Amazon SageMaker customers can view and manage their quota limits through Service Quotas. In addition, they can view near real-time utilization metrics and create Amazon CloudWatch metrics to view and programmatically query SageMaker quotas.
SageMaker helps you build, train, and deploy machine learning (ML) models with ease. To learn more, refer to Getting started with Amazon SageMaker. Service Quotas simplifies limit management by allowing you to view and manage your quotas for SageMaker from a central location.
With Service Quotas, you can view the maximum number of resources, actions, or items in your AWS account or AWS Region. You can also use Service Quotas to request an increase for adjustable quotas.
With the increasing usage of MLOps practices, and therefore the demand for resources designated for ML model experimentation and retraining, more customers need to run multiple instances, often of the same instance type at the same time.
Many data science teams often work in parallel, using several instances for processing, training, and tuning concurrently. Previously, users would sometimes reach an adjustable account limit for some particular instance type and have to manually request a limit increase from AWS.
To request quota increases manually from the Service Quotas UI, you can choose the quota from the list and choose Request quota increase. For more information, refer to Requesting a quota increase.

In this post, we show how you can use the new features to automatically request limit increases when a high level of instances is reached.
Solution overview
The following diagram illustrates the solution architecture.

This architecture includes the following workflow:
- A CloudWatch metric monitors the usage of the resource. A CloudWatch alarm triggers when the resource usage goes beyond a certain preconfigured threshold.
- A message is sent to Amazon Simple Notification Service (Amazon SNS).
- The message is received by an AWS Lambda function.
- The Lambda function requests the quota increase.
Aside from requesting for a quota increase for the specific account, the Lambda function can also add the quota increase to the organization template (up to 10 quotas). This way, any new account created under a given AWS Organization has the increased quota requests by default.
Prerequisites
Complete the following prerequisite steps:
- Set up an AWS account and create an AWS Identity and Access Management (IAM) user. For instructions, refer to Secure Your AWS Account.
- Install the AWS SAM CLI.
Deploy using AWS Serverless Application Model
To deploy the application using the GitHub repo, run the following command in the terminal:
After the solution is deployed, you should have a new alarm on the CloudWatch console. This alarm monitors usage for SageMaker notebook instances for the ml.t3.medium instance.

