Key Takeaways:
- ExecuTorch 0.7 now enables KleidiAI by default, delivering automatic acceleration on Arm CPUs with zero integration effort.
- GenAI is now performant on millions of existing devices—including 3–5 year-old smartphones and Raspberry Pi 5—thanks to Arm CPU features like SDOT and I8MM.
- On-device use cases like private voice assistants, message summarization, and local code/gen AI copilots are now possible—without the cloud, and without the battery drain.
Arm’s recent SME2 announcement underscores the growing role of Arm KleidiAI as the AI acceleration layer powering the next wave of AI on Arm. By embedding into widely-used Edge AI frameworks like XNNPack, MediaPipe, MNN, ONNX Runtime, and even llama.cpp, KleidiAI has delivered substantial performance improvements with no code changes required by developers. That foundation leads directly to the upcoming ExecuTorch 0.7 beta, where KleidiAI will be enabled by default—bringing automatic acceleration to devices built on the latest Arm CPU architecture, as well as a vast base of existing phones built on earlier generations.
Android and cross-platform developers—whether first- or third-party—gain instant access to KleidiAI AI performance optimizations via ExecuTorch and XNNPack. The result? Faster model startups, lower latency, leaner memory footprints—and no integration hurdles. What previously required custom tuning is now turn-key performance, ready out of the box. This efficiency unlocks new possibilities—not just for the latest high-end devices, but for a much broader range of hardware.
When we consider running Generative AI (GenAI) on mobile devices, it’s easy to envision the latest flagship smartphones equipped with powerful CPUs, GPUs, and NPUs. But what if we told you that GenAI experiences—like running large language models (LLMs)—can also be brought to devices that are 3, 4, or even 5 years old? Or even to the Raspberry Pi 5?
Well, this is now not just a vision, but a practical reality—thanks to the Arm SDOT CPU feature, which has been available in Arm CPUs since 2015.
What is SDOT?
The SDOT (Signed Dot Product) instruction, introduced in the Armv8.2 architecture and later CPUs, enables efficient dot product operations on vectors of 8-bit signed integers. The following image illustrates the behavior of one such SDOT instruction available on Arm CPUs:
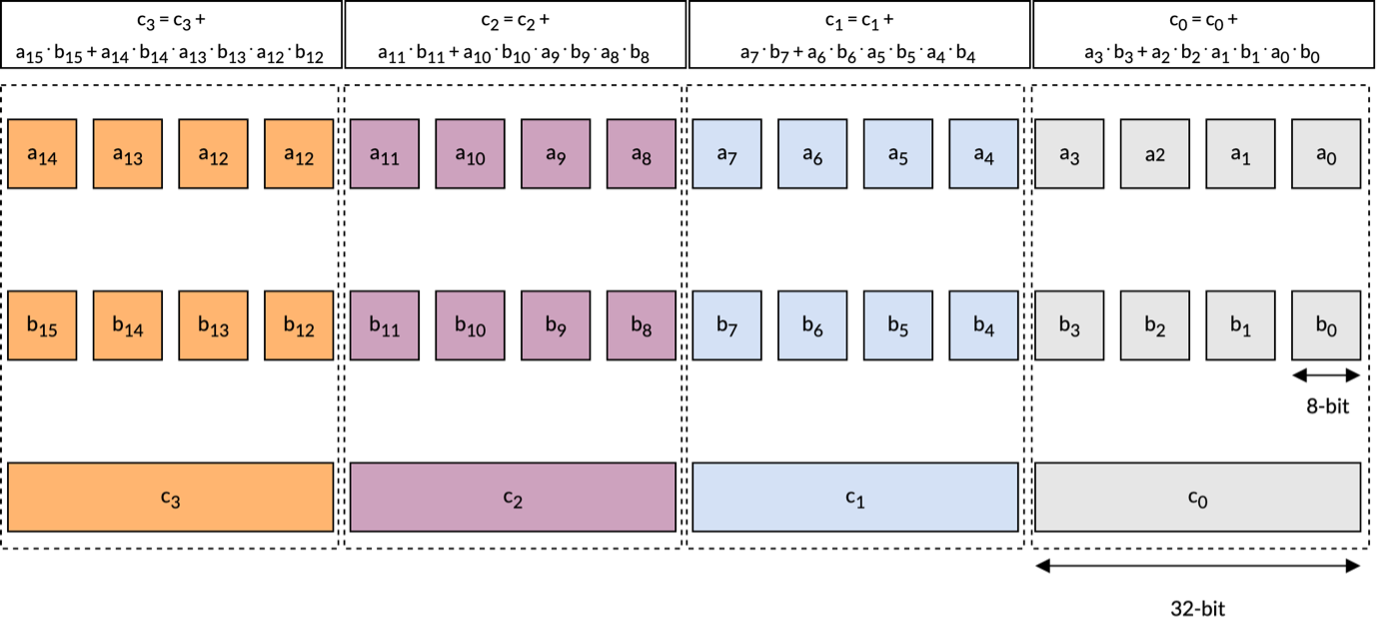 As shown above, the instruction produces four 32-bit integer outputs, each resulting from the dot product of corresponding groups of four int8 elements from the left-hand side (LHS) and right-hand side (RHS) vector registers.
