Data science and data engineering teams spend a significant portion of their time in the data preparation phase of a machine learning (ML) lifecycle performing data selection, cleaning, and transformation steps. It’s a necessary and important step of any ML workflow in order to generate meaningful insights and predictions, because bad or low-quality data greatly reduces the relevance of the insights derived.
Data engineering teams are traditionally responsible for the ingestion, consolidation, and transformation of raw data for downstream consumption. Data scientists often need to do additional processing on data for domain-specific ML use cases such as natural language and time series. For example, certain ML algorithms may be sensitive to missing values, sparse features, or outliers and require special consideration. Even in cases where the dataset is in a good shape, data scientists may want to transform the feature distributions or create new features in order to maximize the insights obtained from the models. To achieve these objectives, data scientists have to rely on data engineering teams to accommodate requested changes, resulting in dependency and delay in the model development process. Alternatively, data science teams may choose to perform data preparation and feature engineering internally using various programming paradigms. However, it requires an investment of time and effort in installation and configuration of libraries and frameworks, which isn’t ideal because that time can be better spent optimizing model performance.
Amazon SageMaker Data Wrangler simplifies the data preparation and feature engineering process, reducing the time it takes to aggregate and prepare data for ML from weeks to minutes by providing a single visual interface for data scientists to select, clean, and explore their datasets. Data Wrangler offers over 300 built-in data transformations to help normalize, transform, and combine features without writing any code. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3),Amazon Athena, Amazon Redshift, and Snowflake. You can now also use Databricks as a data source in Data Wrangler to easily prepare data for ML.
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes. With Databricks as a data source for Data Wrangler, you can now quickly and easily connect to Databricks, interactively query data stored in Databricks using SQL, and preview data before importing. Additionally, you can join your data in Databricks with data stored in Amazon S3, and data queried through Amazon Athena, Amazon Redshift, and Snowflake to create the right dataset for your ML use case.
In this post, we transform the Lending Club Loan dataset using Amazon SageMaker Data Wrangler for use in ML model training.
Solution overview
The following diagram illustrates our solution architecture.
The Lending Club Loan dataset contains complete loan data for all loans issued through 2007–2011, including the current loan status and latest payment information. It has 39,717 rows, 22 feature columns, and 3 target labels.
To transform our data using Data Wrangler, we complete the following high-level steps:
Download and split the dataset.
Create a Data Wrangler flow.
Import data from Databricks to Data Wrangler.
Import data from Amazon S3 to Data Wrangler.
Join the data.
Apply transformations.
Export the dataset.
Prerequisites
The post assumes you have a running Databricks cluster. If your cluster is running on AWS, verify you have the following configured:
Databricks setup
An instance profile with required permissions to access an S3 bucket
A bucket policy with required permissions for the target S3 bucket
After the Databricks cluster is up and running with required access to Amazon S3, you can fetch the JDBC URL from your Databricks cluster to be used by Data Wrangler to connect to it.
Fetch the JDBC URL
To fetch the JDBC URL, complete the following steps:
In Databricks, navigate to the clusters UI.
Choose your cluster.
On the Configuration tab, choose Advanced options.
Under Advanced options, choose the JDBC/ODBC tab.
Copy the JDBC URL.
Make sure to substitute your personal access token in the URL.
Data Wrangler setup
This step assumes you have access to Amazon SageMaker, an instance of Amazon SageMaker Studio, and a Studio user.
To allow access to the Databricks JDBC connection from Data Wrangler, the Studio user requires following permission:
secretsmanager:PutResourcePolicy
Follow below steps to update the IAM execution role assigned to the Studio user with above permission, as an IAM administrative user.
On the IAM console, choose Roles in the navigation pane.
Choose the role assigned to your Studio user.
Choose Add permissions.
Choose Create inline policy.
For Service, choose Secrets Manager.
On Actions, choose Access level.
Choose Permissions management.
Choose PutResourcePolicy.
For Resources, choose Specific and select Any in this account.
Download and split the dataset
You can start by downloading the dataset. For demonstration purposes, we split the dataset by copying the feature columns id, emp_title, emp_length, home_owner, and annual_inc to create a second loans_2.csv file. We remove the aforementioned columns from the original loans file except the id column and rename the original file to loans_1.csv. Upload the loans_1.csv file to Databricks to create a table loans_1 and loans_2.csv in an S3 bucket.
On the Studio console, on the File menu, choose New.
