AlphaStar is the first AI to reach the top league of a widely popular esport without any game restrictions.Read More
Improving Cross-Lingual Transfer Learning by Filtering Training Data
In a paper we’re presenting at this year’s Conference on Empirical Methods in Natural Language Processing, we describe experiments with a new data selection technique.Read More
Get to Know Uber ATG at ICCV, CoRL, and IROS 2019
Uber ATG is committed to publishing research advancements with the goal of bringing self-driving cars to the world safely and scalably. We hope our approach to sharing will deepen the interactions and collaborations between industry and academia, and will ultimately …
The post Get to Know Uber ATG at ICCV, CoRL, and IROS 2019 appeared first on Uber Engineering Blog.
The FEVER data set: What doesn’t kill it will make it stronger
This year at EMNLP, we will cohost the Second Workshop on Fact Extraction and Verification — or FEVER — which will explore techniques for automatically assessing the veracity of factual assertions online.Read More
Evolving Michelangelo Model Representation for Flexibility at Scale
Michelangelo, Uber’s machine learning (ML) platform, supports the training and serving of thousands of models in production across the company. Designed to cover the end-to-end ML workflow, the system currently supports classical machine learning, time series forecasting, and deep …
The post Evolving Michelangelo Model Representation for Flexibility at Scale appeared first on Uber Engineering Blog.
Tools for generating synthetic data helped bootstrap Alexa’s new-language releases
In the past few weeks, Amazon announced versions of Alexa in three new languages: Hindi, U.S. Spanish, and Brazilian Portuguese. Like all new-language launches, these addressed the problem of how to bootstrap the machine learning models that interpret customer requests, without the ability to learn from customer interactions.Read More

PyTorch 1.3 adds mobile, privacy, quantization, and named tensors
PyTorch continues to gain momentum because of its focus on meeting the needs of researchers, its streamlined workflow for production use, and most of all because of the enthusiastic support it has received from the AI community. PyTorch citations in papers on ArXiv grew 194 percent in the first half of 2019 alone, as noted by O’Reilly, and the number of contributors to the platform has grown more than 50 percent over the last year, to nearly 1,200. Facebook, Microsoft, Uber, and other organizations across industries are increasingly using it as the foundation for their most important machine learning (ML) research and production workloads.
We are now advancing the platform further with the release of PyTorch 1.3, which includes experimental support for features such as seamless model deployment to mobile devices, model quantization for better performance at inference time, and front-end improvements, like the ability to name tensors and create clearer code with less need for inline comments. We’re also launching a number of additional tools and libraries to support model interpretability and bringing multimodal research to production.
Additionally, we’ve collaborated with Google and Salesforce to add broad support for Cloud Tensor Processing Units, providing a significantly accelerated option for training large-scale deep neural networks. Alibaba Cloud also joins Amazon Web Services, Microsoft Azure, and Google Cloud as supported cloud platforms for PyTorch users. You can get started now at pytorch.org.
PyTorch 1.3
The 1.3 release of PyTorch brings significant new features, including experimental support for mobile device deployment, eager mode quantization at 8-bit integer, and the ability to name tensors. With each of these enhancements, we look forward to additional contributions and improvements from the PyTorch community.
Named tensors (experimental)
Cornell University’s Sasha Rush has argued that, despite its ubiquity in deep learning, the traditional implementation of tensors has significant shortcomings, such as exposing private dimensions, broadcasting based on absolute position, and keeping type information in documentation. He proposed named tensors as an alternative approach.
Today, we name and access dimensions by comment:
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)
But naming explicitly leads to more readable and maintainable code:
NCHW = [‘N’, ‘C’, ‘H’, ‘W’]
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C')
images.select('C', index=0)
Quantization (experimental)
It’s important to make efficient use of both server-side and on-device compute resources when developing ML applications. To support more efficient deployment on servers and edge devices, PyTorch 1.3 now supports 8-bit model quantization using the familiar eager mode Python API. Quantization refers to techniques used to perform computation and storage at reduced precision, such as 8-bit integer. This currently experimental feature includes support for post-training quantization, dynamic quantization, and quantization-aware training. It leverages the FBGEMM and QNNPACK state-of-the-art quantized kernel back ends, for x86 and ARM CPUs, respectively, which are integrated with PyTorch and now share a common API.
