We’re excited to announce Amazon SageMaker Data Wrangler support for Amazon S3 Access Points. With its visual point and clikc interface, SageMaker Data Wrangler simplifies the process of data preparation and feature engineering including data selection, cleansing, exploration, and visualization, while S3 Access Points simplifies data access by providing unique hostnames with specific access policies.
Starting today, SageMaker Data Wrangler is making it easier for users to prepare data from shared datasets stored in Amazon Simple Storage Service (Amazon S3) while enabling organizations to securely control data access in their organization. With S3 Access Points, data administrators can now create application- and team-specific access points to facilitate data sharing, rather than managing complex bucket policies with many different permission rules.
In this post, we walk you through importing data from, and exporting data to, an S3 access point in SageMaker Data Wrangler.
Solution Overview
Imagine you, as an administrator, have to manage data for multiple data science teams running their own data preparation workflows in SageMaker Data Wrangler. Administrators often face three challenges:
- Data science teams need to access their datasets without compromising the security of others
- Data science teams need access to some datasets with sensitive data, which further complicates managing permissions
- Security policy only permits data access through specific endpoints to prevent unauthorized access and to reduce the exposure of data
With traditional bucket policies, you would struggle setting up granular access because bucket policies apply the same permissions to all objects within the bucket. Traditional bucket policies also can’t support securing access at the endpoint level.
S3 Access Points solves these problems by granting fine-grained access control at a granular level, making it easier to manage permissions for different teams without impacting other parts of the bucket. Instead of modifying a single bucket policy, you can create multiple access points with individual policies tailored to specific use cases, reducing the risk of misconfiguration or unintended access to sensitive data. Lastly, you can enforce endpoint policies on access points to define rules that control which VPCs or IP addresses can access the data through a specific access point.
