How Amazon is aligning its decarbonization goals with the best available science.Read More
Google demonstrates leading performance in latest MLPerf Benchmarks

Cross posted with the Google Cloud blog by Tao Wang, Software Engineer, Aarush Selvan, Product Manager.
The latest round of MLPerf benchmark results have been released, and Google’s TPU v4 supercomputers demonstrated record-breaking performance at scale. This is a timely milestone since large-scale machine learning training has enabled many of the recent breakthroughs in AI, with the latest models encompassing billions or even trillions of parameters (T5, Meena, GShard, Switch Transformer, and GPT-3).
Google’s TPU v4 Pod was designed, in part, to meet these expansive training needs, and TPU v4 Pods set performance records in four of the six MLPerf benchmarks Google entered using TensorFlow and JAX. These scores are a significant improvement over our winning submission from last year and demonstrate that Google once again has the world’s fastest machine learning supercomputers. These TPU v4 Pods are already widely deployed throughout Google data centers for our internal machine learning workloads and will be available via Google Cloud later this year.
 |
| Figure 1: Speedup of Google’s best MLPerf Training v1.0 TPU v4 submission over the fastest non-Google submission in any availability category – in this case, all baseline submissions came from NVIDIA. Comparisons are normalized by overall training time regardless of system size. Taller bars are better.1 |
Let’s take a closer look at some of the innovations that delivered these ground-breaking results and what this means for large model training at Google and beyond.
Google’s continued performance leadership
Google’s submissions for the most recent MLPerf demonstrated leading top-line performance (fastest time to reach target quality), setting new performance records in four benchmarks. We achieved this by scaling up to 3,456 of our next-gen TPU v4 ASICs with hundreds of CPU hosts for the multiple benchmarks. We achieved an average of 1.7x improvement in our top-line submissions compared to last year’s results. This means we can now train some of the most common machine learning models in a matter of seconds.
|
| Figure 2: Speedup of Google’s MLPerf Training v1.0 TPU v4 submission over Google’s MLPerf Training v0.7 TPU v3 submission (exception: DLRM results in MLPerf v0.7 were obtained using TPU v4). Comparisons are normalized by overall training time regardless of system size. Taller bars are better. Unet3D not shown since it is a new benchmark for MLPerf v1.0.2 |
We achieved these performance improvements through continued investment in both our hardware and software stacks. Part of the speedup comes from using Google’s fourth-generation TPU ASIC, which offers a significant boost in raw processing power over the previous generation, TPU v3. 4,096 of these TPU v4 chips are networked together to create a TPU v4 Pod, with each pod delivering 1.1 exaflop/s of peak performance.
 |
| Figure 3: A visual representation of 1 exaflop/s of computing power. If 10 million laptops were running simultaneously, then all that computing power would almost match the computing power of 1 exaflop/s. |
In parallel, we introduced a number of new features into the XLA compiler to improve the performance of any ML model running on TPU v4. One of these features provides the ability to operate two (or potentially more) TPU cores as a single logical device using a shared uniform memory access system. This memory space unification allows the cores to easily share input and output data – allowing for a more performant allocation of work across cores. A second feature improves performance through a fine-grained overlap of compute and communication. Finally, we introduced a technique to automatically transform convolution operations such that space dimensions are converted into additional batch dimensions. This technique improves performance at the low batch sizes that are common at very large scales.
Enabling large model research using carbon-free energy
Though the margin of difference in topline MLPerf benchmarks can be measured in mere seconds, this can translate to many days worth of training time on the state-of-the-art models that comprise billions or trillions of parameters. To give an example, today we can train a 4 trillion parameter dense Transformer with GSPMD on 2048 TPU cores. For context, this is over 20 times larger than the GPT-3 model published by OpenAI last year. We are already using TPU v4 Pods extensively within Google to develop research breakthroughs such as MUM and LaMDA, and improve our core products such as Search, Assistant and Translate. The faster training times from TPUs result in efficiency savings and improved research and development velocity. Many of these TPU v4 Pods will be operating at or near 90% carbon free energy. Furthermore, cloud datacenters can be ~1.4-2X more energy efficient than typical datacenters, and the ML-oriented accelerators – like TPUs – running inside them can be ~2-5X more effective than off-the-shelf systems.
We are also excited to soon offer TPU v4 Pods on Google Cloud, making the world’s fastest machine learning training supercomputers available to customers around the world, and we recently released an all-new Cloud TPU system architecture that provides direct access to TPU host machines, greatly improving the user experience.
Want to learn more?
Read how to get started using TPUs to train your model. We are excited to see how you will expand the machine learning frontier with access to exaflops of TPU computing power!
¹ All results retrieved from www.mlperf.org on June 30, 2021. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Chart uses results 1.0-1067, 1.0-1070, 1.0-1071, 1.0-1072, 1.0-1073, 1.0-1074, 1.0-1075, 1.0-1076, 1.0-1077, 1.0-1088, 1.0-1089, 1.0-1090, 1.0-1091, 1.0-1092.
² All results retrieved from www.mlperf.org on June 30, 2021. MLPerf name and logo are trademarks. See www.mlperf.org for more information. Chart uses results 0.7-65, 0.7-66, 0.7-67, 1.0-1088, 1.0-1090, 1.0-1091, 1.0-1092..
