Machine Learning for Code Repair
Across the board, programming has increased in popularity, ranging from developing with general-purpose programming languages like Python, C, Java to using simpler languages like HTML, SQL, LaTeX, and Excel formulas. When writing code we often make syntax errors such as typos, unbalanced parentheses, invalid indentations, etc., and need to fix them. In fact, several studies 1 show that both beginner and professional programmers spend 50% of time fixing code errors during programming. Automating code repair can dramatically enhance the programming productivity 2.
Recent works 3 use machine learning models to fix code errors by training the models on human-labeled (broken code, fixed code) pairs. However, collecting this data for even a single programming language is costly, much less the dozens of languages commonly used in practice.
On the other hand, unlabeled (unaligned) data—not aligned as (broken, fixed) pairs—is readily available: for example, raw code snippets on the web like GitHub. An unsupervised approach for training code repair models would make them much more scalable and widely deployable. In our recent work 4 published at ICML 2021, we study how to leverage unlabeled data to learn code fixers effectively.
Problem Setup
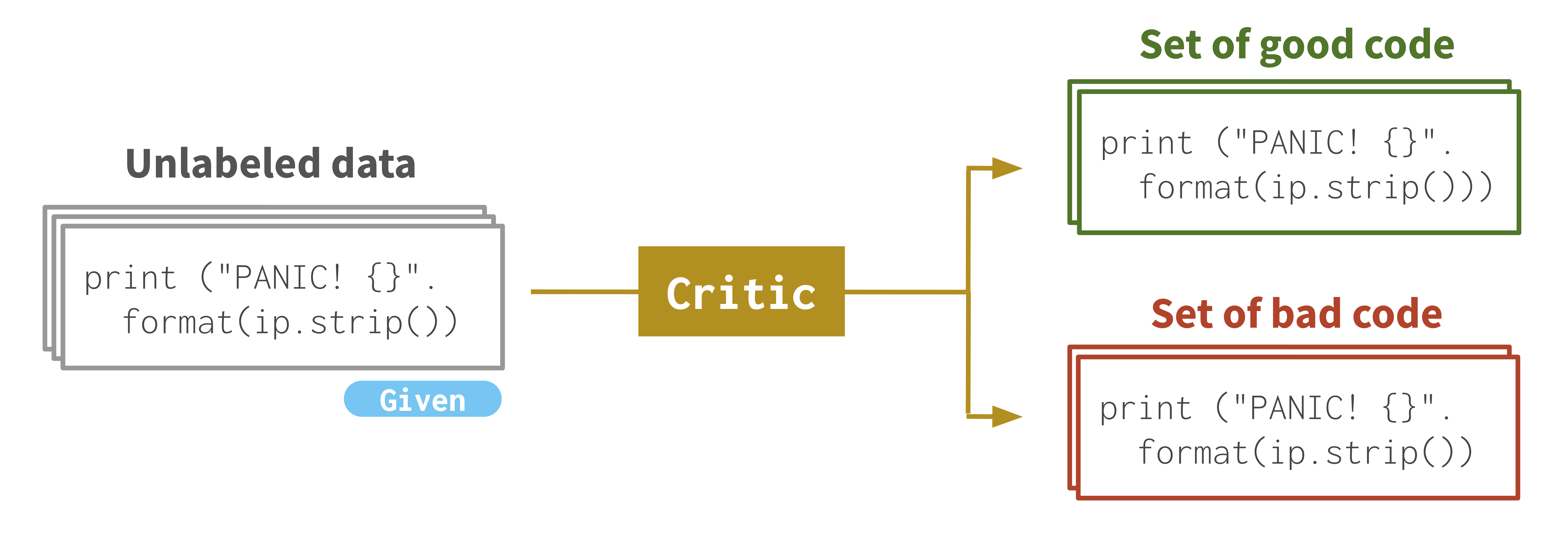
In code repair, we are given a critic that assesses the quality of an input: for instance, a compiler or code analyzer that tells us if input code has any syntax errors. The code is bad if there is at least one error and it is good if there are no errors. What we want is a fixer that repairs bad code into good code that satisfies the critic, e.g. repairing missing parenthesis as in the figure below. Our goal is to use unlabeled data and critic to learn a fixer.
Challenges
While unlabeled data can be split into a set of good code and a set of bad code using the critic, they are unaligned; in other words, they do not form (broken, fixed) pairs ready to be used for training a fixer.