Choose Data Wrangler flow.
Rename the flow as desired.
Alternatively, you can create a new data flow from the Launcher.
On the Studio console, choose Amazon SageMaker Studio in the navigation pane.
Choose New data flow.
Creating a new flow can take a few minutes to complete. After the flow has been created, you see the Import data page.
Import data from Databricks into Data Wrangler
Next, we set up Databricks (JDBC) as a data source in Data Wrangler. To import data from Databricks, we first need to add Databricks as a data source.
On the Import data tab of your Data Wrangler flow, choose Add data source.
On the drop-down menu, choose Databricks (JDBC).
On the Import data from Databricks page, you enter your cluster details.
For Dataset name, enter a name you want to use in the flow file.
For Driver, choose the driver com.simba.spark.jdbc.Driver.
For JDBC URL, enter the URL of your Databricks cluster obtained earlier.
The URL should resemble the following format jdbc:spark://<serve- hostname>:443/default;transportMode=http;ssl=1;httpPath=<http- path>;AuthMech=3;UID=token;PWD=<personal-access-token>.
In the SQL query editor, specify the following SQL SELECT statement:
select * from loans_1
If you chose a different table name while uploading data to Databricks, replace loans_1 in the above SQL query accordingly.
In the SQL query section in Data Wrangler, you can query any table connected to the JDBC Databricks database. The pre-selected Enable sampling setting retrieves the first 50,000 rows of your dataset by default. Depending on the size of the dataset, unselecting Enable sampling may result in longer import time.
Choose Run.
Running the query gives a preview of your Databricks dataset directly in Data Wrangler.
Choose Import.
Data Wrangler provides the flexibility to set up multiple concurrent connections to the one Databricks cluster or multiple clusters if required, enabling analysis and preparation on combined datasets.
Import the data from Amazon S3 into Data Wrangler
Next, let’s import the loan_2.csv file from Amazon S3.
On the Import tab, choose Amazon S3 as the data source.
Navigate to the S3 bucket for the loan_2.csv file.
When you select the CSV file, you can preview the data.
In the Details pane, choose Advanced configuration to make sure Enable sampling is selected and COMMA is chosen for Delimiter.
Choose Import.
After the loans_2.csv dataset is successfully imported, the data flow interface displays both the Databricks JDBC and Amazon S3 data sources.
Join the data
Now that we have imported data from Databricks and Amazon S3, let’s join the datasets using a common unique identifier column.
On the Data flow tab, for Data types, choose the plus sign for loans_1.
Choose Join.
Choose the loans_2.csv file as the Right dataset.
Choose Configure to set up the join criteria.
For Name, enter a name for the join.
For Join type, choose Inner for this post.
Choose the id column to join on.
Choose Apply to preview the joined dataset.
Choose Add to add it to the data flow.
Apply transformations
Data Wrangler comes with over 300 built-in transforms, which require no coding. Let’s use built-in transforms to prepare the dataset.
Drop column
First we drop the redundant ID column.
On the joined node, choose the plus sign.
Choose Add transform.
Under Transforms, choose + Add step.
Choose Manage columns.
For Transform, choose Drop column.
For Columns to drop, choose the column id_0.
Choose Preview.
Choose Add.
Format string
Let’s apply string formatting to remove the percentage symbol from the int_rate and revol_util columns.
On the Data tab, under Transforms, choose + Add step.
Choose Format string.
For Transform, choose Strip characters from right.
Data Wrangler allows you to apply your chosen transformation on multiple columns simultaneously.
For Input columns, choose int_rate and revol_util.
For Characters to remove, enter %.
Choose Preview.
Choose Add.
Featurize text
Let’s now vectorize verification_status, a text feature column. We convert the text column into term frequency–inverse document frequency (TF-IDF) vectors by applying the count vectorizer and a standard tokenizer as described below. Data Wrangler also provides the option to bring your own tokenizer, if desired.
Under Transformers, choose + Add step.
Choose Featurize text.
For Transform, choose Vectorize.
For Input columns, choose verification_status.
Choose Preview.
Choose Add.
Export the dataset
After we apply multiple transformations on different columns types, including text, categorical, and numeric, we’re ready to use the transformed dataset for ML model training. The last step is to export the transformed dataset to Amazon S3. In Data Wrangler, you have multiple options to choose from for downstream consumption of the transformations:
Export a Studio notebook that creates a SageMaker pipeline with your data flow, or a notebook that creates an Amazon SageMaker Feature Store feature group and adds features to an offline or online feature store.
