tldr: 1.22x – 1.28x training acceleration with MXFP8, equivalent convergence compared to BF16.
We recently worked with a Crusoe B200 cluster with 1856 GPUs, giving us a first look at training speed improvements using the new MX-FP8 datatype with TorchAO’s implementation and TorchTitan (Llama3-70B, HSDP2, Context Parallel=2). This work is similar in spirit to our previous large-scale training on Crusoe H200s.
Our tests showed successful loss curve equivalence and speedups between 1.22x and 1.28x as compared to training in BF16, even at the full 1856-GPU scale.

- Note that these results were with an earlier [v0.10, April 2025] version of TorchAO, and the relevant kernels have continued to improve and thus would yield faster results if run again.
Remarkably, we observed only about a 5% performance difference when scaling from 4 to 188 nodes, a 47x increase in total world size.
Background – Float8 progression via scaling precision:
We have previously used various implementations of float8, with increasing levels of scaling precision. The scaling factor scope moved from tensorwise, or one scale for the entire tensor, to rowwise, or one scaler per row, and now to MX-style, which is one scaling factor per every 32 elements.
From there, DeepSeek promoted a finer-grained implementation of float8 where inputs (A matrix) are quantized at 1×128 scaling, and the weights (B matrix) are scaled at 128×128 blockwise.
Around the same time, TorchAO released float8 rowwise where there is a single scaling factor for each row. We previously tested this on Crusoe H200 clusters, showcasing loss convergence.
That leads us to the finest-grained scaling yet, MXFP8.
Originally pioneered by Microsoft, MX has become anOCP standard. For MXFP8 on Nvidia Blackwell, we have a hardware-supported mxfp8 where blocks of 32 elements (1×32) of a tensor are quantized with a single scaling factor.
By intuition, scaling at 1×32 should provide higher precision than say 1×128, and with Blackwell we can ask the hardware to do the quantization with the requirement that extent K % 32 == 0 (basically the tensor must divide evenly by 32 so that we don’t get into padding requirements).

Figure 1: Visual comparison of Float8 Tensorwise, left, vs MXFP8, right (credit: NVIDIA docs)
The other change is that the scaling factor precision moves from FP32 to E8M0 (effectively power of 2 scaling):

Figure 2: Scaling factor dtype comparison (Image credit: NVIDIA docs)
MXFP8 training acceleration results:
With that, we can review the speedups compared to BF16 running TorchTitan with Llama3-70B model size, HSDP2, and Context Parallel=2.
We see a range of speedups from 1.22x at 1504 GPU scale, to 1.285x at 32 gpu scale:

Figure 3: Speedups from training with MXFP8 at various gpu scales
MXFP8 Convergence results:
More importantly, at 1856 scale, we also see near equivalent convergence (slightly favoring mxfp8) from the loss curves:
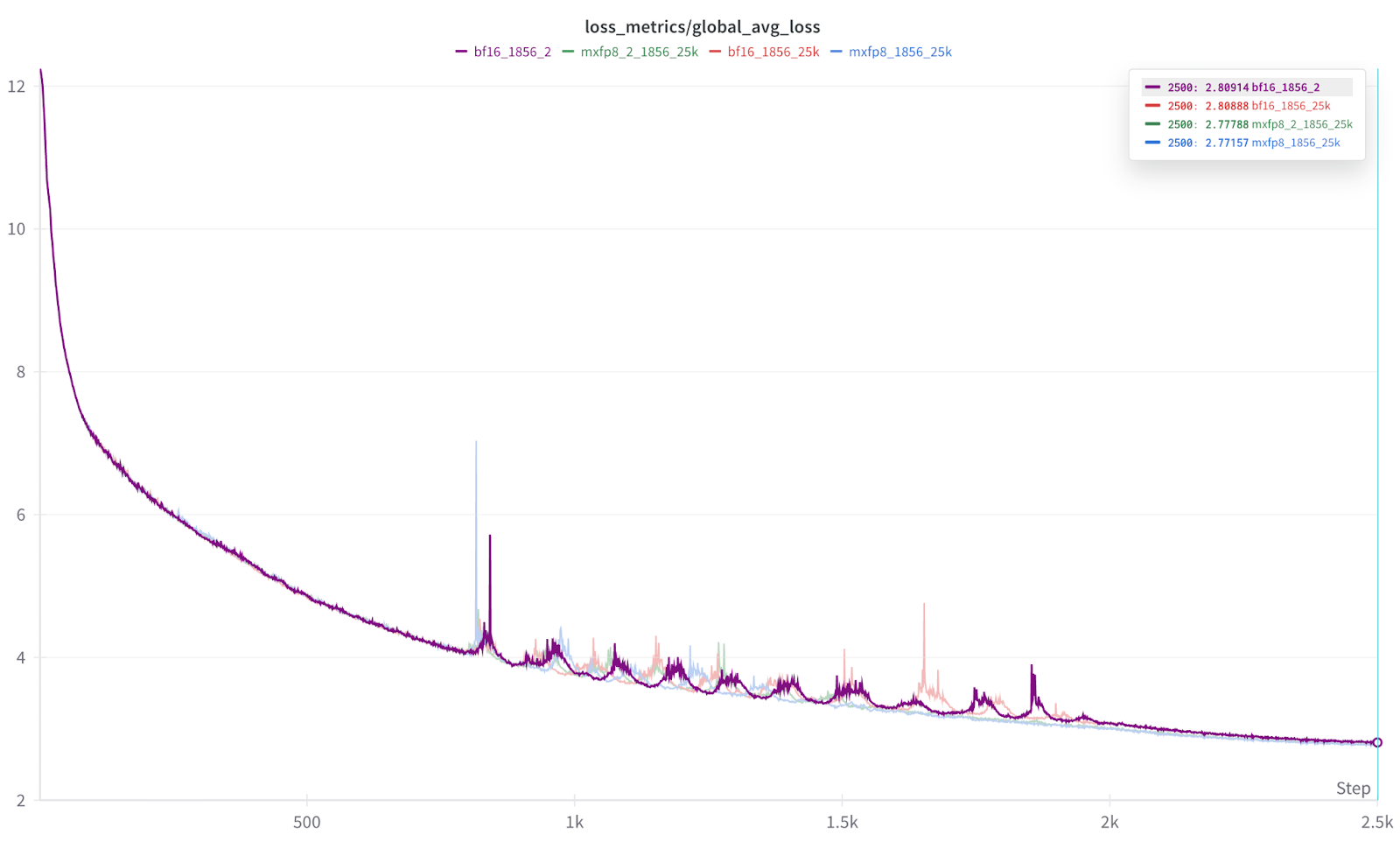
Figure 4: Overlay of loss curves across multiple training runs
And a zoom of the results. Each run was repeated 2x to help prove out result consistency.

Figure 5: final results of each 2500 iteration run.
As you can see from the Figure 5 results, each dtype (BF16, MXFP8) run resulted in nearly indistinguishable final results, and further we also see that the MXFP8 results consistently came out slightly ahead. Thus, in our initial testing, we find that MXFP8 provides both training acceleration and equal to slightly better convergence/accuracy relative to BF16.
Future work:
The purpose of these large-scale runs was to establish initial performance metrics and numerical equivalence in terms of loss convergence with TorchAO’s MXFP8 compared to BF16.
We have already improved the relevant kernels, such as
dim1
In addition, we are planning to explore future MXFP4 and NVFP4 training based on the Quartet paper.