Language Model Pretraining
Language models (LMs), like BERT 1 and the GPT series 2, achieve remarkable performance on many natural language processing (NLP) tasks. They are now the foundation of today’s NLP systems. 3 These models serve important roles in products and tools that we use every day, such as search engines like Google 4 and personal assistants like Alexa 5.
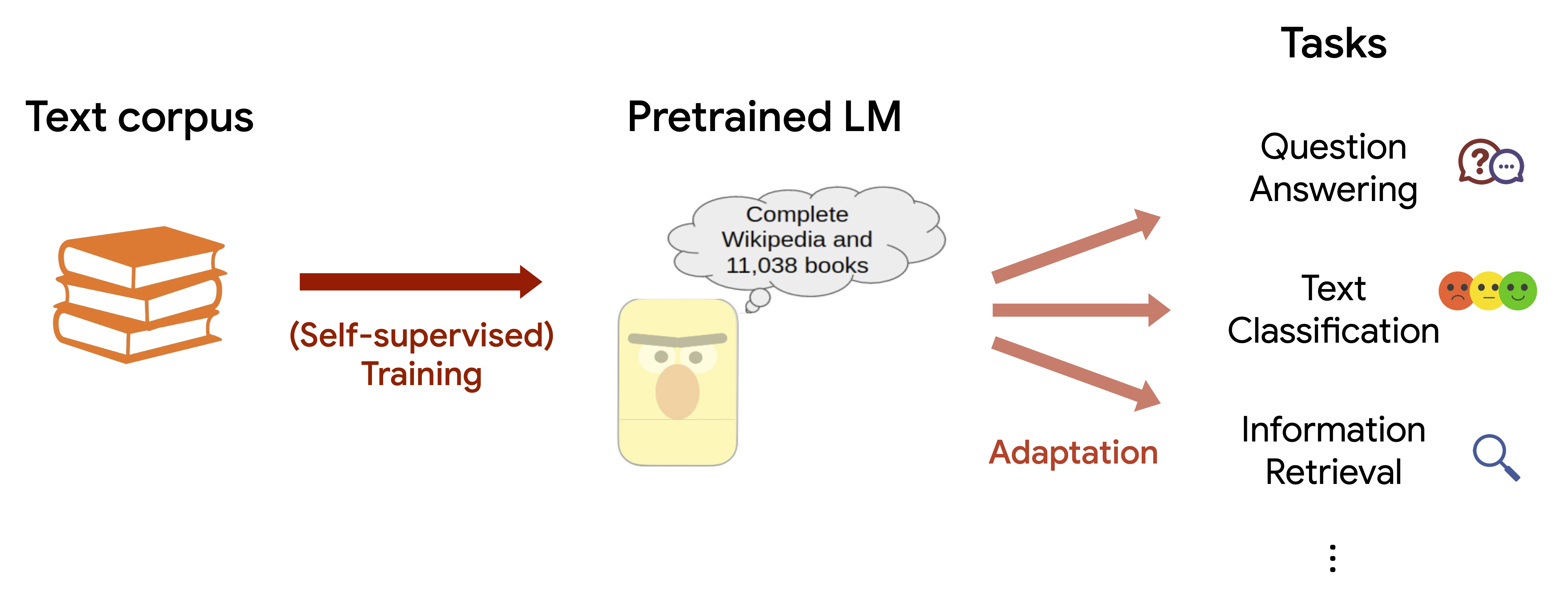
These LMs are powerful because they can be pretrained via self-supervised learning on massive amounts of text data on the web without the need for labels, after which the pretrained models can be quickly adapted to a wide range of new tasks without much task-specific finetuning. For instance, BERT is pretrained to predict randomly masked words in original text (masked language modeling), e.g. predicting the masked word “dog” from “My __ is fetching the ball”. GPTs are pretrained to predict the next word given a previous sequence of text (causal language modeling), e.g. predicting the next word “ball” from “My dog is fetching the”. In either cases, through pretraining, LMs learn to encode various knowledge from a text corpus that helps to perform downstream applications involving language understanding or generation. In particular, LMs can learn world knowledge (associations between concepts like “dog”, “fetch”, “ball”) from training text where the concepts appear together, and help for knowledge-intensive applications like question answering. 6
Challenges.
