Machine learning (ML) has proven to be one of the most successful and widespread applications of technology, affecting a wide range of industries and impacting billions of users every day. With this rapid adoption of ML into every industry, companies are facing challenges in supporting low-latency predictions and with high availability while maximizing resource utilization and reducing associated costs. Because each ML framework has its own dependencies, and deployment steps for each framework are different, deploying models built in different frameworks in production and managing each of the endpoints becomes more and more complex.
Amazon SageMaker multi-container endpoints (MCEs) enables us to group models on different frameworks and deploy them to the same host, creating a single endpoint. You can provide containers for the different frameworks that you’re using to build the models, and SageMaker takes all of these containers and puts them behind one endpoint. For instance, you could have a PyTorch and a TensorFlow model loaded up on two dedicated endpoints serving the same or entirely different use cases, and both of these models have intermittent incoming traffic not utilizing resources to its limit. In such a scenario, you could club them together using containers into one endpoint using an MCE, improving the resource utilization while reducing the costs incurred in having both the models serving from different endpoints.
Multi-container endpoints provide a scalable and cost-effective solution to deploy up to 15 models built on different ML frameworks, model servers, and algorithms serving the same or different use case, meaning that you can have models built on diverse ML frameworks or intermediary steps across all of these containers and models. All these models can be accessed individually via direct invocation or stitched into a pipeline using serial invocation, where the output of one model is the input for the next one.
In this post, we discuss how to perform cost-efficient ML inference with multi-framework models on SageMaker.
MCE invocation patterns
SageMaker MCE direct invocation is useful in cases where you have clubbed unrelated models into an MCE endpoint or you’re running an A/B test between the models behind an MCE endpoint to gauge their performance. You can call the specific container directly in the API call and get the prediction from that model.
With serial invocation, you can stitch together 2–15 containers, and the output of one becomes the input of the next container in sequence. This is an ideal use case if, for example, you have a multi-step prediction pipeline where a Scikit-learn model is used for an intermediate prediction and the result is fed to a TensorFlow model for final inference. Instead of having them deployed as different endpoints and another application or job orchestrating them and making multiple API calls, you can deploy them as a SageMaker MCE, abstracting the logic and setting them up for serial invocation, where SageMaker manages the data transfer between one container to another automatically and emits the output of the final container to the client making the API request.
SageMaker MCE serial invocation is fundamentally different from a SageMaker serial inference pipeline (more details in the sections below). A serial inference pipeline is targeted more to orchestrate complex ML workflows such as data preprocessing, building a model ensemble, implementing conditional checks to determine which model to invoke, or postprocessing the prediction, involving business logic before the prediction is sent out to the downstream applications. In contrast, MCE serial invocation is designed to stitch 2–14 models into a pipeline for inference, each model taking the prediction of the previous model as input.
All the containers in an MCE are always in service and in memory, so there is no cold start while invoking the endpoint. MCEs also improve endpoint utilization and improve costs because models are deployed behind one endpoint and share the underlying compute instance, instead of each model occupying individual compute resources.
