Today we announce the general availability of Renate, an open-source Python library for automatic model retraining. The library provides continual learning algorithms able to incrementally train a neural network as more data becomes available.
By open-sourcing Renate, we would like to create a venue where practitioners working on real-world machine learning systems and researchers interested in advancing the state of the art in automatic machine learning, continual learning, and lifelong learning come together. We believe that synergies between these two communities will generate new ideas in the machine learning research community and provide a tangible positive impact in real-world applications.
Model retraining and catastrophic forgetting
Training neural networks incrementally is not a simple task. In practice, data provided at different points in time is often sampled from different distributions. For example, in question-answering systems, the distribution of the topics in the questions can significantly vary over time. In classification systems, the addition of new categories may be required when the data is collected in different parts of the world. Fine-tuning the previously trained models with new data in these cases will lead to a phenomenon called “catastrophic forgetting.” There will be good performance on the most recent examples, but the quality of the predictions made for data collected in the past will degrade significantly. Moreover, the performance degradation will be even more severe when the retraining operation happens regularly (e.g., daily or weekly).
When storing a small chunk of data is possible, methods based on reusing old data during the retraining can partially alleviate the catastrophic forgetting problem. Several methods have been developed following this idea. Some of them store only the raw data, while more advanced ones also save additional metadata (e.g., the intermediate representation of the data points in memory). Storing a small amount of data (e.g., thousands of data points) and using them carefully led to the superior performance displayed in the figure below.

Bring your own model and dataset
When training neural network models, it may be necessary to change the network structure, the data transformation and other important details. While code changes are limited, it can become a complex task when these models are part of a large software library. To avoid these inconveniences, Renate offers customers the ability to define their models and datasets in predefined Python functions as part of a configuration file. This has the advantage of keeping the customers’ code clearly separate from the rest of the library and allow customers without any knowledge of the Renate’s internal structure to use the library effectively.
Moreover, all functions, including the model definition, are very flexible. In fact, the model definition function allows users to create neural networks from scratch following their own needs or to instantiate well-known models from open-source libraries like transformers or torchvision. It just requires adding the necessary dependencies to the requirements file.
A tutorial on how to write the configuration file is available at How to Write a Config File.
The benefit of hyperparameter optimization
As is often the case in machine learning, continual learning algorithms come with a number of hyperparameters. Its settings can make an important difference in the overall performance, and careful tuning can positively impact the predictive performance. When training a new model, Renate can enable hyperparameter optimization (HPO) using state-of-the-art algorithms like ASHA to exploit the ability to run multiple parallel jobs on Amazon SageMaker. An example of the outcomes is displayed in the figure below.
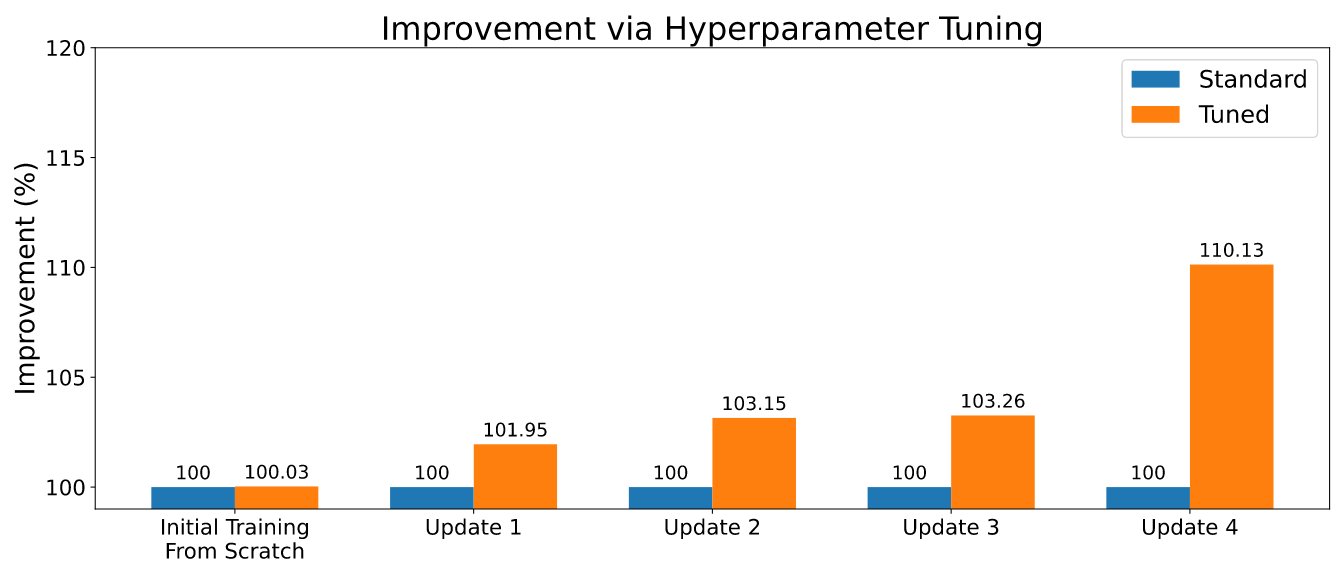
In order to enable HPO, the user will need to define the search space or use one of the default search spaces provided with the library. Refer to the example at Run a training job with HPO. Customers that are looking for a quicker retuning can also leverage the results of their previous tuning jobs by selecting algorithms with transfer learning functionalities. In this way, optimizers will be informed about which hyperparameters are performing well across different tuning jobs and will be able to focus on those, reducing the tuning time.
