Amazon Elastic Compute Cloud (Amazon EC2) G5 instances are the first and only instances in the cloud to feature NVIDIA A10G Tensor Core GPUs, which you can use for a wide range of graphics-intensive and machine learning (ML) use cases. With G5 instances, ML customers get high performance and a cost-efficient infrastructure to train and deploy larger and more sophisticated models for natural language processing (NLP), computer vision (CV), and recommender engine use cases.
The purpose of this post is to showcase the performance benefits of G5 instances for large-scale ML inference workloads. We do this by comparing the price-performance (measured as $ per million inferences) for NLP and CV models with G4dn instances. We start by describing our benchmarking approach and then present throughput vs. latency curves across batch sizes and data type precision. In comparison to G4dn instances, we find that G5 instances deliver consistently lower cost per million inferences for both full precision and mixed precision modes for the NLP and CV models while achieving higher throughput and lower latency.
Benchmarking approach
To develop a price-performance study between G5 and G4dn, we need to measure throughput, latency, and cost per million inferences as a function of batch size. We also study the impact of full precision vs. mixed precision. Both the model graph and inputs are loaded into CUDA prior to inferencing.
As shown in the following architecture diagram, we first create respective base container images with CUDA for the underlying EC2 instance (G4dn, G5). To build the base container images, we start with AWS Deep Learning Containers, which use pre-packaged Docker images to deploy deep learning environments in minutes. The images contain the required deep learning PyTorch libraries and tools. You can add your own libraries and tools on top of these images for a higher degree of control over monitoring, compliance, and data processing.
Then we build a model-specific container image that encapsulates the model configuration, model tracing, and related code to run forward passes. All container images are loaded on into Amazon ECR to allow for horizontal scaling of these models for various model configurations. We use Amazon Simple Storage Service (Amazon S3) as a common data store to download configuration and upload benchmark results for summarization. You can use this architecture to recreate and reproduce the benchmark results and repurpose to benchmark various model types (such as Hugging Face models, PyTorch models, other custom models) across EC2 instance types (CPU, GPU, Inf1).

With this experiment set up, our goal is to study latency as a function of throughput. This curve is important for application design to arrive at a cost-optimal infrastructure for the target application. To achieve this, we simulate different loads by queuing up queries from multiple threads and then measuring the round-trip time for each completed request. Throughput is measured based on the number of completed requests per unit clock time. Furthermore, you can vary the batch sizes and other variables like sequence length and full precision vs. half precision to comprehensively sweep the design space to arrive at indicative performance metrics. In our study, through a parametric sweep of batch size and queries from multi-threaded clients, the throughput vs. latency curve is determined. Every request can be batched to ensure full utilization of the accelerator, especially for small requests that may not fully utilize the compute node. You can also adopt this setup to identify the client-side batch size for optimal performance.
In summary, we can represent this problem mathematically as: (Throughput, Latency) = function of (Batch Size, Number of threads, Precision).
This means, given the exhaustive space, the number of experiments can be large. Fortunately, each experiment can be independently run. We recommend using AWS Batch to perform this horizontally scaled benchmarking in compressed time without an increase in benchmarking cost compared to a linear approach to testing. The code for replicating the results is present in the GitHub repository prepared for AWS Re:Invent 2021. The repository is comprehensive to perform benchmarking on different accelerators. You can refer to the GPU aspect of code to build the container (Dockerfile-gpu) and then refer to the code inside Container-Root for specific examples for BERT and ResNet50.
We used the preceding approach to develop performance studies across two model types: Bert-base-uncased (110 million parameters, NLP) and ResNet50 (25.6 million parameters, CV). The following table summarizes the model details.
| Model Type | Model | Details |
| NLP | twmkn9/bert-base-uncased-squad2 | 110 million parameters Sequence length = 128 |
| CV | ResNet50 | 25.6 million parameters |
Additionally, to benchmark across data types (full, half precision), we use torch.cuda.amp, which provides convenient methods to handle mixed precision where some operations use the torch.float32 (float) data type and other operations use torch.float16 (half). For example, operators like linear layers and convolutions are much faster with float16, whereas others like reductions often require the dynamic range of float32. Automatic mixed precision tries to match each operator to its appropriate data type to optimize the network’s runtime and memory footprint.