Choose Export data to export directly to Amazon S3.
In this post, we take advantage of the Export data option in the Transform view to export the transformed dataset directly to Amazon S3.
Choose Export data.
For S3 location, choose Browse and choose your S3 bucket.
In this post, we covered how you can quickly and easily set up and connect Databricks as a data source in Data Wrangler, interactively query data stored in Databricks using SQL, and preview data before importing. Additionally, we looked at how you can join your data in Databricks with data stored in Amazon S3. We then applied data transformations on the combined dataset to create a data preparation pipeline. To explore more Data Wrangler’s analysis capabilities, including target leakage and bias report generation, refer to the following blog post Accelerate data preparation using Amazon SageMaker Data Wrangler for diabetic patient readmission prediction.
Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using Artificial Intelligence and Machine Learning. In his spare time, Roop enjoys reading and hiking.
Igor Alekseev is a Partner Solution Architect at AWS in Data and Analytics. Igor works with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect, he implemented many projects in Big Data, including several data lakes in the Hadoop ecosystem. As a Data Engineer, he was involved in applying AI/ML to fraud detection and office automation. Igor’s projects were in a variety of industries including communications, finance, public safety, manufacturing, and healthcare. Earlier, Igor worked as full stack engineer/tech lead.
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the user experience for SageMaker Studio. She has 13 years’ experience creating customer-obsessed and data-driven products for both enterprise and consumer spaces. In her spare time, she enjoys reading, being in nature, and spending time with her family.
Henry Wang is a software development engineer at AWS. He recently joined the Data Wrangler team after graduating from UC Davis. He has an interest in data science and machine learning and does 3D printing as a hobby.
The program offers recent PhD graduates an opportunity to advance research while working alongside experienced scientists with backgrounds in industry and academia.Read More
MIT President L. Rafael Reif recently joined Raúl Rodríguez, associate vice president of internationalization at Tecnológico de Monterrey, for a wide-ranging fireside chat about the power of education and its impact in addressing global issues, even more so in a post pandemic world.
“When I was younger, my parents used to always tell me and my brothers that we had to have an education because your education is the only thing you can bring with you, if you have to leave in a hurry,” recalled Reif, who was visiting with students and researchers on the Monterrey Tec campus at the invitation of José Antonio Fernández, chair of the board at the Tec and a member of the MIT Corporation.
Reif recounted his own experiences both academic and personal and shared his hope for a better future, emphasizing the role students will play in shaping it.
“Many think that the purpose of university is to educate and advance knowledge — education and research — and that it should stop there… but students want to do something good. They want to make an impact and help,” said Reif. “So, I think that the purpose of university is not only to educate and advance knowledge, but to help students use that knowledge to solve problems — problems facing their cities, their states, their country, their world.”
Conecta, a news site of Monterrey Tec, has additional coverage and photos from the MIT president’s visit.
Large pre-trained language models such as GPT-3, Codex, and others can be tuned to generate code from natural language specifications of programmer intent. Such automated models have the potential to improve productivity for every programmer in the world. But since the models can struggle to understand program semantics, the quality of the resulting code can’t be guaranteed.
In our research paper, Jigsaw: Large Language Models meet Program Synthesis, which has been accepted at the International Conference on Software Engineering (ICSE 2022), we introduce a new tool that can improve the performance of these large language models. Jigsaw deploys post-processing techniques that understand the programs’ syntax and semantics and then leverages user feedback to improve future performance. Jigsaw is designed to synthesize code for Python Pandas API using multi-modal inputs.
Our experience suggests that as these large language models evolve for synthesizing code from intent, Jigsaw can play an important role in improving the accuracy of the systems.
The promise, and perils, of machine-written software
Large language models like OpenAI’s Codex are redefining the landscape of programming. A software developer, while solving a programming task, can provide a description in English for an intended code fragment and Codex can synthesize the intended code in languages like Python or JavaScript. However, the synthesized code might be incorrect and might even fail to compile or run. Codex users are responsible for vetting the code before using it. With Project Jigsaw, we aim to automate some of this vetting to boost the productivity of developers who are using large language models like Codex for code synthesis.