We demonstrate how to use S3 Access Points with SageMaker Data Wrangler with the following steps:
- Upload data to an S3 bucket.
- Create an S3 access point.
- Configure your AWS Identity and Access Management (IAM) role with the necessary policies.
- Create a SageMaker Data Wrangler flow.
- Export data from SageMaker Data Wrangler to the access point.
For this post, we use the Bank Marketing dataset for our sample data. However, you can use any other dataset you prefer.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- An Amazon SageMaker Studio domain and user. For details on setting these up, refer to Onboard to Amazon SageMaker Domain Using Quick setup.
- An S3 bucket.
Upload data to an S3 bucket
Upload your data to an S3 bucket. For instructions, refer to Uploading objects. For this post, we use the Bank Marketing dataset.
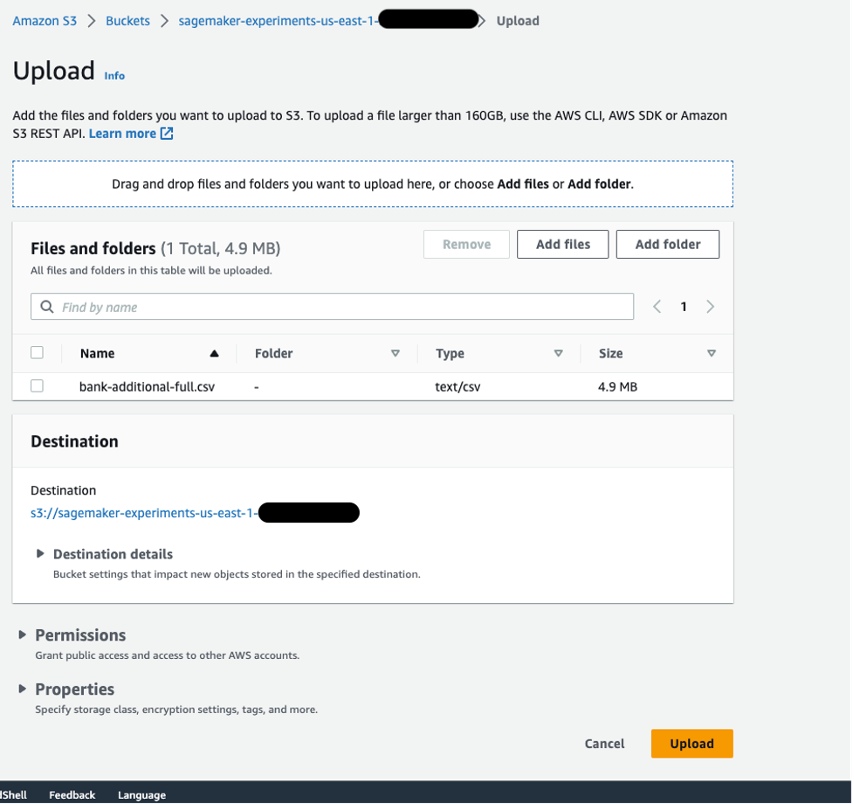
Create an S3 access point
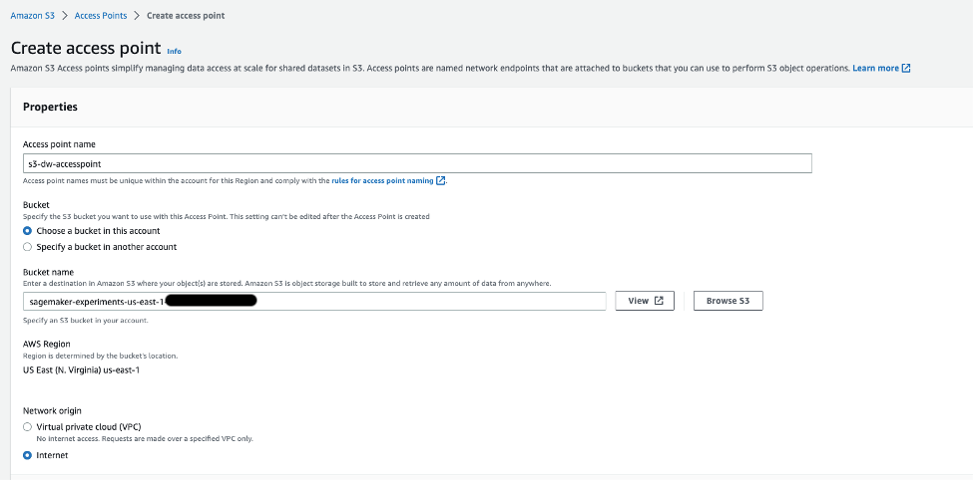
To create an S3 access point, complete the following steps. For more information, refer to Creating access points.
- On the Amazon S3 console, choose Access Points in the navigation pane.
- Choose Create access point.
- For Access point name, enter a name for your access point.
- For Bucket, select Choose a bucket in this account.
- For Bucket name, enter the name of the bucket you created.
- Leave the remaining settings as default and choose Create access point.
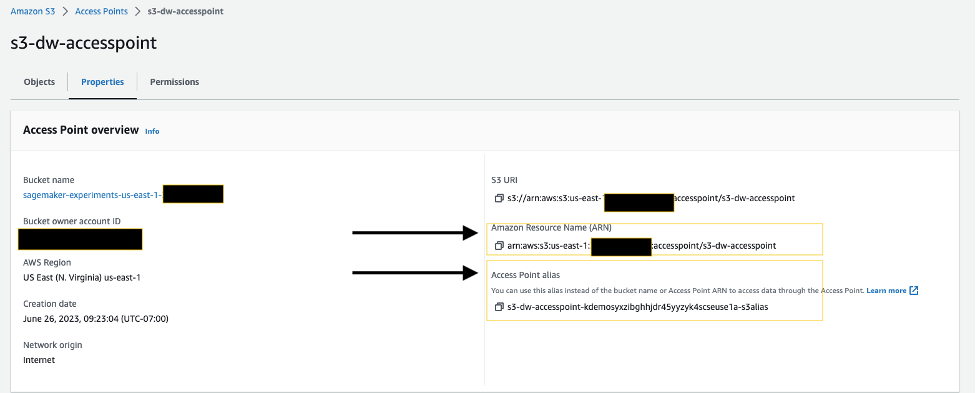
On the access point details page, note the Amazon Resource Name (ARN) and access point alias. You use these later when you interact with the access point in SageMaker Data Wrangler.
Configure your IAM role
If you have a SageMaker Studio domain up and ready, complete the following steps to edit the execution role:
- On the SageMaker console, choose Domains in the navigation pane.
- Choose your domain.
- On the Domain settings tab, choose Edit.