An update on our progress in responsible AI innovation
Over the past year, responsibly developed AI has transformed health screenings, supportedfact-checking to battle misinformation and save lives, predicted Covid-19 cases to support public health, and protected wildlife after bushfires. Developing AI in a way that gets it right for everyone requires openness, transparency, and a clear focus on understanding the societal implications. That is why we were among the first companies to develop and publish AI Principles and why, each year, we share updates on our progress.
Internal Education
In the last year, to ensure our teams have clarity from day one, we’ve added an introduction to our AI Principles for engineers and incoming hires in technical roles. The course presents each of the Principles as well as the applications we will not pursue.
Integrating our Principles into the work we do with enterprise customers is key, so we’ve continued to make our AI Principles in Practice training mandatory for customer-facing Cloud employees. A version of this training is available to all Googlers.
There is no single way to apply the AI Principles to specific features and product development. Training must consider not only the technology and data, but also where and how AI is used. To offer a more comprehensive approach to implementing the AI Principles, we’ve been developing opportunities for Googlers to share their points of view on the responsible development of future technologies, such as the AI Principles Ethics Fellowship for Google’s Employee Resource Groups. Fellows receive AI Principles training and craft hypothetical case studies to inform how Google prioritizes socially beneficial applications. This inaugural year, 27 fellows selected from 191 applicants from around the world wrote and presented case studies on topics such as genome datasets and a Covid-19 content moderation workflow.
Other programs include a bi-weekly Responsible AI Tech Talk Series featuring external experts, such as the Brookings Institution’s Dr. Nicol Turner Lee presenting on detecting and mitigating algorithmic bias.
Tools and Research
To bring together multiple teams working on technical tools and research, this year we formed the Responsible AI and Human-Centered Technology organization. The basic and applied researchers in the organization are devoted to developing technology and best practices for the technical realization of the AI Principles guidance.
As discussed in our December 2020 End-of-Year report, we regularly release these tools to the public. Currently, researchers are developing Know Your Data (in beta) to help developers understand datasets with the goal of improving data quality, helping to mitigate fairness and bias issues.
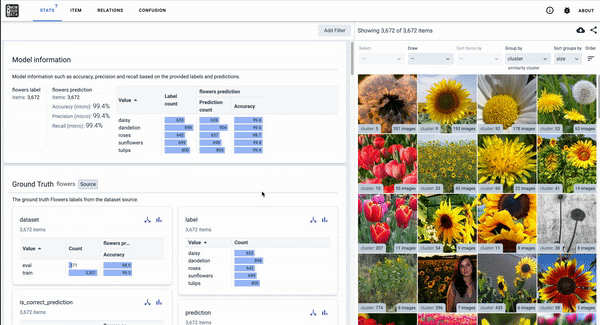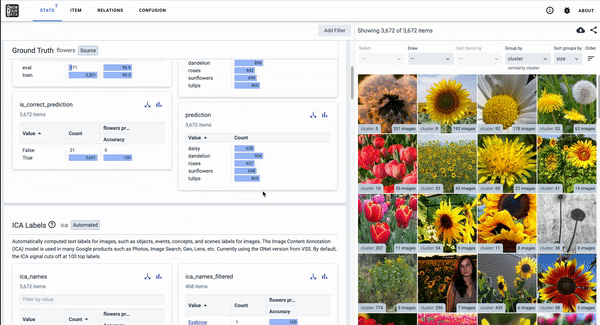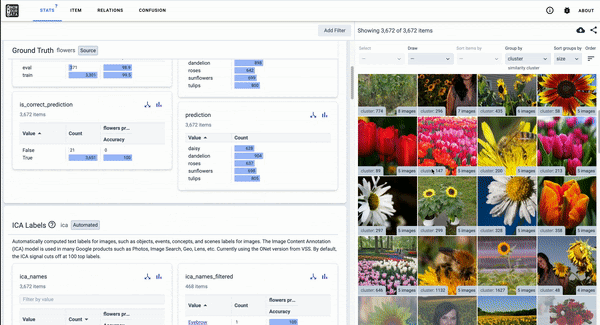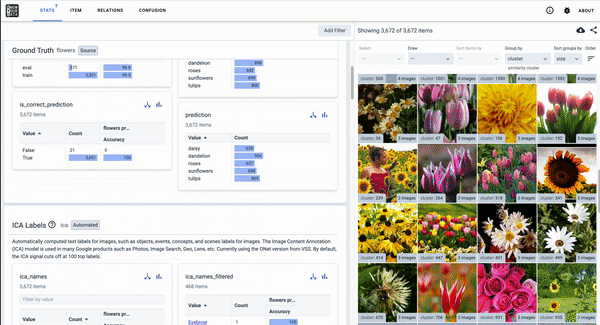
Know Your Data, a Responsible AI tool in beta
Product teams use these tools to evaluate their work’s alignment with the AI Principles. For example, the Portrait Light feature available in both Pixel’s Camera and Google Photos uses multiple machine learning components to instantly add realistic synthetic lighting to portraits. Using computational methods to achieve this effect, however, raised several responsible innovation challenges, including potentially reinforcing unfair bias (AI Principle #2) despite the goal of building a feature that works for all users. So the Portrait Light team generated a training dataset containing millions of photos based on an original set of photos of different people in a diversity of lighting environments, with their explicit consent. The engineering team used various Google Responsible AI tools to test proactively whether the ML models used in Portrait Light performed equitably across different audiences.