Benchmarking results
For a fair comparison, we selected G4dn.4xlarge and G5.4xlarge instances with similar attributes, as listed in the following table.
| Instance | GPUs | GPU Memory (GiB) | vCPUs | Memory (GiB) | Instance Storage (GB) | Network Performance (Gbps) | EBS Bandwidth (Gbps) | Linux On-Demand Pricing (us-east-1) |
| G5.4xlarge | 1 | 24 | 16 | 64 | 1x 600 NVMe SSD | up to 25 | 8 | $1.204/hour |
| G4dn.4xlarge | 1 | 16 | 16 | 64 | 1x 225 NVMe SSD | up to 25 | 4.75 | $1.624/hour |
In the following sections, we compare ML inference performance of BERT and RESNET50 models with a grid sweep approach for specific batch sizes (32, 16, 8, 4, 1) and data type precision (full and half precision) to arrive at the throughput vs. latency curve. Additionally, we investigate the effect of throughput vs. batch size for both full and half precision. Lastly, we measure cost per million inferences as a function of batch size. The consolidated results across these experiments are summarized later in this post.
Throughput vs. latency
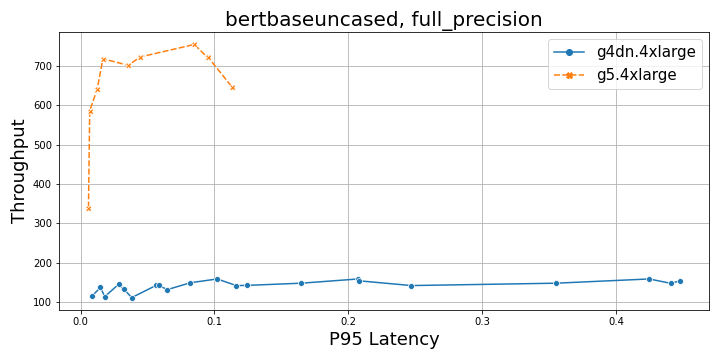
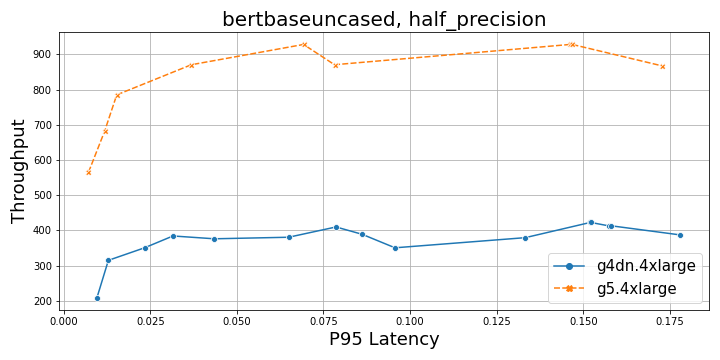
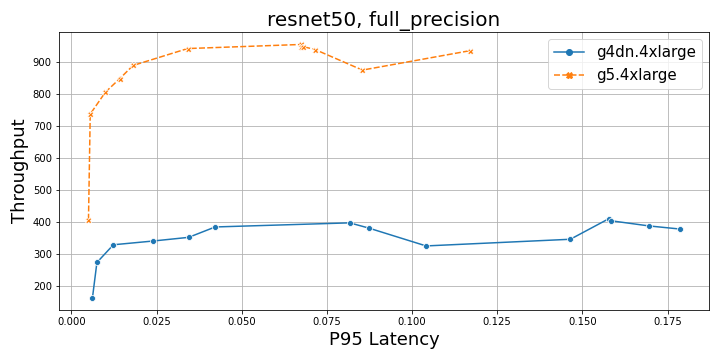
The following figures compare G4dn and G5 instances for NLP and CV workloads at both full and half precision. In comparison to G4dn instances, the G5 instance delivers a throughput of about five times higher (full precision) and about 2.5 times higher (half precision) for a BERT base model, and about 2–2.5 times higher for a ResNet50 model. Overall, G5 is a preferred choice, with increasing batch sizes for both models for both full and mixed precision from a performance perspective.