Run it in the cloud
Renate allows users to quickly transition from training models on a local machine for experimentation to train large-scale neural networks using SageMaker. In fact, running training jobs on a local machine is rather unusual, especially when training large-scale models. At the same time, being able to verify details and test the code locally can be extremely useful. To answer this need, Renate allows quick switching between the local machine and the SageMaker service just by changing a simple flag in the configuration file.
For example, when launching a tuning job, it is possible to run locally execute_tuning_job(..., backend='local') and quickly switch to SageMaker, changing the code as follows:
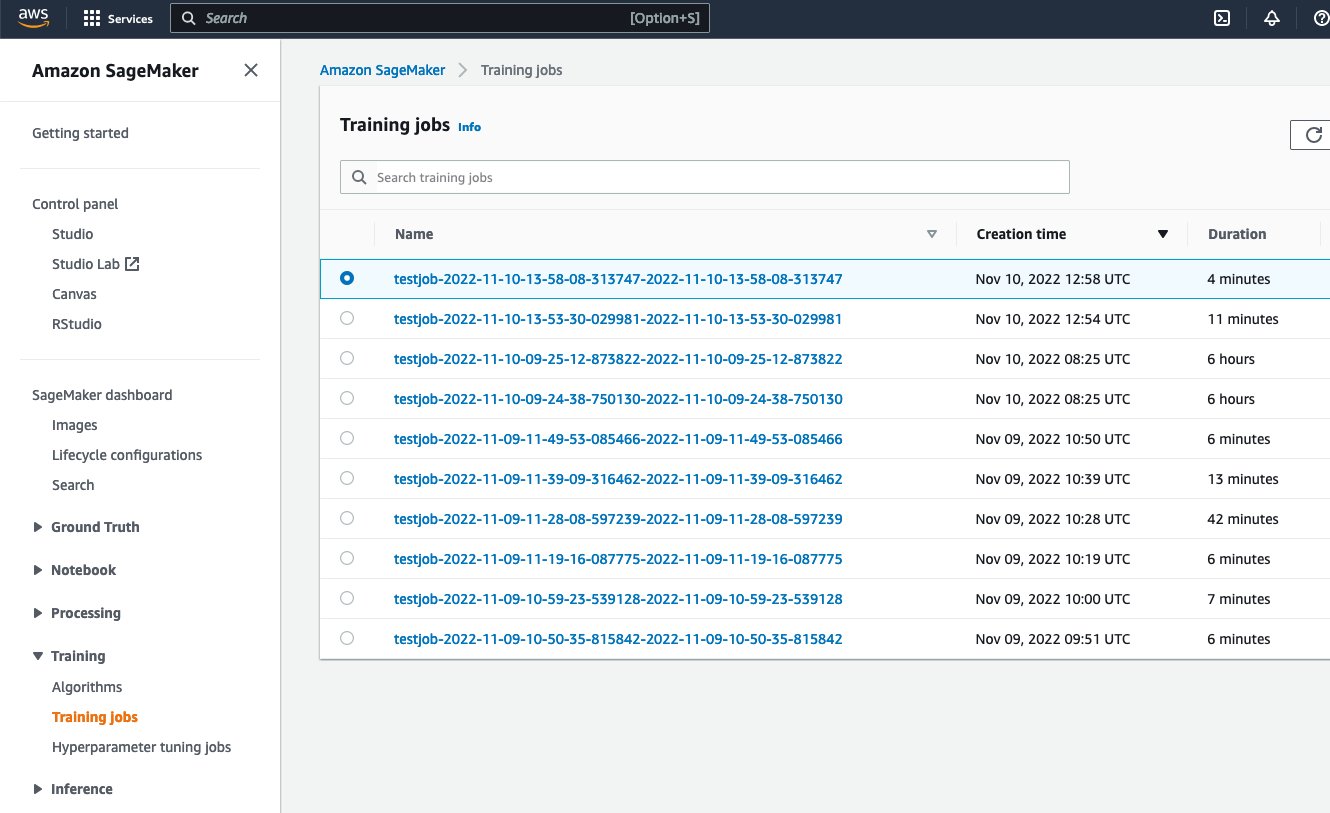
After running the script, it will be possible to see the job running from the SageMaker web interface:
It will also be possible to monitor the training job and read the logs in CloudWatch:
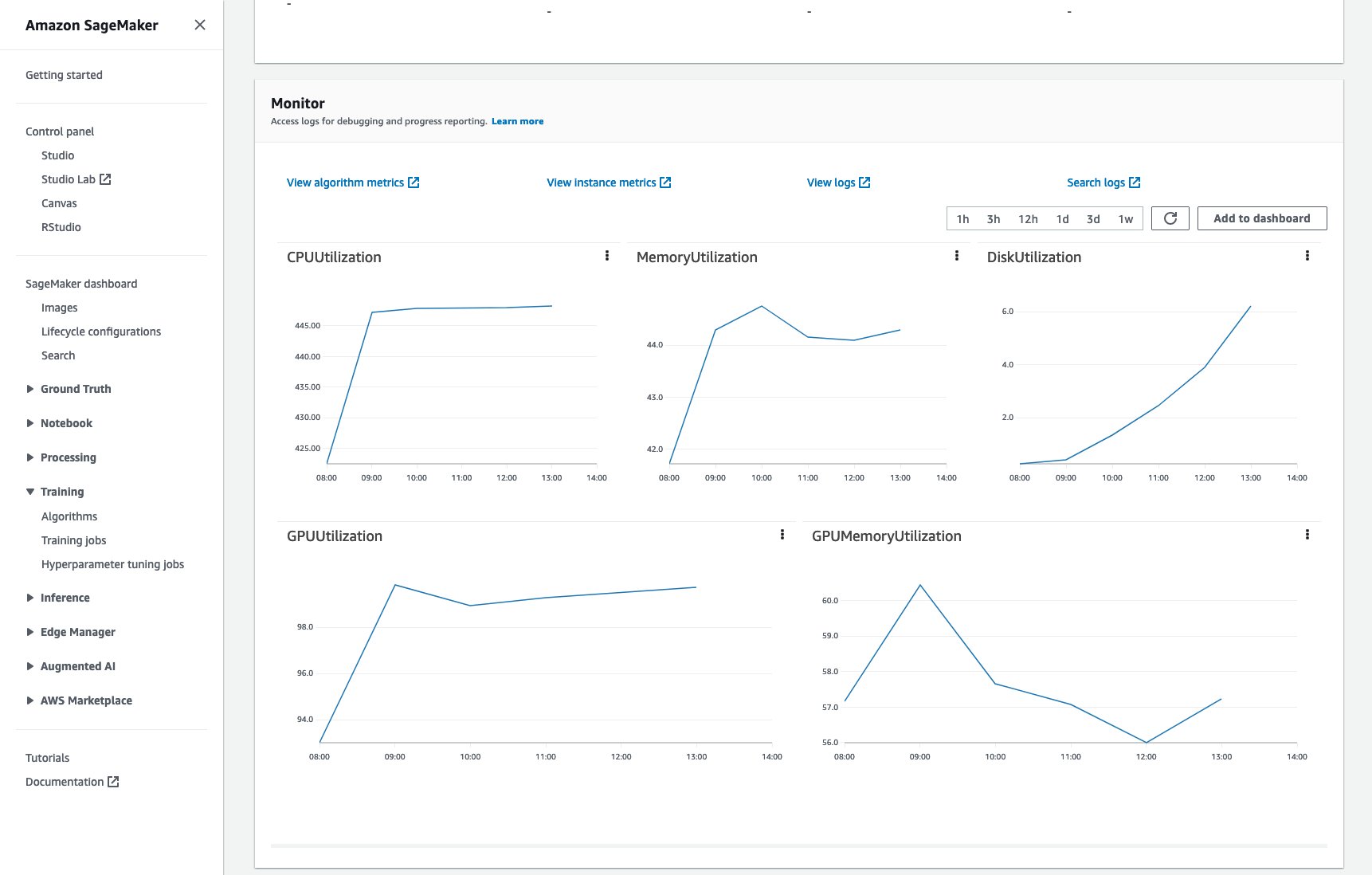
All of this without any additional code or effort.
A full example of running training jobs in the cloud is available at How to Run a Training Job.
Conclusion
In this post, we described the problems associated with retraining neural networks and the main benefits of the Renate library in the process. To learn more about the library, check out the GitHub repository, where you will find a high-level overview of the library and its algorithms, instructions for the installation, and examples that can help you to get you started.
We look forward to your contributions, feedback and discussing this further with everyone interested, and to seeing the library integrated into real-world retraining pipelines.
About the authors
 Giovanni Zappella is a Sr. Applied Scientist working on Long-term science at AWS Sagemaker. He currently works on continual learning, model monitoring and AutoML. Before that he worked on applications of multi-armed bandits for large-scale recommendations systems at Amazon Music.
Giovanni Zappella is a Sr. Applied Scientist working on Long-term science at AWS Sagemaker. He currently works on continual learning, model monitoring and AutoML. Before that he worked on applications of multi-armed bandits for large-scale recommendations systems at Amazon Music.
 Martin Wistuba is an Applied Scientist in the Long-term science team at AWS Sagemaker. His research focuses on automatic machine learning.
Martin Wistuba is an Applied Scientist in the Long-term science team at AWS Sagemaker. His research focuses on automatic machine learning.
 Lukas Balles is an Applied Scientist at AWS. He works on continual learning and topics relating to model monitoring.
Lukas Balles is an Applied Scientist at AWS. He works on continual learning and topics relating to model monitoring.
 Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.
Cedric Archambeau is a Principal Applied Scientist at AWS and Fellow of the European Lab for Learning and Intelligent Systems.