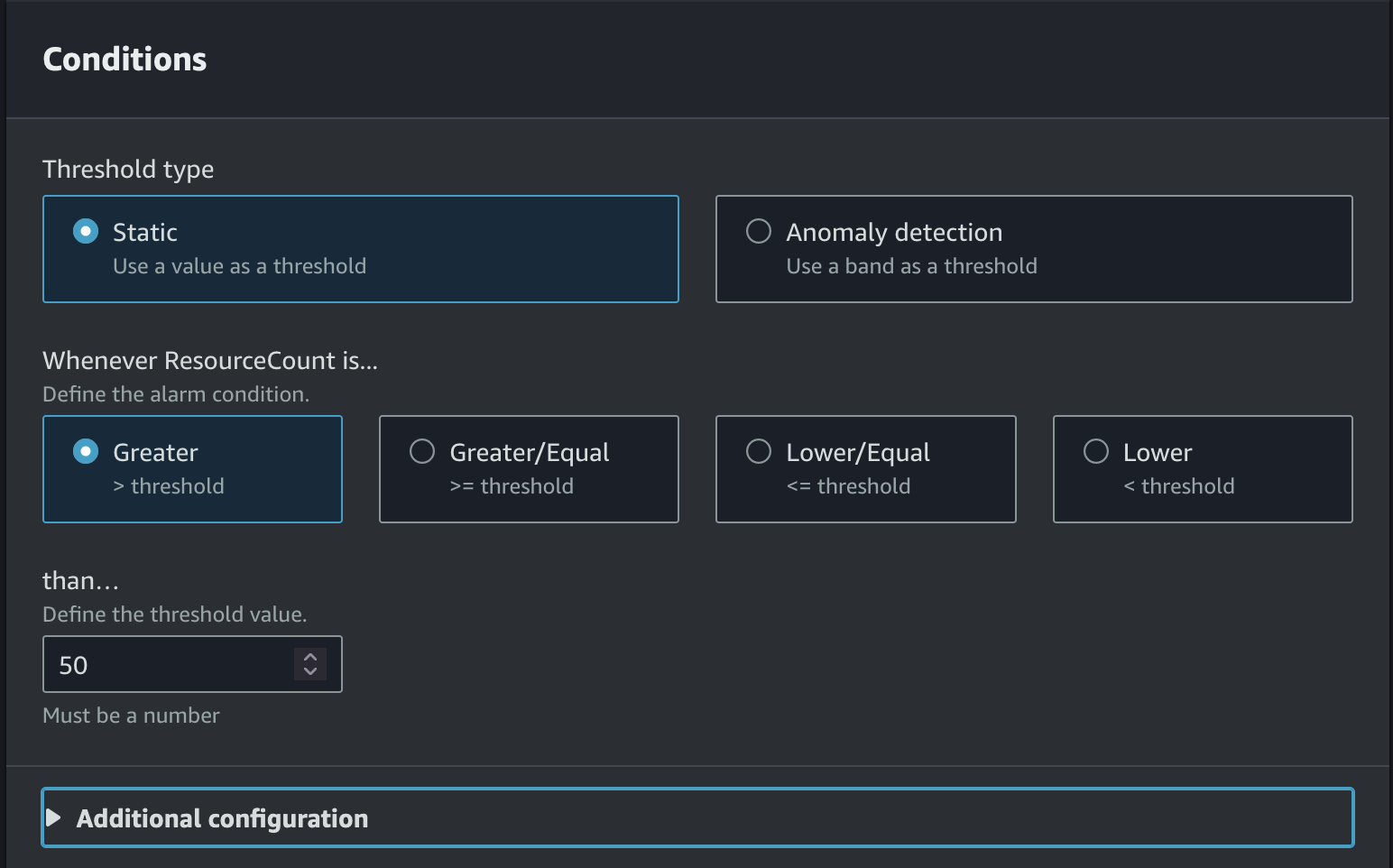
If your resource usage reaches more than 50%, the alarm triggers and the Lambda function requests an increase.


If the account you have is part of an AWS Organization and you have the quota request template enabled, you should also see those increases on the template, if the template has available slots. This way, new accounts from that organization also have the increases configured upon creation.

Deploy using the CloudWatch console
To deploy the application using the CloudWatch console, complete the following steps:
- On the CloudWatch console, choose All alarms in the navigation pane.
- Choose Create alarm.

- Choose Select metric.

- Choose Usage.

- Select the metric you want to monitor.

