Amazon builds first foundation model for multirobot coordination
Trained on millions of hours of data from Amazon fulfillment centers and sortation centers, Amazons new DeepFleet models predict future traffic patterns for fleets of mobile robots.
Robotics
Joey DurhamAugust 11, 11:00 AMAugust 11, 11:00 AM
Large language models and other foundation models have introduced a new paradigm in AI: large models trained in a self-supervised fashion no data annotation required on huge volumes of data can learn general competencies that allow them to perform a variety of tasks. The most prominent examples of this paradigm are in language, image, and video generation. But where else can it be applied?
At Amazon, one answer to that question is in managing fleets of robots. In June, we announced the development of a new foundation model for predicting the interactions of mobile robots on the floors of Amazon fulfillment centers (FCs) and sortation centers, which we call DeepFleet. We still have a lot to figure out, but DeepFleet can already help assign tasks to our robots and route them around potential congestion, increasing the efficiency of our robot deployments by 10%. That lets us deliver packages to customers more rapidly and at lower costs.

One question I get a lot is why we would need a foundation model to predict robots locations. After all, we know exactly what algorithms the robots are running; cant we just simulate their interactions and get an answer that way?
There are two obstacles to this approach. First, accurately simulating the interactions of a couple thousand robots faster than real time is prohibitively resource intensive: our fleet already uses all available computation time to optimize its plans. In contrast, a learned model can quickly infer how traffic will likely play out.
Second, we see predicting robot locations as, really, a pretraining task, which we use to teach an AI to understand traffic flow. We believe that, just as pretraining on next-word prediction enabled chatbots to answer a diverse range of questions, pretraining on location prediction can enable an AI to generate general solutions for mobile-robot fleets.
The success of a foundation model depends on having adequate training data, which is one of the areas where Amazon has an advantage. At the same time that we announced DeepFleet, we also announced the deployment of our millionth robot to Amazon FCs and sortation centers. We have literally billions of hours of robot navigation data that we can use to train our foundation models.
And of course, Amazon is also the largest provider of cloud computing resources, so we have the computational capacity to train and deploy models large enough to benefit from all that training data. One of our papers key findings is that, like other foundation models, a robot fleet foundation model continues to improve as the volume of training data increases.
In some ways, its natural to adapt LLM architectures to the problem of predicting robot location. An LLM takes in a sequence of words and projects that sequence forward, one word at a time. Similarly, a robot navigation model would take in a sequence of robot states or floor states and project it forward, one state at a time.
In other ways, the adaptation isnt so straightforward. With LLMs, its clear what the inputs and outputs should be: words (or more precisely word parts, or tokens). But how about with robot navigation? Should the input to the model be the state of a single robot, and you produce a floor map by aggregating the outputs of multiple models? Or should the inputs and outputs include the state of the whole floor? And if they do, how do you represent the floor? As a set of features relative to the robot location? As an image? As a graph? And how do you handle time? Is each input to the model a snapshot taken at a regular interval? Or does each input represent a discrete action, whenever it took place?
We experimented with four distinct models that answer these questions in different ways. The basic setup is the same for all of them: we model the floor of an FC or sortation center as a grid whose cells can be occupied by robots, which are either laden (storage pods in an FC, packages in a sortation center) or unladen and have fixed orientations; obstacles; or storage or drop-off locations. Unoccupied cells make up travel lanes.
