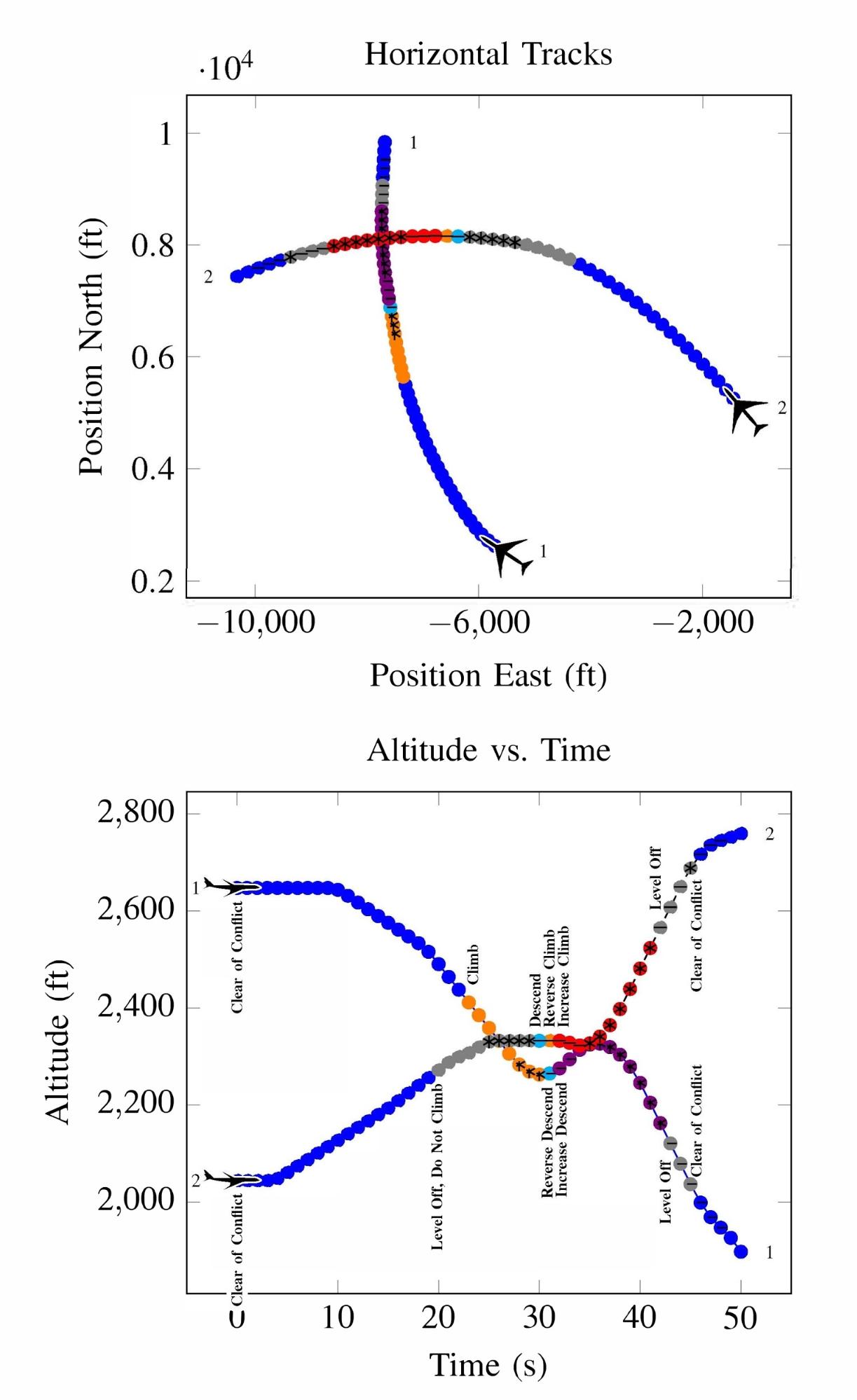
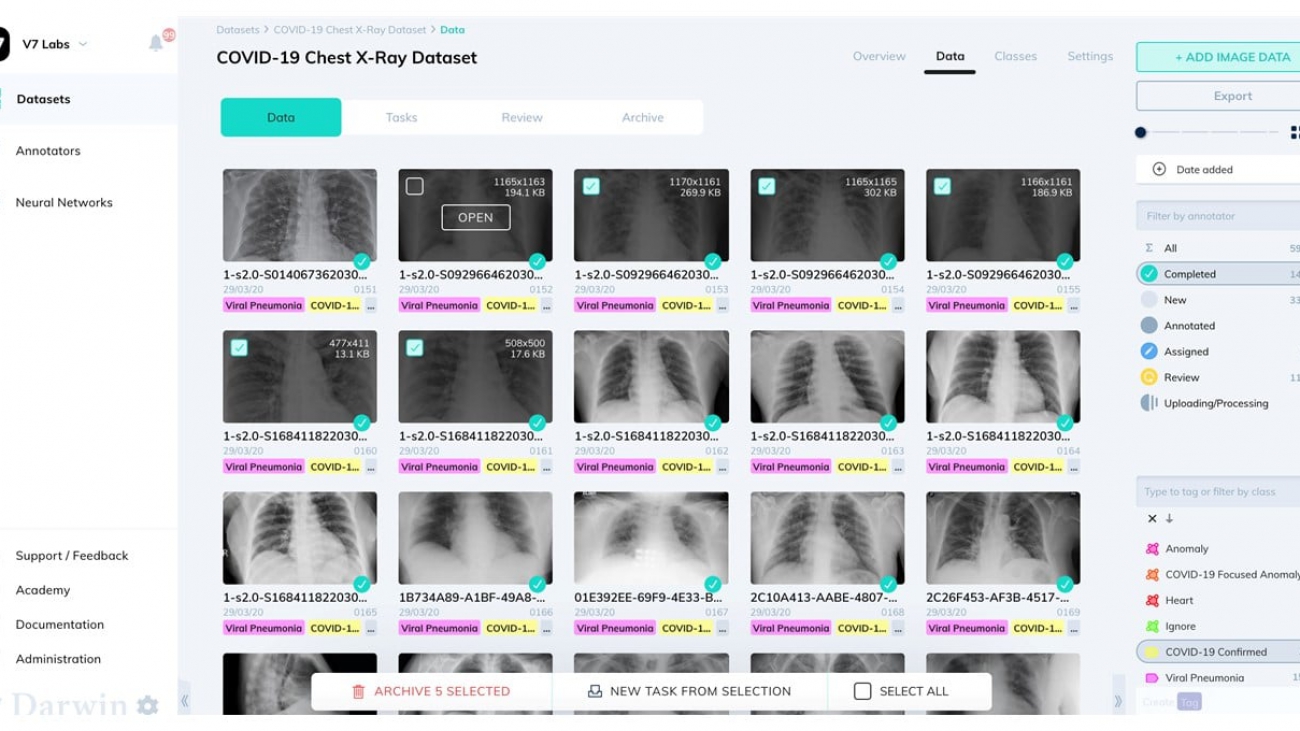
Amazon Kendra is a highly accurate and easy-to-use enterprise search service powered by machine learning (ML). To get started with Amazon Kendra, we offer data source connectors to get your documents easily ingested and indexed.
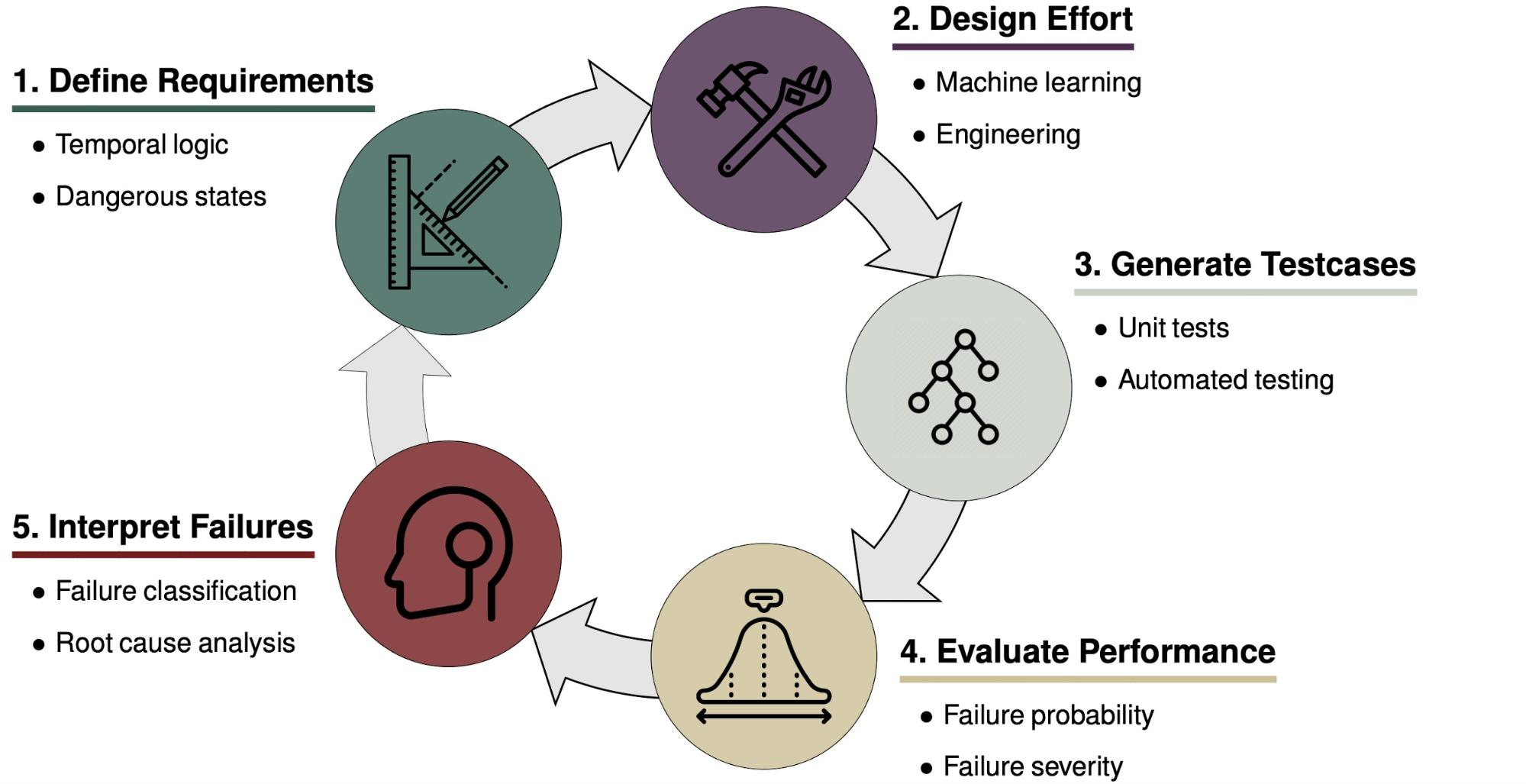
This post describes how to use Amazon Kendra’s SharePoint Online connector. To allow the connector to access your SharePoint Online site, you only need to provide the index URL and the credentials of a user with owner rights. These access credentials will be securely stored in AWS Secrets Manager.
Currently, Amazon Kendra has two provisioning editions: the Amazon Kendra Developer Edition for building proof of concepts (POCs) and the Amazon Kendra Enterprise Edition. Amazon Kendra connectors work with both editions.
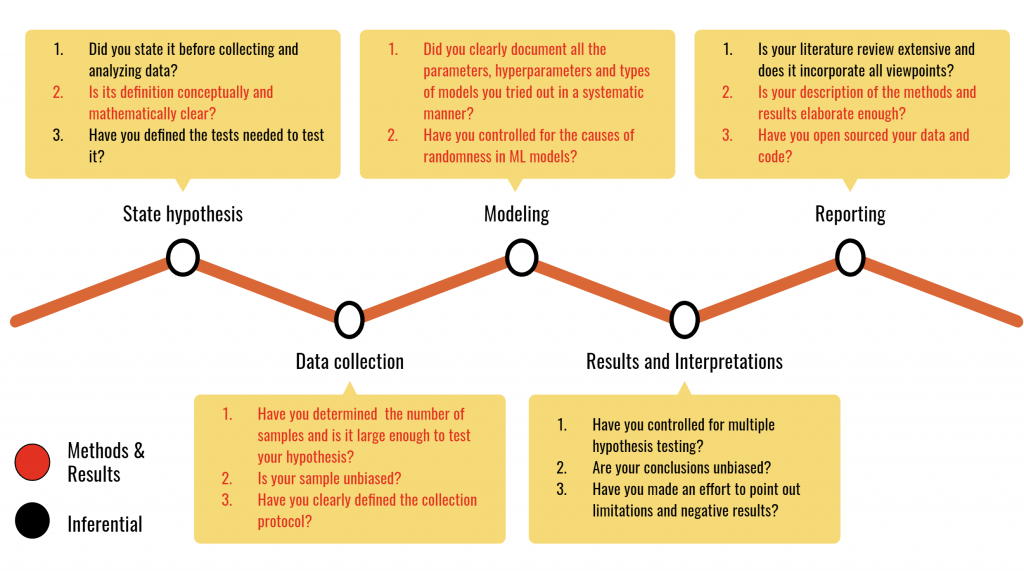
Prerequisites
To get started, you need the following:
- A SharePoint Online site
- A SharePoint Online user with owner rights
Owner rights are the minimum admin rights needed for the connector to access and ingest documents from your SharePoint site. This follows the AWS principle of granting least privilege access.