Our ongoing technical research related to responsible innovation in AI in the last 12 months has led to more than 200 research papers and articles that address AI Principles-related topics. These include exploring and mitigating data cascades; creating the first model-agnostic framework for partially local federated learning suitable for training and inference at scale; and analyzing the energy- and carbon-costs of training six recent ML models to reduce the carbon footprint of training an ML system by up to 99.9%.
Operationalizing the Principles
To help our teams put the AI Principles into practice, we deploy our decision-making process for reviewing new custom AI projects in development — from chatbots to newer fields such as affective technologies. These reviews are led by a multidisciplinary Responsible Innovation team, which draws on expertise in disciplines including trust and safety, human rights, public policy, law, sustainability, and product management. The team also advises product areas, on specific issues related to serving enterprise customers. Any Googler, at any level, is encouraged to apply for an AI Principles review of a project or planned product or service.
Teams can also request other Responsible Innovation services, such as informal consultations or product fairness testing with the Product Fairness (ProFair) team. ProFair tests products from the user perspective to investigate known issues and find new ones, similar to how an academic researcher would go about identifying fairness issues.
Our Google Cloud, Image Search, Next Billion Users and YouTube product teams have engaged with ProFair to test potential new projects for fairness. Consultations include collaborative testing scenarios, focus groups, and adversarial testing of ML models to address improving equity in data labels, fairness in language models, and bias in predictive text, among other issues. Recently, the ProFair team spent nine months consulting with Google researchers on creating an object recognition dataset for physical landmarks (such as buildings), developing criteria for how to choose which classes to recognize and how to determine the amount of training data per class in ways that would assign a fairer relevance score to each class.
Reviewers weigh the nature of the social benefit involved and whether it substantially exceeds potential challenges. For example, in the past year, reviewers decided not to publicly release ML models that can create photo-realistic synthetic faces made with generative adversarial networks (GANs), because of the risk of potential misuse by malicious actors to create “deepfakes” for misinformation purposes.
As another example, a research team requested a review of a new ML training dataset for computer vision fairness techniques that offered more specific attributes about people, such as perceived gender and age-range. The team worked with Open Images, an open data project containing ~9 million images spanning thousands of object categories and bounding box annotations for 600 classes. Reviewers weighed the risk of labeling the data with the sensitive labels of perceived gender presentation and age-range, and the societal benefit of these labels for fairness analysis and bias mitigation. Given these risks, reviewers required creation of a data card explaining the details and limitations of the project. We released the MIAP (More Inclusive Annotations for People) dataset in the Open Images Extended collection. The collection contains more complete bounding box annotations for the person class hierarchy in 100K images containing people. Each annotation is also labeled with fairness-related attributes. MIAP was accepted and presented at the 2021 Artificial Intelligence, Ethics and Society conference.
External Engagement
We remain committed to contributing to emerging international principles for responsible AI innovation. For example, we submitted a response to the European Commission consultation on the inception impact assessment on ethical and legal requirements for AI and feedback on NITI Aayog’s working document on Responsible Use of AI to guide national principles for India. We also supported the Singaporean government’s Guide to Job Redesign in the Age of AI, which outlines opportunities to optimize AI benefits by redesigning jobs and reskilling employees.
Our efforts to engage global audiences, from students to policymakers, center on educational programs and discussions to offer helpful and practical ML education, including:
- A workshop on Federated Learning and Analytics, making all research talks and a TensorFlow Federated tutorial publicly available.
- Machine Learning for Policy Leaders (ML4PL), a 2-hour virtual workshop on the basics of ML. To date, we’ve expanded this globally, reaching more than 350 policymakers across the EU, LatAm, APAC, and US.
- A workshop co-hosted with the Indian Ministry of Electronics and Information Technology on the Responsible Use of AI for Social Empowerment, exploring the potential of AI adoption in the government to address COVID-19, agricultural and environmental crises.
To support these workshops and events with actionable and equitable programming designed for long-term collaboration, over the past year we’ve helped launch:
- AI for Social Good workshops, bringing together NGOs applying AI to tough challenges in their communities with academic experts and Google researchers to encourage collaborative AI solutions. So far we’ve supported more than 30 projects in Asia Pacific and Sub-Saharan Africa with expertise, funding and Cloud Credits.
- Two collaborations with the U.S. National Science Foundation: one to support the National AI Research Institute for Human-AI Interaction and Collaboration with $5 million in funding, along with AI expertise, research collaborations and Cloud support; another to join other industry partners and federal agencies as part of a combined $40 million investment in academic research for Resilient and Intelligent Next-Generation (NextG) Systems, in which Google will offer expertise, research collaborations, infrastructure and in-kind support to researchers.
- Quarterly Equitable AI Research Roundtables (EARR), focused on the potential downstream harms of AI with experts from the Othering and Belonging Institute at UC Berkeley, PolicyLink, and Emory University School of Law.