Suppose Codex provides a code fragment to a software developer. The developer might then undertake a basic vetting by checking whether the code compiles. If it doesn’t compile, then the developer might be able to use the error messages of the compiler to repair it. Once the code eventually does compile, a typical developer will test it on an input to check whether the code is producing the intended output or not. Again, the code might fail (raise an exception or produce incorrect output) and the developer would need to repair it further. We show that this process can be completely automated. Jigsaw takes as input an English description of the intended code, as well as an I/O example. In this way, it pairs an input with the associated output, and provides the quality assurance that the output Python code will compile and generate the intended output on the provided input.
In our ICSE 2022 paper, Jigsaw: Large Language Models meet Program Synthesis, we evaluate this approach on Python Pandas. Pandas is a widely used API in data science, with hundreds of functions for manipulating dataframes, or tables with rows and columns. Instead of asking a developer to memorize the usage of all these functions, an arguably better approach is to use Jigsaw. With Jigsaw, the user provides a description of the intended transformation in English, an input dataframe, and the corresponding output dataframe, and then lets Jigsaw synthesize the intended code. For example, suppose a developer wants to remove the prefix “Name: ” from the column “country” in the table below. Using Pandas, this can be solved performing the following operation:
df['c'] = df['c'].str.replace('Name: ', '')
Figure 1: Input dataframe and output dataframe. Jigsaw removes the superfluous word “Name: ” from the column labelled “country”.
A developer who is new to Pandas will need to figure out the functions and their arguments to put together this code fragment or post the query and example to a forum like StackOverflow and wait for a good Samaritan to respond. In addition, they might have to tweak the response, at times considerably, based on the context. In contrast, it is much more convenient to provide the English query with an input-output table (or dataframe).
How Jigsaw works
Jigsaw takes the English query and pre-processes it with appropriate context to build an input that can be fed to a large language model. The model is treated as a black box and Jigsaw has been evaluated both with GPT-3 and Codex. The advantage of this design is that it enables plug-and-play with the latest and greatest available models. Once the model generates an output code, Jigsaw checks whether it satisfies the I/O example. If so, then Jigsaw is done! The model output is already correct. In our experiments, we found this happened about 30% of the time. If the code fails, then the repair process starts in a post-processing phase.
Figure 2: Inputs are pre-processed before being fed into large language models including GPT-3, Codex, and others. The post-process output is returned to the end-user for verification and editing, if necessary. The learnings are fed back into the pre-process and post-process mechanisms to improve them further.
During post-processing, Jigsaw applies three kinds of transformations to repair the code. Each of these transformations is motivated by the failure modes that we have observed in GPT-3 and Codex. Surprisingly, both GPT-3 and Codex fail in similar ways and hence Jigsaw’s post-processing to address these failure modes is useful for both.
Variable transformations
We have observed that Codex can produce output that uses incorrect variable names. For example, most publicly available code uses names like df1, df2, etc. for dataframes. So, the Codex output also uses these names. Now, if the developer uses g1, g2, etc. as dataframe names, the Codex output is probably going to use df1, df2, etc. and fail. Other times Codex confuses variable names provided to it. For instance, it produces df2.merge(df1)instead of df1.merge(df2). To fix these kinds of errors, Jigsaw replaces names in Codex generated code with all possible names in the scope until it finds a program that satisfies the I/O example. We find this simple transformation to be quite useful in many cases.
Argument transformations
Sometimes Codex generated code calls the expected API functions but with some of the arguments incorrect. For example:
a.) Query – Drop all the rows that are duplicated in column ‘inputB’
To fix such errors, Jigsaw systematically enumerates over all possible arguments, using the function and argument sequences generated by Codex as a starting point, until it finds a program that satisfies the I/O example.
AST-to-AST transformations
An AST (abstract-syntax-tree) is a representation of code in the form of a tree. Since models like Codex work at a syntactic level, they might produce code which is syntactically very close to the intended program, but some characters might be incorrect. For example:
a.) Query – Select rows of dfin where value in bar is or >60
Mistake – missing parentheses change precedence and cause exception
b.) Query – Count the number of duplicated rows in df
out = df.duplicated() # Modelout = df.duplicated().sum() # Correct
Mistake – missing required summation to get the count
To fix this failure mode, Jigsaw provides AST-to-AST transformations that are learned over time. The user would need to fix the code themselves — then the Jigsaw UI will capture the edit, generalize the edit to a more widely applicable transformation, and learn this transformation. With usage, the number of transformations increases, and Jigsaw becomes more and more effective.
