Many companies must tackle the difficult use case of building a highly optimized recommender system. The challenge comes from processing large volumes of data to train and tune the model daily with new data and then make predictions based on user behavior during an active engagement. In this post, we show you how to use Amazon SageMaker Feature Store, a purpose-built repository where you can store, access, and share model features across teams in your company. With both online and offline Feature Store, you can address the complex task of creating a product recommendation engine based on consumer behavior. This post comes with an accompanying workshop and GitHub repo.
The post and workshop are catered towards data scientists and expert machine learning (ML) practitioners who need to build custom models. For the non-data scientist or ML expert audience, check out our AI service Amazon Personalize, which allows developers to build a wide array of personalized experiences without needing ML expertise. This is the same technology powering amazon.com.
Solution overview
In machine learning, expert practitioners know how crucial it is to feed high-quality data when training a model and designing features that influence the model’s overall prediction accuracy. This process is often quite cumbersome and takes multiple iterations to achieve a desired state. This step in the ML workflow is called feature engineering, and usually 60–70% of the process is spent on just this step. In large organizations, the problem is exacerbated and adds to a greater loss of productivity, because different teams often run identical training jobs, or even write duplicate feature engineering code because they have no knowledge of prior work, which leads to inconsistent results. In addition, there is no versioning of features, and having access to the latest feature isn’t possible because there is no notion of a central repository.
To address these challenges, Feature Store provides a fully managed central repository for ML features, making it easy to securely store and retrieve features without the heavy lifting of managing the infrastructure. It lets you define groups of features, use batch ingestion and streaming ingestion, and retrieve the latest feature values with low latency. For more information, see Getting Started with Amazon Sagemaker Feature Store.
The following Feature Store components are relevant to our use case:
- Feature group – This is a group of features that is defined via a schema in Feature Store to describe a record. You can configure the feature group to an online or offline store, or both.
- Online store – The online store is primarily designed for supporting real-time predictions that need low millisecond latency reads and high throughput writes.
- Offline store – The offline store is primarily intended for batch predictions and model training. It’s an append-only store and can be used to store and access historical feature data. The offline store can help you store and serve features for exploration and model training.
Real-time recommendations are time sensitive, mission critical, and depend on the context. Demand for real-time recommendations fades quickly as customers lose interest or demand is met elsewhere. In this post, we build a real-time recommendation engine for an ecommerce website using a synthetic online grocer dataset.
We use Feature Store (both online and offline) to store customers, products, and orders data using feature groups, which we use for model training, validation, and real-time inference. The recommendation engine retrieves features from the online feature store, which is purpose-built for ultra-low latency and high throughput predictions. It suggests the top products that a customer is likely to purchase while browsing through the ecommerce website based on the customer’s purchase history, real-time clickstream data, and other customer profile information. This solution is not intended to be a state-of-the-art recommender, but to provide a rich enough example for exploring the use of Feature Store.
We walk you through the following high-level steps:
- Set up the data and ingest it into Feature Store.
- Train your models.
- Simulate user activity and capture clickstream events.
- Make real-time recommendations.
Prerequisites
To follow along with this post, you need the following prerequisites:
- An AWS instructor-led environment
- A self-paced lab in your own environment, which may incur some charges
Set up data and ingest it into Feature Store
We work with five different datasets based on the synthetic online grocer dataset. Each dataset has its own feature group in Feature Store. The first step is to ingest this data into Feature Store so that we can initiate training jobs for our two models. Refer to the 1_feature_store.ipynb notebook on GitHub.
The following tables show examples of the data that we’re storing in Feature Store.