- MLCommons, a non-profit, which will administer MLPerf, a suite of benchmarks for Google and industry peers.
Committed to sharing tools and discoveries
In the three years since Google released our AI Principles, we’ve worked to integrate this ethical charter across our work — from the development of advanced technologies to business processes. As we learn and engage with people and organizations across society we’re committed to sharing tools, processes and discoveries with the global community. You’ll find many of these in our recently updated People + AI Research Guidebook and on the Google AI responsibilities site, which we update quarterly with case studies and other resources.
Quickly Training Game-Playing Agents with Machine Learning
Posted by Leopold Haller and Hernan Moraldo, Software Engineers, Google Research
In the last two decades, dramatic advances in compute and connectivity have allowed game developers to create works of ever-increasing scope and complexity. Simple linear levels have evolved into photorealistic open worlds, procedural algorithms have enabled games with unprecedented variety, and expanding internet access has transformed games into dynamic online services. Unfortunately, scope and complexity have grown more rapidly than the size of quality assurance teams or the capabilities of traditional automated testing. This poses a challenge to both product quality (such as delayed releases and post-launch patches) and developer quality of life.
Machine learning (ML) techniques offer a possible solution, as they have demonstrated the potential to profoundly impact game development flows — they can help designers balance their game and empower artists to produce high-quality assets in a fraction of the time traditionally required. Furthermore, they can be used to train challenging opponents that can compete at the highest levels of play. Yet some ML techniques can pose requirements that currently make them impractical for production game teams, including the design of game-specific network architectures, the development of expertise in implementing ML algorithms, or the generation of billions of frames of training data. Conversely, game developers operate in a setting that offers unique advantages to leverage ML techniques, such as direct access to the game source, an abundance of expert demonstrations, and the uniquely interactive nature of video games.
Today, we present an ML-based system that game developers can use to quickly and efficiently train game-testing agents, helping developers find serious bugs quickly, while allowing human testers to focus on more complex and intricate problems. The resulting solution requires no ML expertise, works on many of the most popular game genres, and can train an ML policy, which generates game actions from the game state, in less than an hour on a single game instance. We have also released an open source library that demonstrates a functional application of these techniques.
 |
| Supported genres include arcade, action/adventure, and racing games. |
The Right Tool for the Right Job
The most elemental form of video game testing is to simply play the game. A lot. Many of the most serious bugs (such as crashes or falling out of the world) are easy to detect and fix; the challenge is finding them within the vast state space of a modern game. As such, we decided to focus on training a system that could “just play the game” at scale.
We found that the most effective way to do this was not to try to train a single, super-effective agent that could play the entire game from end-to-end, but to provide developers with the ability to train an ensemble of game-testing agents, each of which could effectively accomplish tasks of a few minutes each, which game developers refer to as “gameplay loops”.
 |
These core gameplay behaviors are often expensive to program through traditional means, but are much more efficient to train than a single end-to-end ML model. In practice, commercial games create longer loops by repeating and remixing core gameplay loops, which means that developers can test large stretches of gameplay by combining ML policies with a small amount of simple scripting.
Simulation-centric, Semantic API
One of the most fundamental challenges in applying ML to game development is bridging the chasm between the simulation-centric world of video games and the data-centric world of ML. Rather than ask developers to directly convert the game state into custom, low-level ML features (which would be too labor intensive) or attempting to learn from raw pixels (which would require too much data to train), our system provides developers with an idiomatic, game-developer friendly API that allows them to describe their game in terms of the essential state that a player observes and the semantic actions they can perform. All of this information is expressed via concepts that are familiar to game developers, such as entities, raycasts, 3D positions and rotations, buttons and joysticks.
As you can see in the example below, the API allows the specification of observations and actions in just a few lines of code.
 |
| Example actions and observations for a racing game. |
From API to Neural Network
This high level, semantic API is not just easy to use, but also allows the system to flexibly adapt to the specific game being developed — the specific combination of API building blocks employed by the game developer informs our choice of network architecture, since it provides information about the type of gaming scenario in which the system is deployed. Some examples of this include: handling action outputs differently depending on whether they represent a digital button or analog joystick, or using techniques from image processing to handle observations that result from an agent probing its environment with raycasts (similar to how autonomous vehicles probe their environment with LIDAR).
Our API is sufficiently general to allow modeling of many common control-schemes (the configuration of action outputs that control movement) in games, such as first-person games, third-person games with camera-relative controls, racing games, twin stick shooters, etc. Since 3D movement and aiming are often an integral aspect of gameplay in general, we create networks that automatically tend towards simple behaviors such as aiming, approach or avoidance in these games. The system accomplishes this by analyzing the game’s control scheme to create neural network layers that perform custom processing of observations and actions in that game. For example, positions and rotations of objects in the world are automatically translated into directions and distances from the point of view of the AI-controlled game entity. This transformation typically increases the speed of learning and helps the learned network generalize better.
| An example neural network generated for a game with joystick controls and raycast inputs. Depending on the inputs (red) and the control scheme, the system generates custom pre- and post-processing layers (orange). |
Learning From The Experts in Real Time
After generating a neural network architecture, the network needs to be trained to play the game using an appropriate choice of learning algorithm.