The following graphs compare throughput and P95 latency at full and half precision for BERT.
 |
 |
The following graphs compare throughput and P95 latency at full and half precision for ResNet50.
 |
 |
Throughput and latency vs. batch size
The following graphs show the throughput as a function of the batch size. At low batch sizes, the accelerator isn’t functioning to its fullest capacity and as the batch size increases, throughput is increased at the cost of latency. The throughput curve asymptotes to a maximum value that is a function of the accelerator performance. The curve has two distinct features: a rising section and a flat asymptotic section. For a given model, a performant accelerator (G5) is able to stretch the rising section to higher batch sizes than G4dn and asymptote at a higher throughput. Also, there is a linear trade-off between latency and batch size. Therefore, if the application is latency bound, we can use P95 latency vs. batch size to determine the optimum batch size. However, if the objective is to maximize throughput at the lowest latency, it’s better to select the batch size corresponding to the “knee” between the rising and the asymptotic sections, because any further increase in batch size would result in the same throughput at a worse latency. To achieve the best price-performance ratio, targeting higher throughput at lowest latency, you’re better off horizontally scaling this optimum through multiple inference servers rather than just increasing the batch size.

Cost vs. batch size
In this section, we present the comparative results of inference costs ($ per million inferences) versus the batch size. From the following figure, we can clearly observe that the cost (measured as $ per million inferences) is consistently lower with G5 vs. G4dn both (full and half precision).
 |
 |
The following table summarizes throughput, latency, and cost ($ per million inferences) comparisons for BERT and RESNET50 models across both precision modes for specific batch sizes. In spite of a higher cost per instance, G5 consistently outperforms G4dn across all aspects of inference latency, throughput, and cost ($ per million inference), for all batch sizes. Combining the different metrics into a cost ($ per million inferences), BERT model (32 batch size, full precision) with G5 is 3.7 times more favorable than G4dn, and with ResNet50 model (32 batch size, full precision), it is 1.6 times more favorable than G4dn.
| Model | Batch Size | Precision |
Throughput (Batch size X Requests/sec) |
Latency (ms) |
$/million Inferences (On-Demand) |
Cost Benefit (G5 over G4dn) |
|||
| . | . | . | G5 | G4dn | G5 | G4dn | G5 | G4dn | |
| Bert-base-uncased | 32 | Full | 723 | 154 | 44 | 208 | $0.6 | $2.2 | 3.7X |
| Mixed | 870 | 410 | 37 | 79 | $0.5 | $0.8 | 1.6X | ||
| 16 | Full | 651 | 158 | 25 | 102 | $0.7 | $2.1 | 3.0X | |
| Mixed | 762 | 376 | 21 | 43 | $0.6 | $0.9 | 1.5X | ||
| 8 | Full | 642 | 142 | 13 | 57 | $0.7 | $2.3 | 3.3X | |
| Mixed | 681 | 350 | 12 | 23 | $0.7 | $1.0 | 1.4X | ||
| . | 1 | Full | 160 | 116 | 6 | 9 | $2.8 | $2.9 | 1.0X |
| Mixed | 137 | 102 | 7 | 10 | $3.3 | $3.3 | 1.0X | ||
| ResNet50 | 32 | Full | 941 | 397 | 34 | 82 | $0.5 | $0.8 | 1.6X |
| Mixed | 1533 | 851 | 21 | 38 | $0.3 | $0.4 | 1.3X | ||
| 16 | Full | 888 | 384 | 18 | 42 | $0.5 | $0.9 | 1.8X | |
| Mixed | 1474 | 819 | 11 | 20 | $0.3 | $0.4 | 1.3X | ||
| 8 | Full | 805 | 340 | 10 | 24 | $0.6 | $1.0 | 1.7X | |
| Mixed | 1419 | 772 | 6 | 10 | $0.3 | $0.4 | 1.3X | ||
| . | 1 | Full | 202 | 164 | 5 | 6 | $2.2 | $2 | 0.9X |
| Mixed | 196 | 180 | 5 | 6 | $2.3 | $1.9 | 0.8X | ||
Additional inference benchmarks
In addition to the BERT base and ResNet50 results in the prior sections, we present additional benchmarking results for other commonly used large NLP and CV models in PyTorch. The performance benefit of G5 over G4dn has been presented for BERT Large models at various precision, and Yolo-v5 models for various sizes. For the code for replicating the benchmark, refer to NVIDIA Deep Learning Examples for Tensor Cores. These results show the benefit of using G5 over G4dn for a wide range of inference tasks spanning different model types.