The metadata in your SharePoint Online documents must be specifically mapped to Amazon Kendra attributes. This mapping is done in the Attributes and field mappings section in this post. The SharePoint document title is mapped to the Amazon Kendra system attribute _document_title. If you skip the field mapping step, you need to create a new data connector to the SharePoint Online site.
The AWS Identity and Access Management (IAM) role for the SharePoint Online data source is not the same as the Amazon Kendra index IAM role. Please read the section Defining targets: Site URL and data source IAM role carefully. It’s important to pay particular attention to the interplay between the SharePoint Online data source’s IAM role and the secrets manager that contains your SharePoint Online credentials.
For this post, we assume that you already have a SharePoint Online site deployed.
Setting up a SharePoint Online connector for Amazon Kendra from the console
The following section describes the process of deploying an Amazon Kendra index and configuring a SharePoint Online connector. If you already have an index, you can skip to the Configuring the SharePoint Online connector section.
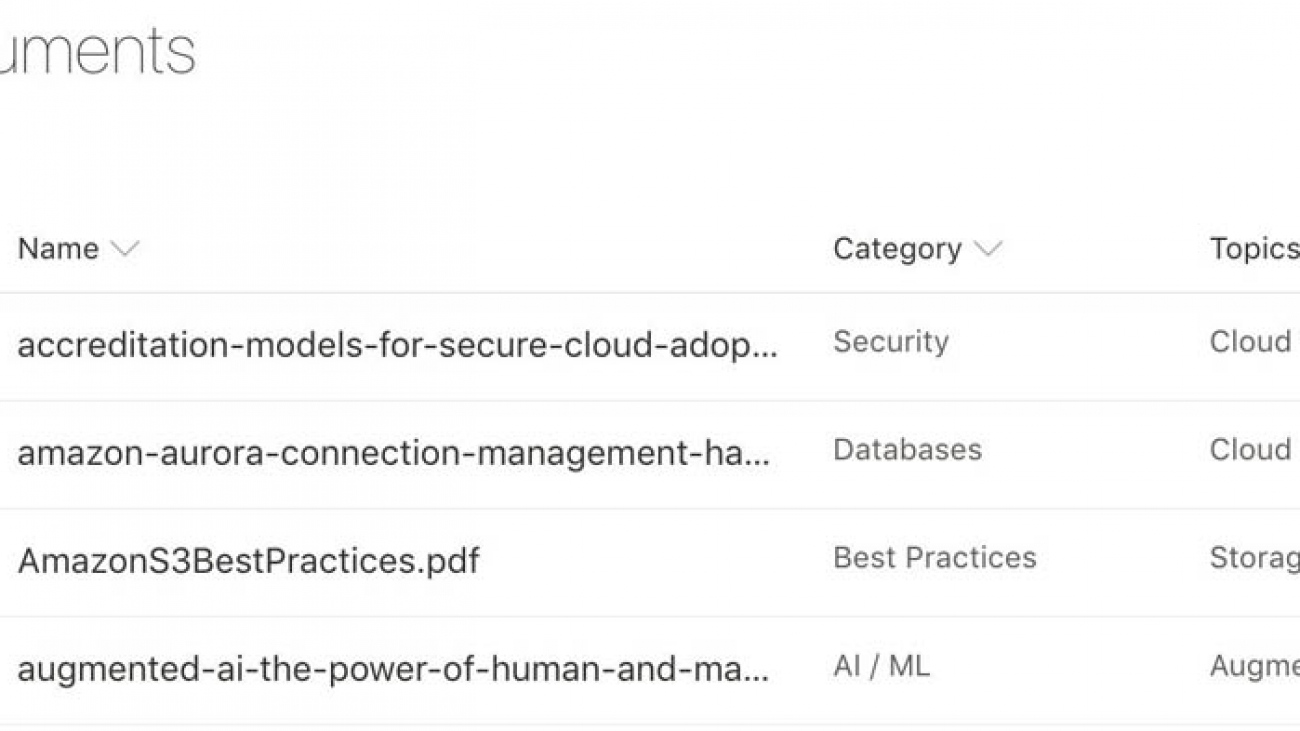
For this use case, our SharePoint Online site contains a collection of AWS whitepapers with custom columns, such as Topics. 
Creating an Amazon Kendra index
In an Amazon Kendra setup workflow, the first step is to create an index, where you define an IAM role and the method you want Amazon Kendra to use for data encryption. For this use case, we create a new role.
If you use an existing role, check that it has permission to write to an Amazon CloudWatch log. For more information, see IAM roles for indexes. 
Next, you select which provisioning edition to use. For this post, I select the Developer edition. If you’re new to Amazon Kendra, we recommend creating an Amazon Kendra Developer Edition index because it’s a more cost-efficient way to explore Amazon Kendra. For production environments, we highly recommended using the Enterprise Edition because it allows for more storage capacity and queries per day, and is designed for high availability.