Reinforcement learning (RL), in which an ML policy is trained directly to maximize a reward, may seem like the obvious choice since they have been successfully used to train highly competent ML policies for games. However, RL algorithms tend to require more data than a single game instance can produce in a reasonable amount of time, and achieving good results in a new domain often requires hyperparameter tuning and strong ML domain knowledge.
Instead, we found that imitation learning (IL), which trains ML policies based by observing experts play the game, works well for our use case. Unlike RL, where the agent needs to discover a good policy on its own, IL only needs to recreate the behavior of a human expert. Since game developers and testers are experts in their own games, they can easily provide demonstrations of how to play the game.
We use an IL approach inspired by the DAgger algorithm, which allows us to take advantage of video games’ most compelling quality — interactivity. Thanks to the reductions in training time and data requirements enabled by our semantic API, training is effectively realtime, giving a developer the ability to fluidly switch between providing gameplay demonstrations and watching the system play. This results in a natural feedback loop, in which a developer iteratively provides corrections to a continuous stream of ML policies.
From the developer’s perspective, providing a demonstration or a correction to faulty behavior is as simple as picking up the controller and starting to play the game. Once they are done, they can put the controller down and watch the ML policy play. The result is a training experience that is real-time, interactive, highly experiential, and, very often, more than a little fun.
 |
| ML policy for an FPS game, trained with our system. |
Conclusion
We present a system that combines a high-level semantic API with a DAgger-inspired interactive training flow that enables training of useful ML policies for video game testing in a wide variety of genres. We have released an open source library as a functional illustration of our system. No ML expertise is required and training of agents for test applications often takes less than an hour on a single developer machine. We hope that this work will help inspire the development of ML techniques that can be deployed in real-world game-development flows in ways that are accessible, effective, and fun to use.
Acknowledgements
We’d like to thank the core members of the project: Dexter Allen, Leopold Haller, Nathan Martz, Hernan Moraldo, Stewart Miles and Hina Sakazaki. Training algorithms are provided by TF Agents, and on-device inference by TF Lite. Special thanks to our research advisors, Olivier Bachem, Erik Frey, and Toby Pohlen, and to Eugene Brevdo, Jared Duke, Oscar Ramirez and Neal Wu who provided helpful guidance and support.

The bridge between supply and demand
How Amazon’s Delivery Experience team acts as a concierge for customers.Read More
Douglas Coupland fuses AI and art to inspire students
Have you ever noticed that the word art is embedded in the phrase artificial intelligence? Neither did we, but when the opportunity presented itself to explore how artificial intelligence (AI) inspires artistic expression — with the help of internationally renowned Canadian artist Douglas Coupland — the Google Research team jumped on it. This collaboration, with the support of Google Arts & Culture, culminated in a project called Slogans for the Class of 2030, which spotlights the experiences of the first generation of young people whose lives are fully intertwined with the existence of AI.
This collaboration was brought to life by first introducing Coupland’s written work to a machine learning language model. Machine learning is a form of AI that provides computer systems the ability to automatically learn from data. In this case, Google research scientists tuned a machine learning algorithm with Coupland’s 30-year body of written work — more than a million words — so it would familiarize itself with the author’s unique style of writing. From there, curated general-public social media posts on selected topics were added to teach the algorithm how to craft short-form, topical statements.
Once the algorithm was trained, the next step was to process and reassemble suggestions of text for Coupland to use as inspiration to create twenty-five Slogans for the Class of 2030.
“I would comb through ‘data dumps’ where characters from one novel were speaking with those in other novels in ways that they might actually do. It felt like I was encountering a parallel universe Doug,” Coupland says. “And from these outputs, the statements you see here in this project appeared like gems. Did I write them? Yes. No. Could they have existed without me? No.”
A common theme in Coupland’s work is the investigation of the human condition through the lens of pop culture. The focus on the class of 2030 was intentional. Coupland wanted to create works that would serve as inspiration for students in their early teens who will be graduating from universities in 2030. For those teens considering their future career paths, he hoped that this collaboration would trigger a broader conversation on the vast possibilities in the field and would acquaint them with the fact that AI does not have to be strictly scientific, it can be artful.
Unveiled today, all 25 thought-provoking and visually rich digital slogans are yours to experience on Google Arts & Culture alongside Coupland’s artistic statement and other behind-the-scenes material. This isn’t Douglas’ first collaboration with Google Arts & Culture; in 2019 Coupland’s Vancouver art exhibition was captured virtually. In 2015 and 2016, he joined theGoogle Arts & Culture Lab residency in Paris where he collaborated with engineers to develop many works including theSearch book andthe Living Internet.
In an effort to celebrate local talent and culture, multiple venues across Canada have signed on to project the slogans, for a limited time, on larger-than-life digital screens allowing curious minds to experience them in an immersive way. The screens include the Terry Fox Memorial Plaza at BC Place Stadium in Vancouver B. C., the TELUS Len Werry building in downtown Calgary, TELUS Harbour in downtown Toronto and select Pattison digital screens across Canada.
Technology has always played a role in creating new types of possibilities that inspire artists — from the sounds of distortion to the electronic sounds of synths for musicians for example. Today, advances in AI are opening up new possibilities for other forms of art and we look forward to seeing what the crossroads of art and technology bring to life.