| Model | Precision | Batch Size | Sequence Length | Throughput (sent/sec) | Throughput: G4dn | Speedup Over G4dn |
| BERT-large | FP16 | 1 | 128 | 93.5 | 40.31 | 2.3 |
| BERT-large | FP16 | 4 | 128 | 264.2 | 87.4 | 3.0 |
| BERT-large | FP16 | 8 | 128 | 392.1 | 107.5 | 3.6 |
| BERT-large | FP32 | 1 | 128 | 68.4 | 22.67 | 3.0 |
| BERT-large | 4 | 128 | 118.5 | 32.21 | 3.7 | |
| BERT-large | 8 | 128 | 132.4 | 34.67 | 3.8 |
| Model | GFLOPS | Number of Parameters | Preprocessing (ms) | Inference (ms) | Inference (Non-max-suppression) (NMS/image) |
| YOLOv5s | 16.5 | 7.2M | 0.2 | 3.6 | 4.5 |
| YOLOv5m | 49.1 | 21M | 0.2 | 6.5 | 4.5 |
| YOLOv5l | 109.3 | 46M | 0.2 | 9.1 | 3.5 |
| YOLOv5x | 205.9 | 86M | 0.2 | 14.4 | 1.3 |
Conclusion
In this post, we showed that for inference with large NLP and CV PyTorch models, EC2 G5 instances are a better choice compared to G4dn instances. Although the on-demand hourly cost for G5 instances is higher than G4dn instances, its higher performance can achieve 2–5 times the throughput at any precision for NLP and CV models, which makes the cost per million inferences 1.5–3.5 times more favorable than G4dn instances. Even for latency bound applications, G5 is 2.5–5 times better than G4dn for NLP and CV models.
In summary, AWS G5 instances are an excellent choice for your inference needs from both a performance and cost per inference perspective. The universality of the CUDA framework and the scale and depth of the G5 instance pool on AWS provides you with a unique ability to perform inference at scale.
About the authors
 Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
Ankur Srivastava is a Sr. Solutions Architect in the ML Frameworks Team. He focuses on helping customers with self-managed distributed training and inference at scale on AWS. His experience includes industrial predictive maintenance, digital twins, probabilistic design optimization and has completed his doctoral studies from Mechanical Engineering at Rice University and post-doctoral research from Massachusetts Institute of Technology.
 Sundar Ranganathan is the Head of Business Development, ML Frameworks on the Amazon EC2 team. He focuses on large-scale ML workloads across AWS services like Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
Sundar Ranganathan is the Head of Business Development, ML Frameworks on the Amazon EC2 team. He focuses on large-scale ML workloads across AWS services like Amazon EKS, Amazon ECS, Elastic Fabric Adapter, AWS Batch, and Amazon SageMaker. His experience includes leadership roles in product management and product development at NetApp, Micron Technology, Qualcomm, and Mentor Graphics.
 Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics-infused deep learning, building, and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
Mahadevan Balasubramaniam is a Principal Solutions Architect for Autonomous Computing with nearly 20 years of experience in the area of physics-infused deep learning, building, and deploying digital twins for industrial systems at scale. Mahadevan obtained his PhD in Mechanical Engineering from the Massachusetts Institute of Technology and has over 25 patents and publications to his credit.
 Amr Ragab is a Principal Solutions Architect for EC2 Accelerated Platforms for AWS, devoted to helping customers run computational workloads at scale. In his spare time he likes traveling and finding new ways to integrate technology into daily life.
Amr Ragab is a Principal Solutions Architect for EC2 Accelerated Platforms for AWS, devoted to helping customers run computational workloads at scale. In his spare time he likes traveling and finding new ways to integrate technology into daily life.