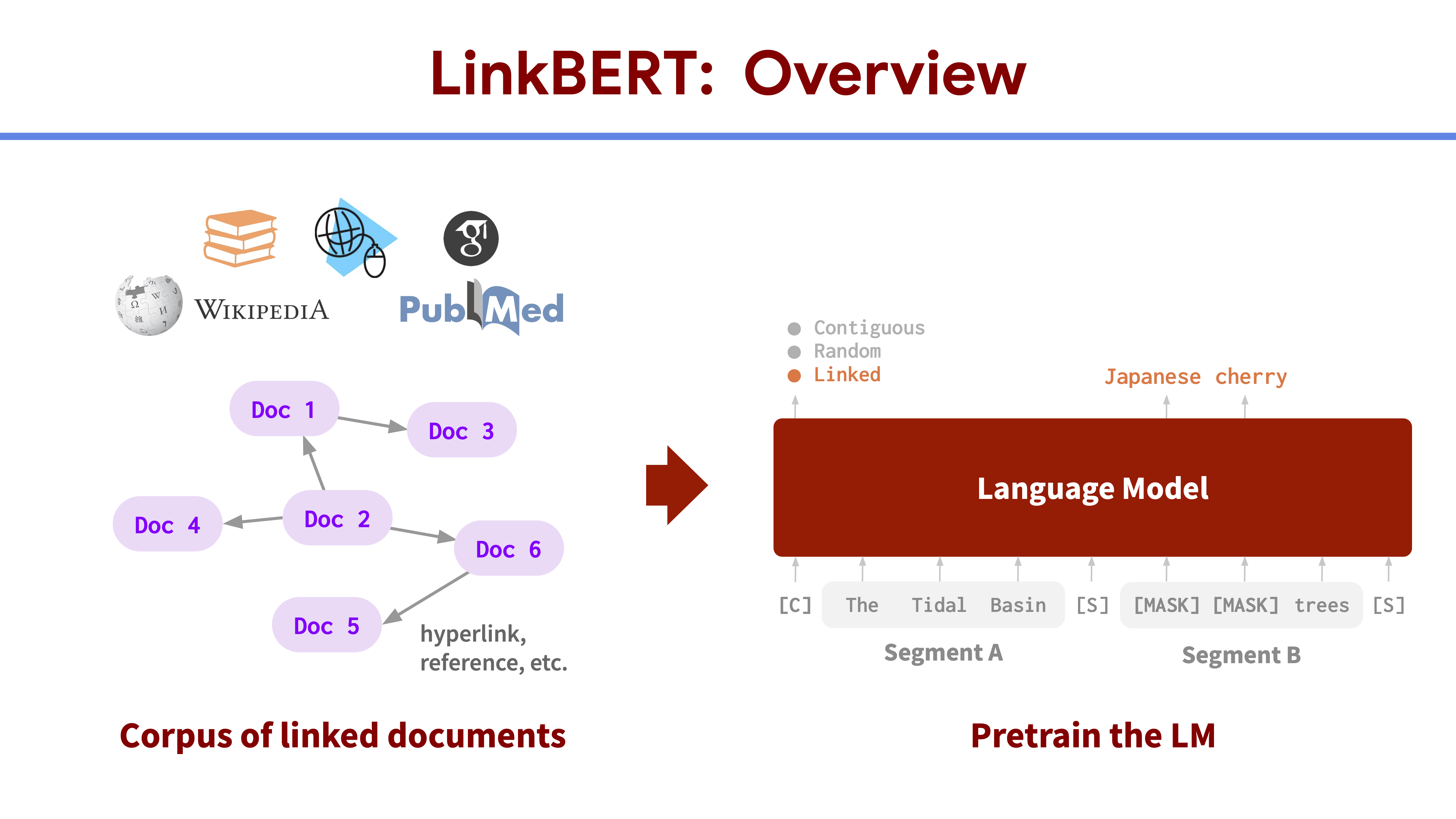
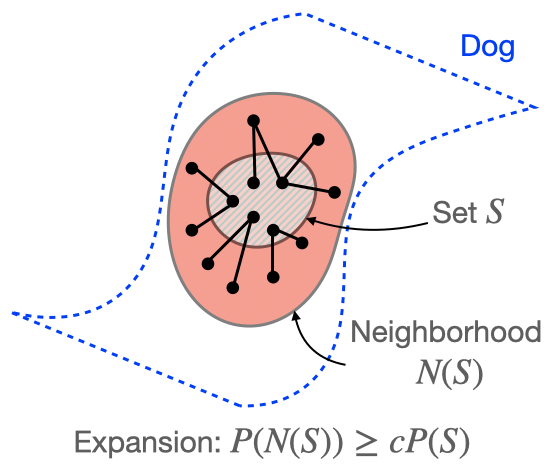
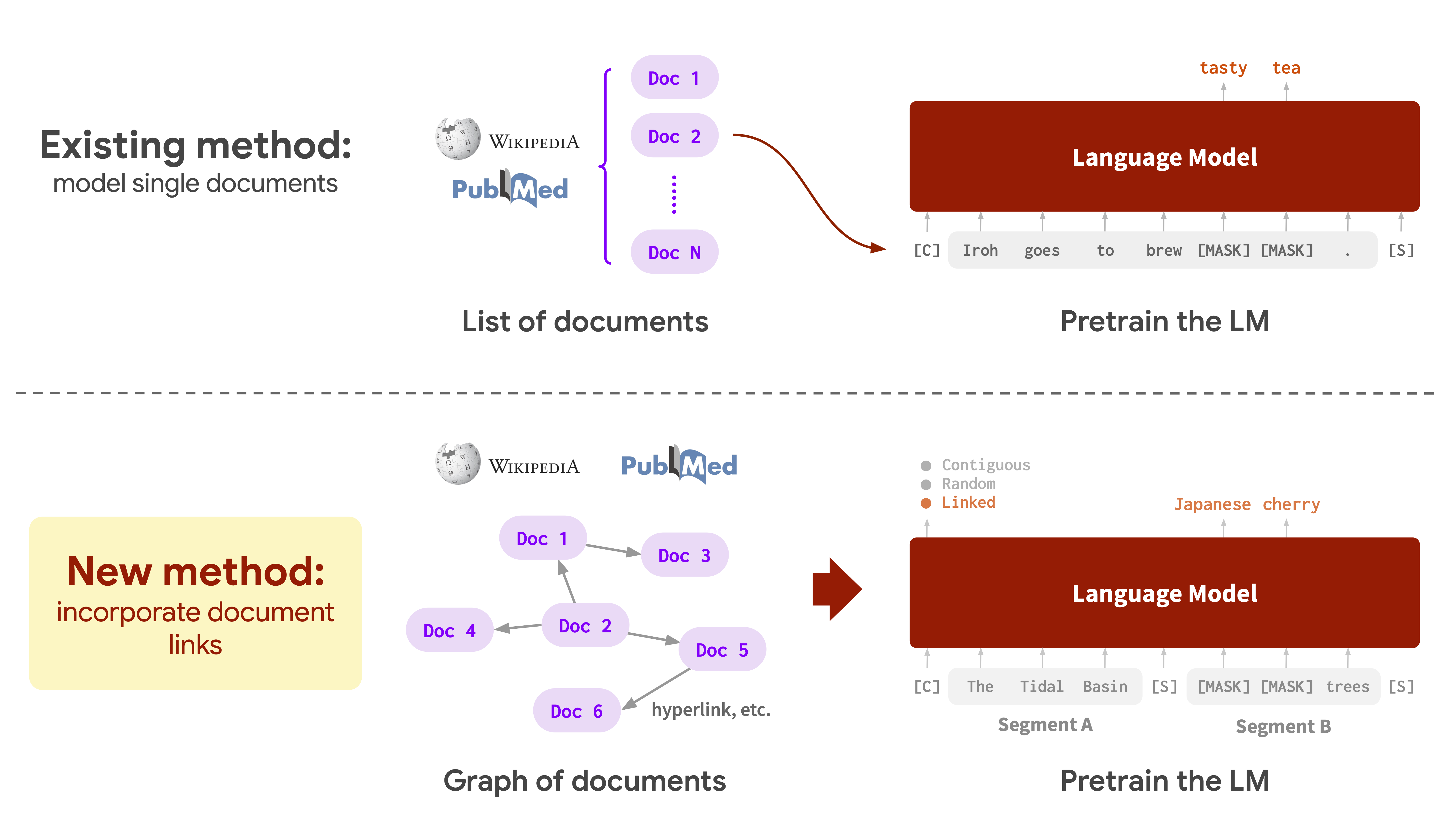
A challenge with most common LM pretraining strategies is that they model a single document at a time. That is, one would split a text corpus into a list of documents and draw training instances for LMs from each document independently. Treating each document independently may pose limitations because documents often have rich dependencies with each other. For instance, text from the web 7 or scientific literature 8 is often used for LM training, but they all have document links, such as hyperlinks and citation links. Document links are crucial because knowledge can span across multiple documents beyond a single document. As an example, the Wikipedia article “Tidal Basin, Washington D.C.” shown on the left of the figure below describes that the basin hosts “National Cherry Blossom Festival”, and