Connecting the digital and physical worlds safely and reliably on the Uber platform presents exciting technological challenges and opportunities. For Uber, artificial intelligence (AI) is essential to developing systems that are capable of optimized, automated decision making at scale.
At re:MARS 2019, Brad Porter, Amazon’s vice president of robotics, talked about how a symphony of humans and robots work together to deliver customer orders.Read More
Amazon’s director of forecasting, Jenny Freshwater, speaks about how AI is used to power forecasting decisions, so that items are always in stock for Amazon’s customers.Read More
In the last decade, we’ve seen learning-based systems provide transformative solutions for a wide range of perception and reasoning problems, from recognizing objects in images to recognizing and translating human speech. Recent progress in deep reinforcement learning (i.e. integrating deep neural networks into reinforcement learning systems) suggests that the same kind of success could be realized in automated decision making domains. If fruitful, this line of work could allow learning-based systems to tackle active control tasks, such as robotics and autonomous driving, alongside the passive perception tasks to which they have already been successfully applied.
While deep reinforcement learning methods – like Soft Actor Critic – can learn impressive motor skills, they are challenging to train on large and broad data that is not from the target environment. In contrast, the success of deep networks in fields like computer vision was arguably predicated just as much on large datasets, such as ImageNet, as it was on large neural network architectures. This suggests that applying data-driven methods to robotics will require not just the development of strong reinforcement learning methods, but also access to large and diverse datasets for robotics. Not only can large datasets enable models that generalize effectively, but they can also be used to pre-train models that can then be adapted to more specialized tasks using much more modest datasets. Indeed, “ImageNet pre-training” has become a default approach for tackling diverse tasks with small or medium datasets – like 3D building reconstruction. Can the same kind of approach be adopted to enable broad generalization and transfer in active control domains, such as robotics?
Unfortunately, the design and adoption of large datasets in reinforcement learning and robotics has proven challenging. Since every robotics lab has their own hardware and experimental set-up, it is not apparent how to move towards an “ImageNet-scale” dataset for robotics that is useful for the entire research community. Hence, we propose to collect data across multiple different settings, including from varying camera viewpoints, varying environments, and even varying robot platforms. Motivated by the success of large-scale data-driven learning, we created RoboNet, an extensible and diverse dataset of robot interaction collected across fourdifferentresearchlabs. The collaborative nature of this work allows us to easily capture diverse data in various lab settings across a wide variety of objects, robotic hardware, and camera viewpoints. Finally, we find that pre-training on RoboNet offers substantial performance gains compared to training from scratch in entirely new environments.
Our goal is to pre-train reinforcement learning models on a sufficiently diverse dataset and then transfer knowledge (either zero-shot or with fine-tuning) to a different test environment.
Collecting RoboNet
RoboNet consists of 15 million video frames, collected by different robots interacting with different objects in a table-top setting. Every frame includes the image recorded by the robot’s camera, arm pose, force sensor readings, and gripper state. The collection environment, including the camera view, the appearance of the table or bin, and the objects in front of the robot are varied between trials. Since collection is entirely autonomous, large amounts can be cheaply collected across multiple institutions. A sample of RoboNet along with data statistics is shown below:
A sample of data from RoboNet alongside a summary of the current dataset. Note that any GIF compression artifacts in this animation are not present in the dataset itself.
How can we use RoboNet?
After collecting a diverse dataset, we experimentally investigate how it can be used to enable general skill learning that transfers to new environments. First, we pre-train visual dynamics models on a subset of data from RoboNet, and then fine-tune them to work in an unseen test environment using a small amount of new data. The constructed test environments (one of which is visualized below) all include different lab settings, new cameras and viewpoints, held-out robots, and novel objects purchased after data collection concluded.
Example test environment constructed in a new lab, with a temporary uncalibrated camera, and a new Baxter robot. Note that while Baxters are present in RoboNet that data is not included during model pre-training.
After tuning, we deploy the learned dynamics models in the test environment to perform control tasks – like picking and placing objects – using the visual foresight model based reinforcement learning algorithm. Below are example control tasks executed in various test environments.
Kuka can align shirts next to the others
Baxter can sweep the table with cloth
Franka can grasp and reposition the markers
Kuka can move the plate to the edge of the table
Baxter can pick up and reposition socks
Franka can stack the towel on the pile
Here you can see examples of visual foresight fine-tuned to perform basic control tasks in three entirely different environments. For the experiments, the target robot and environment was subtracted from RoboNet during pre-training. Fine-tuning was accomplished with data collected in one afternoon.