Customers
| A | customer_id | name | state | age | is_married | customer_health_index |
| 0 | C1 | justin gutierrez | alaska | 52 | 1 | 0.59024 |
| 1 | C2 | karen cross | idaho | 29 | 1 | 0.6222 |
| 2 | C3 | amy king | oklahoma | 70 | 1 | 0.22548 |
| 3 | C4 | nicole hartman | missouri | 52 | 1 | 0.97582 |
| 4 | C5 | jessica powers | minnesota | 31 | 1 | 0.88613 |
Products
| A | product_name | product_category | product_id | product_health_index |
| 0 | chocolate sandwich cookies | cookies_cakes | P1 | 0.1 |
| 1 | nutter butter cookie bites go-pak | cookies_cakes | P25 | 0.1 |
| 2 | danish butter cookies | cookies_cakes | P34 | 0.1 |
| 3 | gluten free all natural chocolate chip cookies | cookies_cakes | P55 | 0.1 |
| 4 | mini nilla wafers munch pack | cookies_cakes | P99 | 0.1 |
Orders
| A | customer_id | product_id | purchase_amount |
| 0 | C1 | P10852 | 87.71 |
| 1 | C1 | P10940 | 101.71 |
| 2 | C1 | P13818 | 42.11 |
| 3 | C1 | P2310 | 55.37 |
| 4 | C1 | P393 | 55.16 |
Clickstream historical
| A | customer_id | product_id | bought | healthy_activity_last_2m | rating |
| 0 | C1 | P10852 | 1 | 1 | 3.04843 |
| 1 | C3806 | P10852 | 1 | 1 | 1.67494 |
| 2 | C5257 | P10852 | 1 | 0 | 2.69124 |
| 3 | C8220 | P10852 | 1 | 1 | 1.77345 |
| 4 | C1 | P10852 | 0 | 9 | 3.04843 |
Clickstream real-time
| A | customer_id | sum_activity_weight_last_2m | avg_product_health_index_last_2m |
| 0 | C09234 | 8 | 0.2 |
| 1 | D19283 | 3 | 0.1 |
| 2 | C1234 | 9 | 0.8 |
We then create the relevant feature groups in Feature Store:
After the feature groups are created and available, we ingest the data into each group:
We don’t ingest data into the click_stream_feature_group because we expect the data to come from real-time clickstream events.
Train your models
We train two models for this use case: a collaborative filtering model and a ranking model. The following diagram illustrates the training workflow.

The collaborative filtering model recommends products based on historical user-product interactions.
The ranking model reranks the recommended products from the collaborative filtering model by taking the user’s clickstream activity and using that to make personalized recommendations. The 2_recommendation_engine_models.ipynb notebook to train the models is available on GitHub.
Collaborative filtering model
We use a collaborative filtering model based on matrix factorization using the Factorization Machines algorithm to retrieve product recommendations for a customer. This is based on a customer profile and their past purchase history in addition to features such as product category, name, and description. The customer’s historical purchase data and product data from the ecommerce store’s product catalog are stored in three separate offline Feature Store feature groups: customers, products, and click-stream-historical, which we created in the last section. After we retrieve our training data, we need to transform a few variables so that we have a proper input for our model. We use two types of transformations: one-hot encoding and TF-IDF.
- Let’s query the Feature Store feature groups we created to get this historical data to help with training:
| A | customer_id | product_id | rating | state | age | is_married | product_name |
| 0 | C6019 | P15581 | 1.97827 | kentucky | 51 | 0 | organic strawberry lemonade fruit juice drink |
| 1 | C1349 | P1629 | 1.76518 | nevada | 74 | 0 | sea salt garden veggie chips |
| 2 | C3750 | P983 | 2.6721 | arkansas | 41 | 1 | hair balance shampoo |
| 3 | C4537 | P399 | 2.14151 | massachusetts | 33 | 1 | plain yogurt |
| 4 | C5265 | P13699 | 2.40822 | arkansas | 44 | 0 | cacao nib crunch stone ground organic |
- Next, prepare the data so that we can feed it to the model for training:
- Then we split the data into train and test sets:
- Finally, we start training using Amazon SageMaker:
- Start training the model using the following:
- When our model has completed training, we deploy a real-time endpoint for use later:
Ranking model
We also train an XGBoost model based on clickstream historical aggregates data to predict a customer’s propensity to buy a given product. We use aggregated features on real-time clickstream data (stored and retrieved in real time from Feature Store) along with product category features. We use Amazon Kinesis Data Streams to stream real-time clickstream data and Amazon Kinesis Data Analytics to aggregate the streaming data using a stagger window query over a period of the last 2 minutes. This aggregated data is stored in an online Feature Store feature group in real time to be subsequently used for inference by the ranking model. For this use case, we predict bought, which is a Boolean variable that indicates whether a user bought an item or not.
- Let’s query the feature groups we created to get data to train the ranking model:
| A | bought | healthy_activity_last_2m | product_health_index | customer_health_index | product_category |
| 0 | 0 | 2 | 0.9 | 0.34333 | tea |
| 1 | 0 | 0 | 0.9 | 0.74873 | vitamins_supplements |
| 2 | 0 | 0 | 0.8 | 0.37688 | yogurt |
| 3 | 0 | 0 | 0.7 | 0.42828 | refrigerated |
| 4 | 1 | 3 | 0.2 | 0.24883 | chips_pretzels |
- Prepare the data for the XGBoost ranking model:
- Split the data into train and test sets:
- Begin model training:
- When our model has completed training, we deploy a real-time endpoint for use later:
Simulate user activity and capture clickstream events
As the user interacts with the ecommerce website, we need a way to capture their activity in the form of clickstream events. In the 3_click_stream_kinesis.ipynb notebook, we simulate user activity and capture these clickstream events with Kinesis Data Streams, aggregate them with Kinesis Data Analytics, and ingest these events into Feature Store. The following diagram illustrates this workflow.