Configuring the SharePoint Online connector
After you create your index, you set up the data sources. One of the advantages of implementing Amazon Kendra is that you can use a set of prebuilt connectors for data sources such as Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), SharePoint Online, and Salesforce.

For this use case, we choose SharePoint Online.
Assigning a name to the data source
In the Define attributes section, you enter a name for the data source, an optional description, and assign optional tags.

Defining targets: Site URL and data source IAM role
In the Define targets section, you enter the targets where you need to define the SharePoint Online site URLs where the documents reside and the IAM role that the connecter uses to operate. It’s important to remember that this IAM role is different from the one used to create the index. For more information, see IAM roles for data sources.
If you don’t have an IAM role for this task, you can easily create one by choosing Create New Role. For this use case, I use a previously created role.
Under the URL text box, you can select Use change log, which enables the connector to use the SharePoint change log to determine the documents that need to be updated in the index. If your SharePoint change log is too large, your sync process may take longer.
You can also select Crawl attachments, which allows the crawler to include the attachments associated with items stored in your site.

You can also include or exclude documents by using regular expressions. You can define patterns that Amazon Kendra either uses to exclude certain documents from indexing or include only documents with that pattern. For more information, see SharePointConfiguration.

Providing SharePoint Online credentials
In the Configure settings section, you set up your SharePoint Online user (if you don’t have one created, you can create an additional user). The credentials you enter are stored in the Secrets Manager.

Save the authentication information and set up the sync run schedule, which determines how often Kendra checks your SharePoint Online site URLs for changes. For this use case, I choose to Run on demand.

Attributes and field mappings
In this next step, you can create field mappings. Even though this is an optional step, it’s a good idea to add this extra layer of metadata to your documents from SharePoint Online. Metadata enables you to improve accuracy through manual tuning, filtering, and faceting. You can’t add metadata to already ingested documents, so if you want to add metadata later, you need to delete this data source and recreate this data source with metadata and re-ingest your documents.
The default SharePoint Online metadata fields are Title, Created, and Modified.

