fine-tuning only linear layers, as in LoRA. It harms utility when other types of layers are involved in fine-tuning, such as normalization layers, which typically require high-precision operations.
Table 3. Test set accuracy averaged over 5 runs, at different privacy levels. Batch size = 32.
Industry use case
We experiment with fine-tuning a large language model with 8B parameters with DP-SGD and LoRA (~7M trainable parameters). Compared to FP32 training, BF16 achieves a 3.4x increase in samples processed per second, whereas mixed precision achieves a 1.1x increase. We achieve on-par loss and loss convergence speed between all precision settings.
Conclusion
We have integrated a popular technique for training large-scale models into Opacus, further enhancing Opacus’ ability to meet the challenges of private training. With mixed and low precision, Opacus achieves increased throughput and training with larger batch sizes. Our preliminary experiments show that this can be achieved without sacrificing utility. We also provide some insight into which type of precision is most suitable for different fine-tuning settings. We invite developers and the research community to experiment with this new feature and to provide further results on the utility performance of DP-SGD in mixed and low precision settings.
To learn more about Opacus, visit opacus.ai and github.com/pytorch/opacus.