if we jump to the hyperlinked article shown on the right, we see that the festival celebrates “Japanese cherry trees”. Combined, the hyperlink offers new, multi-hop knowledge such as “Tidal Basin has Japanese cherry trees”, which is not available in the original single document alone.
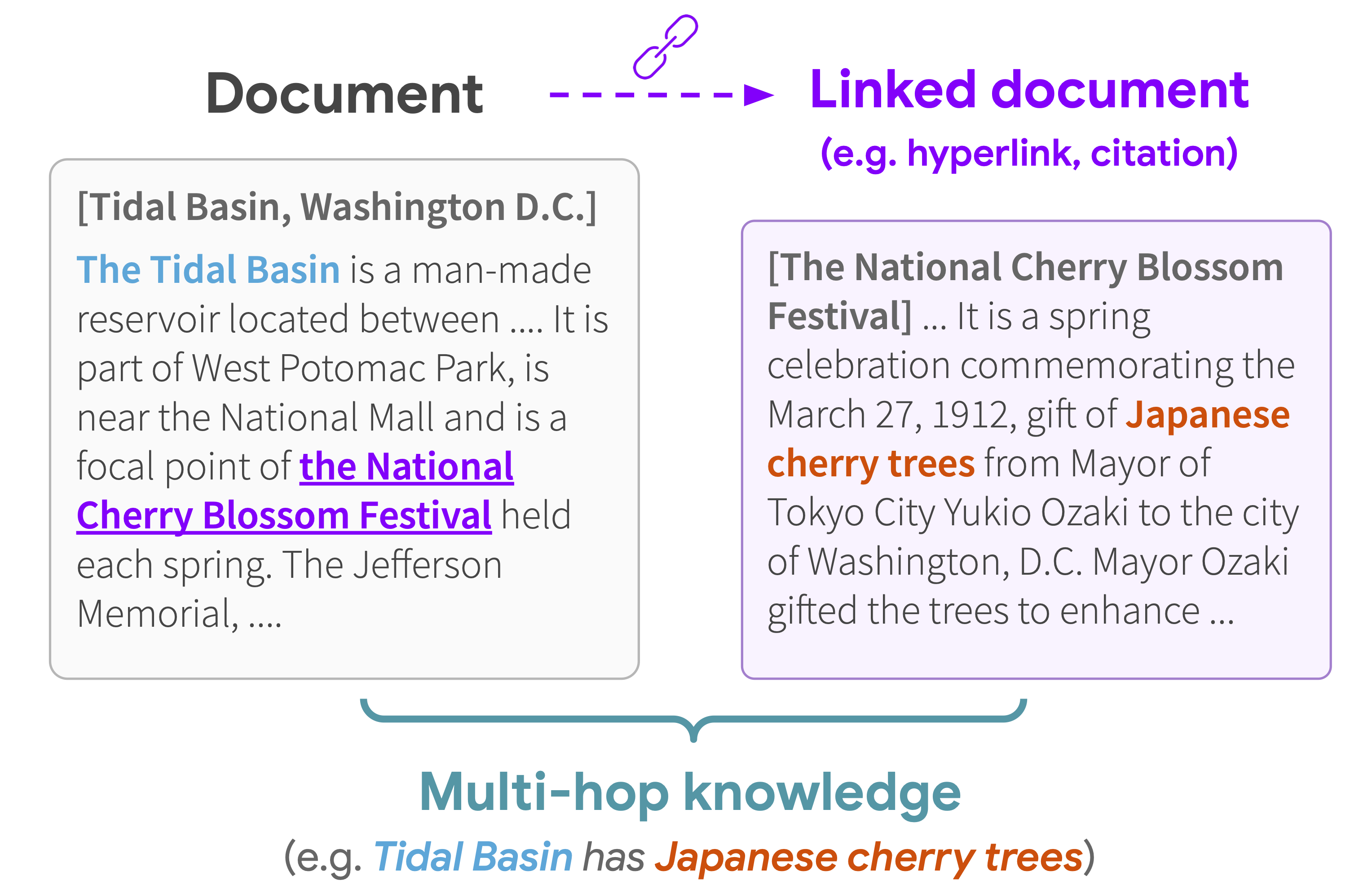
Models that train without these dependencies may fail to capture knowledge or facts that are spread across multiple documents. Learning such multi-hop knowledge in pretraining can be important for various applications including question answering and knowledge discovery (e.g. “What trees can you see at the Tidal Basin?”). Indeed, document links like hyperlinks and citations are ubiquitous and we humans also use them all the time to learn new knowledge and make discoveries. A text corpus is thus not simply a list of documents but a graph of documents with links connecting each other.