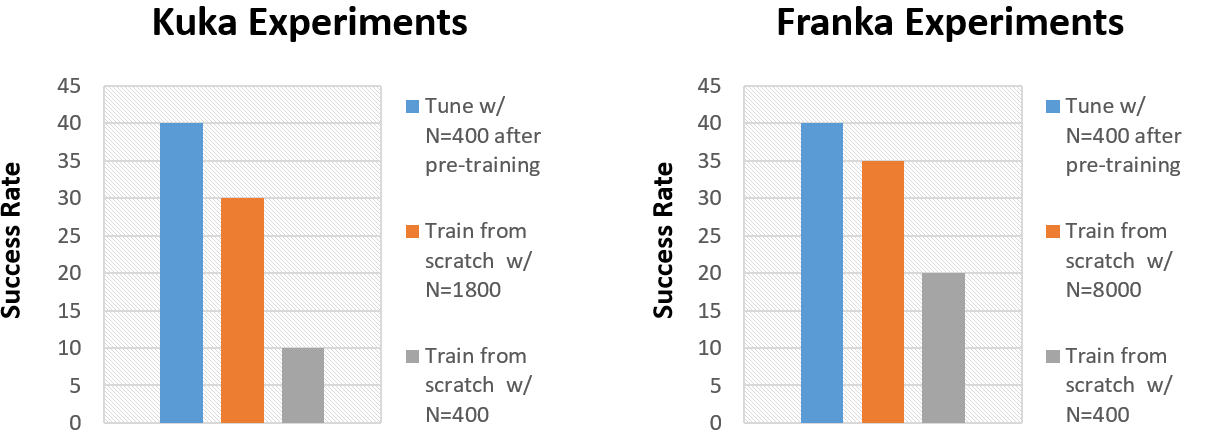
We can now numerically evaluate if our pre-trained controllers can pick up skills in new environments faster than a randomly initialized one. In each environment, we use a standard set of benchmark tasks to compare the performance of our pre-trained controller against the performance of a model trained only on data from the new environment. The results show that the fine-tuned model is ~4x more likely to complete the benchmark task than the one trained without RoboNet. Impressively, the pre-trained models can even slightly outperform models trained from scratch on significantly (5-20x) more data from the test environment. This suggests that transfer from RoboNet does indeed offer large performance gains compared to training from scratch!
We compare the performance of fine-tuned models against their counterparts trained from scratch in two different test environments (with different robot platforms).
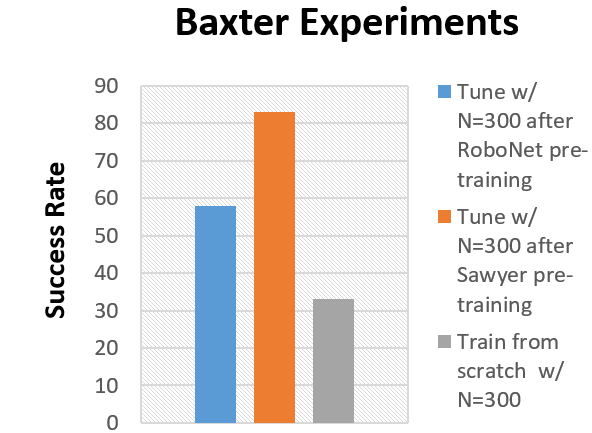
Clearly fine-tuning is better than training from scratch, but is training on all of RoboNet always the best way to go? To test this, we compare pre-training on various subsets of RoboNet versus training from scratch. As seen before, the model pre-trained on all of RoboNet (excluding the Baxter platform) performs substantially better than the random initialization model. However, the “RoboNet pre-trained” model is outperformed by a model trained on a subset of RoboNet data collected on the Sawyer robot – the single-arm variant of Baxter.
Models pre-trained on various subsets of RoboNet are compared to one trained from scratch in an unseen (during pre-training) Baxter control environment
The similarities between the Baxter and Sawyer likely partly explain our results, but why does simply adding data to the training set hurt performance after fine-tuning? We theorize that this effect occurs due to model under-fitting. In other words, RoboNet is an extremely challenging dataset for a visual dynamics model, and imperfections in the model predictions result in bad control performance. However, larger models with more parameters tend to be more powerful, and thus make better predictions on RoboNet (visualized below). Note that increasing the number of parameters greatly improves prediction quality, but even large models with 500M parameters (middle column in the videos below) are still quite blurry. This suggests ample room for improvement, and we hope that the development of newer more powerful models will translate to better control performance in the future.
