Every day, financial organizations need to analyze news articles, SEC filings, and press releases, as well as track financial events such as bankruptcy announcements, changes in executive leadership at companies, and announcements of mergers and acquisitions. They want to accurately extract the key data points and associations among various people and organizations mentioned within an announcement to update their investment models in a timely manner. Traditional natural language processing services can extract entities such as people, organizations and locations from text, but financial analysts need more. They need to understand how these entities relate to each other in the text.
Today, Amazon Comprehend is launching Comprehend Events, a new API for event extraction from natural language text documents. With this launch, you can use Comprehend Events to extract granular details about real-world events and associated entities expressed in unstructured text. This new API allows you to answer who-what-when-where questions over large document sets, at scale and without prior NLP experience.
This post gives an overview of the NLP capabilities that Comprehend Events supports, along with suggestions for processing and analyzing documents with this feature. We’ll close with a discussion of several solutions that use Comprehend Events, such as knowledge base population, semantic search, and document triage, all of which can be developed with companion AWS services for storing, visualizing, and analyzing the predictions made by Comprehend Events.
Comprehend Events overview
The Comprehend Events API, under the hood, converts unstructured text into structured data that answers who-what-when-where-how questions. Comprehend Events lets you extract the event structure from a document, distilling pages of text down to easily processed data for consumption by your AI applications or graph visualization tools. In the following figure, an Amazon press release announcing the 2017 acquisition of Whole Foods Market, Inc. is rendered as a graph showing the core semantics of the acquisition event, as well as the status of Whole Foods’ CEO post merger.
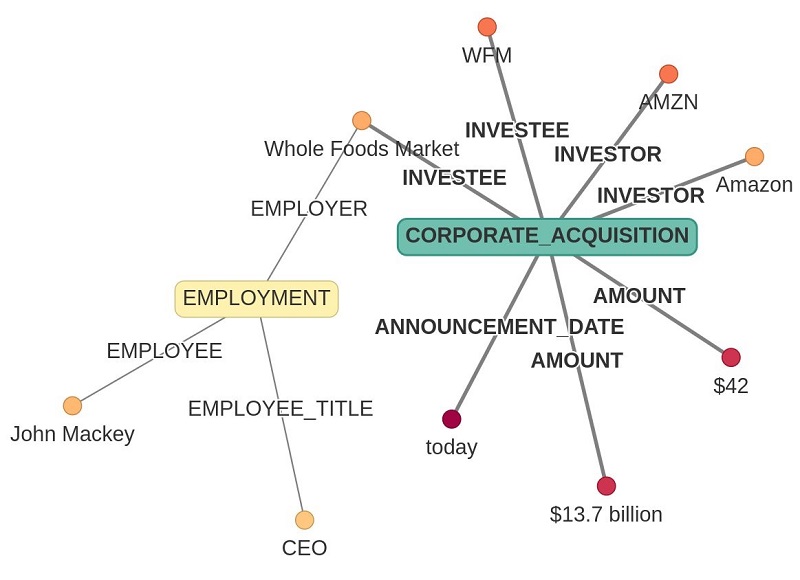
Amazon (AMZN) today announced that they will acquire Whole Foods Market (WFM) for $42 per share in an all-cash transaction valued at approximately $13.7 billion, including Whole Foods Market’s net debt. Whole Foods Market will continue to operate stores under the Whole Foods Market brand and source from trusted vendors and partners around the world. John Mackey will remain as CEO of Whole Foods Market and Whole Foods Market’s headquarters will stay in Austin, Texas.
Extracted event triggers – Which events took place. In our example, CORPORATE_ACQUISITION and EMPLOYMENT events were detected. Not shown in the preceding figure, the API also returns which words in the text indicate the occurrence of the event, for example the words “acquire” and “transaction” in the context of the document indicate that a CORPORATE_ACQUISITION took place. The Comprehend Events API returns a variety of insights into the event semantics of a document:
- Extracted entity mentions – Which words in the text indicate which entities are involved in the event, including named entities such as “Whole Foods Market” and common nouns such as “today.” The API also returns the type of the entity detected, for example
ORGANIZATIONfor “Whole Foods Market.” - Event argument role (also known as slot filling) – Which entities play which roles in which events; for example Amazon is an
INVESTORin the acquisition event. - Groups of coreferential event triggers – Which triggers in the document refer to the same event. The API also groups triggers such as “transaction” and “acquire” around the
CORPORATE_ACQUISITIONevent (not shown above). - Groups of coreferential entity mentions – Which mentions in the document refer to the same entity. For example, the API returns the grouping of “Amazon” with “they” as a single entity (not shown above).