In our recent work 9 published at ACL 2022, we develop a new pretraining method, LinkBERT, that incorporates such document link information to train language models with more world knowledge.
Approach: LinkBERT
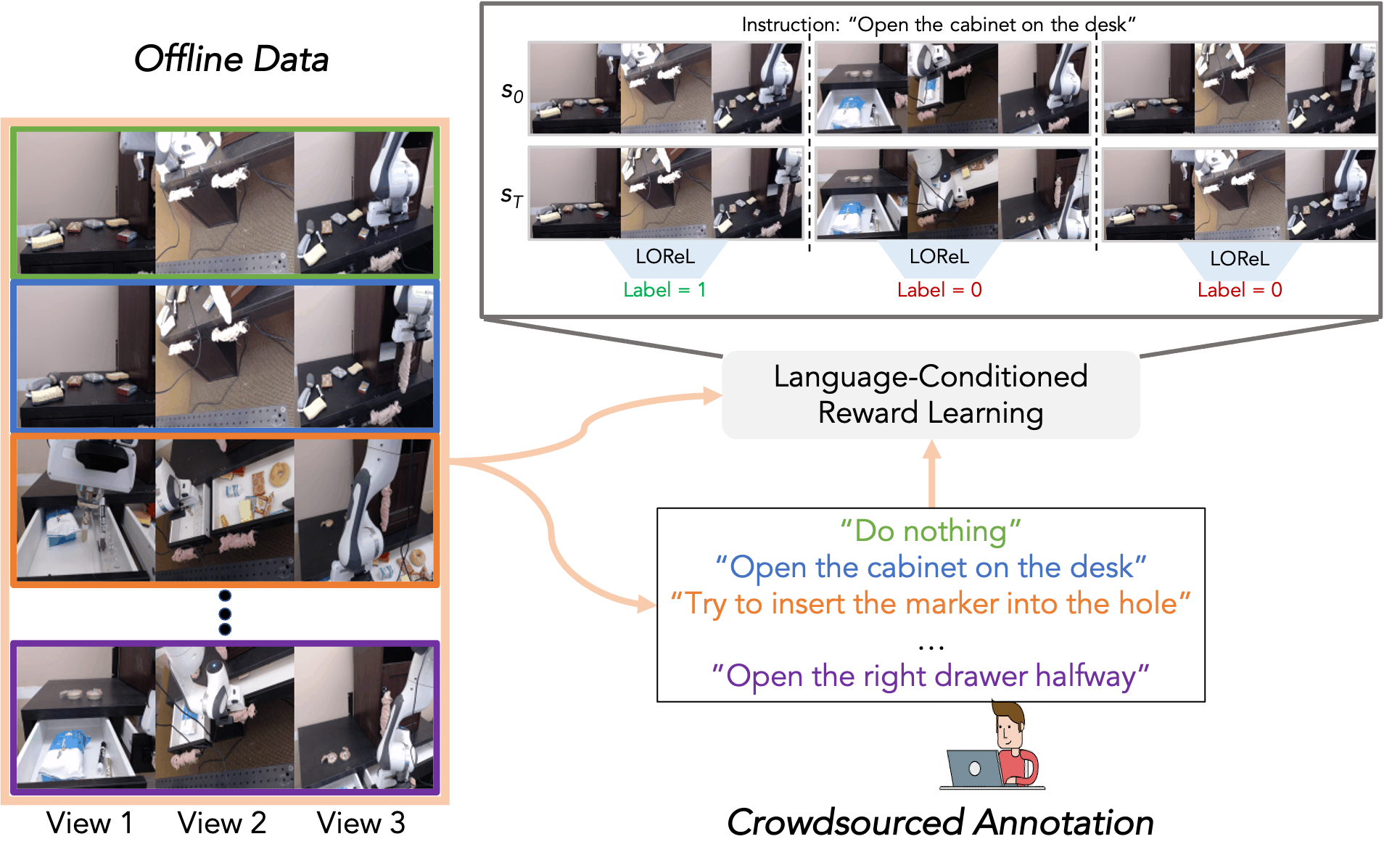
At a high level, LinkBERT consists of three steps: (0) obtaining links between documents to build a document graph from the text corpus, (1) creating link-aware training instances from the graph by placing linked documents together, and finally (2) pretraining the LM with link-aware self-supervised tasks: masked language modeling (MLM) and document relation prediction (DRP).

Document Graph Construction.
Given a text corpus, we link related documents to make a graph so that the links can bring together useful knowledge. Although this graph can be derived in any way, we will focus on using hyperlinks and citation links as they generally have high quality of relevance (i.e. low false-positive rate) and are available ubiquitously at scale. 10 To make the document graph, we treat each document as a node, and add a directed edge (i, j) if there is a hyperlink from document i to document j.
Link-aware LM Input Creation.
Given the document graph, we then create link-aware inputs that will be fed into our LM. As LMs can learn token dependency effectively if the tokens are shown in the same input instance 11, we want to place linked documents together in the input instance. In this way, the LM can learn multi-hop or multi-document dependencies of concepts as the LM will see training instances where these concepts appear together in the same sequence. To achieve this, we first chunk each document into segments of roughly 256 tokens, which is half of the maximum BERT LM input length. Then, we concatenate two segments (Segment A and B) together as an input sequence for the LM according to the links in the document graph. We have three options for how to choose segments to concatenate together:
- Option 1: contiguous segments. Take two contiguous segments from the same document. This is essentially the same as previous LMs.