To learn more about the design and architecture, check out the API docs here, and get started with any of the supported techniques using the tutorials available here.
PyTorch mobile (experimental)
Running ML on edge devices is growing in importance as applications continue to demand lower latency. It is also a foundational element for privacy-preserving techniques such as federated learning. To enable more efficient on-device ML, PyTorch 1.3 now supports an end-to-end workflow from Python to deployment on iOS and Android.
This is an early, experimental release, optimized for end-to-end development. Coming releases will focus on:
- Optimization for size: Build level optimization and selective compilation depending on the operators needed for user applications (i.e., you pay binary size for only the operators you need)
- Performance: Further improvements to performance and coverage on mobile CPUs and GPUs
- High level API: Extend mobile native APIs to cover common preprocessing and integration tasks needed for incorporating ML in mobile applications. e.g. Computer vision and NLP
Learn more or get started on Android or iOS here.
New tools for model interpretability and privacy
Captum
As models become ever more complex, it is increasingly important to develop new methods for model interpretability. To help address this need, we’re launching Captum, a tool to help developers working in PyTorch understand why their model generates a specific output. Captum provides state-of-the-art tools to understand how the importance of specific neurons and layers and affect predictions made by the models. Captum’s algorithms include integrated gradients, conductance, SmoothGrad and VarGrad, and DeepLift.
The example below shows how to apply model interpretability algorithms on a pretrained ResNet model and then visualize the attributions for each pixel by overlaying them on the image.
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt, delta = noise_tunnel.attribute(input, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(["original_image", "heat_map"],
["all", "positive"],
np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)),
cmap=default_cmap,
show_colorbar=True)

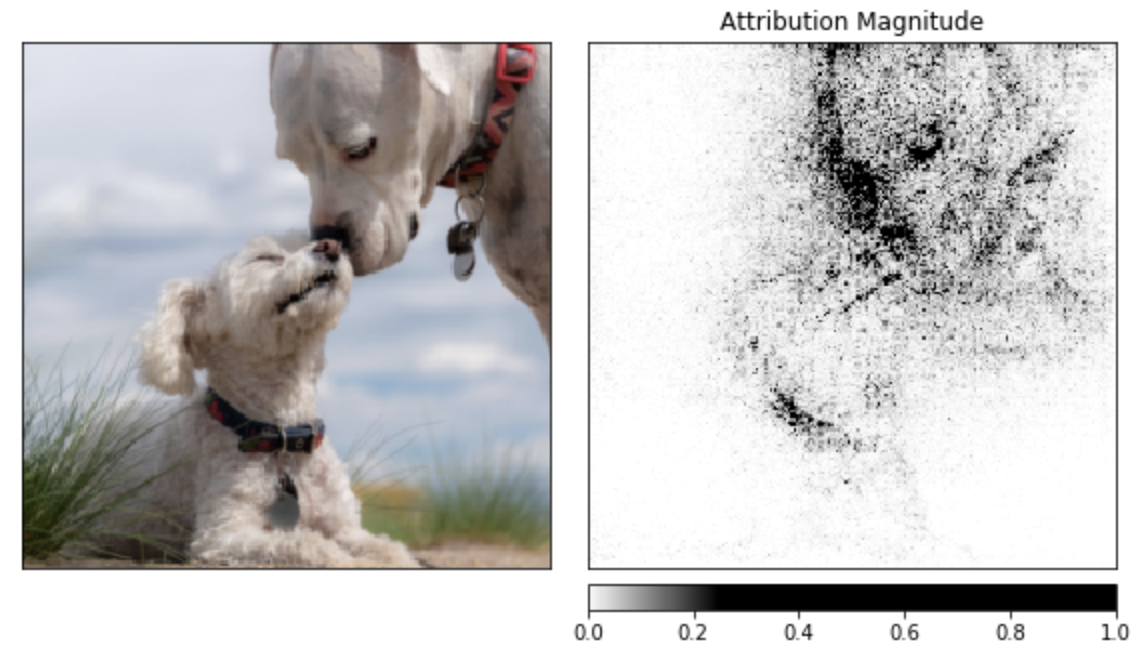
Learn more about Captum at captum.ai.