A straightforward technique 5 is to apply random or heuristic perturbations to good code, such as dropping tokens, and prepare synthetic paired data (perturbed code, good code) to train a fixer. However, such synthetically-generated bad code does not match the distribution of real bad code written by humans. For instance, as the figure below shows, synthetic perturbations (purple box) may drop parentheses arbitrarily from code, generating errors that are rare in real code. In contrast, human-written code (red box) rarely misses parentheses when only a single pair appears, but misses parentheses often in a nested context (e.g., 10x more than non-nested in our Python code dataset collected from GitHub). This distributional mismatch between synthetic data and real data can result in low code repair performance when used in practice. To tackle this challenge, we introduce a new training approach, Break-It-Fix-It (BIFI), that adapts the fixer towards real distributions of bad code.

Approach: Break-It-Fix-It
The basic idea of BIFI is to introduce a machine learning-based breaker that learns to corrupt good code into realistic bad code, and iteratively train both the fixer and the breaker while using them in conjunction to generate more realistic paired data. Concretely, BIFI takes as inputs:
- Critic
- Unaligned set of good and bad code
- Initial fixer, which potentially is trained on synthetic data
BIFI then improves the fixer by performing the following cycle of data generation and training procedure:
- Apply the fixer to the set of bad code, which consists of real code errors made by humans, and use the critic to assess if the fixer’s output is good. If good, keep the pair
- Train the breaker on the resulting paired data from Step 1. Consequently, the breaker can generate more realistic errors than the initial synthetic data
- Apply the breaker to the set of good code, and keep outputs that the critic judges as bad
- Train the fixer on the newly-generated paired data in Step 1 and Step 3
These steps are also illustrated in the left panel of the figure below. We iterate over this cycle to improve the fixer and the breaker simultaneously until they have both converged. The intuition is that a better fixer and breaker will be able to generate more realistic paired data, which in turn helps to train a better fixer and breaker.
BIFI is related to the backtranslation (cycle-consistency) method in unsupervised translation 6. If we apply backtranslation directly to the code repair task, we would do the following:
- Apply the fixer to the set of bad code and generate (noisy) good code
- Train the breaker to reconstruct the bad code
- Apply the breaker to the set of good code and generate (noisy) bad code
- Train the fixer to reconstruct the good code
as illustrated in the right panel of the figure. BIFI improves on backtranslation in two aspects. First, while backtranslation may include non-fixed code as good or non-broken code as bad in Step 1 or 3, BIFI uses the critic to verify if the generated code is actually fixed or broken in Step 1 and 3, as highlighted with pink in the left panel of the figure. This ensures the correctness of training data generated by the breaker and fixer. Second, while backtranslation only uses paired data generated in Step 3 to train the fixer in Step 4, BIFI uses paired data generated in both Step 3 and Step 1, as paired data from Step 1 contains real code errors made by humans. This improves the distributional match of generated training data.
Let’s use our code repair model!
We apply and evaluate our method, BIFI, on two code repair benchmarks:
- GitHub-Python 7: Fix syntax errors in Python code. Critic is Python AST parser.
- DeepFix 8: Fix compiler errors in C code. Critic is C compiler.
BIFI improves on existing unsupervised methods for code repair
Using the GitHub-Python dataset, we first compare BIFI with existing unsupervised methods for code repair: a synthetic baseline that uses synthetic paired data generated by randomly dropping, inserting or replacing tokens from good code, and a backtranslation baseline that directly applies backtracklation to code repair. The synthetic baseline serves as the initial fixer for our BIFI algorithm. We find that BIFI improves the repair accuracy by 28% (62%→90%) over the synthetic baseline and by 10% (80%→90%) over the backtranslation baseline, as shown in the left panel of the figure. This result suggests that while we started from a simple initial fixer trained with random perturbations, BIFI can automatically turn it into a usable fixer with high repair accuracy.
For the other dataset, DeepFix, there are several prior works that use heuristic ways to generate synthetic paired data for the task: Gupta+17 9, Hajipour+19 10, DrRepair 11. We take the existing best model, DrRepair, as our initial fixer and apply BIFI. We find that it improves the repair accuracy by 5% (66%→71%), as shown in the right panel of the figure. This result suggests that while the initial fixer DrRepair was already trained with manually designed heuristics, there is still room for improving the adaptation to a more realistic distribution of code errors. BIFI helps to achieve this without additional manual effort.
Examples of breaker outputs
Let’s look at several examples of code generated by the trained breaker. Given the good Python code shown on the left below, we show on the right outputs that the breaker places high probability on. In output 1, the breaker converts raise ValueError(...) into raise ValueError, ..., which is an obsolete usage of raise in Python. In output 2, the breaker drops a closing parenthesis in a nested context. These are both errors commonly seen in human written bad code.