- Option 2: random segments. Sample one segment from a random document and sample a second segment from another random document.
-
Option 3: linked segments. Sample one segment from a random document and sample a second segment randomly from a document linked to the first document in the document graph.
The reason we have these three options is to create a training signal for LinkBERT such that the model will learn to recognize relations between text segments. We will explain this in the next paragraph.

Link-aware LM Pretraining.
After creating input instances made up of pairs of segments, the last step is to use these created inputs to train the LM with link-aware self-supervised tasks. We consider the following two tasks:
- Masked language modeling (MLM), which masks some tokens in the input text and then predicts the tokens using the surrounding tokens. This encourages the LM to learn multi-hop knowledge of concepts brought into the same context by document links. For instance, in our running example about Tidal Basin, the LM would be able to learn the multi-hop relations from “Tidal Basin” to “National Cherry Blossom Festival” to “Japanese cherry trees”, as these three concepts will be all presented together in the same training instances.
- Document relation prediction (DRP), which makes the model classify the relation of Segment B to Segment A as to whether the two segments are contiguous, random or linked. This task encourages the LM to learn relevance and dependencies between documents, and also learn bridging concepts such as “National Cherry Blossom Festival” in our running example.
We pretrain the LM with these two objectives jointly.

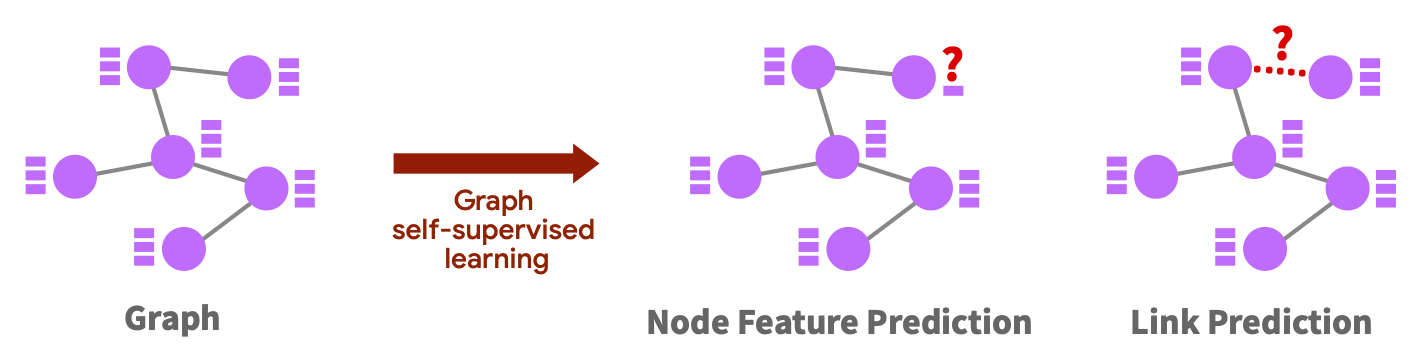
We can also motivate these two pretraining tasks as performing self-supervised learning algorithms on the document graph:
- Node feature prediction 12, which is to predict masked features of a node using neighbor nodes. This corresponds to MLM, where we predict masked tokens in Segment A using Segment B and vice versa.
- Link prediction 13, which is to predict the existence or type of an edge between two nodes. This corresponds to DRP, where we predict if two segments are linked (edge), contiguous (self-loop), or random (no edge).
Let’s use LinkBERT!
We will now see how LinkBERT performs on several downstream natural language processing tasks. We pretrained LinkBERT in two domains:
- General domain: we use Wikipedia as the pretraining corpus, which is the same as previous language models like BERT, except that here we also use the hyperlinks between Wikipedia articles.
- Biomedical domain: we use PubMed as the pretraining corpus, which is the same as previous biomedical language models like PubmedBERT 14, except that here we also use the citation links between PubMed articles.
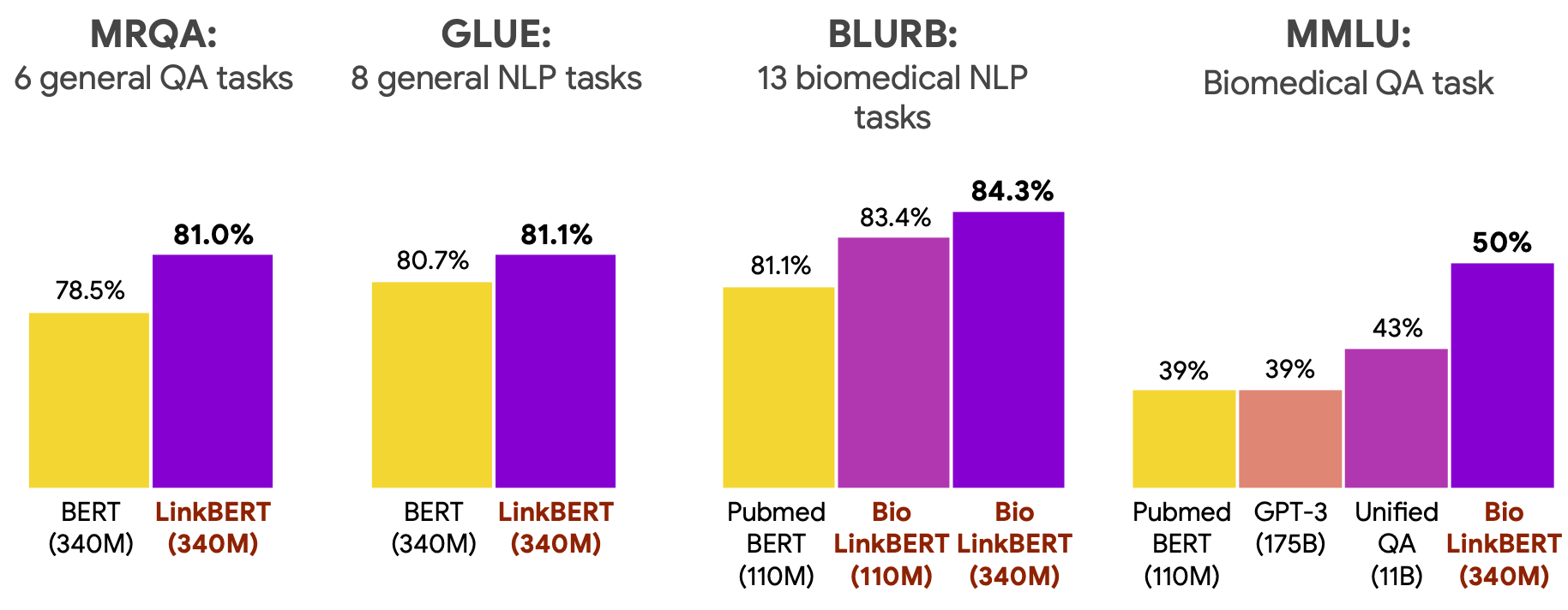
LinkBERT improves previous BERT models on many applications.