- Select the condition of when you would like the alarm to trigger.
For more possible configurations when configuring the alarm, see Create a CloudWatch alarm based on a static threshold.
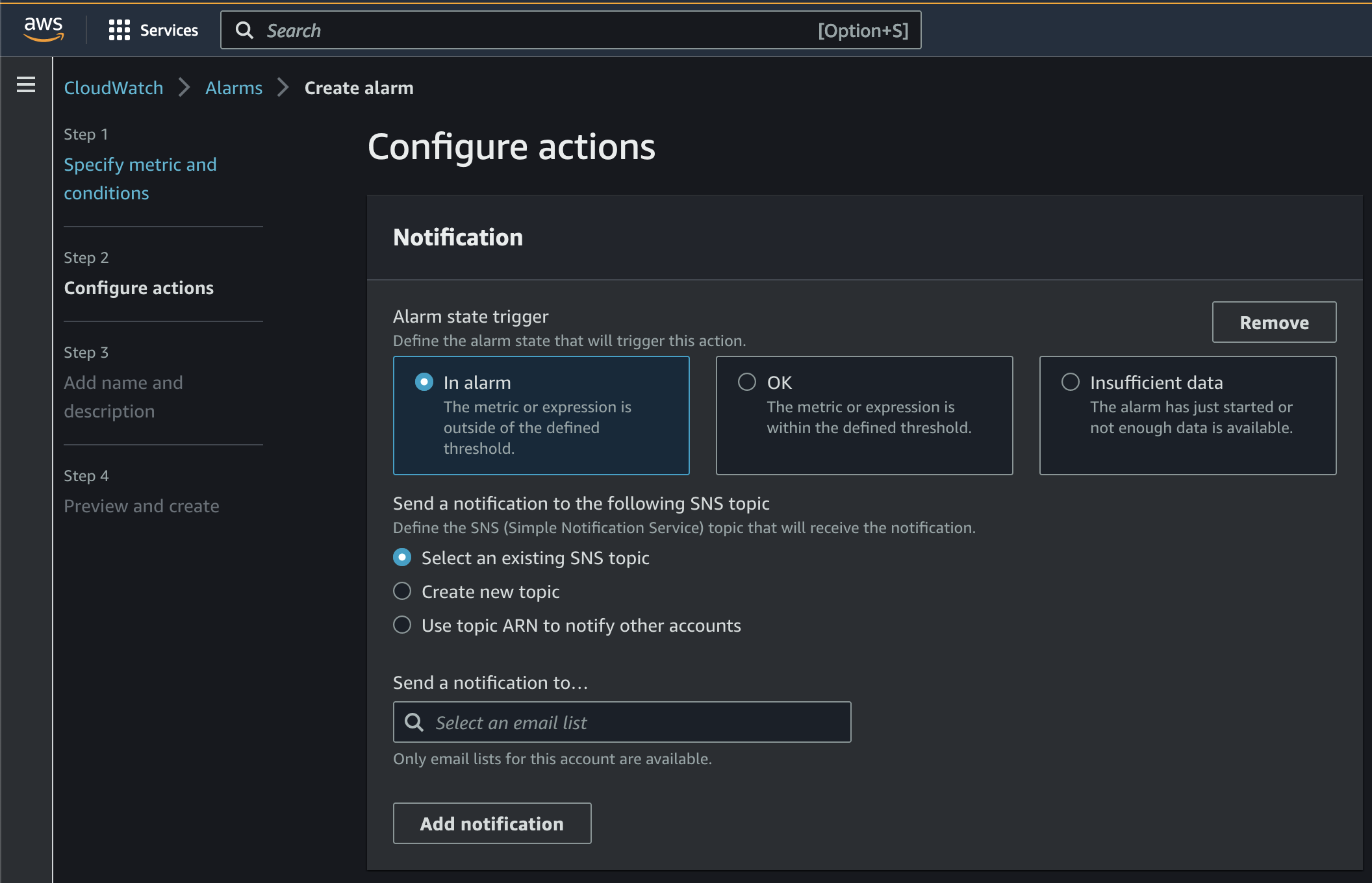
- Configure the SNS topic to be notified about the alarm.
You can also use Amazon SNS to trigger a Lambda function when the alarm is triggered. See Using AWS Lambda with Amazon SNS for more information.
- For Alarm name, enter a name.
- Choose Next.

- Choose Create alarm.

Clean up
To clean up the resources created as part of this post, make sure to delete all the created stacks. To do that, run the following command:
Conclusion
In this post, we showed how you can use the new integration from SageMaker with Service Quotas to automate the requests for quota increases for SageMaker resources. This way, data science teams can effectively work in parallel and reduce issues related to unavailability of instances.
You can learn more about Amazon SageMaker quotas by accessing the documentation. You can also learn more about Service Quotas here.
About the authors
 Bruno Klein is a Machine Learning Engineer in the AWS ProServe team. He particularly enjoys creating automations and improving the lifecycle of models in production. In his free time, he likes to spend time outdoors and hiking.
Bruno Klein is a Machine Learning Engineer in the AWS ProServe team. He particularly enjoys creating automations and improving the lifecycle of models in production. In his free time, he likes to spend time outdoors and hiking.
 Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build Amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area. You can find him on LinkedIn.
Paras Mehra is a Senior Product Manager at AWS. He is focused on helping build Amazon SageMaker Training and Processing. In his spare time, Paras enjoys spending time with his family and road biking around the Bay Area. You can find him on LinkedIn.