Posted by Jessica Yung and Joan Puigcerver
In this article, we’ll walk you through using BigTransfer (BiT), a set of pre-trained image models that can be transferred to obtain excellent performance on new datasets, even with only a few examples per class.
ImageNet-pretrained ResNet50s are a current industry standard for extracting representations of images. With our BigTransfer (BiT) paper, we share models that perform significantly better across many tasks, and transfer well even when using only a few images per dataset.
You can find BiT models pre-trained on ImageNet and ImageNet-21k in TFHub as TensorFlow2 SavedModels that you can use easily as Keras Layers. There are a variety of sizes ranging from a standard ResNet50 to a ResNet152x4 (152 layers deep, 4x wider than a typical ResNet50) for users with larger computational and memory budgets but higher accuracy requirements.
| Figure 1: The x-axis shows the number of images used per class, ranging from 1 to the full dataset. On the plots on the left, the curve in blue above is our BiT-L model, whereas the curve below is a ResNet-50 pre-trained on ImageNet (ILSVRC-2012). |
In this tutorial, we show how to load one of our BiT models and either (1) use it out-of-the-box or (2) fine-tune it to your target task for higher accuracy. Specifically, we demonstrate using a ResNet50 trained on ImageNet-21k.
What is Big Transfer (BiT)?
Before we get into the details of how to use the models, how did we train models that transfer well to many tasks?
Upstream training
The essence is in the name – we effectively train large architectures on large datasets. Before our paper, few papers had seen significant benefits from training on larger public datasets such as ImageNet-21k (14M images, 10x larger than the commonly-used ImageNet). The components we distilled for training models that transfer well are:
Big datasets
The best performance across our models increases as the dataset size increases.
Big architectures
We show that in order to make the most out of big datasets, one needs large enough architectures. For example, training a ResNet50 on JFT (which has 300M images) does not always improve performance relative to training the ResNet50 on ImageNet-21k (14.8M images), but we consistently see improvements when training larger models like a ResNet152x4 on JFT as opposed to ImageNet-21k (Figure 2 below).

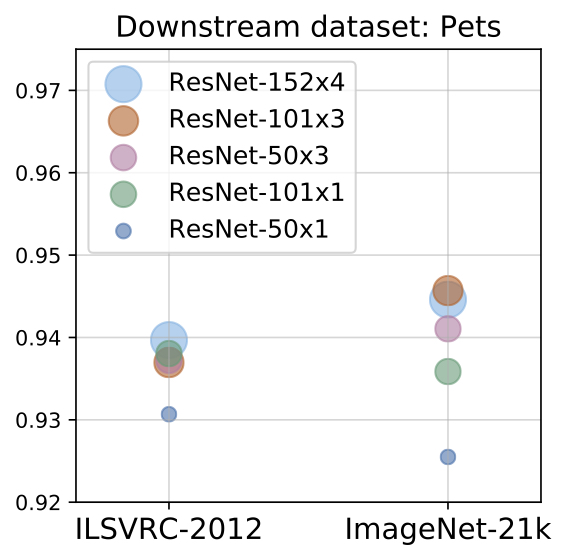
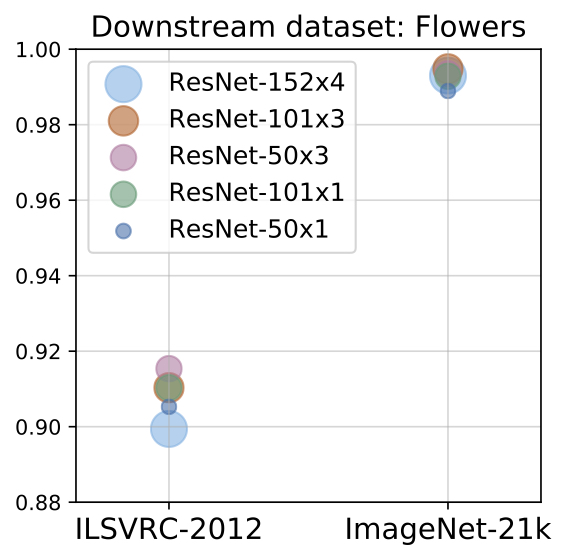
| Figure 2: The effect of larger upstream datasets (x-axis) and model size (bubble size/colour) on performance on downstream tasks. Using larger datasets or larger models alone may hurt performance – both need to be increased in tandem. |
Long pre-training time
We also show that it’s important to train for long enough when pre-training on larger datasets. It’s standard to train on ImageNet for 90 epochs, but if we train on a larger dataset such as ImageNet-21k for the same number of steps (and then fine-tune on ImageNet), the performance is worse than if we’d trained on ImageNet directly.