We evaluated the pretrained LinkBERT models on diverse downstream tasks in each domain:
- General question answering (MRQA) and general NLP (GLUE) benchmarks
- Biomedical NLP (BLURB) and biomedical question answering (MedQA, MMLU) benchmarks.
LinkBERT improves the baseline language models pretrained without document links (i.e. BERT and PubmedBERT) consistently across tasks and domains. The gain for the biomedical domain is especially large, likely because scientific literature has crucial dependencies with each other via citation links, which are captured by LinkBERT. The biomedical LinkBERT, which we call BioLinkBERT, achieves new state-of-the-art performance on the BLURB, MedQA and MMLU benchmarks.
Effective for multi-hop reasoning.
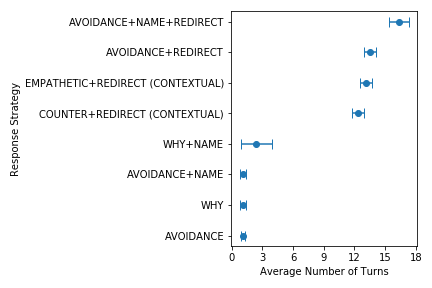
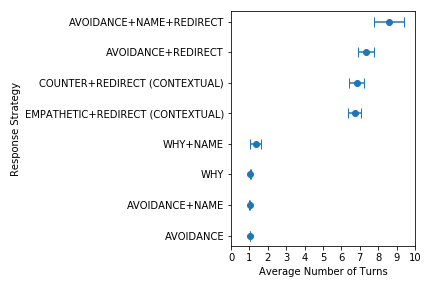
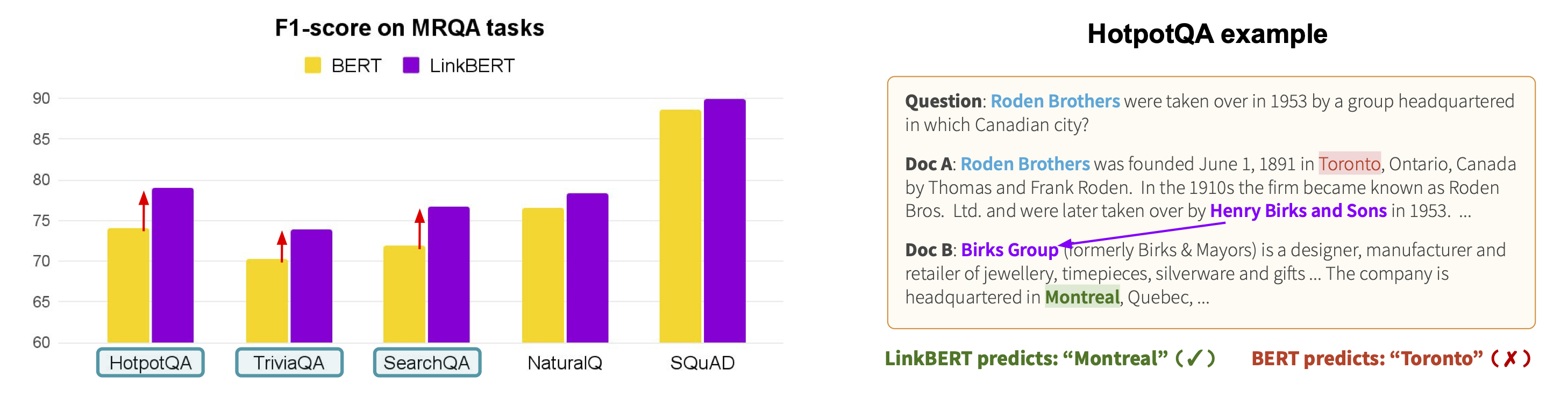
LinkBERT exhibits several interesting strengths. The first strength is multi-hop reasoning. Within the MRQA benchmarks, there are several tasks that involve multi-hop reasoning such as HotpotQA and triviaQA, and we find that LinkBERT provides large improvements for BERT on those tasks. As an example, the figure below shows an example from HotpotQA. Answering the given question needs 2-hop reasoning because we need to know what organization took over Roden Brothers in 1953 (the first document), and then we need to know where that organization was headquartered (the second document). BERT tends to simply predict a location name that appears in the same document as the one about Roden Brothers (“Toronto”), but LinkBERT is able to correctly connect information across the two documents to predict the answer (“Montreal”). The intuition is that because LinkBERT brings together multiple related concepts/documents into the same input instances during pretraining, it helps the model to reason with multiple concepts/documents in downstream tasks.