CrypTen
Practical applications of ML via cloud-based or machine-learning-as-a-service (MLaaS) platforms pose a range of security and privacy challenges. In particular, users of these platforms may not want or be able to share unencrypted data, which prevents them from taking full advantage of ML tools. To address these challenges, the ML community is exploring a number of technical approaches, at various levels of maturity. These include homomorphic encryption, secure multiparty computation, trusted execution environments, on-device computation, and differential privacy.
To provide a better understanding of how some of these technologies can be applied, we are releasing CrypTen, a new community-based research platform for taking the field of privacy-preserving ML forward. Learn more about CrypTen here. It is available on GitHub here.
Tools for multimodal AI systems
Digital content is often made up of several modalities, such as text, images, audio, and video. For example, a single public post might contain an image, body text, a title, a video, and a landing page. Even one particular component may have more than one modality, such as a video that contains both visual and audio signals, or a landing page that is composed of images, text, and HTML sources.
The ecosystem of tools and libraries that work with PyTorch offer enhanced ways to address the challenges of building multimodal ML systems. Here are some of the latest libraries launching today:
Detectron2
Object detection and segmentation are used for tasks ranging from autonomous vehicles to content understanding for platform integrity. To advance this work, Facebook AI Research (FAIR) is releasing Detectron2, an object detection library now implemented in PyTorch. Detectron2 provides support for the latest models and tasks, increased flexibility to aid computer vision research, and improvements in maintainability and scalability to support production use cases.
Detectron2 is available here and you can learn more here.
Speech extensions to fairseq
Language translation and audio processing are critical components in systems and applications such as search, translation, speech, and assistants. There has been tremendous progress in these fields recently thanks to the development of new architectures like transformers, as well as large-scale pretraining methods. We’ve extended fairseq, a framework for sequence-to-sequence applications such as language translation, to include support for end-to-end learning for speech and audio recognition tasks.These extensions to fairseq enable faster exploration and prototyping of new speech research ideas while offering a clear path to production.
Get started with fairseq here.
Cloud provider and hardware ecosystem support
Cloud providers such as Amazon Web Services, Microsoft Azure, and Google Cloud provide extensive support for anyone looking to develop ML on PyTorch and deploy in production. We’re excited to share the general availability of Google Cloud TPU support and a newly launched integration with Alibaba Cloud. We’re also expanding hardware ecosystem support.
- Google Cloud TPU support now broadly available. To accelerate the largest-scale machine learning (ML) applications deployed today and enable rapid development of the ML applications of tomorrow, Google created custom silicon chips called Tensor Processing Units (TPUs). When assembled into multi-rack ML supercomputers called Cloud TPU Pods, these TPUs can complete ML workloads in minutes or hours that previously took days or weeks on other systems. Engineers from Facebook, Google, and Salesforce worked together to enable and pilot Cloud TPU support in PyTorch, including experimental support for Cloud TPU Pods. PyTorch support for Cloud TPUs is also available in Colab. Learn more about how to get started with PyTorch on Cloud TPUs here.
- Alibaba adds support for PyTorch in Alibaba Cloud. The initial integration involves a one-click solution for PyTorch 1.x, Data Science Workshop notebook service, distributed training with Gloo/NCCL, as well as seamless integration with Alibaba IaaS such as OSS, ODPS, and NAS. Together with the toolchain provided by Alibaba, we look forward to significantly reducing the overhead necessary for adoption, as well as helping Alibaba Cloud’s global customer base leverage PyTorch to develop new AI applications.