At the time of launch, Comprehend Events is available as an asynchronous API supporting extraction of a fixed set of event types in the finance domain. This domain includes a variety of event types (such as CORPORATE_ACQUISITION and IPO), both standard and novel entity types (such as PER and ORG vs. STOCK_CODE and MONETARY_VALUE), and the argument roles that can connect them (such as INVESTOR, OFFERING_DATE, or EMPLOYER). For the complete ontology, see the Detect Events API documentation.
To demonstrate the functionality of the feature, we’ll show you how to process a small set of sample documents, using both the Amazon Comprehend console and the Python SDK.
Formatting documents for processing
The first step is to transform raw documents into a suitable format for processing. Comprehend Events imposes a few requirements on document size and composition:
- Individual documents must be UTF-8 encoded and no more than 10 KB in length. As a best practice, we recommend segmenting larger documents at logical boundaries (section headers) or performing sentence segmentation with existing open-source tools.
- For best performance, markup (such as HTML), tabular material, and other non-prose spans of text should be removed from documents. The service is intended to process paragraphs of unstructured text.
- A single job must not contain more than 50 MB of data. Larger datasets must be divided into smaller sets of documents for parallel processing. The different document format modes also impose size restrictions:
- One document per file (ODPF) – A maximum of 5,000 files in a single Amazon Simple Storage Service (Amazon S3) location.
- One document per line (ODPL) – A maximum of 5,000 lines in a single text file. Newline characters (
n,r,rn) should be replaced with other whitespace characters within a given document.
For this post, we use a set of 117 documents sampled from Amazon’s Press Center: sample_finance_dataset.txt. The documents are formatted as a single ODPL text file and already conform to the preceding requirements. To implement this solution on your own, just upload the text file to an S3 bucket in your account before continuing with the following steps.
Job creation option 1: Using the Amazon Comprehend console
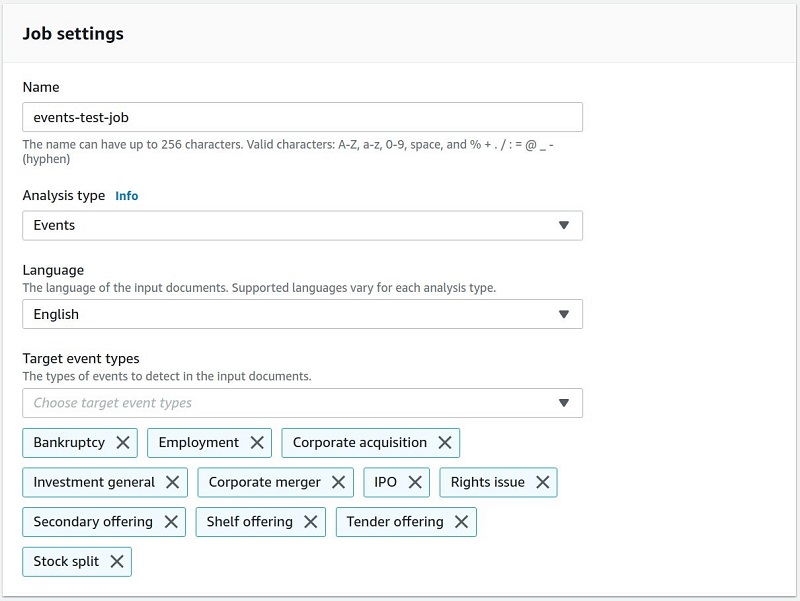
Creating a new Events labeling job takes only a few minutes.
- On the Amazon Comprehend console, choose Analysis jobs.
