A guest post by Niranjan Hasabnis, Mohammad Ashraf Bhuiyan, Wei Wang, AG Ramesh at Intel The recent growth of Deep Learning has driven the development of more complex models that require significantly more compute and memory capabilities. Several low precision numeric formats have been proposed to address the problem. Google’s bfloat16 and the FP16: IEEE half-precision format are two of the most widely used sixteen bit formats. Mixed precision training and inference using low precision formats have been developed to reduce compute and bandwidth requirements.
The recent growth of Deep Learning has driven the development of more complex models that require significantly more compute and memory capabilities. Several low precision numeric formats have been proposed to address the problem. Google’s bfloat16 and the FP16: IEEE half-precision format are two of the most widely used sixteen bit formats. Mixed precision training and inference using low precision formats have been developed to reduce compute and bandwidth requirements.
Bfloat16, originally developed by Google and used in TPUs, uses one bit for sign, eight for exponent, and seven for mantissa. Due to the greater dynamic range of bfloat16 compared to FP16, bfloat16 can be used to represent gradients directly without the need for loss scaling. In addition, it has been shown that mixed precision training using bfloat16 can achieve the same state-of-the-art (SOTA) results across several models using the same number of iterations as FP32 and with no changes to hyper-parameters.
The recently launched 3rd Gen Intel® Xeon® Scalable processor (codenamed Cooper Lake), featuring Intel® Deep Learning Boost, is the first general-purpose x86 CPU to support the bfloat16 format. Specifically, three new bfloat16 instructions are added as a part of the AVX512_BF16 extension within Intel Deep Learning Boost: VCVTNE2PS2BF16, VCVTNEPS2BF16, and VDPBF16PS. The first two instructions allow converting to and from bfloat16 data type, while the last one performs a dot product of bfloat16 pairs. Further details can be found in the hardware numerics document published by Intel.
Intel has worked with the TensorFlow development team to enhance TensorFlow to include bfloat16 data support for CPUs. We are happy to announce that these features are now available in the Intel-optimized buildof TensorFlow on github.com. Developers can use the latest Intel build of TensorFlow to execute their current FP32 models using bfloat16 on 3rd Gen Intel Xeon Scalable processors with just a few code changes.
Using bfloat16 with Intel-optimized TensorFlow.
Existing TensorFlow 1 FP32 models (or TensorFlow 2 models using v1 compat mode) can be easily ported to use the bfloat16 data type to run on Intel-optimized TensorFlow. This can be done by enabling a graph rewrite pass (AutoMixedPrecisionMkl). The rewrite optimization pass will automatically convert certain operations to bfloat16 while keeping some in FP32 for numerical stability. In addition, models can also be manually converted by following instructions provided by Google for running on the TPU. However, such manual porting requires a good understanding of the model and can prove to be cumbersome and error prone.
TensorFlow 2 has a Keras mixed precision API that allows model developers to use mixed precision for training Keras models on GPUs and TPUs. We are currently working on supporting this API in Intel optimized TensorFlow for 3rd Gen Intel Xeon Scalable processors. This feature will be available in TensorFlow master branch later this year. Once available, we recommend users use the Keras API over the grappler pass, as the Keras API is more flexible and supports Eager mode.
Performance improvements.
We investigated the performance improvement of mixed precision training and inference with bfloat16 on 3 models – ResNet50v1.5, BERT-Large (SQuAD), and SSD-ResNet34. ResNet50v1.5 is a widely tested image classification model that has been included in MLPerf for benchmarking different hardware on vision workloads. BERT-Large (SQuAD) is a fine-tuning task that focuses on reading comprehension and aims to answer questions given a text/document. SSD-ResNet34 is an object detection model that uses ResNet34 as a backbone model.
The bfloat16 models were benchmarked on a 4 socket system with 3rd Gen Intel Xeon Scalable Processors with 28 cores* and compared with FP32 performance of a 4 socket system with 28 core 2nd Gen Intel Xeon Scalable Processors.