One powerful feature is the ability to create custom field mappings. For example, on my SharePoint Online site, I created a column named Category. By importing this extra piece of information, we can create filters based on category names.

To import that extra information, you create a custom field mapping by choosing Add a new field mapping button.

If you’re combining multiple data sources, you can map this new field to an existing field. For this use case, I have other documents that have the attribute Category, so I choose Option A to map fields to an existing document attributes field in my Amazon Kendra index. For more information, see Creating custom document attributes.

Also, on my SharePoint Site, I have an additional field called Topic. Because I don’t have that field on my index yet, I select Option B and enter the data source field name and select the data type (for this use case, String).

Field names are case-sensitive, so we need to make sure we match them. Additionally, when a data field on SharePoint is renamed, only the display name changes. This means that if you want to import a data field, you need to refer to the original name. A way to find it is to sort by that column and check the name as listed on the address bar.

Let’s check what field is used for sorting:

Reviewing settings and creating a SharePoint Online data source
As a last step, you review the settings and create the data source. The Domain(s) and role section provides additional configuration information.
After you create your SharePoint Online data source, a banner similar to the following screenshot will appear at the top of your screen. To start the syncing and document ingestion process, choose Sync now.

You see a banner indicating the progress of the data source sync job. After the sync job is finished, you can test your index.
Testing
You can test your new index on the Amazon Kendra search console. See the following screenshot.

Also, if you configured extra fields as facetable, you can filter your documents by those facets. See the following screenshot.