- Chose Create job.
- For Name, enter a name (for this post, we use
events-test-job). - For Analysis type¸ choose Events.
- For Language, choose English.
- For Target event types, choose your types of events (for example, Corporate acquisition).
- In the Input data section, for S3 location, enter the location of the sample ODPL file you downloaded earlier.
- In the Output data section, for S3 location, enter a location for the event output.

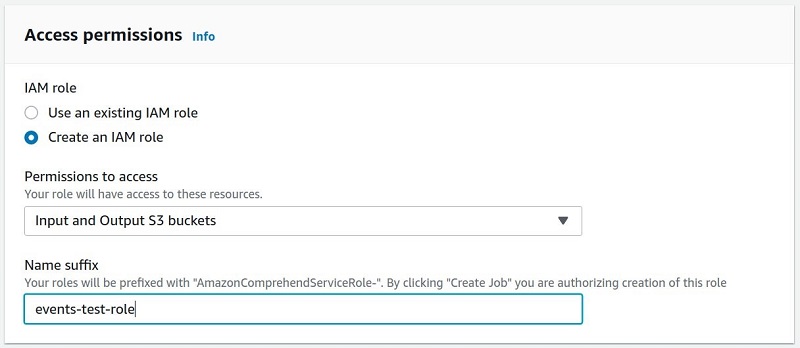
- For IAM role, choose to use an existing AWS Identity and Access (IAM) role or create a new one.
- Choose Create job.
A new job appears in the Analysis jobs queue.
Job creation option 2: Using the SDK
Alternatively, you can perform these same steps with the Python SDK. First, we specify Comprehend Events job parameters, just as we would with any other Amazon Comprehend feature. See the following code:
# Client and session information
session = boto3.Session()
comprehend_client = session.client(service_name="comprehend")
# Constants for S3 bucket and input data file.
bucket = "comprehend-events-blogpost-us-east-1"
filename = 'sample_finance_dataset.txt'
input_data_s3_path = f's3://{bucket}/' + filename
output_data_s3_path = f's3://{bucket}/'
# IAM role with access to Comprehend and specified S3 buckets
job_data_access_role = 'arn:aws:iam::xxxxxxxxxxxxx:role/service-role/AmazonComprehendServiceRole-test-events-role'
# Other job parameters
input_data_format = 'ONE_DOC_PER_LINE'
job_uuid = uuid.uuid1()
job_name = f"events-job-{job_uuid}"
event_types = ["BANKRUPTCY", "EMPLOYMENT", "CORPORATE_ACQUISITION",
"INVESTMENT_GENERAL", "CORPORATE_MERGER", "IPO",
"RIGHTS_ISSUE", "SECONDARY_OFFERING", "SHELF_OFFERING",
"TENDER_OFFERING", "STOCK_SPLIT"]
Next, we use the start_events_detection_job API endpoint to start the analysis of the input data file and capture the job ID, which we use later to poll and retrieve results:
# Begin the inference job
response = comprehend_client.start_events_detection_job(
InputDataConfig={'S3Uri': input_data_s3_path,
'InputFormat': input_data_format},
OutputDataConfig={'S3Uri': output_data_s3_path},
DataAccessRoleArn=job_data_access_role,
JobName=job_name,
LanguageCode='en',
TargetEventTypes=event_types
)
# Get the job ID
events_job_id = response['JobId']
An asynchronous Comprehend Events job typically takes a few minutes for a small number of documents and up to several hours for lengthier inference tasks. For our sample dataset, inference should take approximately 20 minutes. It’s helpful to poll the API using the describe_events_detection_job endpoint. When the job is complete, the API returns a JobStatus of COMPLETED. See the following code:
# Get current job status
job = comprehend_client.describe_events_detection_job(JobId=events_job_id)
# Loop until job is completed
waited = 0
timeout_minutes = 30
while job['EventsDetectionJobProperties']['JobStatus'] != 'COMPLETED':
sleep(60)
waited += 60
assert waited//60 < timeout_minutes, "Job timed out after %d seconds." % waited
job = comprehend_client.describe_events_detection_job(JobId=events_job_id)
Finally, we collect the Events inference output from Amazon S3 and convert to a list of dictionaries, each of which contains the predictions for a given document:
# The output filename is the input filename + ".out"
output_data_s3_file = job['EventsDetectionJobProperties']['OutputDataConfig']['S3Uri'] + filename + '.out'