Let’s look at a few use cases and see how you can use SageMaker MCEs to optimize ML inference.
Use cases for SageMaker MCEs
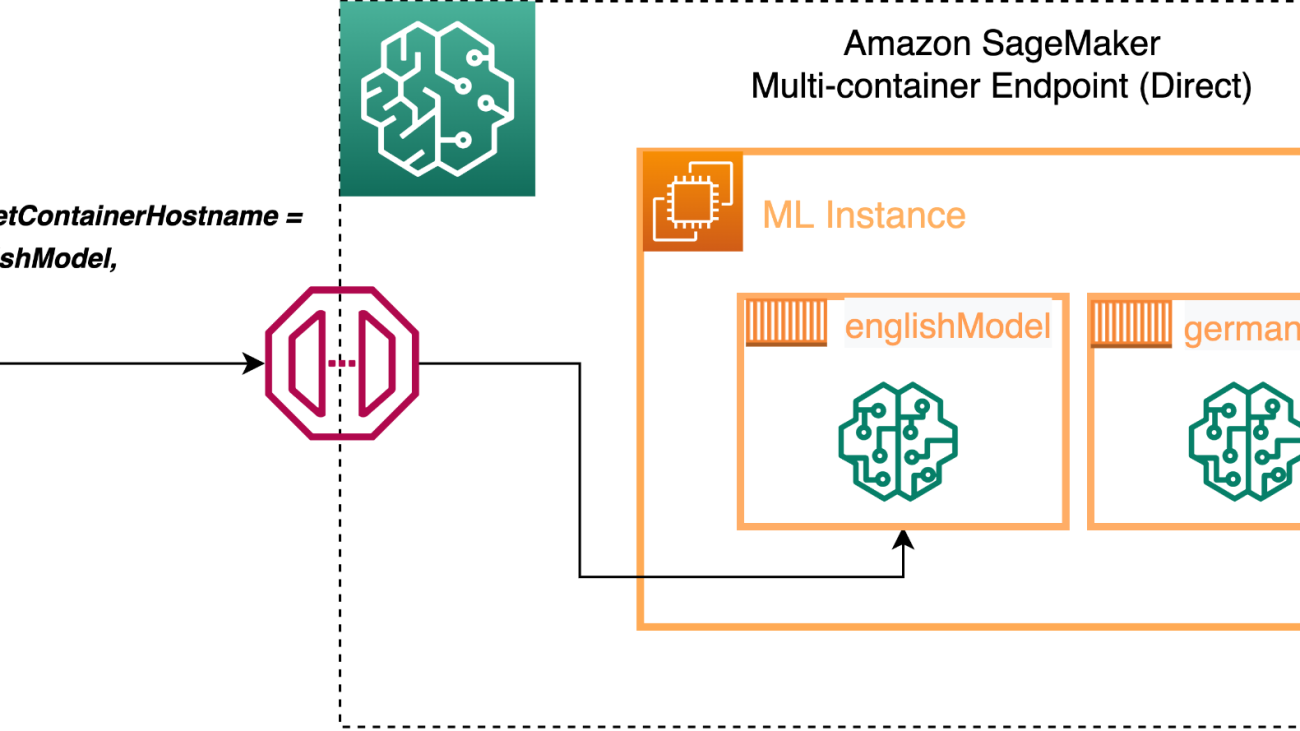
Suppose you have two models for sentiment classification, one for English language and other for German language, and these models are serving different geographies with traffic coming in at different times in a day. Instead of having two endpoints running 24/7, you can deploy both of them into one endpoint using an MCE and access them using direct invocation, thereby optimizing your resource utilization and costs. See the following code:
In this example, we have two models (englishModel and germanModel), and we define the containers in the SageMaker create_model construct and define the InferenceExecutionConfig as ‘Direct’. Now we can call the endpoint for inference and define the TargetContainerHostname as either englishModel or germanModel depending on the client making the API call:
You can also use direct invocation within the MCE to run A/B tests to compare the performance between the models.
The following diagram illustrates our architecture.

Similarly, in other ML use cases, when the trained model is used for processing a request, the model receives data in a format that needs to be preprocessed (for example, featurized) before it can be passed to the algorithm for inference. When ML algorithms are chained together, the output of one model serves as input for the next one before reaching the final result. In this case, you can build a SageMaker MCE serial pipeline, where the containers talk to each other in the sequence defined in the create_model construct instead of you deploying each of the models into different endpoints and writing an independent logic to facilitate the flow of data between all these models and API calls. The following diagram illustrates this architecture.

For this use case, we use the following code:
In this example, we have two processing containers (Processing-1 and Processing-2) for feature processing and data transformations, and two inference containers (Inference-1 and Inference-2) to run ML model predictions on the preprocessed data. The PipelineModel instance allows you to define the inference pipeline composed of a linear sequence of four containers that process requests for inference on data. The containers are co-located on the same instance, enabling you to run inference with low latency.
Scale multi-model endpoints for large numbers of models
The benefits of SageMaker multi-model endpoints increase based on the scale of model consolidation. You can see cost savings when hosting two models with one endpoint, and for use cases with hundreds or thousands of models, the savings are much greater.
Scaling the MCE endpoints is also straightforward using the SageMakerVariantInvocationsPerInstance predefined metric, which gives the average number of times per minute that each instance for a model endpoint is invoked to define a TargetScaling policy. SageMaker dynamically adjusts the number of instances provisioned for a model in response to changes in your workload. When the workload increases, autoscaling brings more instances online and loads with the target models and containers to keep up serving the requests. When the workload decreases, autoscaling removes unnecessary instances and offloads the model containers so that the containers don’t eat up the resources, and you don’t pay for instances that you aren’t using. The time to complete the first request against a given model experiences additional latency (called a cold start) to download the model from Amazon Simple Storage Service (Amazon S3) and load it into memory. Subsequent calls finish with no additional overhead because the model is already loaded. See the following code:
Following the preceding example policy configuration, we use the SageMakerVariantInvocationsPerInstance predefined metric to adjust the number of variant instances so that each instance has an InvocationsPerInstance metric of 70.