Creating an Amazon Kendra index with a SharePoint Online connector with Python
In addition to the console, you can create a new Amazon Kendra index SharePoint online connector and sync it by using the AWS SDK for Python (Boto3). Boto3 makes it easy to integrate your Python application, library, or script with AWS services, including Amazon Kendra.
My personal preference for testing my Python scripts is to spin up an Amazon SageMaker notebook instance, a fully managed ML Amazon Elastic Compute Cloud (Amazon EC2) instance that runs the Jupyter Notebook app. For instructions, see Create an Amazon SageMaker Notebook Instance.
IAM roles requirements and overview
To create an index using the AWS SDK, you need to have the policy AmazonKendraFullAccess attached to the role you are using.
At a high level, these are the different roles Amazon Kendra requires:
- IAM roles for indexes – Needed to write to CloudWatch Logs.
- IAM roles for data sources – Needed when you use the
CreateDataSource method. These roles require a specific set of permissions depending on the connector you use. For our use case, it needs permissions to access the following:
- Secrets Manager, where the SharePoint online credentials are stored.
- The AWS Key Management Service (AWS KMS) customer master key (CMK) to decrypt the credentials by Secrets Manager.
- The
BatchPutDocument and BatchDeleteDocument operations to update the index.
- The Amazon S3 bucket that contains the SSL certificate used to communicate with the SharePoint Site (we use SSL for this use case).
For more information, see IAM access roles for Amazon Kendra.
For this method, you need:
- An Amazon SageMaker notebooks role with permission to create an Amazon Kendra index where you’re using the notebook
- An Amazon Kendra IAM role for CloudWatch
- An Amazon Kendra IAM role for the SharePoint Online connector
- A SharePoint Online credentials store on Secrets Manager
Creating an Amazon Kendra index
To create an index, you use the following code:
import boto3
from botocore.exceptions import ClientError
import pprint
import time
kendra = boto3.client("kendra")
print("Creating an index")
description = <YOUR INDEX DESCRIPTION>
index_name = <YOUR NEW INDEX NAME>
role_arn = "KENDRA ROLE WITH CLOUDWATCH PERMISSIONS ROLE"
try:
index_response = kendra.create_index(
Description = description,
Name = index_name,
RoleArn = role_arn,
Edition = "DEVELOPER_EDITION",
Tags=[
{
'Key': 'Project',
'Value': 'SharePoint Test'
}
]
)
pprint.pprint(index_response)
index_id = index_response['Id']
print("Wait for Kendra to create the index.")
while True:
# Get index description
index_description = kendra.describe_index(
Id = index_id
)
# If status is not CREATING quit
status = index_description["Status"]
print(" Creating index. Status: "+status)
if status != "CREATING":
break
time.sleep(60)
except ClientError as e:
print("%s" % e)
print("Done creating index.")
While your index is being created, you get regular updates (every 60 seconds; check line 38) until the process is complete. See the following code:
Creating an index
{'Id': '3311b507-bfef-4e2b-bde9-7c297b1fd13b',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '45',
'content-type': 'application/x-amz-json-1.1',
'date': 'Mon, 20 Jul 2020 19:58:19 GMT',
'x-amzn-requestid': 'a148a4fc-7549-467e-b6ec-6f49512c1602'},
'HTTPStatusCode': 200,
'RequestId': 'a148a4fc-7549-467e-b6ec-6f49512c1602',
'RetryAttempts': 2}}
Wait for Kendra to create the index.
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: CREATING
Creating index. Status: ACTIVE
Done creating index
When your index is ready it will provide an ID 3311b507-bfef-4e2b-bde9-7c297b1fd13b on the response. Your index ID will be different than the ID in this post.
Adding attributes to the Amazon Kendra index
If you have metadata attributes associated with your SharePoint Online documents, you should do the following:
- Determine the Amazon Kendra attribute name you want for each of your SharePoint Online metadata attributes. By default, Amazon Kendra has six reserved fields (
_category, created_at, _file_type, _last_updated_at, _source_uri, and _view_count).
- Update the Amazon Kendra index with the Amazon Kendra attribute names.
- Map each SharePoint Online metadata attribute to each Amazon Kendra metadata attribute.
If you have the metadata attribute Topic associated with your SharePoint Online document, and you want to use the same attribute name in the Amazon Kendra index, the following code adds the attribute Topic to your Amazon Kendra index:
try:
update_response = kendra.update_index(
Id='3311b507-bfef-4e2b-bde9-7c297b1fd13b',
RoleArn='arn:aws:iam::<YOUR ACCOUNT NUMBER>-NUMBER:role/service-role/AmazonKendra-us-east-1-KendraRole',
DocumentMetadataConfigurationUpdates=[
{
'Name': 'Topic',
'Type': 'STRING_VALUE',
'Search': {
'Facetable': True,
'Searchable': True,
'Displayable': True
}
}
]
)
except ClientError as e:
print('%s' % e)
pprint.pprint(update_response)
If everything goes well, we receive a 200 response:
{'ResponseMetadata': {'HTTPHeaders': {'content-length': '0',
'content-type': 'application/x-amz-json-1.1',
'date': 'Mon, 20 Jul 2020 20:17:07 GMT',
'x-amzn-requestid': '3eba66c9-972b-4757-8d92-37be17c8f8a2},
'HTTPStatusCode': 200,
'RequestId': '3eba66c9-972b-4757-8d92-37be17c8f8a2',
'RetryAttempts': 0}}
}
Providing the SharePoint Online credentials
You also need to have GetSecretValue for your secret stored in Secrets Manager.
If you need to create a new secret in Secrets Manager to store the SharePoint Online credentials, make sure the role you use has permissions to create a secret and tagging. See the following policy code:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "SecretsManagerWritePolicy",
"Effect": "Allow",
"Action": [
"secretsmanager:UntagResource",
"secretsmanager:CreateSecret",
"secretsmanager:TagResource"
],
"Resource": "*"
}
]
}
To create a secret on Secrets Manager, enter the following code:
secretsmanager = boto3.client('secretsmanager')
SecretName = <YOUR SECRETNAME>
SharePointCredentials = "{'username': <YOUR SHAREPOINT SITE USERNAME>, 'password': <YOUR SHAREPOINT SITE PASSWORD>}"
try:
create_secret_response = secretsmanager.create_secret(
Name=SecretName,
Description='Secret for a Sharepoint data source connector',
SecretString=SharePointCredentials,
Tags=[
{
'Key': 'Project',
'Value': 'SharePoint Test'
}
]
)
except ClientError as e:
print('%s' % e)
pprint.pprint(create_secret_response)
If everything went well, you get a response with your secret’s ARN:
{'ARN': <YOUR SECRETS ARN>,
'ResponseMetadata': {'HTTPHeaders': {'connection': 'keep-alive',
'content-length': '159',
'content-type': 'application/x-amz-json-1.1',
'date': 'Wed, 22 Jul 2020 16:05:32 GMT',
'x-amzn-requestid': '3d0ac6ff-bd32-4d2e-8107-13e49f070de5'},
'HTTPStatusCode': 200,
'RequestId': '3d0ac6ff-bd32-4d2e-8107-13e49f070de5',
'RetryAttempts': 0},
'VersionId': '7f7633ce-7f6c-4b10-b5b2-2943dd3fd6ee'}
Creating the SharePoint Online data source
Your Amazon Kendra index is up and running and you have established the attributes that you want to map to our SharePoint Online document’s attributes.