# Load the output into a result dictionary # Get the files.
results = []
with smart_open.open(output_data_s3_file) as fi:
results.extend([json.loads(line) for line in fi.readlines() if line])The Comprehend Events API output schema
When complete, the output is written to Amazon S3 in JSON lines format, with each line encoding all the event extraction predictions for a single document. Our output schema includes the following information:
- Comprehend Events system output contains separate objects for entities and events, each organized into groups of coreferential objects.
- The API output includes the text, character offset, and type of each entity mention and trigger.
- Event argument roles are linked to entity groups by an
EntityIndex. - Confidence scores for classification tasks are given as Score. Confidence of entity and trigger group membership is given with
GroupScore. - Two additional fields,
FileandLine, are present as well, allowing you to track document provenance.
The following Comprehend Events API output schema represents entities as lists of mentions and events as lists of triggers and arguments:
{
"Entities": [
{
"Mentions": [
{
"BeginOffset": number,
"EndOffset": number,
"Score": number,
"GroupScore": number,
"Text": "string",
"Type": "string"
}, ...
]
}, ...
],
"Events": [
{
"Type": "string",
"Arguments": [
{
"EntityIndex": number,
"Role": "string",
"Score": number
}, ...
],
"Triggers": [
{
"BeginOffset": number,
"EndOffset": number,
"Score": number,
"Text": "string",
"GroupScore": number,
"Type": "string"
}, ...
]
}, ...
]
"File": "string",
"Line": "string
}
Analyzing Events output
The API output encodes all the semantic relationships necessary to immediately produce several useful visualizations of any given document. We walk through a few such depictions of the data in this section, referring you to the Amazon SageMaker Jupyter notebook accompanying this post for the working Python code necessary to produce them. We use the press release about Amazon’s acquisition of Whole Foods mentioned earlier in this post as an example.
Visualizing entity and trigger spans
As with any sequence labeling task, one of the simplest visualizations for Comprehend Events output is highlighting triggers and entity mentions, along with their respective tags. For this post, we use displaCy‘s ability to render custom tags. In the following visualization, we see some of the the usual range of entity types detected by NER systems (PERSON, ORGANIZATION), as well as finance-specific ones, such as STOCK_CODE and MONETARY_VALUE. Comprehend Events detects non-named entities (common nouns and pronouns) as well as named ones. In addition to entities, we also see tagged event triggers, such as “merger” (CORPORATE_MERGER) and “acquire” (CORPORATE_ACQUISITION).

Graphing event structures
Highlighting tagged spans is informative because it localizes system predictions about entity and event types in the text. However, it doesn’t show the most informative thing about the output: the predicted argument role associations among events and entities. The following plot depicts the event structure of the document as a semantic graph. In the graph, vertices are entity mentions and triggers; edges are the argument roles held by the entities in relation to the triggers. For simple renderings of a small number of events, we recommend common open-source tools such as networkx and pyvis, which we used to produce this visualization. For larger graphs, and graphs of large numbers of documents, we recommend a more robust solution for graph storage, such as Amazon Neptune.

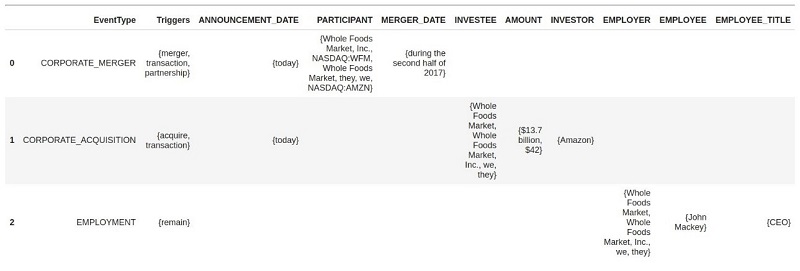
Tabulating event structures
Lastly, you can always render the event structure produced by the API as a flat table, indicating, for example, the argument roles of the various participants in each event, as in the following table. The table demonstrates how Comprehend Events groups entity mentions and triggers into coreferential groups. You can use these textual mention groups to verify and analyze system predictions.