Effective for document relation understanding.
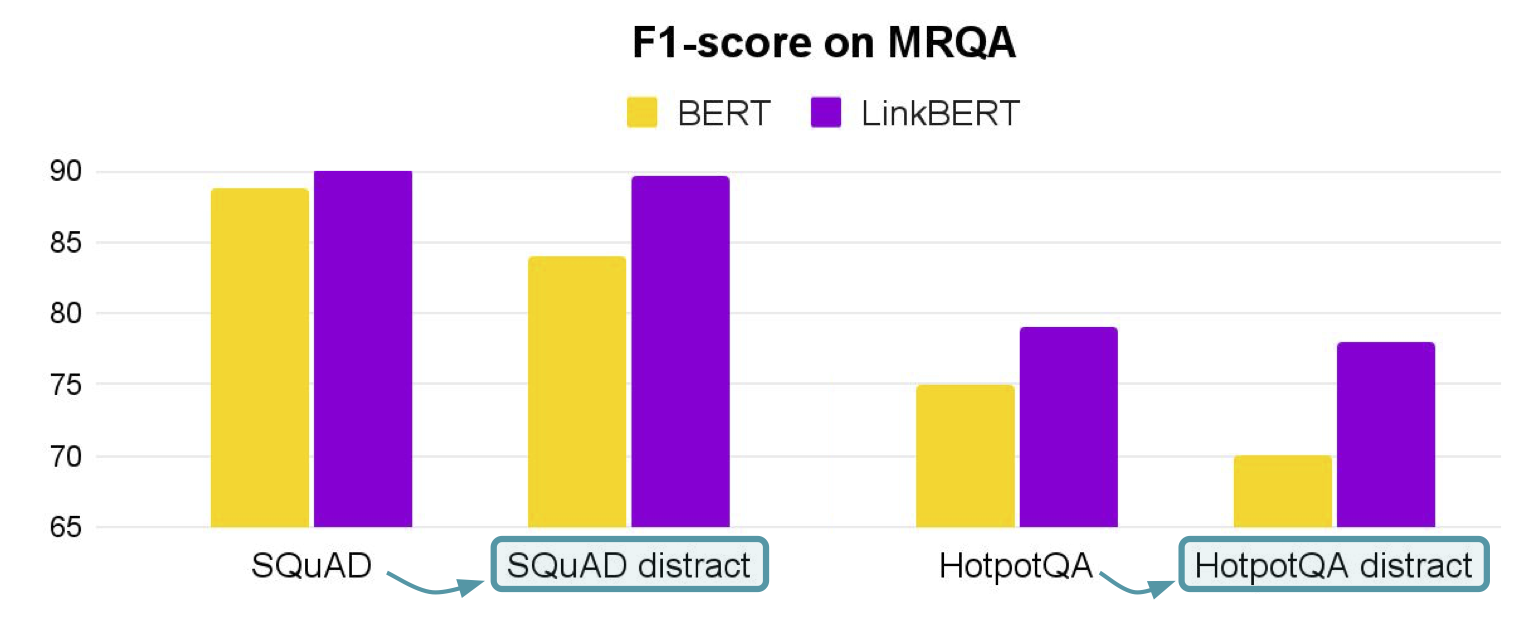
Another strength of LinkBERT is that it can better model the relationships between multiple documents. For instance, in open-domain QA, a model must identify an answer from multiple retrieved documents, where many of the documents are likely noisy or otherwise unrelated to the question. 15 To simulate this, we added distracting documents to the original MRQA tasks such as SQuAD and HotpotQA. We find that LinkBERT is robust to irrelevant documents and maintains the QA accuracy, while BERT incurs a performance drop in this setup. Our intuition is that the Document Relation Prediction task used in pretraining helps recognizing document relevance in downstream tasks.
Effective for few-shot and data-efficient QA.
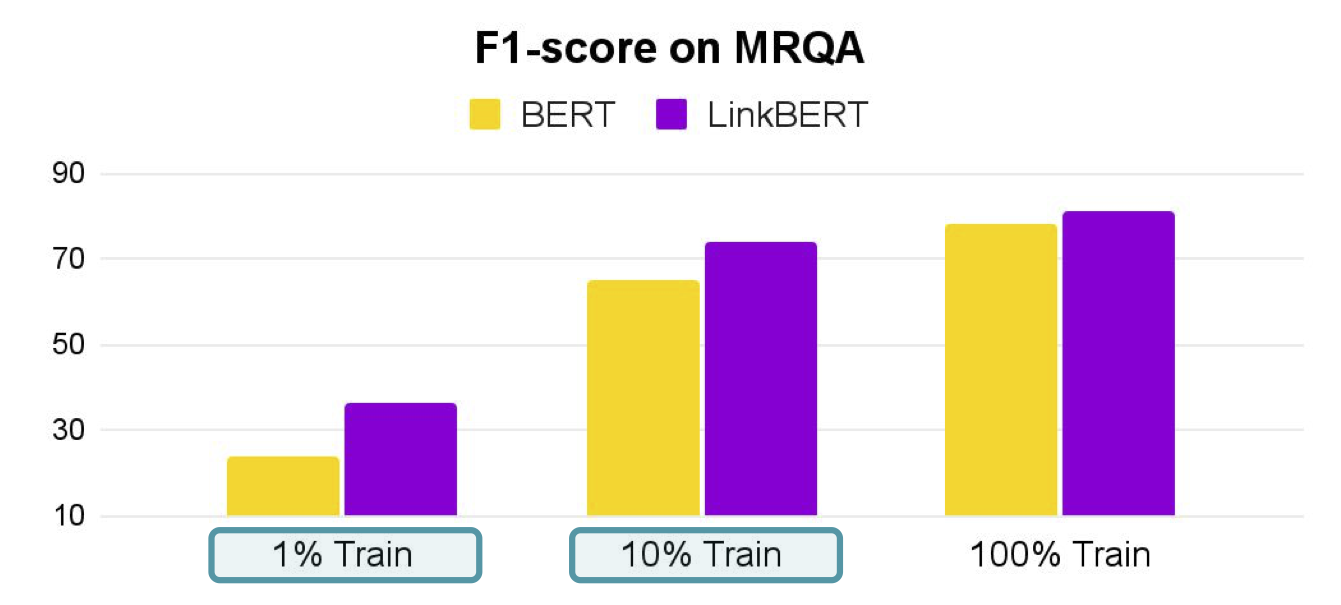
The third strength is few-shot and data-efficient QA. For each QA dataset, we tried finetuning LinkBERT or BERT with only 10% or 1% of the available training data. We find that LinkBERT provides large improvements for BERT on these low-resource paradigms. This finding suggests that LinkBERT has internalized more knowledge than BERT during pretraining, and supports the original intuition that document links can bring in new, useful knowledge for LMs.
