
Every day there is something new going on in the world of AWS Machine Learning—from launches to new use cases like posture detection to interactive trainings like the AWS Power Hour: Machine Learning on Twitch. We’re packaging some of the not-to-miss information from the ML Blog and beyond for easy perusing each month. Check back at the end of each month for the latest roundup.

See use case section for how to build a posture tracker project with AWS DeepLens
Launches
As models become more sophisticated, AWS customers are increasingly applying machine learning (ML) prediction to video content, whether that’s in media and entertainment, autonomous driving, or more. At AWS, we had the following exciting July launches:
- On July 9, we announced that SageMaker Ground Truth now supports video labeling. The National Football League (NFL) has already put this new feature to work to develop labels for training a computer vision system that tracks all 22 players as they move on the field during plays. Amazon SageMaker Ground Truth reduced the timeline for developing a high-quality labeling dataset by more than 80%.
- On July 13, we launched the availability of AWS DeepRacer Evo and Sensor Kit for purchase. AWS DeepRacer Evo is available for a limited-time, discounted price of $399, a savings of $199 off the regular bundle price of $598, and the AWS DeepRacer Sensor Kit is available for $149, a savings of $100 off the regular price of $249. AWS DeepRacer is a fully autonomous 1/18th scale race car powered by reinforcement learning (RL) that gives ML developers of all skill levels the opportunity to learn and build their ML skills in a fun and competitive way. AWS DeepRacer Evo includes new features and capabilities to help you learn more about ML through the addition of sensors that enable object avoidance and head-to-head racing. Both items are available on com for shipping in the US only.
- On July 23, we announced that Contact Lens for Amazon Connect is now generally available. Contact Lens is a set of capabilities for Amazon Connect enabled by ML that gives contact centers the ability to understand the sentiment, trends, and compliance of customer conversations to improve their experience and identify crucial feedback.
- As of July 28, Amazon Fraud Detector is now generally available. Amazon Fraud Detector is a fully managed service that makes it easy to identify potentially fraudulent online activities such as online payment fraud and the creation of fake accounts. It uses your data, ML, and more than 20 years of fraud detection expertise from Amazon to automatically identify potentially fraudulent online activity so you can catch more fraud faster.
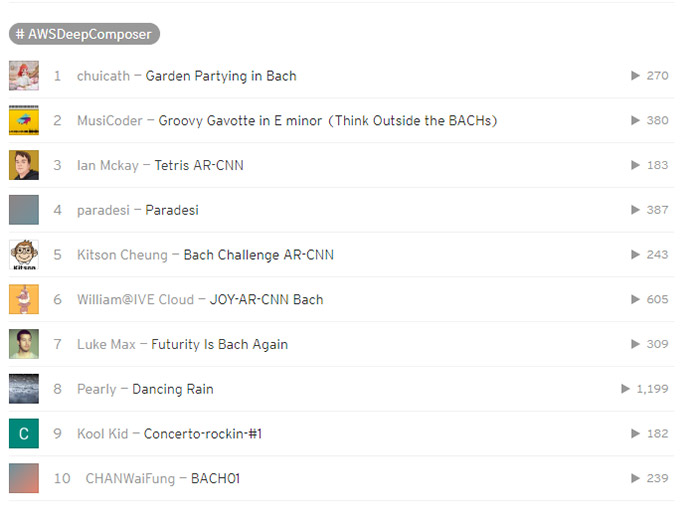
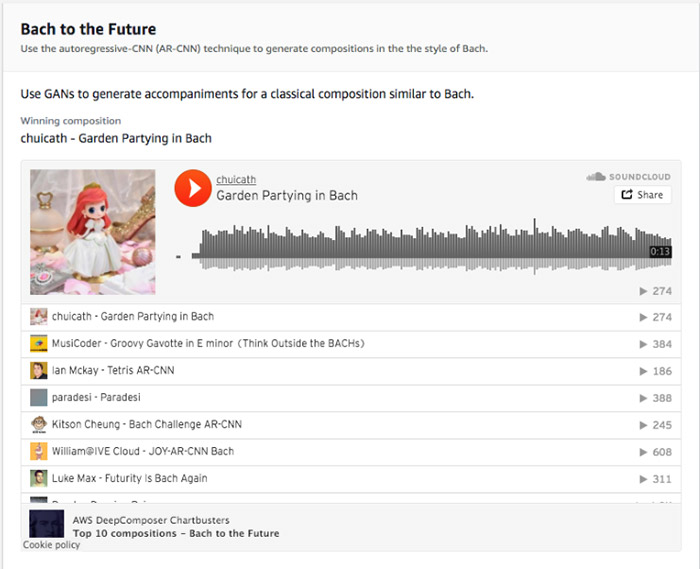
- Develop your own custom genre model to create AI-generated tunes in our latest AWS DeepComposer Chartbusters Challenge, Spin the Model. Submit your entries by 8/23 & see if you can top the #AI charts on SoundCloud for a chance to win some great prizes.
Use cases
Get ideas and architectures from AWS customers, partners, ML Heroes, and AWS experts on how to apply ML to your use case:
- AWS Machine Learning Hero Cyrus Wong shares how he developed Callouts, a simple, consistent, and scalable solution for educators to communicate with students using Amazon Connect and Amazon Lex. Learn how you can build your own scalable outbound call engine.
- The products Atlassian builds have hundreds of developers working on them, composed of a mixture of monolithic applications and microservices. When an incident occurs, it can be hard to diagnose the root cause due to the high rate of change within the code bases. Learn how implementing Amazon CodeGuru Profiler has enabled Atlassian developers to own and take action on performance engineering.
- Given the shift in customer trends to audio consumption, Amazon Polly launched a new speaking style focusing on the publishing industry: the Newscaster speaking style. Learn how the Newscaster voice was built and how you can use the Newscaster voice with your content in a few simple steps.
- Personalized recommendations can help improve customer engagement and conversion. Learn how Pulselive, a digital media sports technology company, increased video consumption by 20% with Amazon Personalize.
- Working from home can be a big change to your ergonomic setup, which can make it hard for you to keep a healthy posture and take frequent breaks throughout the day. To help you maintain good posture and have fun with ML in the process, you can build a posture tracker project with AWS DeepLens, the AWS programmable video camera for developers to learn ML.
Explore more ML stories
Want more news about developments in ML? Check out the following stories:
- Formula 1 Pit Strategy Battle – Take a deep dive into how the Amazon ML Solutions Lab and Professional Services Teams worked with Formula 1 to build a real-time race strategy prediction application using AWS technology that brings pit wall decisions to the viewer, and resulted in the Pit Strategy Battle graphic. You can also learn how a serverless architecture can provide ML predictions with minimal latency across the globe, and how to get started on your own ML journey.
- Fairness in AI – At the seventh Workshop on Automated Machine Learning (AutoML) at the International Conference on Machine Learning, Amazon researchers won a best paper award for the paper “Fair Bayesian Optimization.” The paper addresses the problem of ensuring the fairness of AI systems, a topic that has drawn increasing attention in recent years. Learn more about the research findings at Amazon.Science.
Mark your calendars
Join us for the following exciting ML events:
- Have fun while learning how to build, train, and deploy ML models with Amazon SageMaker Fridays. Join our expert ML Specialists Emily Webber and Alex McClure for a live session on Twitch. Register now!
- AWS Power Hour: Machine Learning is a weekly, live-streamed program that premiered Thursday, July 23, at 7:00 p.m. EST and will air at that time every Thursday for 7 weeks.
Also, if you missed it, see the Amazon Augmented AI (Amazon A2I) Tech Talk to learn how you can implement human reviews to review your ML predictions from Amazon Textract, Amazon Rekognition, Amazon Comprehend, Amazon SageMaker, and other AWS AI/ ML services.
See you next month for more on AWS ML!
About the author
 Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.
Laura Jones is a product marketing lead for AWS AI/ML where she focuses on sharing the stories of AWS’s customers and educating organizations on the impact of machine learning. As a Florida native living and surviving in rainy Seattle, she enjoys coffee, attempting to ski and enjoying the great outdoors.






 Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.
Matt Chwastek is a Senior Product Manager for Amazon Personalize. He focuses on delivering products that make it easier to build and use machine learning solutions. In his spare time, he enjoys reading and photography.





 Abhi Sharma is a deep learning architect on the Amazon ML Solutions Lab team, where he helps AWS customers in a variety of industries leverage machine learning to solve business problems. He is an avid reader, frequent traveler, and driving enthusiast.
Abhi Sharma is a deep learning architect on the Amazon ML Solutions Lab team, where he helps AWS customers in a variety of industries leverage machine learning to solve business problems. He is an avid reader, frequent traveler, and driving enthusiast. Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.
Ryan Brand is a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction. Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.
Tatsuya Arai Ph.D. is a biomedical engineer turned deep learning data scientist on the Amazon Machine Learning Solutions Lab team. He believes in the true democratization of AI and that the power of AI shouldn’t be exclusive to computer scientists or mathematicians.















 Jyothi Nookula is a Principal Product Manager for AWS AI devices. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.
Jyothi Nookula is a Principal Product Manager for AWS AI devices. She loves to build products that delight her customers. In her spare time, she loves to paint and host charity fund raisers for her art exhibitions.







 Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with their Conversational AI strategy, architecture, and development. Shanthan has an MBA in Marketing from Duke University, MS in Management Information Systems from Oklahoma State University, and a Bachelors in Technology from Kakaitya University in India. He is also currently pursuing his third Masters in Analytics from Georgia Tech.
Shanthan Kesharaju is a Senior Architect in the AWS ProServe team. He helps our customers with their Conversational AI strategy, architecture, and development. Shanthan has an MBA in Marketing from Duke University, MS in Management Information Systems from Oklahoma State University, and a Bachelors in Technology from Kakaitya University in India. He is also currently pursuing his third Masters in Analytics from Georgia Tech. Soyoung Yoon is a Conversation A.I. Architect at AWS Professional Services where she works with customers across multiple industries to develop specialized conversational assistants which have helped these customers provide their users faster and accurate information through natural language. Soyoung has M.S. and B.S. in Electrical and Computer Engineering from Carnegie Mellon University.
Soyoung Yoon is a Conversation A.I. Architect at AWS Professional Services where she works with customers across multiple industries to develop specialized conversational assistants which have helped these customers provide their users faster and accurate information through natural language. Soyoung has M.S. and B.S. in Electrical and Computer Engineering from Carnegie Mellon University.