You now need an IAM role with Kendra:BatchPutDocument and kendra:BatchDeleteDocument permissions. For more information, see IAM roles for Microsoft SharePoint Online data sources. We use the ARN for this IAM role when invoking the CreateDataSource API.
Make sure the role you use for your data source connector has a trust relationship with Amazon Kendra. See the following code:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "kendra.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
The following code is the policy structure used:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue"
],
"Resource": [
"arn:aws:secretsmanager:region:account ID:secret:secret ID"
]
},
{
"Effect": "Allow",
"Action": [
"kms:Decrypt"
],
"Resource": [
"arn:aws:kms:region:account ID:key/key ID"
]
},
{
"Effect": "Allow",
"Action": [
"kendra:BatchPutDocument",
"kendra:BatchDeleteDocument"
],
"Resource": [
"arn:aws:kendra:region:account ID:index/index ID"
],
"Condition": {
"StringLike": {
"kms:ViaService": [
"kendra.amazonaws.com"
]
}
}
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:aws:s3:::bucket name/*"
]
}
]
}
The following code is my role’s ARN:
arn:aws:iam::<YOUR ACCOUNT NUMBER>:role/Kendra-Datasource
Following the least privilege principle, we only allow our role to put and delete documents in our index and read the secrets to connect to our SharePoint Online site.
When creating a data source, you can specify the sync schedule, which indicates how often your index syncs with the data source we create. This schedule is defined on the Schedule key of our request. You can use schedule expressions for rules to define how often you want to sync your data source. For this use case, the ScheduleExpression is 'cron(0 11 * * ? *)', which sets the data source to sync every day at 11:00 AM.
I use the following code. Make sure you match your SiteURL and SecretARN, as well as your IndexID. Additionally, FieldMappings is where you map between the SharePoint Online attribute name and the Amazon Kendra index attribute name. I use the same attribute name in both, but you can name the Amazon Kendra attribute whatever you’d like.
print('Create a data source')
SecretArn= <YOUR SHAREPOINT ONLINE USER AND PASSWORD SECRETS ARN>
SiteUrl = <YOUR SHAREPOINT SITE URL>
DSName= <YOUR NEW DATA SOURCE NAME>
IndexId= <YOUR INDEX ID>
DSRoleArn= <YOUR DATA SOURCE ROLE>
ScheduleExpression='cron(0 11 * * ? *)'
try:
datasource_response = kendra.create_data_source(
Name=DSName,
IndexId=IndexId,
Type='SHAREPOINT',
Configuration={
'SharePointConfiguration': {
'SharePointVersion': 'SHAREPOINT_ONLINE',
'Urls': [
SiteUrl
],
'SecretArn': SecretArn,
'CrawlAttachments': True,
'UseChangeLog': True,
'FieldMappings': [
{
'DataSourceFieldName': 'Topic',
'IndexFieldName': 'Topic'
},
],
'DocumentTitleFieldName': 'Title'
},
},
Description='My SharePointOnline Datasource',
RoleArn=DSRoleArn,
Schedule=ScheduleExpression,
Tags=[
{
'Key': 'Project',
'Value': 'SharePoint Test'
}
]
)
pprint.pprint(datasource_response)
print('Waiting for Kendra to create the DataSource.')
datasource_id = datasource_response['Id']
while True:
# Get index description
datasource_description = kendra.describe_data_source(
Id=datasource_id,
IndexId=IndexId
)
# If status is not CREATING quit
status = datasource_description["Status"]
print(" Creating index. Status: "+status)
if status != "CREATING":
break
time.sleep(60)
except ClientError as e:
print('%s' % e)
At this point, you should receive a 200 response:
Create a data source
{'Id': '527ac6f7-5f3c-46ec-b2cd-43980c714bf7',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '45',
'content-type': 'application/x-amz-json-1.1',
'date': 'Mon, 20 Jul 2020 15:26:13 GMT',
'x-amzn-requestid': '30480044-0a86-446c-aadc-f64acb4b3a86'},
'HTTPStatusCode': 200,
'RequestId': '30480044-0a86-446c-aadc-f64acb4b3a86',
'RetryAttempts': 0}}
Syncing the data source
Even though you defined a schedule for syncing the data source, you can sync on demand by using start_data_source_sync_job:
DSId=<YOUR DATA SOURCE ID>
IndexId=<YOUR INDEX ID>
try:
ds_sync_response = kendra.start_data_source_sync_job(
Id=DSId,
IndexId=IndexId
)
except ClientError as e:
print('%s' % e)
pprint.pprint(ds_sync_response)
The response should look like the following code:
{'ExecutionId': '6574acd6-e66f-4797-85cf-278dce9256b4',
'ResponseMetadata': {'HTTPHeaders': {'content-length': '54',
'content-type': 'application/x-amz-json-1.1',
'date': 'Mon, 20 Jul 2020 15:54:24 GMT',
'x-amzn-requestid': '415547b2-d095-4501-b6ad-eba4b731d109'},
'HTTPStatusCode': 200,
'RequestId': '415547b2-d095-4501-b6ad-eba4b731d109',
'RetryAttempts': 0}}
Testing
Finally, you can query your index. See the following code:
response = kendra.query(
IndexId='3311b507-bfef-4e2b-bde9-7c297b1fd13b',
QueryText='Is there a service that has 11 9s of durability?')
if response['TotalNumberOfResults'] > 0:
print(response['ResultItems'][0]['DocumentExcerpt']['Text'])
print("More information: "+response['ResultItems'][0]['DocumentURI'])
else:
print('No results found, please try a different search term.')
You will get a result like the following code:
Amazon S3 has a data durability of 11 nines.
For transactional data storage, customers have the option to take advantage of the fully
managed Amazon Relational Database Service (Amazon RDS) that supports Amazon
Aurora, PostgreSQL, MySQL, MariaDB, Oracle, and Microsoft SQL Server with high
More information: https://juansdomain.sharepoint.com/sites/AWSWhitePapers/Shared%20Documents/real-time_communication_aws.pdf
Common errors
Each of the errors noted in this section can occur if you’re using the Amazon Kendra console or the Amazon Kendra API.
You should look at the CloudWatch logs and error messages returned on the Amazon Kendra console or via the Amazon Kendra API. The CloudWatch logs help you determine the reason for a particular error, whether you are experiencing it using the console or programmatically.
Common errors when trying to access SharePoint Online as a data source are:
- Secrets Manager errors
- SharePoint credential errors
- IAM role errors
- URL errors
In the following sections, we provide more details on how to address each error.
Secrets Manager errors
You might get an error message from the Secrets Manager stating that your role doesn’t have permissions to retrieve the secrets value. This can occur when you create a new secret manager and you don’t add read permissions to the data source role.
Here’s an example of the error message:
Create a DataSource
('An error occurred (ValidationException) when calling the CreateDataSource '
'operation: Secrets Manager throws the exception: User: '
'arn:aws:sts::<YOUR ACCOUNT NUMBER>:assumed-role/Kendra-Datasource/DataSourceConfigurationValidator '
'is not authorized to perform: secretsmanager:GetSecretValue on resource: '
<YOUR SECRET ARN> '(Service: AWSSecretsManager; Status Code: 400; Error Code: '
'AccessDeniedException; Request ID: 886ff6ac-f8f3-46b0-94dc-8286fd1682c1; '
'Proxy: null)')
To address this, you need to make sure that our role has a policy attached to with GetSecretValue permissions on the secret.
If you’re troubleshooting on the console, complete the following steps:
- On the Secrets Manager console, copy the secret ARN.
The secret ARN is listed in the Secret details section. See the following screenshot.