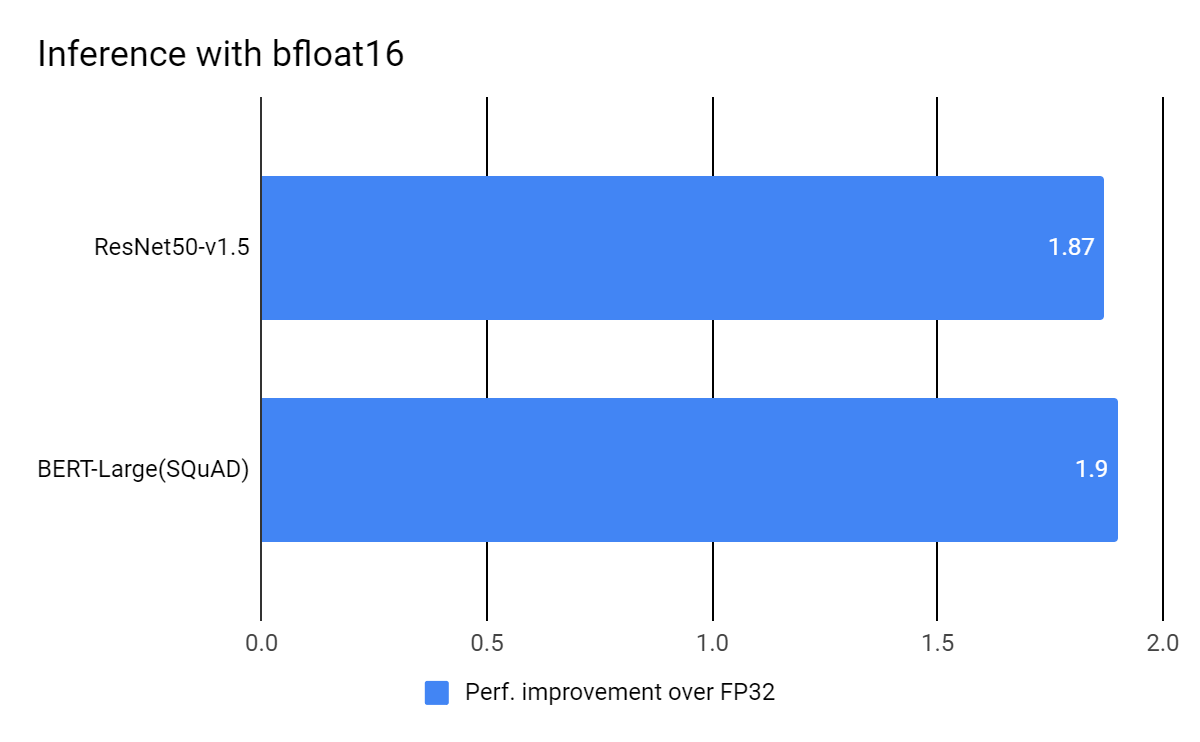
As shown in the charts above, training the models with mixed precision on a 3rd Gen Intel Xeon Scalable Processors with bfloat16 was 1.7x to 1.9x faster than FP32 precision on a 2nd Gen Intel Xeon Scalable Processors. Similarly, for inference, using bfloat16 precision resulted in a 1.87x to 1.9x performance increase.
Accuracy and time to train
In addition to performance measurements, we performed full convergence tests for the three deep learning models on two multi socket 3rd Gen Intel Xeon Scalable processor based systems*. For BERT-Large (SQuAD) and SSD-ResNet34, 4 socket 28 core systems were used. For ResNet50v1.5, we used an 8-socket 28 core system of 3rd Gen Intel Xeon Scalable processors. The models were first trained with FP32, and exactly the same hyper-parameters (learning rate etc.) and batch sizes were used to train the model with mixed precision.  The results above show that the models from three different use cases (image classification, language modeling, and object detection) are all able to reach SOTA accuracy using the same number of epochs. For ResNet50v1.5, the standard MLPerf threshold of 75.9% top-1 accuracy was used and both bfloat16 and FP32 reached the target accuracy in 84th epochs (evaluation every 4 epochs with eval offset of 0). For BERT-Large (SQuAD) fine-tuning task, both Bfloat16 and FP32 used two epochs. SSD-ResNet34, trained in 60 epochs. With the improved run time performance, the total time to train with bfloat16 was 1.7x to 1.9x better than the training time in FP32.