Use LinkBERT for your own applications
LinkBERT can be used easily as a drop-in replacement for BERT. The pretrained LinkBERT models (LinkBERT and BioLinkBERT) are available on HuggingFace, and you can load them by
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/LinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/LinkBERT-large')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('michiyasunaga/BioLinkBERT-large')
model = AutoModel.from_pretrained('michiyasunaga/BioLinkBERT-large')
inputs = tokenizer("Sunitinib is a tyrosine kinase inhibitor", return_tensors="pt")
outputs = model(**inputs)
To use LinkBERT for downstream applications such as question answering and text classification, you can use the finetuning scripts provided at https://github.com/michiyasunaga/LinkBERT, or simply replace the BERT model path with LinkBERT in your favorite BERT finetuning scripts.
Summary
We introduced LinkBERT, a new pretraining method that leverages document links such as hyperlinks and citations to train a knowledgeable language model (LM). Specifically, we place linked documents in the same LM input sequence, and train the LM with two joint self-supervised tasks: masked language modeling and document relation prediction.
LinkBERT can be used as a drop-in replacement for BERT. In addition to improving performance for general language understanding tasks (e.g. text classification), LinkBERT better captures document or concept relations, and is effective for multi-hop reasoning and cross-document understanding. LinkBERT also internalizes more world knowledge and is effective for knowledge-intensive tasks, such as few-shot question answering.
We release the pretrained LinkBERT models. We hope they can be helpful for your projects and research, especially knowledge or reasoning-intensive applications. Finally, we think that LinkBERT opens up many exciting future projects, such as generalizing to GPT or sequence-to-sequence 16 style language models to perform document link-aware text generation, and generalizing the notion of document links to other modalities, e.g., incorporating source code dependency links in the training of language models for code 17.
This blog post is based on the paper:
- LinkBERT: Pretraining Language Models with Document Links. Michihiro Yasunaga, Jure Leskovec and Percy Liang. ACL 2022. The models, code, data are available on GitHub and HuggingFace.
If you have questions, please feel free to email us.
- Michihiro Yasunaga: myasu@cs.stanford.edu
Acknowledgments
Many thanks to the members of the Stanford P-Lambda group, SNAP group and NLP group for their valuable feedback. Many thanks to Jacob Schreiber and Michael Zhang for edits on this blog post.
-
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova. 2019. ↩
-
Language Models are Few-Shot Learners. Tom B. Brown, et al. 2020. ↩
-
On the Opportunities and Risks of Foundation Models. Rishi Bommasani et al. 2021. ↩
-
Google uses BERT for its search engine: https://blog.google/products/search/search-language-understanding-bert/ ↩
-
Language Model is All You Need: Natural Language Understanding as Question Answering. Mahdi Namazifar et al. Alexa AI. 2020. ↩
-
Language Models as Knowledge Bases? Fabio Petroni, et al. 2019. COMET: Commonsense Transformers for Automatic Knowledge Graph Construction. Antoine Bosselut et al. 2019. ↩
-
For example, text corpora like Wikipedia and WebText are used for training BERT and GPTs. ↩
-
For example, text corpora like PubMed and Semantic Scholar are used for training language models in scientific domains, such as BioBERT and SciBERT. ↩
-
LinkBERT: Pretraining Language Models with Document Links. Michihiro Yasunaga, Jure Leskovec and Percy Liang. 2022. ↩
-
Hyperlinks have been found useful in various NLP research, e.g., Learning to Retrieve Reasoning Paths over Wikipedia Graph for Question Answering. Akari Asai, Kazuma Hashimoto, Hannaneh Hajishirzi, Richard Socher, Caiming Xiong. 2019. HTLM: Hyper-Text Pre-Training and Prompting of Language Models. Armen Aghajanyan, Dmytro Okhonko, Mike Lewis, Mandar Joshi, Hu Xu, Gargi Ghosh, Luke Zettlemoyer. 2022. ↩
-
The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design. Yoav Levine, Noam Wies, Daniel Jannai, Dan Navon, Yedid Hoshen, Amnon Shashua. 2022. ↩
-
Strategies for Pre-training Graph Neural Networks. Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, Jure Leskovec. 2020. ↩
-
Translating Embeddings for Modeling Multi-relational Data. Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, Oksana Yakhnenko. 2013. ↩
-
Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing. Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, Hoifung Poon. 2021. ↩
-
Reading Wikipedia to Answer Open-Domain Questions. Danqi Chen, Adam Fisch, Jason Weston, Antoine Bordes. 2017. ↩
-
Training language models for source code data is an active area of research, e.g., CodeX, AlphaCode. ↩