How we’re supporting 30 new AI for Social Good projects
Over recent years, we have seen remarkable progress in AI’s ability to confront new problems and help solve old ones. Advancing these efforts was one reason we set up the Google Research India lab in 2019, with a particular emphasis on AI research that could make a positive social impact. It’s also why we’ve supported nonprofit organizations through the Google AI Impact Challenge.
Working in partnership with Google.org and Google’s University Relations program, our goal is to help academics and nonprofits develop AI techniques that can improve people’s lives — especially in underserved communities that haven’t yet benefited from advances in AI. We reported on the impact of six such projects in 2020. And today, we’re sharing 30 new projects that will receive funding and support as part of our AI for Social Good program.
During the application process, Googlers arranged workshops involving more than 150 teams to discuss potential projects. Following the workshop meetings, project teams made up of NGOs and academics submitted proposals which Google experts reviewed. The result is a promising range of projects spanning seventeen countries across Asia-Pacific and Sub-Saharan Africa — including India, Uganda, Nigeria, Japan and Australia— focused on agriculture, conservation and public health.
In agriculture, this includes research to help farmer collectives with market intelligence and use data to improve crop and irrigation planning for smallholder farmers. In public health, we are backing projects that will enable targeted public health interventions, and will help community health workers to forecast health risks in countries such as Kenya, India and Uganda. We’re also supporting research to better forecast the need for critical resources like vaccines and care, including in Nigeria. And in conservation, we’re supporting research to help understand animal population changes, such as the effect of poaching on elephants, and gorillas. Other projects will help reduce conservation conflict and poaching, including human-elephant conflict in Kenya.
Each project team will receive funding, technical contributions from Google and access to computational resources. Academics in this program will be recognized as “Impact Scholars” for their contributions towards advancing research for social good.
We’ve seen the impact these kinds of projects can make. One of the nonprofit leaders supported by the program last year, ARMMAN founder Dr. Aparna Hegde, has received AI research support from IIT Madras and Google Research to improve maternal and child health outcomes in India. The team is building a predictive model to prevent expectant mothers dropping out of supportive telehealth outreach programs. Results so far show AI could enable ARMMAN to increase the number of women engaged through the program by 50%, and they have received a second Google.org grant to enable them to build on this progress. Dr. Hegde says the program is “already showing encouraging results — and I am confident that this partnership will bring immense benefits in the future.”
Congratulations to all the recipients of this round’s support. We’re looking forward to continuing to nurture the AI for Social Good community, bringing together experts from diverse backgrounds with the common goal of advancing AI to improve lives around the world.
Take All Your Pictures to the Cleaners, with Google Photos Noise and Blur Reduction
Posted by Mauricio Delbracio, Research Scientist and Sungjoon Choi, Software Engineer, Google Research
Despite recent leaps in imaging technology, especially on mobile devices, image noise and limited sharpness remain two of the most important levers for improving the visual quality of a photograph. These are particularly relevant when taking pictures in poor light conditions, where cameras may compensate by increasing the ISO or slowing the shutter speed, thereby exacerbating the presence of noise and, at times, increasing image blur. Noise can be associated with the particle nature of light (shot noise) or be introduced by electronic components during the readout process (read noise). The captured noisy signal is then processed by the camera image processor (ISP) and later may be further enhanced, amplified, or distorted by a photographic editing process. Image blur can be caused by a wide variety of phenomena, from inadvertent camera shake during capture, an incorrect setting of the camera’s focus (automatic or not), or due to the finite lens aperture, sensor resolution or the camera’s image processing.
It is far easier to minimize the effects of noise and blur within a camera pipeline, where details of the sensor, optical hardware and software blocks are understood. However, when presented with an image produced from an arbitrary (possibly unknown) camera, improving noise and sharpness becomes much more challenging due to the lack of detailed knowledge and access to the internal parameters of the camera. In most situations, these two problems are intrinsically related: noise reduction tends to eliminate fine structures along with unwanted details, while blur reduction seeks to boost structures and fine details. This interconnectedness increases the difficulty of developing image enhancement techniques that are computationally efficient to run on mobile devices.
Today, we present a new approach for camera-agnostic estimation and elimination of noise and blur that can improve the quality of most images. We developed a pull-push denoising algorithm that is paired with a deblurring method, called polyblur. Both of these components are designed to maximize computational efficiency, so users can successfully enhance the quality of a multi-megapixel image in milliseconds on a mobile device. These noise and blur reduction strategies are critical components of the recent Google Photos editor updates, which includes “Denoise” and “Sharpen” tools that enable users to enhance images that may have been captured under less than ideal conditions, or with older devices that may have had more noisy sensors or less sharp optics.
 |
| A demonstration of the “Denoise” and “Sharpen” tools now available in the Google Photos editor. |
How Noisy is An Image?
In order to accurately process a photographic image and successfully reduce the unwanted effects of noise and blur, it is vitally important to first characterize the types and levels of noise and blur found in the image. So, a camera-agnostic approach for noise reduction begins by formulating a method to gauge the strength of noise at the pixel level from any given image, regardless of the device that created it. The noise level is modeled as a function of the brightness of the underlying pixel. That is, for each possible brightness level, the model estimates a corresponding noise level in a manner agnostic to either the actual source of the noise or the processing pipeline.