- ML hardware ecosystem expands. In addition to key GPU and CPU partners, the PyTorch ecosystem has also enabled support for dedicated ML accelerators. Updates from Intel and Habana showcase how PyTorch, connected to the Glow optimizing compiler, enables developers to utilize these market-specific solutions.
Growth in the PyTorch community
As an open source, community-driven project, PyTorch benefits from wide range of contributors bringing new capabilities to the ecosystem. Here are some recent examples:
- Mila SpeechBrain aims to provide an open source, all-in-one speech toolkit based on PyTorch. The goal is to develop a single, flexible, user-friendly toolkit that can be used to easily develop state-of-the-art systems for speech recognition (both end to end and HMM-DNN), speaker recognition, speech separation, multi-microphone signal processing (e.g., beamforming), self-supervised learning, and many others. Learn more
- SpaCy is a new wrapping library with consistent and easy-to-use interfaces to several models, in order to extract features to power NLP pipelines. Support is provided for via spaCy’s standard training API. The library also calculates an alignment so the transformer features can be related back to actual words instead of just wordpieces. Learn more
- HuggingFace PyTorch-Transformers (formerly known as pytorch-pretrained-bert is a library of state-of-the-art pretrained models for Natural Language Processing (NLP). The library currently contains PyTorch implementations, pretrained model weights, usage scripts, and conversion utilities for models such as BERT, GPT-2, RoBERTa, and DistilBERT. It has also grown quickly, with more than 13,000 GitHub stars and a broad set of users. Learn more
- PyTorch Lightning is a Keras-like ML library for PyTorch. It leaves core training and validation logic to you and automates the rest. Reproducibility is a crucial requirement for many fields of research, including those based on ML techniques. As the number of research papers submitted to arXiv and conferences skyrockets into the tens of thousands, scaling reproducibility becomes difficult. Learn more.
We recently held the first online Global PyTorch Summer Hackathon, where researchers and developers around the world were invited to build innovative new projects with PyTorch. Nearly 1,500 developers participated, submitting projects ranging from livestock disease detection to AI-powered financial assistants. The winning projects were:
- Torchmeta, which provides extensions for PyTorch to simplify the development of meta-learning algorithms in PyTorch. It features a unified interface inspired by TorchVision for both few-shot classification and regression problems, to allow easy benchmarking on multiple data sets to aid with reproducibility.
- Open-Unmix, a system for end-to-end music demixing with PyTorch. Demixing separates the individual instruments or vocal track from any stereo recording.
- Endless AI-Generated Tees, a store featuring AI-generated T-shirt designs that can be purchased and delivered worldwide. The system uses a state-of-the-art generative model (StyleGAN) that was built with PyTorch and then trained on modern art.
Visit pytorch.org to learn more and get started with PyTorch 1.3 and the latest libraries and ecosystem projects. We look forward to the contributions, exciting research advancements, and real-world applications that the community builds with PyTorch.
We’d like to thank the entire PyTorch team and the community for all their contributions to this work.
Searchable Ground Truth: Querying Uncommon Scenarios in Self-Driving Car Development
At Uber ATG, developing a safe self-driving car system not only means training it on the typical traffic scenarios we see every day, but also the edge cases, those more difficult and rare situations that would even flummox a human …
The post Searchable Ground Truth: Querying Uncommon Scenarios in Self-Driving Car Development appeared first on Uber Engineering Blog.
Causal Bayesian Networks: A flexible tool to enable fairer machine learning
Decisions based on machine learning (ML) are potentially advantageous over human decisions, but the data used to train them often contains human and societal biases that can lead to harmful decisions.Read More
Amazon Releases New Public Data Set to Help Address “Cocktail Party” Problem
Amazon today announced the public release of a new data set that will help speech scientists address the difficult problem of separating speech signals in reverberant rooms with multiple speakers. In the field of automatic speech recognition, this problem is known as the “cocktail party” or “dinner party” problem; accordingly, we call our data set the Dinner Party Corpus, or DiPCo.Read More