Setting up the Comprehend Events AWS CloudFormation stack
You can quickly try out this example for yourself by deploying our sample code into your own account from the provided AWS CloudFormation template. We’ve included all the necessary steps in a Jupyter notebook, so you can easily walk through creating the preceding visualizations and see how it all works. From there, you can easily modify it to run over other custom datasets, modify the results, ingest them into other systems, and build upon the solution. Complete the following steps:
- Choose Launch Stack:
![]()
- After the template loads in the AWS CloudFormation console, choose Next.
- For Stack name, enter a name for your deployment.
- Choose Next.
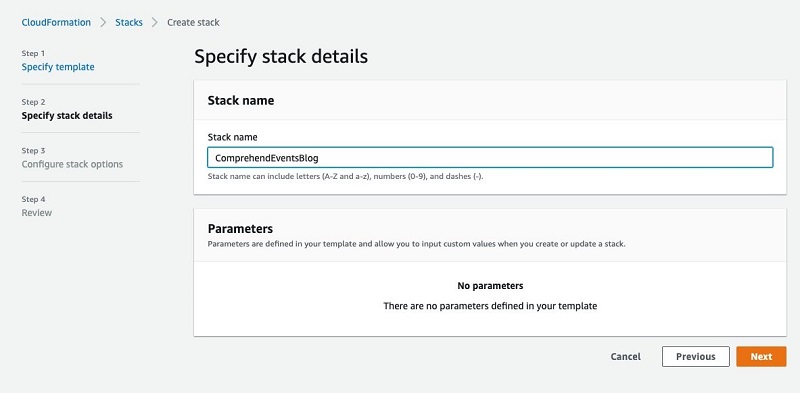
- Choose Next on the following page.
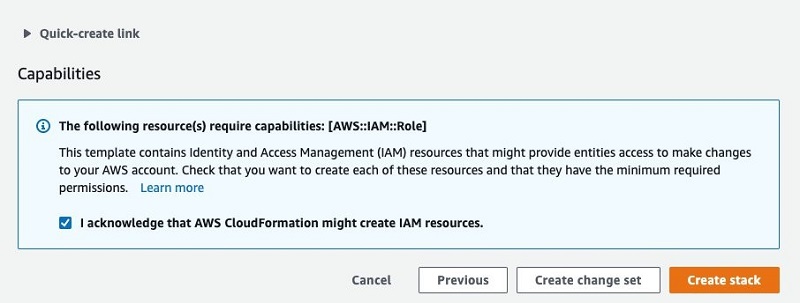
- Select the check box acknowledging this template will create IAM resources.
This allows the SageMaker notebook instance to talk with Amazon S3 and Amazon Comprehend.
- Choose Create stack.
- When stack creation is complete, browse to your notebook instances on the SageMaker console.
A new instance is already loaded with the example data and Jupyter notebook.
- Choose Open Jupyter for the
comprehend-events-blognotebook.

The data and notebook are already loaded on the instance. This was done through a SageMaker lifecycle configuration.
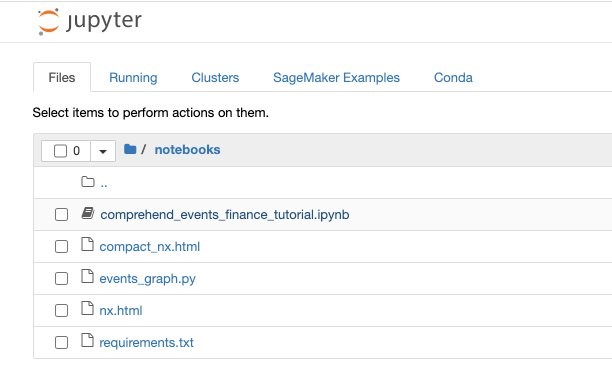
- Choose the
notebooksfolder. - Choose the
comprehend_events_finance_tutorial.ipynbnotebook.