A producer emits clickstream events (simulating user activity) to the Kinesis data stream; we use Kinesis Data Analytics to aggregate the clickstream data for the last 2 minutes of activity.
Finally, an AWS Lambda function takes the data from Kinesis Data Analytics and ingests it into Feature Store (specifically the click_stream feature group).
We simulate customer clickstream activity on a web application like saving products to cart, liking products, and so on. For this, we use Kinesis Data Streams, a scalable real-time streaming service.
- Simulate the clickstream activity with the following code:
The ranking model recommends ranked products to a customer based on a customer’s last 2 minutes of activity on the ecommerce website. To aggregate the streaming infomation over a window of last 2 minutes, we use Kinesis Data Analytics and create a Kinesis Data Analytics application. Kinesis Data Analytics can process data with sub-second latency from Kinesis Data Streams using SQL transformations.
- Create the application with the following code:
- Use the following input schema to define how data from the Kinesis data stream is made available to SQL queries in the Kinesis Data Analytics application:
Now we need to create a Lambda function to take the output from our Kinesis Data Analytics application and ingest that data into Feature Store. Specifically, we ingest that data into our
click streamfeature group. - Create the Lambda function using the lambda-stream.py code on GitHub.
- We then define an output schema, which contains the Lambda ARN and destination schema:
Next, we invoke the API to create the Kinesis Data Analytics application. This application aggregates the incoming streaming data from Kinesis Data Streams using the SQL provided earlier using the input, output schemas, and Lambda function.
- Invoke the API with the following code:
- When the app status is
Ready, we start the Kinesis Data Analytics application: - For this workshop, we created two helper functions that simulate clickstream events generated on a website and send it to the Kinesis data stream:
Now let’s ingest our clickstream data into Feature Store via Kinesis Data Streams and Kinesis Data Analytics. For inference_customer_id, we simulate a customer browsing pattern for unhealthy products like cookies, ice cream, and candy using a lower health index range of 0.1–0.3.
We produce six records, which are ingested into the data stream and aggregated by Kinesis Data Analytics into a single record, which is then ingested into the click stream feature group in Feature Store. This process should take 2 minutes.
- Ingest the clickstream data with the following code:
- Make sure that the data is now in the
click_streamfeature group:
Make real-time recommendations
The following diagram depicts how the real-time recommendations are provided.
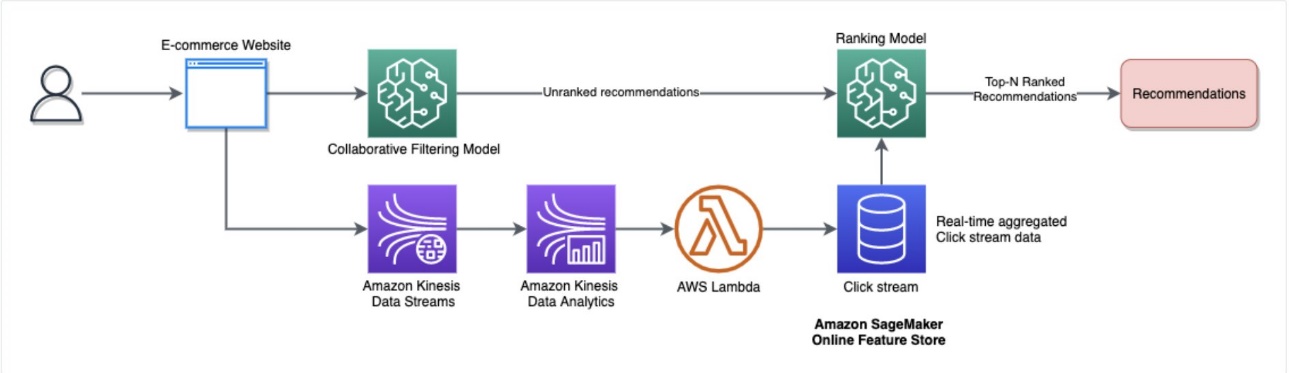
After the model is trained and tuned, the model is deployed behind a live endpoint that the application can query over an API for real-time recommendations on items for a particular user. The collaborative filter model generates offline recommendations for particular users based on past orders and impressions. The clickstream gathers any events on recent browsing and provides this input to the ranking model, which produces the top-N recommendations to provide to the application to display to the user.