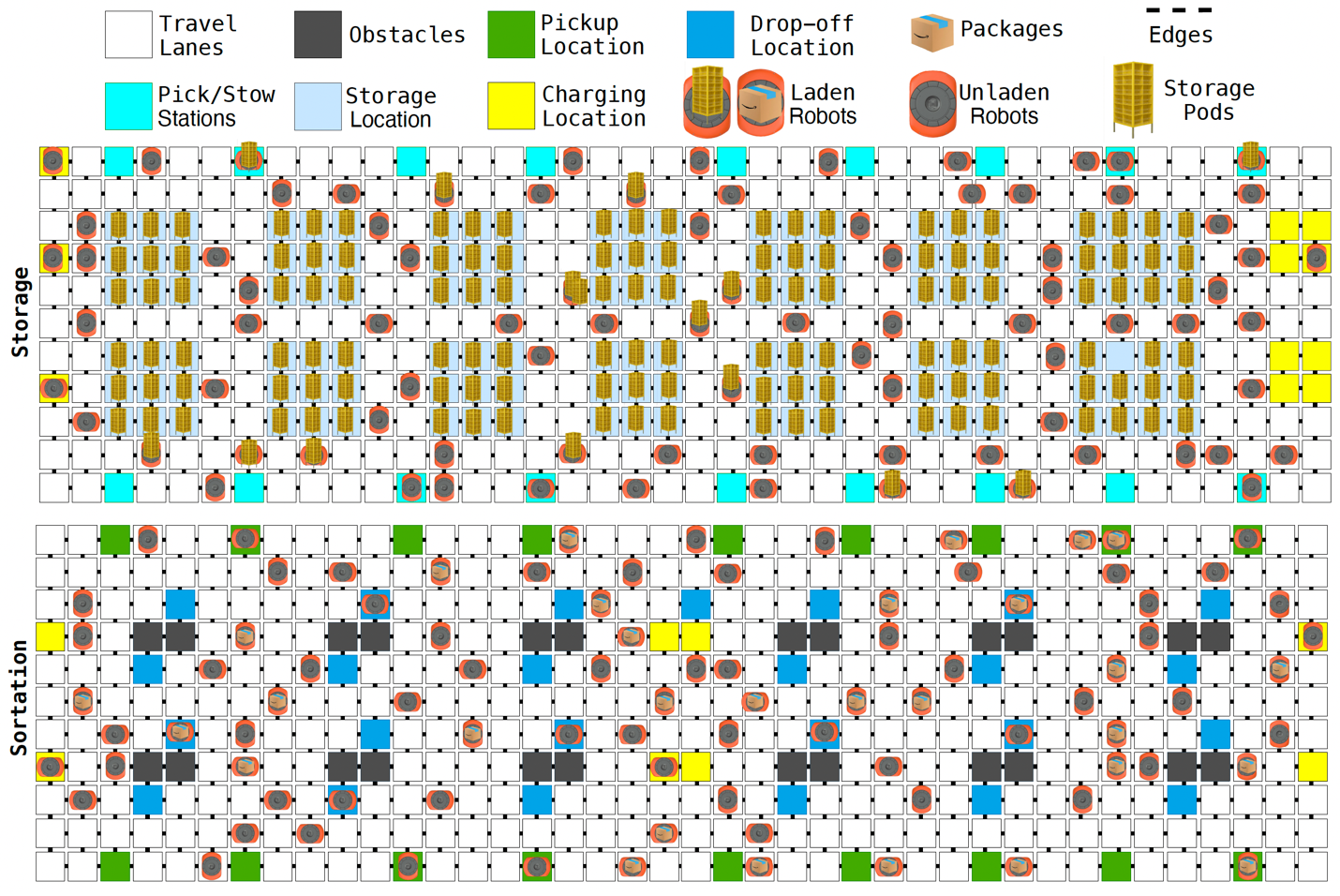
Like most machine learning systems of the past 10 years, our models produce embeddings of input data, or vector representations that capture data features useful for predictive tasks. All of our models make use of the Transformer architecture that is the basis of todays LLMs. The Transformers characteristic feature is the attention mechanism: when determining its next output, the model determines how much it should attend to each data item its already seen or to supplementary data. One of our models also uses a convolutional neural network, the standard model for image processing, while another uses a graph neural network to capture spatial relationships.
DeepFleet is the collective name for all of our models. Individually, they are the robot-centric model, the robot-floor model, the image-floor model, and the graph-floor model.
1. The robot-centric model
The robot-centric model focuses on one robot at a time the ego robot and builds a representation of its immediate environment. The models encoder produces an embedding of the ego robots state where it is, what direction its facing, where its headed, whether its laden or unladen, and so on. The encoder also produces embeddings of the states of the 30 robots nearest the ego robot; the 100 nearest grid cells; and the 100 nearest objects (drop-off chutes, storage pods, charging stations, and so on).
A Transformer combines these embeddings into a single embedding, and a sequence of such embeddings representing a sequence of states and actions the ego robot took passes to a decoder. On the basis of that sequence, the decoder predicts the robots next action. This process happens in parallel for every robot on the floor. Updating the state of the floor as a whole is a matter of sequentially applying each robots predicted action.