To estimate this brightness-based noise level, we sample a number of small patches across the image and measure the noise level within each patch, after roughly removing any underlying structure in the image. This process is repeated at multiple scales, making it robust to artifacts that may arise from compression, image resizing, or other non-linear camera processing operations.
 |
| The two segments on the left illustrate signal-dependent noise present in the input image (center). The noise is more prominent in the bottom, darker crop and is unrelated to the underlying structure, but rather to the light level. Such image segments are sampled and processed to generate the spatially-varying noise map (right) where red indicates more noise is present. |
Reducing Noise Selectively with a Pull-Push Method
We take advantage of self-similarity of patches across the image to denoise with high fidelity. The general principle behind such so-called “non-local” denoising is that noisy pixels can be denoised by averaging pixels with similar local structure. However, these approaches typically incur high computational costs because they require a brute force search for pixels with similar local structure, making them impractical for on-device use. In our “pull-push” approach1, the algorithmic complexity is decoupled from the size of filter footprints thanks to effective information propagation across spatial scales.
The first step in pull-push is to build an image pyramid (i.e., multiscale representation) in which each successive level is generated recursively by a “pull” filter (analogous to downsampling). This filter uses a per-pixel weighting scheme to selectively combine existing noisy pixels together based on their patch similarities and estimated noise, thus reducing the noise at each successive, “coarser” level. Pixels at coarser levels (i.e., with lower resolution) pull and aggregate only compatible pixels from higher resolution, “finer” levels. In addition to this, each merged pixel in the coarser layers also includes an estimated reliability measure computed from the similarity weights used to generate it. Thus, merged pixels provide a simple per-pixel, per-level characterization of the image and its local statistics. By efficiently propagating this information through each level (i.e., each spatial scale), we are able to track a model of the neighborhood statistics for increasingly larger regions in a multiscale manner.
After the pull stage is evaluated to the coarsest level, the “push” stage fuses the results, starting from the coarsest level and generating finer levels iteratively. At a given scale, the push stage generates “filtered” pixels following a process similar to that of the pull stage, but going from coarse to finer levels. The pixels at each level are fused with those of coarser levels by doing a weighted average of same-level pixels along with coarser-level filtered pixels using the respective reliability weights. This enables us to reduce pixel noise while preserving local structure, because only average reliable information is included. This selective filtering and reliability (i.e. information) multiscale propagation is what makes push-pull different from existing frameworks.
 |
| This series of images shows how filtering progresses through the pull-push process. Coarser level pixels pull and aggregate only compatible pixels from finer levels, as opposed to the traditional multiscale approaches using a fixed (non-data dependent) kernel. Notice how the noise is reduced throughout the stages. |
The pull-push approach has a low computational cost, because the algorithm to selectively filter similar pixels over a very large neighborhood has a complexity that is only linear with the number of image pixels. In practice, the quality of this denoising approach is comparable to traditional non-local methods with much larger kernel footprints, but operates at a fraction of the computational cost.
 |
 |
| Image enhanced using the pull-push denoising method. |
How Blurry Is an Image?
An image with poor sharpness can be thought of as being a more pristine latent image that was operated on by a blur kernel. So, if one can identify the blur kernel, it can be used to reduce the effect. This is referred to as “deblurring”, i.e., the removal or reduction of an undesired blur effect induced by a particular kernel on a particular image. In contrast, “sharpening” refers to applying a sharpening filter, built from scratch and without reference to any particular image or blur kernel. Typical sharpening filters are also, in general, local operations that do not take account of any other information from other parts of the image, whereas deblurring algorithms estimate the blur from the whole image. Unlike arbitrary sharpening, which can result in worse image quality when applied to an image that is already sharp, deblurring a sharp image with a blur kernel accurately estimated from the image itself will have very little effect.
We specifically target relatively mild blur, as this scenario is more technically tractable, more computationally efficient, and produces consistent results. We model the blur kernel as an anisotropic (elliptical) Gaussian kernel, specified by three parameters that control the strength, direction and aspect ratio of the blur.
