Medical imaging is an important tool for the diagnosis and localization of disease. Over the past decade, collections of medical images have grown rapidly, and open repositories such as The Cancer Imaging Archive and Imaging Data Commons have democratized access to this vast imaging data. Computational tools such as machine learning (ML) and artificial intelligence (AI) have emerged as an effective and viable option for rapid analysis of this imaging data. Many algorithms have been developed for different kinds of image analysis. These include classification, segmentation, and localization, to name a few. However, the development of the algorithm and training of the required ML model is only one piece of the larger ML/AI puzzle.
Cost-efficient and high-performance deployment of the model is also vital. Additionally, for a model to be of any use at scale, it must be deployed for inference in a reliable, scalable environment.
In this post, we discuss one possible approach of using native AWS technologies to deploy ML algorithms at scale for a medical imaging use case. We talk about segmenting a tumor from MRI brain scans and cover solution architecture, compute infrastructure, and results.
Solution overview
The solution proposed in this post is based around a trained U-net model using the popular Keras framework and with a sample dataset from the popular Kaggle competition platform.
The trained U-net model is then processed via the AWS Neuron SDK so that it can be optimized to target Amazon EC2 Inf1 instances, featuring AWS Inferentia, the first AWS ML accelerator optimized for inference.
The solution uses a managed elastic architecture with fast storage to ensure that high throughput is maintained across each layer of the solution. The following diagram describes the overall architecture.
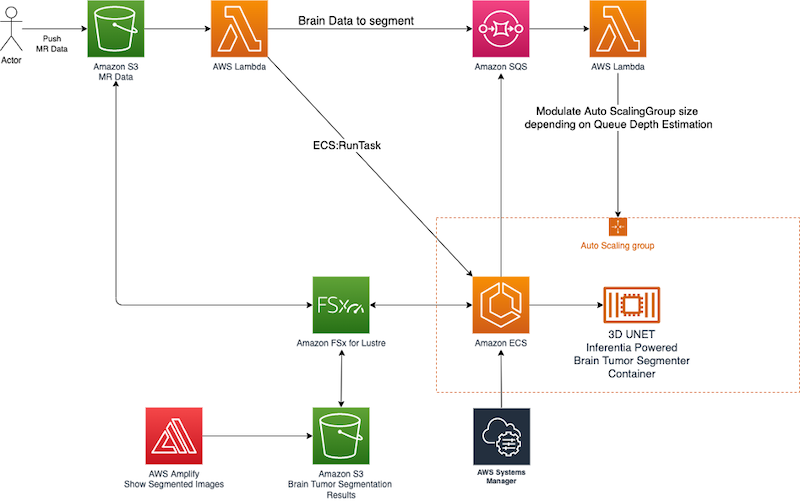
The central idea around the proposed architecture spins around an elastic cluster of AWS Inferentia-powered containers running on Amazon Elastic Container Service (Amazon ECS) serving a U-net model optimized via the AWS Neuron SDK.
The inference nodes: AWS Inferentia