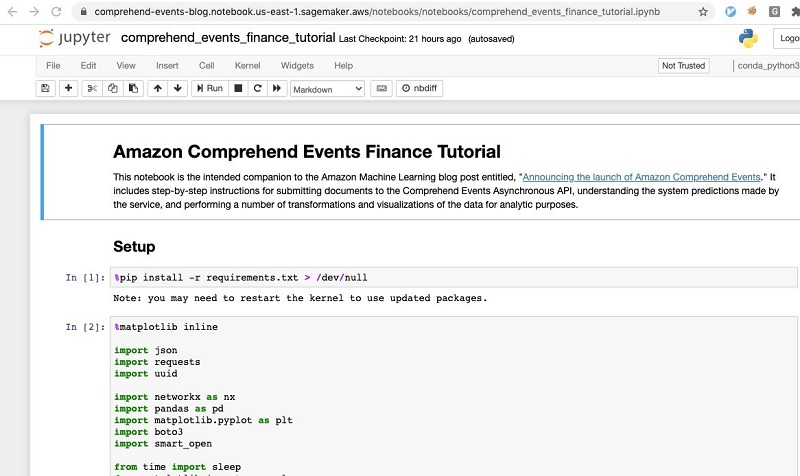
- Step through the notebook to try Comprehend Events out yourself.
Applications using Comprehend Events
We have demonstrated applying Comprehend Events to a small set of documents and demonstrated visualizing the event structures found in a sample document. The power of Comprehend Events, however, lies in its ability to extract and structure business-relevant facts from large collections of unstructured documents. In this section, we discuss a few potential solutions that you could build on top of the foundation provided by Comprehend Events.
Knowledge graph construction
Business and financial services analysts need to visually explore event-based relationships among corporate entities, identifying potential patterns over large collections of data. Without a tool like Comprehend Events, you have to manually identify entities of interests and events in documents and manually enter them in network visualization tools for tracking. Comprehend Events allows you to populate knowledge graphs over large collections of data. You can store these graphs and search, for example, in Neptune and explore using network visualization tools without expensive manual extraction.
Semantic search
Analysts also need to find documents in which actors of interest participate in events of interest (at places, at times). The most common approach to this task involves enterprise search: using complex Boolean queries to find co-occurring strings that typically match your desired search patterns. Natural language is rich and highly variable, however, and even the best searches often miss key details in unstructured text. Comprehend Events allows you to populate a search index with event-argument associations, enriching free text search with extracted event data. You can process collections of documents with Comprehend Events, index the documents in Amazon Elasticsearch Service (Amazon ES) with the extracted event data, and enable field-based search over event-argument tuples in downstream applications.
Document triage
An additional application of Comprehend Events is simple filtration of large text collections for events of interest. This task is typically performed with a tool such as Amazon Comprehend customer classification, but requires hundreds or thousands of annotated training documents to produce a custom model. Comprehend Events allows developers without such training data to process a large collection of documents and detect financial events found in the event taxonomy. You can simply process batches of documents with the asynchronous API and route documents matching pre-defined event patterns to downstream applications.
Conclusion
This post has demonstrated the application and utility of Comprehend Events for information processing in the finance domain. This new feature gives you the ability to enrich your applications with close semantic analysis of financial events from unstructured text, all without any NLP model training or tuning. For more information, just check out our documentation or try out the above walkthrough for yourself in the Console or in our Jupyter notebook through CloudFormation or on Github. We’re exciting to hear your comments and questions in the comments section!
About the Authors
 Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors.
Graham Horwood is a data scientist at Amazon AI. His work focuses on natural language processing technologies for customers in the public and commercial sectors.
 Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
Ben Snively is an AWS Public Sector Specialist Solutions Architect. He works with government, non-profit, and education customers on big data/analytical and AI/ML projects, helping them build solutions using AWS.
 Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.
Sameer Karnik is a Sr. Product Manager leading product for Amazon Comprehend, AWS’s natural language processing service.