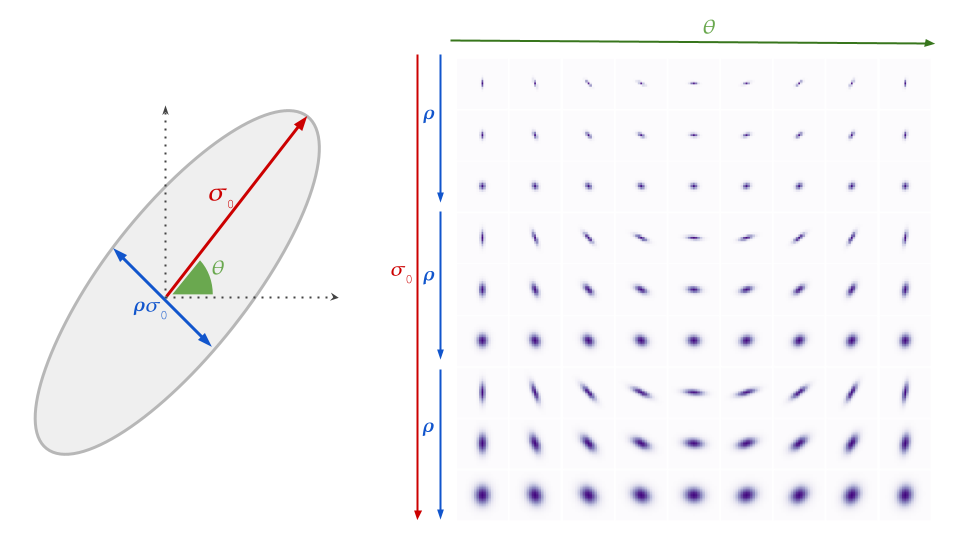 |
| Gaussian blur model and example blur kernels. Each row of the plot on the right represents possible combinations of σ0, ρ and θ. We show three different σ0 values with three different ρ values for each. |
Computing and removing blur without noticeable delay for the user requires an algorithm that is much more computationally efficient than existing approaches, which typically cannot be executed on a mobile device. We rely on an intriguing empirical observation: the maximal value of the image gradient across all directions at any point in a sharp image follows a particular distribution. Finding the maximum gradient value is efficient, and can yield a reliable estimate of the strength of the blur in the given direction. With this information in hand, we can directly recover the parameters that characterize the blur.
Polyblur: Removing Blur by Re-blurring
To recover the sharp image given the estimated blur, we would (in theory) need to solve a numerically unstable inverse problem (i.e., deblurring). The inversion problem grows exponentially more unstable with the strength of the blur. As such, we target the case of mild blur removal. That is, we assume that the image at hand is not so blurry as to be beyond practical repair. This enables a more practical approach — by carefully combining different re-applications of an operator we can approximate its inverse.
 |
 |
| Mild blur, as shown in these examples, can be effectively removed by combining multiple applications of the estimated blur. |
This means, rather counterintuitively, that we can deblur an image by re-blurring it several times with the estimated blur kernel. Each application of the (estimated) blur corresponds to a first order polynomial, and the repeated applications (adding or subtracting) correspond to higher order terms in a polynomial. A key aspect of this approach, which we call polyblur, is that it is very fast, because it only requires a few applications of the blur itself. This allows it to operate on megapixel images in a fraction of a second on a typical mobile device. The degree of the polynomial and its coefficients are set to invert the blur without boosting noise and other unwanted artifacts.
 |
| The deblurred image is generated by adding and subtracting multiple re-applications of the estimated blur (polyblur). |
Integration with Google Photos
The innovations described here have been integrated and made available to users in the Google Photos image editor in two new adjustment sliders called “Denoise” and “Sharpen”. These features allow users to improve the quality of everyday images, from any capture device. The features often complement each other, allowing both denoising to reduce unwanted artifacts, and sharpening to bring clarity to the image subjects. Try using this pair of tools in tandem in your images for best results. To learn more about the details of the work described here, check out our papers on polyblur and pull-push denoising. To see some examples of the effect of our denoising and sharpening up close, have a look at the images in this album.
Acknowledgements
The authors gratefully acknowledge the contributions of Ignacio Garcia-Dorado, Ryan Campbell, Damien Kelly, Peyman Milanfar, and John Isidoro. We are also thankful for support and feedback from Navin Sarma, Zachary Senzer, Brandon Ruffin, and Michael Milne.
1 The original pull-push algorithm was developed as an efficient scattered data interpolation method to estimate and fill in the missing pixels in an image where only a subset of the pixels are specified. Here, we extend its methodology and present a data-dependent multiscale algorithm for denoising images efficiently. ↩
2021 Request for Proposals: Faculty awards to support machine learning courses, diversity, and inclusion
Posted by Josh Gordon for the TensorFlow team
Google AI and the TensorFlow team have a funding opportunity open to universities. If you’re a faculty member interested in teaching machine learning courses, and/or leading or contributing to diversity initiatives, please read on to learn more. We have parallel goals for these awards, and you may apply for funding with one or both in mind.
- We want to support you as you lead or contribute to diversity initiatives that widen access to ML education for currently underrepresented groups in computer science. We are especially interested in programs that include a clear focus on cultivating and retaining a “critical mass” of students, and that encourage students to pursue graduate study and/or future careers in ML.
- We want to support you as you design, develop, and teach undergraduate or graduate level machine learning courses that include examples with open-source libraries. We would like to support courses that teach practical, in-demand skills, and to support courses that prepare students to solve new and challenging problems using ML in applied areas, such as healthcare, journalism, basic science, and others.

We especially welcome proposals that combine these goals, proposals that include cross-institutional collaborations, and proposals that include collaborations between faculty and graduate students. We look forward to hearing your ideas!
To learn more, please see the RFP at goo.gle/tensorflow-rfp. Please note that the submission deadline is July 30th, 2021. For questions, you can reach out to tensorflow-rfp@google.com.
On demand: The 2021 AWS Machine Learning Summit
Didn’t get the opportunity to attend the summit earlier this month? Now available on demand: Presentations on the science of machine learning by leading scholars, a fireside chat with Andrew Ng, and more career-growth content.Read More