Refer to the 4_realtime_recommendations.ipynb notebook on GitHub.
- The first step is to create a
Predictorobject from our collaborative filtering model endpoint (which we created earlier) so that we can use it to make predictions: - Then we pass the cached data to this predictor to get our initial set of recommendations for a particular customer:
- Let’s see the initial recommendations for this customer:
| A | index | customer_id | product_id | state | age | is_married | product_name | predictions |
| 0 | 1 | C3571 | P10682 | maine | 35 | 0 | mini cakes birthday cake | 1.65686 |
| 1 | 6 | C3571 | P6176 | maine | 35 | 0 | pretzel ”shells” | 1.64399 |
| 2 | 13 | C3571 | P7822 | maine | 35 | 0 | degreaser | 1.62522 |
| 3 | 14 | C3571 | P1832 | maine | 35 | 0 | up beat craft brewed kombucha | 1.60065 |
| 4 | 5 | C3571 | P6247 | maine | 35 | 0 | fruit punch roarin’ waters | 1.5686 |
| 5 | 8 | C3571 | P11086 | maine | 35 | 0 | almonds mini nut-thins cheddar cheese | 1.54271 |
| 6 | 12 | C3571 | P15430 | maine | 35 | 0 | organic pork chop seasoning | 1.53585 |
| 7 | 4 | C3571 | P4152 | maine | 35 | 0 | white cheddar bunnies | 1.52764 |
| 8 | 2 | C3571 | P16823 | maine | 35 | 0 | pirouette chocolate fudge creme filled wafers | 1.51293 |
| 9 | 9 | C3571 | P9981 | maine | 35 | 0 | decaf tea, vanilla chai | 1.483 |
We now create a Predictor object from our ranking model endpoint (which we created earlier) so that we can use it to get predictions for the customer using their recent activity. Remember that we simulated recent behavior using the helper scripts and streamed it using Kinesis Data Streams to the click stream feature group.
- Create the
Predictorobject with the following code: - To construct the input for the ranking model, we need to one-hot encode product categories as we did in training:
Now we create a function to take the output from the collaborative filtering model and join it with the one-hot encoded product categories and the real-time clickstream data from our click stream feature group, because this data will influence the ranking of recommended products. The following diagram illustrates this process.

- Create the function with the following code:
- Let’s put everything together by calling the function we created to get real-time personalized product recommendations using data that’s being streamed to Feature Store to influence ranking on the initial list of recommended products from the collaborative filtering predictor:
- Now that we have our personalized ranked recommendations, let’s see what the top five recommended products are:
Clean up
When you’re done using this solution, run the 5_cleanup.ipynb notebook to clean up the resources that you created as part of this post.
Conclusion
In this post, we used SageMaker Feature Store to accelerate training for a recommendation model and improve the accuracy of predictions based on recent behavioral events. We discussed the concepts of feature groups and offline and online stores and how they work together solve the common challenges businesses face with ML and solving complex use cases such as recommendation systems. This post is a companion to the workshop that was conducted live at AWS re:Invent 2021. We encourage readers to use this post and try out the workshop to grasp the design and internal workings of Feature Store.
About the Author
 Arnab Sinha is a Senior Solutions Architect for AWS, acting as Field CTO to help customers design and build scalable solutions supporting business outcomes across data center migrations, digital transformation and application modernization, big data analytics and AIML. He has supported customers across a variety of industries, including retail, manufacturing, health care & life sciences, and agriculture. Arnab holds nine AWS Certifications, including the ML Specialty Certification. Prior to joining AWS, Arnab was a technology leader, Principal Enterprise Architect, and software engineer for over 21 years.
Arnab Sinha is a Senior Solutions Architect for AWS, acting as Field CTO to help customers design and build scalable solutions supporting business outcomes across data center migrations, digital transformation and application modernization, big data analytics and AIML. He has supported customers across a variety of industries, including retail, manufacturing, health care & life sciences, and agriculture. Arnab holds nine AWS Certifications, including the ML Specialty Certification. Prior to joining AWS, Arnab was a technology leader, Principal Enterprise Architect, and software engineer for over 21 years.
 Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
Bobby Lindsey is a Machine Learning Specialist at Amazon Web Services. He’s been in technology for over a decade, spanning various technologies and multiple roles. He is currently focused on combining his background in software engineering, DevOps, and machine learning to help customers deliver machine learning workflows at scale. In his spare time, he enjoys reading, research, hiking, biking, and trail running.
 Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
Vikram Elango is an AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia USA. Vikram helps financial and insurance industry customers with design, thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking and camping with his family.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.