As shown above, the instruction produces four 32-bit integer outputs, each resulting from the dot product of corresponding groups of four int8 elements from the left-hand side (LHS) and right-hand side (RHS) vector registers.
This instruction can be utilized to accelerate matrix multiplication routines—the core computational workload behind every LLM—when using Int8 or lower-bit precision formats, such as Int4. These operations typically involve numerous dot products between individual rows of the left-hand side matrix and corresponding columns of the right-hand side matrix.
The SDOT instruction is already widely supported across a diverse range of devices, opening the door for GenAI use cases to reach a significantly larger smartphone audience. As of today, Arm CPUs in approximately 3 billion Arm-based devices include this capability—enabling powerful on-device GenAI experiences for the majority of users. In fact, 72% of all devices now support this instruction
Thanks to ExecuTorch, we’re now enabling models like Llama 3.2 to run efficiently on the majority of Android devices as well as edge devices like the Raspberry Pi 5.
KleidiAI + ExecuTorch: Bringing It All Together
For last year’s quantized Llama 3.2 1B announcement, the ExecuTorch and KleidiAI teams collaborated to deliver optimizations for the Int4 matrix-multiplication on Arm CPUs leveraging the I8MM feature, available from the armv8.6 architecture onwards. As highlighted in a previous blog post, ExecuTorch with KleidiAI achieves over 20% higher prefill performance on the Galaxy S24+ compared to non-KleidiAI kernels. This translates to more than 350 tokens per second during the prefill phase and over 40 tokens per second during the decode phase. This level of performance is sufficient to enable on-device tasks, such as summarizing unread messages, with a smooth user experience using only Arm CPUs. For context, summarizing around 50 unread messages typically involves processing approximately 600 tokens.
This year, the ExecuTorch and KleidiAI teams have focused on optimizing Int4 matrix multiplication performance by leveraging the SDOT instruction, aiming to broaden adoption. See the XNNPack PR
See the XNNPack PR
While LLM performance on Arm CPUs with only the SDOT extension may not match latest flagship smartphones, it still enables impressive capabilities for on-device generative AI. In fact, in many scenarios, the decode phase is faster than the average human reading speed—highlighting that even older Arm CPUs can support practical and meaningful GenAI use cases.
For example, when combined with speech-to-text and text-to-speech models, a local LLM of this kind enables the creation of a fully private smart assistant that operates entirely offline, eliminating concerns about data privacy while still offering rich voice-based interactions. Such a device could seamlessly interact with your connected devices, ensuring users have peace of mind with their data.
Another compelling use case for running Llama 3.2 1B is context-aware text completion in local text editors. As you type, the model provides intelligent, real-time suggestions to streamline writing or coding workflows—all without requiring an internet connection.
These are just a few examples, and they only scratch the surface of what’s possible with on-device GenAI.
Conclusion: GenAI for Everyone
With the combined power of SDOT, KleidiAI, and ExecuTorch, we’re pushing the boundaries of what’s possible—bringing Generative AI beyond high-end flagship devices and making it accessible on billions of Arm-based devices already in use.
Now it’s your turn—we’re excited to see what you’ll create. To help you get started, check out Arm’s learning path, designed to guide you through developing your own applications with LLMs using ExecuTorch and KleidiAI.