We can also scale SageMaker MCEs based on our own custom metric, such as CPUUtilization, MemoryUtilization, GPUUtilization, GPUMemoryUtilization, or DiskUtilization, to scale up or down the number of instances based on utilization of a specific resource. For more information, refer to Automatically Scale Amazon SageMaker Models.
It’s recommended that the model in each container exhibits similar compute and latency requirements on each inference request, because if traffic to the MCE shifts from a high CPU utilization model to a low CPU utilization model, but the overall call volume remains the same, the endpoint doesn’t scale out and there may not be enough instances to handle all the requests to the high CPU utilization model.
Secure MCEs
For MCEs with direct invocation, multiple containers are hosted in a single instance by sharing memory and a storage volume. It’s important to secure the containers, maintain the correct mapping of requests to target containers, and provide users with the correct access to target containers. You can restrict invoke_endpoint access to a limited set of containers inside an MCE using the sagemaker:TargetContainerHostname AWS Identity and Access Management (IAM) condition key. SageMaker uses IAM roles to provide IAM identity-based policies that you use to specify allowed or denied actions and resources and the conditions under which actions are allowed or denied. The following policies show how to limit calls to specific containers within an endpoint:
Monitor multi-model endpoints using Amazon CloudWatch metrics
To make price and performance trade-offs, you’ll want to test multi-model endpoints with models and representative traffic from your own application. SageMaker provides additional metrics in Amazon CloudWatch for multi-model endpoints so you can determine the endpoint usage and the cache hit rate and optimize your endpoint. The metrics are as follows:
- ModelLoadingWaitTime – The interval of time that an invocation request waits for the target model to be downloaded or loaded to perform the inference.
- ModelUnloadingTime – The interval of time that it takes to unload the model through the container’s
UnloadModelAPI call. - ModelDownloadingTime – The interval of time that it takes to download the model from Amazon S3.
- ModelLoadingTime – The interval of time that it takes to load the model through the container’s
LoadModelAPI call. - ModelCacheHit – The number of
InvokeEndpointrequests sent to the endpoint where the model was already loaded. Taking theAveragestatistic shows the ratio of requests in which the model was already loaded. - LoadedModelCount – The number of models loaded in the containers in the endpoint. This metric is emitted per instance. The
Averagestatistic with a period of 1 minute tells you the average number of models loaded per instance, and theSumstatistic tells you the total number of models loaded across all instances in the endpoint. The models that this metric tracks aren’t necessarily unique because you can load a model in multiple containers in the endpoint.
There are also several other metrics that are used by each container running on an instance, such as Invocations indicating the number of InvokeEndpoint requests sent to a container inside an endpoint, ContainerLatency giving the time an endpoint took for the target container or all the containers in a serial invocation to respond as viewed from SageMaker, and CPUUtilization and MemoryUtilizaton indicating the CPU units and percentage of memory.
Conclusion
In the post, we discussed how SageMaker multi-container endpoints can be helpful in optimizing costs and resource utilization. Examples of when to utilize MCEs include, but are not limited to, the following:
- Hosting models across different frameworks (such as TensorFlow, PyTorch, and Scikit-learn) that don’t have sufficient traffic to saturate the full capacity of an instance
- Hosting models from the same framework with different ML algorithms (such as recommendations, forecasting, or classification) and handler functions
- Comparisons of similar architectures running on different framework versions (such as TensorFlow 1.x vs. TensorFlow 2.x) for scenarios like A/B testing
SageMaker MCEs support deploying up to 15 containers on real-time endpoints and invoking them independently for low-latency inference and cost savings. The models can be completely heterogenous, with their own independent serving stack. You can either invoke these containers sequentially or independently for each request. Securely hosting multiple models, from different frameworks, on a single instance could save you up to 90% in cost compared to hosting models in dedicated single-instance endpoints.
About the authors
 Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Dhawal Patel is a Principal Machine Learning Architect at AWS. He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and artificial intelligence. He focuses on deep learning, including NLP and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
 Vikram Elango is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps global financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
Vikram Elango is a Senior AI/ML Specialist Solutions Architect at Amazon Web Services, based in Virginia, US. Vikram helps global financial and insurance industry customers with design and thought leadership to build and deploy machine learning applications at scale. He is currently focused on natural language processing, responsible AI, inference optimization, and scaling ML across the enterprise. In his spare time, he enjoys traveling, hiking, cooking, and camping with his family.
 Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Saurabh Trikande is a Senior Product Manager for Amazon SageMaker Inference. He is passionate about working with customers and is motivated by the goal of democratizing machine learning. He focuses on core challenges related to deploying complex ML applications, multi-tenant ML models, cost optimizations, and making deployment of deep learning models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.




















 Ana Scarolina Art
Ana Scarolina Art