- On the IAM console, choose Roles.
- Search for the role associated with Amazon Kendra.

- Choose the role that you assigned to the data source.
- Choose Add inline policy.

- For Select Service, choose Secrets Manager.
- On the visual editor, on the Access Level, choose Read.
- Choose GetSecretValue.
- Under Resources, select Specific.
- Choose Add ARN.
- For Specify ARN for secret, enter the secret ARN you copied.


- Review and choose Create Policy.

You can now go back to your Amazon Kendra data source setup and finish the process.
SharePoint credential errors
Another common issue can be caused by a failure to crawl the site. On the sync details, the error message may say something about invalid URLs. To dive deeper into the issue, select the error message.

This takes you to the CloudWatch console, where you can enter a query on the latest logs and choose Run Query.

The results appear on the Logs tab.
You can see three records matching the logStream generated by the data source sync job.

For the first document, the error message is “The URLs specified in the data source configuration aren’t valid. The URLs should be either a SharePoint site or list. Check the URLs and try the request again.”

However, it’s interesting to notice that this is the last generated message. let’s see what Document #2 shows us:

You may receive an invalid URL for the data source configuration that is triggered because of an underlying authentication problem.
The easiest way to address this issue is to generate new credentials for the Amazon Kendra crawler.
- To set up a user for the crawler to run, log in to your SharePoint Online configuration and open the Microsoft 365 Admin page.

- In the User management section, choose Add user.

- Fill in the form with the details for the crawler.

For this use case, you don’t need to assign a license for this user.

- Set it up as a user without admin center access.

- After you create the user, record the generated password because you need to modify it later.

- We can now go back to our site and choose the members icon on the top right of the screen.

- To add a member, choose Add members.

- Add the new user you just created and choose Save.

- From the drop-down menu under the new user’s name, choose Owner.

IAM role issues
Another common issue is caused by lack of permissions for the IAM role used to crawl your data source.
You can identify this issue on the CloudWatch logs. See the following code:
{
"CrawlStatus": "ERROR",
"ErrorCode": "InvalidRequest",
"ErrorMessage": "Amazon Kendra can't run the BatchDeleteDocument action with the
specified role. Make sure that the role grants
the kendra:BatchDeleteDocument permission."
}
The permissions needed for this task are BatchPutDocument and BatchDeleteDocument.

Make sure that the resource matches your index ID (you can find your index ID on the index details page on the console).

Wrong SharePoint site URL
You may experience an error stating you need to provide a sharepoint.com URL. Make sure your site URL is under sharepoint.com.

Conclusion
You have now learned how to ingest the documents from your SharePoint Online site into your Amazon Kendra Index, either through the console or programmatically. In this example case, you have loaded some AWS Whitepapers into your index. You are now able to run some queries such as “What AWS service has 11 nines of durability?

Finally, don’t forget to check the other blog posts about Amazon Kendra!
About the Author
 Juan Pablo Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.
Juan Pablo Bustos is an AI Services Specialist Solutions Architect at Amazon Web Services, based in Dallas, TX. Outside of work, he loves spending time writing and playing music as well as trying random restaurants with his family.

David Shute is a Senior ML GTM Specialist at Amazon Web Services focused on Amazon Kendra. When not working, he enjoys hiking and walking on a beach.
Read More
 Every day there is something new going on in the world of AWS Machine Learning—from launches to new use cases to interactive trainings. We’re packaging some of the not-to-miss information from the ML Blog and beyond for easy perusing each month. Check back at the end of each month for the latest roundup.
Every day there is something new going on in the world of AWS Machine Learning—from launches to new use cases to interactive trainings. We’re packaging some of the not-to-miss information from the ML Blog and beyond for easy perusing each month. Check back at the end of each month for the latest roundup.
 Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.
Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.