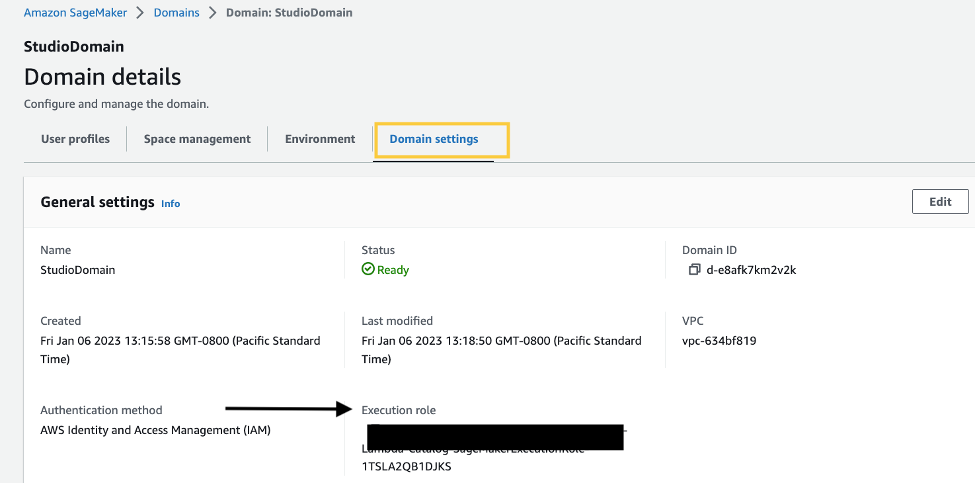
By default, the IAM role that you use to access Data Wrangler is SageMakerExecutionRole. We need to add the following two policies to use S3 access points:
- Policy 1 – This IAM policy grants SageMaker Data Wrangler access to perform
PutObject,GetObject, andDeleteObject:
- Policy 2 – This IAM policy grants SageMaker Data Wrangler access to get the S3 access point:
- Create these two policies and attach them to the role.
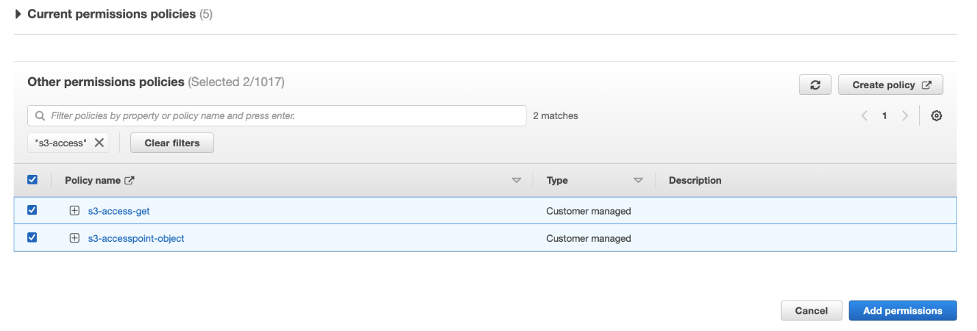
Using S3 Access Points in SageMaker Data Wrangler
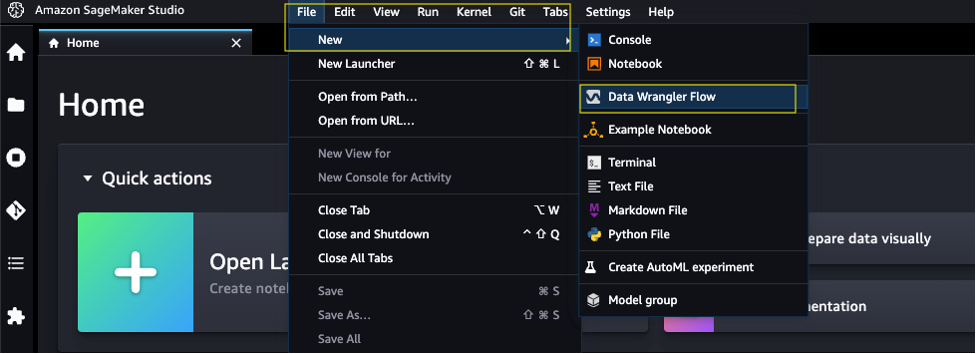
To create a new SageMaker Data Wrangler flow, complete the following steps:
- Launch SageMaker Studio.
- On the File menu, choose New and Data Wrangler Flow.