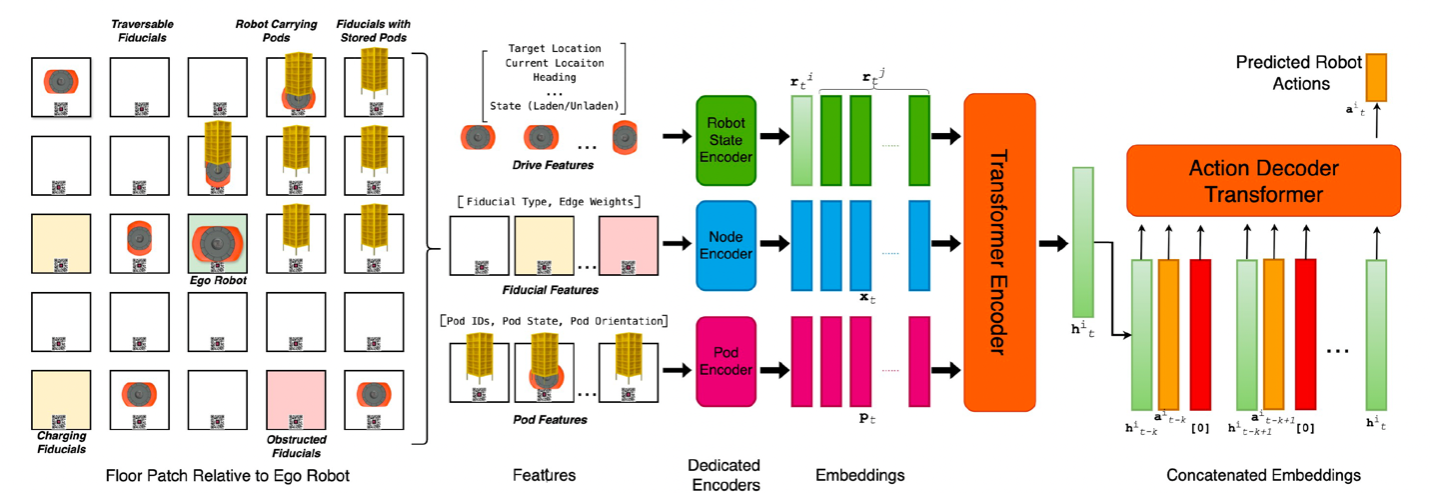
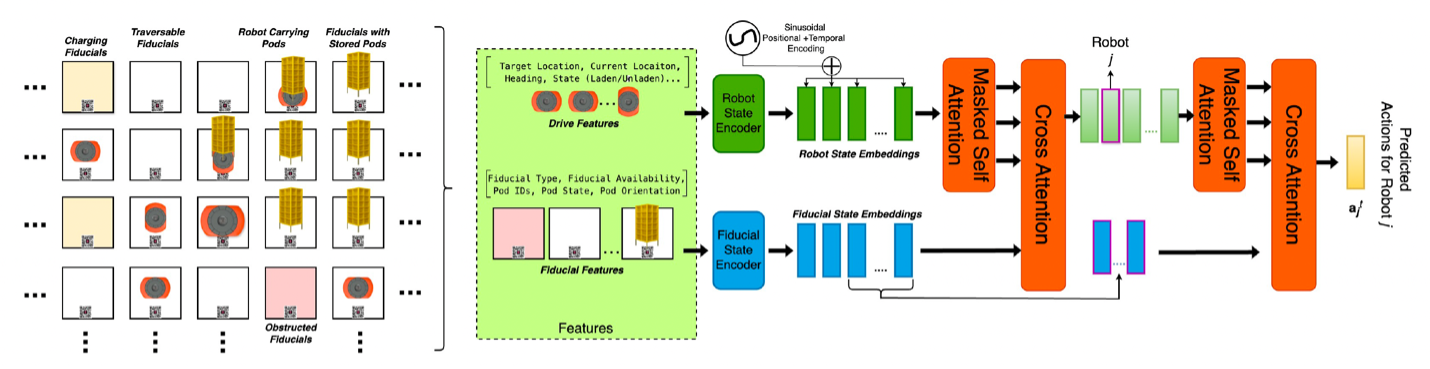
2. The robot-floor model
With the robot-floor model, separate encoders produce embeddings of the robot states and fixed features of the floor cells. As the only changes to the states of the floor cells are the results of robotic motion, the floor state requires only a single embedding.
At decoding time, we use cross-attention between the robot embeddings and the floor state embedding to produce a new embedding for each robot that factors in floor state information. Then, for each robot, we use cross-attention between its updated embedding and those of each of the other robots to produce a final embedding, which captures both robot-robot and robot-floor relationships. The last layer of the model the output head uses these final embeddings to predict each robots next action.
3. The image-floor model
Convolutional neural networks step through an input image, applying different filters to fixed-size blocks of pixels. Each filter establishes a separate processing channel through the network. Typically, the filters are looking for different image features, such as contours with particular shapes and orientations.
In our case, however, the pixels are cells of the floor grid, and each channel is dedicated to a separate cell feature. There are static features, such as fixed objects in particular cells, and dynamic features, such as the locations of the robots and their states.
In each channel, representations of successive states of the floor are flattened converted from 2-D grids to 1-D vectors and fed to a Transformer. The Transformers attention mechanism can thus attend to temporal and spatial features simultaneously. The Transformers output is an encoding of the next floor state, which a convolutional decoder converts back to a 2-D representation.