AWS offers various ways to deploy a deep learning model in the cloud. One option uses AWS Inferentia, which is a high-performance ML inference chip designed by AWS.
AWS Inferentia delivers up to 80% lower cost per inference and up to 2.3 times higher throughput than comparable current generation GPU-based Amazon Elastic Compute Cloud (Amazon EC2) instances. With Inf1 instances, you can run high-scale ML inference applications for a variety of medical imaging uses cases. The AWS Neuron SDK optimizes models for deployment onto AWS Inferentia-powered instances.
AWS Neuron consists of a compiler, runtime, and profiling tools that help optimize the performance of workloads for AWS Inferentia.
With AWS Neuron, developers can deploy neural network models using popular frameworks like PyTorch or TensorFlow on AWS Inferentia-based EC2 Inf1 instances.
The workflow to deploy a trained deep learning model into an AWS Inferentia accelerated inference node consists of the following steps:
- Train a neural network model.
- Process the trained model via the AWS Neuron compiler to generate an AWS Inferentia-optimized trained neural model.
- Use the AWS Neuron runtime to load the AWS Inferentia-optimized model to EC2 Inf1 instances and run inference requests.
Inference at scale: An elastic architecture for AWS Inferentia
The architecture elasticity is determined by an AWS Lambda function and Amazon Simple Queue Service (Amazon SQS) queue that receives requests for segmentations initiated by simply uploading the volume that needs to be segmented into an Amazon Simple Storage Service (Amazon S3) bucket.
The AWS Inferentia ECS cluster gets fed from a highly performant Amazon FSx for Lustre file system, which accelerates compute workloads with shared storage that provides sub-millisecond latencies, up to hundreds of GBs/s of throughput, and millions of IOPS.
The following diagram outlines the architecture that enables the AWS Inferentia cluster to be elastic and scale dynamically according the number of inference requests submitted to the whole system.
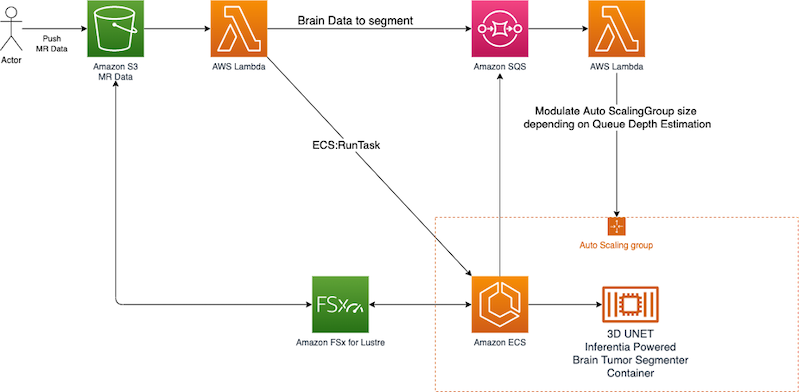
In this architecture, an actor pushes an image volume to an S3 bucket. After the image volume is uploaded to THE S3 bucket, a Lambda function gets triggered using the built-in Amazon S3 event notification.
This function places the image volume S3 key into a request queue implemented via Amazon SQS. At the same time, it instructs the AWS Inferentia ECS cluster to start a new task to process the uploaded image volume.
To compliment this architecture, another Lambda function fetches the SQS queue depth and uses this value to modulate the size of the ECS cluster, adding or removing nodes according to the queue depth.
To ensure that the ECS cluster can be fed constantly with data, a highly performant FSx for Lustre file system is placed in front of the ECS cluster. Here, using the automated integration of FSx for Lustre with Amazon S3, the data uploaded into the S3 bucket landing zone is automatically made available in the FSx for Lustre file system and is ready to be consumed by the ECS cluster.
Inference results
The following sample images show the results of a brain tumor classification (multi-class segmentation) task done using the architecture described in this post.

The following figure shows the benchmark results of AWS Inferentia vs. NVIDIA Tesla V100-SXM2-16GB GPU.

Conclusion
Medical imaging is an important tool for the diagnosis and localization of disease. With the growing demand for diagnosis from various modalities, for example from emergency units, the need for automated tools to isolate and support radiologists and doctors in the diagnosis of various pathologies is becoming increasingly important.
In this post, we explored using EC2 Inf1 instance types with AWS Inferentia acceleration to build an elastic inference architecture that can support the ever-increasing inference demand while keeping costs under control.
To learn more about how AWS is accelerating innovation in healthcare, visit AWS for Health.
About the Author
 Benedetto Carollo is the Senior Solution Architect for medical imaging and healthcare at Amazon Web Services in Europe, Middle East, and Africa. His work focuses on helping medical imaging and healthcare customers solve business problems by leveraging technology. Benedetto has over 15 years of experience of technology and medical imaging and has worked for companies like Canon Medical Research and Vital Images. Benedetto received his summa cum laude MSc in Software Engineering from the University of Palermo – Italy.
Benedetto Carollo is the Senior Solution Architect for medical imaging and healthcare at Amazon Web Services in Europe, Middle East, and Africa. His work focuses on helping medical imaging and healthcare customers solve business problems by leveraging technology. Benedetto has over 15 years of experience of technology and medical imaging and has worked for companies like Canon Medical Research and Vital Images. Benedetto received his summa cum laude MSc in Software Engineering from the University of Palermo – Italy.