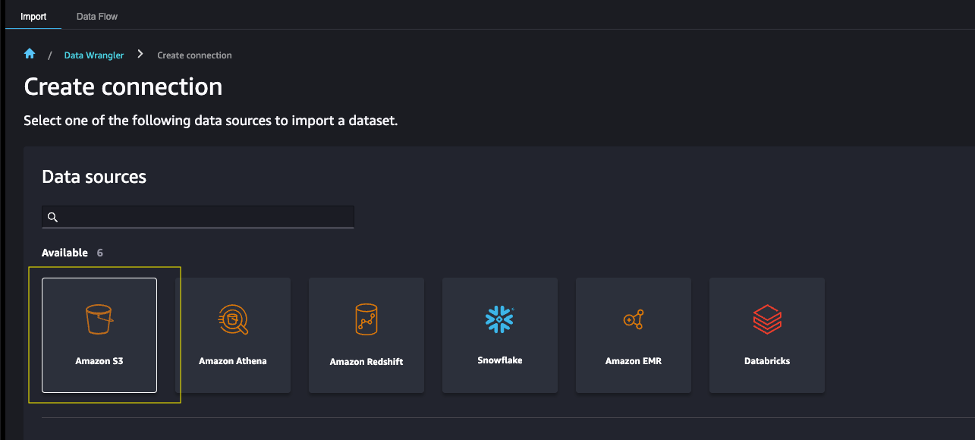
- Choose Amazon S3 as the data source.
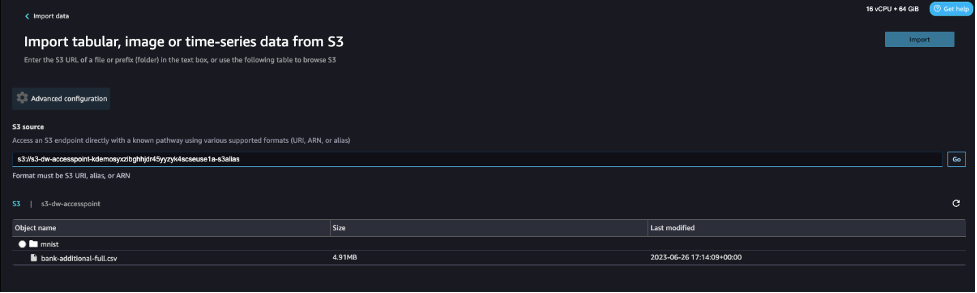
- For S3 source, enter the S3 access point using the ARN or alias that you noted down earlier.
For this post, we use the ARN to import data using the S3 access point. However, the ARN only works for S3 access points and SageMaker Studio domains within the same Region.
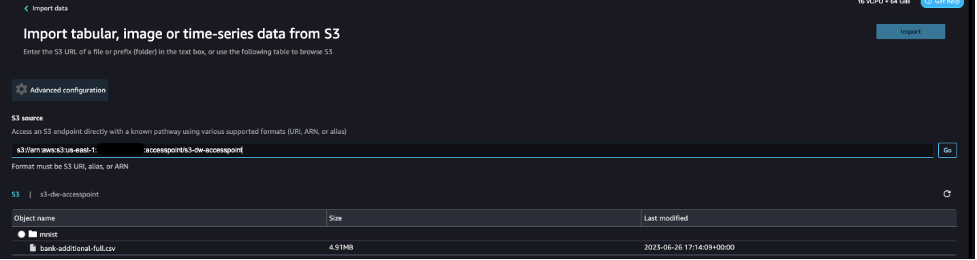
Alternatively, you can use the alias, as shown in the following screenshot. Unlike ARNs, aliases can be referenced across Regions.
Export data from SageMaker Data Wrangler to S3 access points
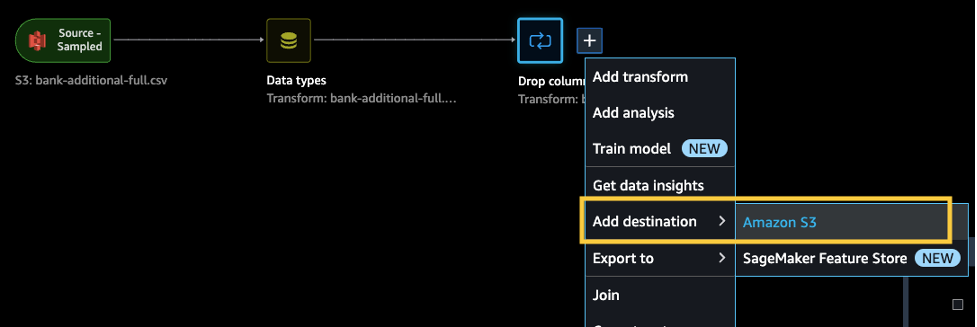
After we complete the necessary transformations, we can export the results to the S3 access point. In our case, we simply dropped a column. When you complete whatever transformations you need for your use case, complete the following steps:
- In the data flow, choose the plus sign.