GroupNorm and Weight Standardisation
Finally, we use GroupNorm combined with Weight Standardisation instead of BatchNorm. Since our models are large, we can only fit a few images on each accelerator (e.g. GPU or TPU chip). However, BatchNorm performs worse when the number of images on each accelerator is too low. GroupNorm does not have this problem, but does not scale well to large overall batch sizes. But when we combine GroupNom with Weight Standardisation, we see that GroupNorm scales well to large batch sizes, even outperforming BatchNorm.
Downstream fine-tuning
Moreover, downstream fine-tuning is cheap in terms of data efficiency and compute – our models attain good performance with only a few examples per class on natural images. We also designed a hyperparameter configuration which we call ‘BiT-HyperRule’ that performs fairly well on many tasks without the need to do an expensive hyperparameter sweep.
BiT-HyperRule: our hyperparameter heuristic
As alluded to above, this is not a hyperparameter sweep – given a dataset, it specifies one set of hyperparameters that we’ve seen produce good results. You can often obtain better results by running a more expensive hyperparameter sweep, but BiT-HyperRule is an effective way of getting good initial results on your dataset.
In BiT-HyperRule, we use SGD with an initial learning rate of 0.003, momentum 0.9, and batch size 512. During fine-tuning, we decay the learning rate by a factor of 10 at 30%, 60% and 90% of the training steps.
As data preprocessing, we resize the image, take a random crop, and then do a random horizontal flip (details in Table 1). We do random crops and horizontal flips for all tasks except those where such actions destroy label semantics. For example, we don’t apply random crops to counting tasks, or random horizontal flips to tasks where we’re meant to predict the orientation of an object (Figure 3).
 |
| Table 1: Downstream resizing and random cropping details. If images are larger, we resize them to a larger fixed size to benefit from fine-tuning on higher resolution. |
 |
| Figure 3: CLEVR count example: Here the task is to count the number of small cylinders or red objects in the image. We would not apply a random crop since that may crop out objects we would like to count, but we apply a random horizontal flip since that doesn’t change the number of objects we care about in the image (and thus does not change the label). Image attribution: CLEVR count example by Johnson et. al.) |
We determine the schedule length and whether or not to use MixUp (Zhang et. al., 2018, illustrated in Figure 4) according to the dataset size (Table 2).
 |
| Figure 4: MixUp takes pairs of examples and linearly combines the images and labels. These images are taken from the dataset tf_flowers. |
 |
| Table 2: Details on downstream schedule length and when we use MixUp. |
We determined these hyperparameter heuristics based on empirical results. We explain our method and describe our results in more detail in our paper and in our Google AI blog post.
Tutorial
Now let’s actually fine-tune one of these models! You can follow along by running the code in this colab.
1) Load the pre-trained BiT model
You can download one of our BiT models pre-trained on ImageNet-21k from TensorFlow Hub. The models are saved as SavedModels. Loading them is very simple:
import tensorflow_hub as hub
# Load model from TFHub into KerasLayer
model_url = "https://tfhub.dev/google/bit/m-r50x1/1"
module = hub.KerasLayer(model_url)2) Use BiT out-of-the-box
If you don’t yet have labels for your images (or just want to have some fun), you may be interested in using the model out-of-the-box, i.e. without fine-tuning it. For this, we will use a model fine-tuned on ImageNet so it has the interpretable ImageNet label space of 1k classes. Many common objects are not covered, but it gives a reasonable idea of what is in the image.
# use model
logits = imagenet_module(image)Note that BiT models take inputs with values between 0 and 1.