Examples of fixer outputs
Let’s look at how our fixer performs through examples too. The left side of the figure shows human-written Python code with an indentation error—one needs to add indent to the err = 0 line and remove indent in the next line. The initial fixer, shown in the center, only inserts one indent token and fails to fix the error. This is most likely due to the mismatch between real errors and synthetic errors used in training: synthetic errors generated by random perturbations do not frequently contain this kind of indentation error where multiple tokens need to be inserted/removed accordingly. The fixer trained by BIFI, shown on the right, fixes the indentation error by inserting and removing the correct pair of indent tokens. We find that this is one of the representative examples of when BIFI successfully fixes code errors but the initial fixer fails.

Finally, one limitation of this work is that we focus on fixing syntactic errors (we use critics such as AST parser and compiler), and we are not evaluating the semantic correctness of our outputs. Extending BIFI to fixing semantic errors is an exciting future research avenue.
Conclusion
Machine learning of source code repair is an important direction to enhance programming productivity, but collecting human-labeled data is costly. In this work, we studied how to learn source code repair in an unsupervised way, and developed a new training method, BIFI. The key innovation of BIFI is that it creates realistic paired data for training fixers from a critic (e.g. compiler) and unlabeled data (e.g. code snippets on the web) only, which are cheaply available.
More broadly, the idea of learning fixers from critics + unlabeled data is applicable to various repair tasks beyond code repair, such as grammatical error correction 12 and molecule design, using domain-specific critics. Additionally, the idea of using a critic to improve the quality of paired data is applicable to various translation tasks by introducing a learned critic. We hope that BIFI can be an effective solution to unsupervised repair tasks and translation tasks.
You can check out our full paper here and our source code/data on GitHub.
Acknowledgments
This blog post is based on the paper:
- Break-It-Fix-It: Unsupervised Learning for Program Repair. Michihiro Yasunaga and Percy Liang. ICML 2021.
Many thanks to Percy Liang, as well as members of the Stanford P-Lambda group, SNAP group and NLP group for their valuable feedback. Many thanks to Jacob Schreiber and Sidd Karamcheti for edits on this blog post.
-
Reversible Debugging Software. Tom Britton, Lisa Jeng, Graham Carver, Paul Cheak, Tomer Katzenellenbogen. 2013. Programmers’ Build Errors: A Case Study (at Google). Hyunmin Seo, Caitlin Sadowski, Sebastian Elbaum, Edward Aftandilian, Robert Bowdidge. 2014. ↩
-
Improving programming productivity with machine learning is an extremely active area of research. A prominent example is the Copilot / Codex service recently released by OpenAI and GitHub, which translates natural language (e.g. English) descriptions into code. Automated code repair is another complementary technology to improve programming productivity. ↩
-
SEQUENCER: Sequence-to-Sequence Learning for End-to-End Program Repair. Zimin Chen, Steve Kommrusch, Michele Tufano, Louis-Noël Pouchet, Denys Poshyvanyk, Martin Monperrus. 2019. DeepDelta: Learning to Repair Compilation Errors. Ali Mesbah Andrew Rice Emily Johnston Nick Glorioso Eddie Aftandilian. 2019. Patching as Translation: the Data and the Metaphor. Yangruibo Ding, Baishakhi Ray, Premkumar Devanbu, Vincent J. Hellendoorn. 2020 ↩
-
Break-It-Fix-It: Unsupervised Learning for Program Repair. Michihiro Yasunaga, Percy Liang. 2021. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. DeepBugs: A Learning Approach to Name-based Bug Detection. Michael Pradel, Koushik Sen. 2018. Neural program repair by jointly learning to localize and repair. Marko Vasic, Aditya Kanade, Petros Maniatis, David Bieber, Rishabh Singh. 2019. Global relational models of source code. Vincent J. Hellendoorn, Charles Sutton, Rishabh Singh, Petros Maniatis, David Bieber. 2020. ↩
-
Improving Neural Machine Translation Models with Monolingual Data. Rico Sennrich, Barry Haddow, Alexandra Birch. 2016. Phrase-Based & Neural Unsupervised Machine Translation. Guillaume Lample, Myle Ott, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato. 2018. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. ↩
-
DeepFix: Fixing common C language errors by deep learning. Rahul Gupta, Soham Pal, Aditya Kanade, Shirish Shevade. 2017. ↩
-
SampleFix: Learning to Correct Programs by Sampling Diverse Fixes. Hossein Hajipour, Apratim Bhattacharya, Mario Fritz. 2019. ↩
-
Graph-based, Self-Supervised Program Repair from Diagnostic Feedback. Michihiro Yasunaga, Percy Liang. 2020. ↩
-
LM-Critic: Language Models for Unsupervised Grammatical Error Correction. Michihiro Yasunaga, Jure Leskovec, Percy Liang. 2021. ↩