- Choose Add destination and Amazon S3.
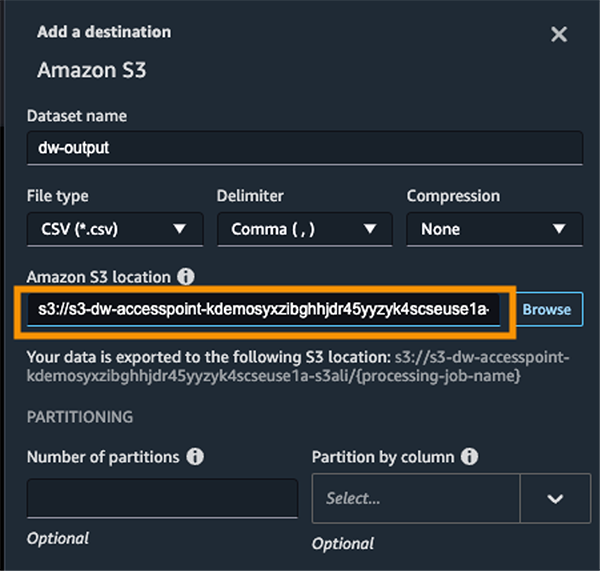
- Enter the dataset name and the S3 location, referencing the ARN.
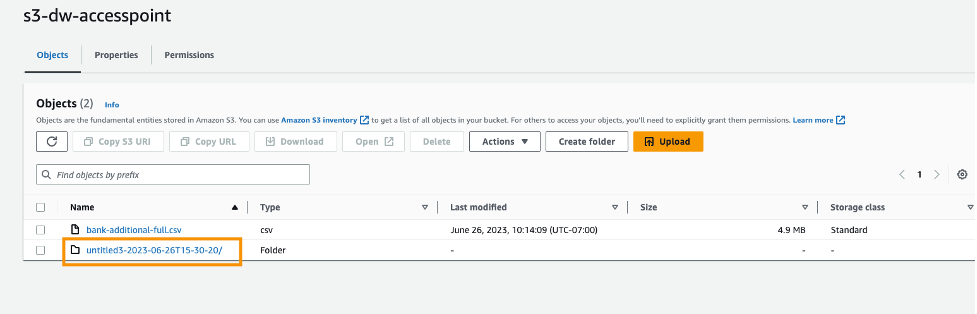
Now you have used S3 access points to import and export data securely and efficiently without having to manage complex bucket policies and navigate multiple folder structures.
Clean up
If you created a new SageMaker domain to follow along, be sure to stop any running apps and delete your domain to stop incurring charges. Also, delete any S3 access points and delete any S3 buckets.
Conclusion
In this post, we introduced the availability of S3 Access Points for SageMaker Data Wrangler and showed you how you can use this feature to simplify data control within SageMaker Studio. We accessed the dataset from, and saved the resulting transformations to, an S3 access point alias across AWS accounts. We hope that you take advantage of this feature to remove any bottlenecks with data access for your SageMaker Studio users, and encourage you to give it a try!
About the authors
 Peter Chung is a Solutions Architect serving enterprise customers at AWS. He loves to help customers use technology to solve business problems on various topics like cutting costs and leveraging artificial intelligence. He wrote a book on AWS FinOps, and enjoys reading and building solutions.
Peter Chung is a Solutions Architect serving enterprise customers at AWS. He loves to help customers use technology to solve business problems on various topics like cutting costs and leveraging artificial intelligence. He wrote a book on AWS FinOps, and enjoys reading and building solutions.
 Neelam Koshiya is an Enterprise Solution Architect at AWS. Her current focus is to help enterprise customers with their cloud adoption journey for strategic business outcomes. In her spare time, she enjoys reading and being outdoors.
Neelam Koshiya is an Enterprise Solution Architect at AWS. Her current focus is to help enterprise customers with their cloud adoption journey for strategic business outcomes. In her spare time, she enjoys reading and being outdoors.