In the colab, you can load an image from an URL and see what the model predicts:
> show_preds(preds, image[0]) |
| Image from PikRepo |
Here the pre-trained model on ImageNet correctly classifies the photo as an elephant.It is also more likely to be an Indian as opposed to an African elephant because of the size of its ears. In the colab, we also predict on an image from the dataset we’re going to fine-tune on, TF flowers, which has also been used in other tutorials. Note that the correct label ‘tulip’ is not a class in ImageNet and so the model cannot predict that at the moment – let’s see what it tries to do instead:
The model predicts a reasonably similar-looking class, ‘bell pepper’.
3) Fine-tune BiT on your task
Now, we are going to fine-tune the BiT model so it performs better on a specific dataset. Here we are going to use Keras for simplicity, and we are going to fine-tune the model on a dataset of flowers (tf_flowers). We will use the model we loaded at the start (i.e. the one pre-trained on ImageNet-21k) so that it is less biased towards a narrow subset of classes.
There are two steps:
- Create a new model with a new final layer (called the ‘head’)
- Fine-tune this model using BiT-HyperRule, our hyperparameter heuristic. We described this in detail earlier in the ‘Downstream fine-tuning’ section of the post.
To create the new model, we:
- Cut off the BiT model’s original head. This leaves us with the “pre-logits” output.
- We do not have to do this if we use the ‘feature extraction’ models, since for those models the head has already been cut off.
- Add a new head with the number of outputs equal to the number of classes of our new task. Note that it is important that we initialise the head to all zeroes.
class MyBiTModel(tf.keras.Model):
"""BiT with a new head."""
def __init__(self, num_classes, module):
super().__init__()
self.num_classes = num_classes
self.head = tf.keras.layers.Dense(num_classes, kernel_initializer='zeros')
self.bit_model = module
def call(self, images):
# No need to cut head off since we are using feature extractor model
bit_embedding = self.bit_model(images)
return self.head(bit_embedding)
model = MyBiTModel(num_classes=5, module=module)When we fine-tune the model, we use BiT-HyperRule, our heuristic for choosing hyperparameters for downstream fine-tuning which we described earlier. We also code our heuristic in full in the colab.
# Define optimiser and loss
# Decay learning rate by factor of 10 at SCHEDULE_BOUNDARIES.
lr = 0.003
SCHEDULE_BOUNDARIES = [200, 300, 400, 500]
lr_schedule = tf.keras.optimizers.schedules.PiecewiseConstantDecay(boundaries=SCHEDULE_BOUNDARIES,
values=[lr, lr*0.1, lr*0.001, lr*0.0001])
optimizer = tf.keras.optimizers.SGD(learning_rate=lr_schedule, momentum=0.9)To fine-tune the model, we use the simple Keras model.fit API:
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
model.compile(optimizer=optimizer,
loss=loss_fn,
metrics=['accuracy'])
# Fine-tune model
model.fit(
pipeline_train,
batch_size=512,
steps_per_epoch=10,
epochs=50,
validation_data=pipeline_test)We see that our model attains 95% validation accuracy within 20 steps, and attains over 98% validation accuracy after fine-tuning using BiT-HyperRule.
4) Save the fine-tuned model for later use
It is easy to save your model to use later on. You can then load your saved model in exactly the same way as we loaded the BiT models at the start.
# Save fine-tuned model as SavedModel
export_module_dir = '/tmp/my_saved_bit_model/'
tf.saved_model.save(model, export_module_dir)
# Load saved model
saved_module = hub.KerasLayer(export_module_dir, trainable=True) Voila – we now have a model that predicts tulips as tulips and not bell peppers.
Voila – we now have a model that predicts tulips as tulips and not bell peppers.
Summary
In this post, you learned about the key components you can use to train models that can transfer well to many different tasks. You also learned how to load one of our BiT models, fine-tune it on your target task and save the resulting model. Hope this helped and happy fine-tuning!
Acknowledgements
This blog post is based on work by Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly and Neil Houlsby. We thank many members of Brain Research Zurich and the TensorFlow team for their feedback, especially Luiz Gustavo Martins, André Susano Pinto, Marcin Michalski, Josh Gordon, Martin Wicke, Daniel Keysers, Amélie Royer, Basil Mustafa, and Mario Lučić.
Additional links