We compare video prediction models of various size trained on RoboNet. A 75M parameter model (right-most column) generates significantly blurrier predictions than a large model with 500M parameters (center column).
Final Thoughts
This work takes the first step towards creating learned robotic agents that can operate in a wide range of environments and across different hardware. While our experiments primarily explore model-based reinforcement learning, we hope that RoboNet will inspire the broader robotics and reinforcement learning communities to investigate how to scale model-based or model-free RL algorithms to meet the complexity and diversity of the real world.
Since the dataset is extensible, we encourage other researchers to contribute the data generated from their experiments back into RoboNet. After all, any data containing robot telemetry and video could be useful to someone else, so long as it contains the right documentation. In the long term, we believe this process will iteratively strengthen the dataset, and thus allow our algorithms that use it to achieve greater levels of generalization across tasks, environments, robots, and experimental set-ups.
Finally, I would like to thank Sergey Levine, Chelsea Finn, and Frederik Ebert for their helpful feedback on this post, as well as the editors of the BAIR, SAIL, and CMU MLD blogs.
This blog post was based on the following paper:RoboNet: Large-Scale Multi-Robot Learning. S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, C. Finn. In Conference on Robot Learning, 2019. (pdf)
Michael I. Jordan, Amazon Scholar and professor at the University of California, Berkeley, writes about the classical goals in human-imitative AI, and reflects on how in the current hubbub over the AI revolution it is easy to forget that these goals haven’t yet been achieved.Read More
In 2017, when the journal IEEE Internet Computing was celebrating its 20th anniversary, its editorial board decided to identify the single paper from its publication history that had best withstood the “test of time”. The honor went to a 2003 paper called “Amazon.com Recommendations: Item-to-Item Collaborative Filtering”, by then Amazon researchers Greg Linden, Brent Smith, and Jeremy York.Read More
We’re releasing Safety Gym, a suite of environments and tools for measuring progress towards reinforcement learning agents that respect safety constraints while training.
We also provide a standardized method of comparing algorithms and how well they avoid costly mistakes while learning. If deep reinforcement learning is applied to the real world, whether in robotics or internet-based tasks, it will be important to have algorithms that are safe even while learning—like a self-driving car that can learn to avoid accidents without actually having to experience them.
Reinforcement learning agents need to explore their environments in order to learn optimal behaviors. Essentially, they operate on the principle of trial and error: they try things out, see what works or doesn’t work, and then increase the likelihood of good behaviors and decrease the likelihood of bad behaviors. However, exploration is fundamentallyrisky: agents might try dangerous behaviors that lead to unacceptable errors. This is the “safe exploration” problem in a nutshell.
Consider an example of an autonomous robot arm in a factory using reinforcement learning (RL) to learn how to assemble widgets. At the start of RL training, the robot might try flailing randomly, since it doesn’t know what to do yet. This poses a safety risk to humans who might be working nearby, since they could get hit.
For restricted examples like the robot arm, we can imagine simple ways to ensure that humans aren’t harmed by just keeping them out of harm’s way: shutting down the robot whenever a human gets too close, or putting a barrier around the robot. But for general RL systems that operate under a wider range of conditions, simple physical interventions won’t always be possible, and we will need to consider other approaches to safe exploration.
Constrained reinforcement learning
The first step towards making progress on a problem like safe exploration is to quantify it: figure out what can be measured, and how going up or down on those metrics gets us closer to the desired outcome. Another way to say it is that we need to pick a formalism for the safe exploration problem. A formalism allows us to design algorithms that achieve our goals.
While there are several options, there is not yet a universal consensus in the field of safe exploration research about the right formalism. We spent some time thinking about it, and the formalism we think makes the most sense to adopt is constrained reinforcement learning.
Constrained RL is like normal RL, but in addition to a reward function that the agent wants to maximize, environments have cost functions that the agent needs to constrain. For example, consider an agent controlling a self-driving car. We would want to reward this agent for getting from point A to point B as fast as possible. But naturally, we would also want to constrain the driving behavior to match traffic safety standards.