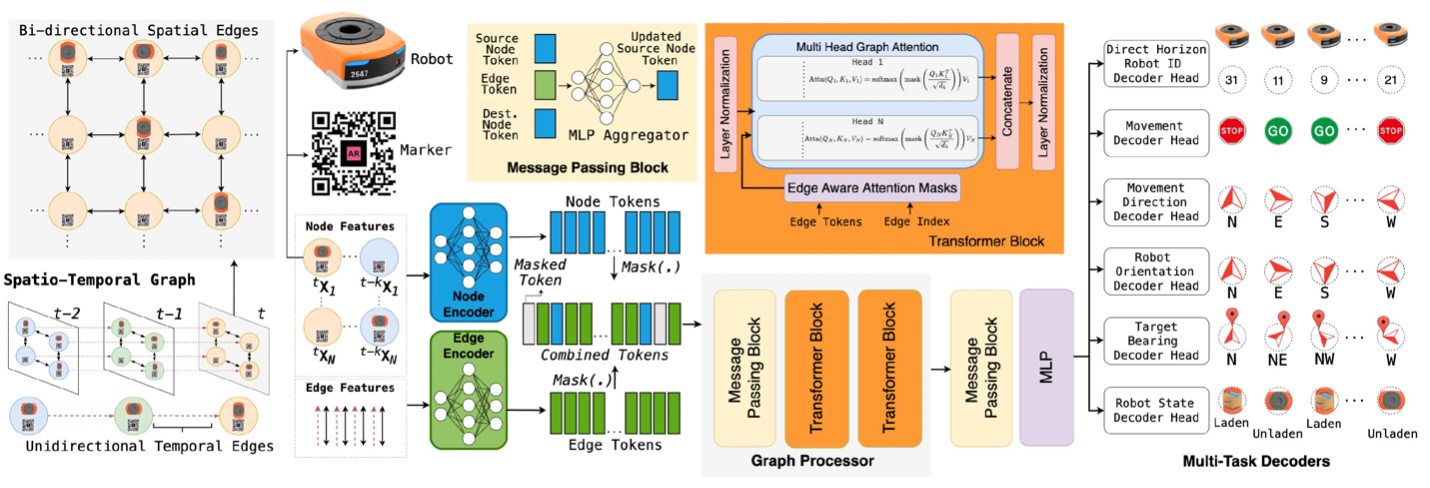
4. The graph-floor model
A natural way to model the FC or sortation center floor is as a graph whose nodes are floor cells and whose edges encode the available movements between cells (for example, a robot may not move into a cell occupied by another object). We convert such a spatial graph into a spatiotemporal graph by adding temporal edges that connect each node to itself at a later time step.
Next, in the approach made standard by graph neural networks, we use a Transformer to iteratively encode the spatiotemporal graph as a set of node embeddings. With each iteration, a nodes embedding factors in information about nodes farther away from it in the graph. In parallel, the model also builds up a set of edge embeddings.
Each encoding block also includes an attention mechanism that uses the edge embeddings to compute attention scores between node embeddings. The output embedding thus factors in information about the distances between nodes, so it can capture long-range effects.
From the final set of node embeddings, we can decode a prediction of where each robot is, whether it is moving, what direction it is heading, etc.
Evaluation
We used two metrics to evaluate all four models performance. The first is dynamic-time-warping (DTW) distance between predictions and the ground truth across multiple dimensions, including robot position, speed, state, and the timing of load and unload events. The second metric is congestion delay error (CDE), or the relative error between delay predictions and ground truth.
Overall, the robot-centric model performed best, with the top scores on both CDE and the DTW distance on position and state predictions, but the robot-floor model achieved the top score on DTW distance for timing estimation. The graph-floor model didnt fare quite as well, but its results were still strong at a significantly lower parameter count 13 million, versus 97 million for the robot-centric model and 840 million for the robot-floor model.
The image-floor model didnt work well. We suspect that this is because the convolutional filters of a convolutional neural network are designed to abstract away from pixel-level values to infer larger-scale image features, like object classifications. We were trying to use convolutional neural networks for pixel-level predictions, which they may not be suited for.
We also conducted scaling experiments with the robot-centric and graph-floor models, which showed that, indeed, model performance improved with increases in the volume of training data an encouraging sign, given the amount of data we have at our disposal.
On the basis of these results, we are continuing to develop the robot-centric, robot-floor, and graph-floor models, initially using them to predict congestion, with the longer-term goal of using them to produce outputs like assignments of robots to specific retrieval tasks and target locations.
Research areas: Robotics