The results above show that the models from three different use cases (image classification, language modeling, and object detection) are all able to reach SOTA accuracy using the same number of epochs. For ResNet50v1.5, the standard MLPerf threshold of 75.9% top-1 accuracy was used and both bfloat16 and FP32 reached the target accuracy in 84th epochs (evaluation every 4 epochs with eval offset of 0). For BERT-Large (SQuAD) fine-tuning task, both Bfloat16 and FP32 used two epochs. SSD-ResNet34, trained in 60 epochs. With the improved run time performance, the total time to train with bfloat16 was 1.7x to 1.9x better than the training time in FP32.
Intel-optimized Community build of TensorFlow
The Intel-optimized build of TensorFlow now supports Intel® Deep Learning Boost’s new bfloat16 capability for mixed precision training and low precision inference in the TensorFlow GitHub master branch. More information on the Intel build is available here. The models mentioned in this blog and scripts to run the models in bfloat16 and FP32 mode are available through the Model Zoo for Intel Architecture (v1.6.1 or later), which you can download and try from here. [Note: To run a bfloat16 model, you will need a Intel Xeon Scalable processor (Skylake) or later generation Intel Xeon Processor. However, to get the best performance of bfloat16 models, you will need a 3rd Gen Intel Xeon Scalable processor.]
Conclusion
As deep learning models get larger and more complicated, the combination of the latest 3rd Gen Intel Xeon Scalable processors with Intel Deep Learning Boost’s new bfloat16 format can achieve a performance increase of up to 1.7x to 1.9x over FP32 performance on 2nd Gen Intel® Xeon® Scalable Processors, without any loss of accuracy. We have enhanced the Intel -optimized build of TensorFlow so developers can easily port their models to use mixed precision training and inference with bfloat16. In addition, we have shown that the automatically-converted bfloat16 model does not need any additional tuning of hyperparameters to converge; you canuse the same set of hyperparameters that you used to train the FP32 models.
Acknowledgements
The results presented in this blog is the work of many people including the Intel TensorFlow and oneDNN teams and our collaborators in Google’s TensorFlow team.
From Intel – Jojimon Varghese , Xiaoming Cui, Md Faijul Amin, Niroop Ammbashankar, Mahmoud Abuzaina, Sharada Shiddibhavi, Chuanqi Wang, Yiqiang Li, Yang Sheng, Guizi Li, Teng Lu, Roma Dubstov, Tatyana Primak, Evarist Fomenko, Igor Safonov, Abhiram Krishnan, Shamima Najnin, Rajesh Poornachandran, Rajendrakumar Chinnaiyan.
From Google – Reed Wanderman-Milne, Penporn Koanantakool, Rasmus Larsen, Thiru Palaniswamy, Pankaj Kanwar.
*For configuration details see www.intel.com/3rd-gen-xeon-configs.
Notices and Disclaimers
Intel’s compilers may or may not optimize to the same degree for non-Intel microprocessors for optimizations that are not unique to Intel microprocessors. These optimizations include SSE2, SSE3, and SSSE3 instruction sets and other optimizations. Intel does not guarantee the availability, functionality, or effectiveness of any optimization on microprocessors not manufactured by Intel. Microprocessor-dependent optimizations in this product are intended for use with Intel microprocessors. Certain optimizations not specific to Intel microarchitecture are reserved for Intel microprocessors. Please refer to the applicable product User and Reference Guides for more information regarding the specific instruction sets covered by this notice.
Read More