We think constrained RL may turn out to be more useful than normal RL for ensuring that agents satisfy safety requirements. A big problem with normal RL is that everything about the agent’s eventual behavior is described by the reward function, but reward design is fundamentally hard. A key part of the challenge comes from picking trade-offs between competing objectives, such as task performance and satisfying safety requirements. In constrained RL, we don’t have to pick trade-offs—instead, we pick outcomes, and let algorithms figure out the trade-offs that get us the outcomes we want.
We can use the self-driving car case to sketch what this means in practice. Suppose the car earns some amount of money for every trip it completes, and has to pay a fine for every collision.
In normal RL, you would pick the collision fine at the beginning of training and keep it fixed forever. The problem here is that if the pay-per-trip is high enough, the agent may not care whether it gets in lots of collisions (as long as it can still complete its trips). In fact, it may even be advantageous to drive recklessly and risk those collisions in order to get the pay. We have seen this before when training unconstrained RL agents.
By contrast, in constrained RL you would pick the acceptable collision rate at the beginning of training, and adjust the collision fine until the agent is meeting that requirement. If the car is getting in too many fender-benders, you raise the fine until that behavior is no longer incentivized.
Safety Gym
To study constrained RL for safe exploration, we developed a new set of environments and tools called Safety Gym. By comparison to existing environments for constrained RL, Safety Gym environments are richer and feature a wider range of difficulty and complexity.
In all Safety Gym environments, a robot has to navigate through a cluttered environment to achieve a task. There are three pre-made robots (Point, Car, and Doggo), three main tasks (Goal, Button, and Push), and two levels of difficulty for each task. We give an overview of the robot-task combinations below, but make sure to check out the paper for details.
In these videos, we show how an agent without constraints tries to solve these environments. Every time the robot does something unsafe—which here, means running into clutter—a red warning light flashes around the agent, and the agent incurs a cost (separate from the task reward). Because these agents are unconstrained, they often wind up behaving unsafely while trying to maximize reward.
Point is a simple robot constrained to the 2D plane, with one actuator for turning and another for moving forward or backward. Point has a front-facing small square which helps with the Push task.
Goal: Move to a series of goal positions.
Button: Press a series of goal buttons.
Push: Move a box to a series of goal positions.
Car has two independently-driven parallel wheels and a free-rolling rear wheel. For this robot, turning and moving forward or backward require coordinating both of the actuators.
Goal: Move to a series of goal positions.
Button: Press a series of goal buttons.
Push: Move a box to a series of goal positions.
Doggo is a quadruped with bilateral symmetry. Each of its four legs has two controls at the hip, for azimuth and elevation relative to the torso, and one in the knee, controlling angle. A uniform random policy keeps the robot from falling over and generates travel.
Our preliminary results demonstrate the wide range of difficulty of Safety Gym environments: the simplest environments are easy to solve and allow fast iteration, while the hardest environments may be too challenging for current techniques. We also found that Lagrangian methods were surprisingly better than CPO, overturning a previous result in the field.
Below, we show learning curves for average episodic return and average episodic sum of costs. In our paper, we describe how to use these and a third metric (the average cost over training) to compare algorithms and measure progress.
Return and cost trade off against each other meaningfully
To facilitate reproducibility and future work, we’re also releasing the algorithms code we used to run these experiments as the Safety Starter Agents repo.
Open problems
There is still a lot of work to do on refining algorithms for constrained RL, and combining them with other problem settings and safety techniques. There are three things we are most interested in at the moment:
Improving performance on the current Safety Gym environments.
Using Safety Gym tools to investigate safe transfer learning and distributional shift problems.
Combining constrained RL with implicit specifications (like human preferences) for rewards and costs.
Our expectation is that, in the same way we today measure the accuracy or performance of systems at a given task, we’ll eventually measure the “safety” of systems as well. Such measures could feasibly be integrated into assessment schemes that developers use to test their systems, and could potentially be used by the government to create standards for safety.[1] We also hope that systems like Safety Gym can make it easier for AI developers to collaborate on safety across the AI sector via work on open, shared systems.
If you’re excited to work on safe exploration problems with us, we’re hiring!
AI requires people with different experiences, knowledge and backgrounds, which is why we started the DeepMind Scholarship programme and supportuniversitiesand the wider ecosystem.Read More