Evaluation
We evaluated Codex and Jigsaw (with Codex) on various datasets and measured accuracy, which is the percentage of tasks in the dataset where the system produces the intended result. Codex gives an accuracy of about 30% out-of-the-box, which is what is expected from OpenAI’s paper as well. Jigsaw improves the accuracy to >60% and, through user feedback, the accuracy improves to >80%.
The road ahead
We have released the datasets that we used to evaluate Jigsaw in the public domain. Each dataset includes multiple tasks, where each task has an English query and an I/O example. Solving a task requires generating a Pandas code that maps the input dataframe provided to the corresponding output dataframe. We hope that this dataset will help evaluate and compare other systems. Although there are datasets where the tasks have only English queries or only I/O examples, the Jigsaw datasets are the first to contain both English queries and the associated I/O examples.
As these language models continue to evolve and become more powerful, we believe that Jigsaw will still be required for providing the guardrails and making these models viable in real-world scenarios. This is just addressing the tip of the iceberg for research problems in this area and many questions remain to be answered:
Can these language models be trained to learn semantics associated with code?
Can better preprocessing and postprocessing steps be integrated into Jigsaw? For example, we are looking at static analysis techniques to improve the post-processing.
Are I/O examples effective for other APIs apart from Python Pandas? How do we tackle scenarios where I/O examples are not available? How do we adapt Jigsaw for languages like JavaScript and general code in Python?
The developer overhead of providing an example over just providing a natural language query needs further evaluation and investigation.
These are some of the interesting directions we are pursuing. As we refine and improve Jigsaw, we believe it can play an important role in improving programmer productivity through automation. We continue to work on generalizing our experience with the Python Pandas API to work across other APIs and other languages.
Learning the complete quantile function, which maps probabilities to variable values, rather than building separate models for each quantile level, enables better optimization of resource trade-offs.Read More
In addition to GFN Thursday, it’s National Tater Day. Hooray!
To honor the spud-tacular holiday, we’re closing out March with seven new games streaming this week. And a loaded 20+ titles are coming to the GeForce NOW library in April to play — even on a potato PC, thanks to GeForce NOW.
Plus, the GeForce NOW app is available on Chromebook. Get the app today to instantly transform Chromebooks into gaming rigs capable of playing 1,000+ PC titles with and against millions of other players — without waiting for downloads, installs, patches or updates.
GeForce NOW is Your Ride or Fry
Don’t let this one sneak up on you. Play as ghosts and ghost hunters in this chaotic multiplayer hide-and-seek game.
At its roots, GeForce NOW is about playing great games. The final seven titles of March are ready to stream today. Plus, keep your eyes peeled for what’s coming to the cloud in April with 20 games revealed today and some nice surprises to be announced throughout the month.
On top of the 27 titles announced in March, an extra eight ended up coming to the cloud. Check out all the additional games that were added last month:
The Legend of Heroes: Trails of Cold Steel II (Steam)
Finally, GeForce NOW is growing. GeForce NOW Powered by ABYA Free and Priority plans are available again, but only for a limited time and while supplies last in Brazil, Argentina, Uruguay, Paraguay and Chile. Access local servers for lightning fast gameplay with the same legendary GeForce NOW experience.
We have an extra fresh challenge for you this week. Let us know your answer on Twitter or in the comments below.
write a love letter to your potato PC/device in one sentence
we’ll start: “to my ride or fry, we’ll never say goodbye “
In “Just Tech: Centering Community-Driven Innovation at the Margins,” Senior Principal Researcher Mary L. Gray explores how technology and community intertwine and the role technology can play in supporting community-driven innovation and community-based organizations. Dr. Gray and her team are working to bring computer science, engineering, social science, and communities together to boost societal resilience in ongoing work with Project Resolve. She’ll talk with organizers, academics, technology leaders, and activists to understand how to develop tools and frameworks of support alongside members of these communities.
In this episode of the series, Dr. Gray talks with Dr. Tawanna Dillahunt, Associate Professor at University of Michigan’s School of Information, Zachary Rowe, Executive Director of Friends of Parkside, and Joanna Velazquez, Campaign Manager at Detroit Action. The guests share personal experiences where community and research collaborations have been most impactful in solving problems, talk about ways that participatory research can foster equal partnerships and fuel innovation, and offer perspectives on how researchers can best work with communities to work through problems at a local level. They also discuss the role that technology plays—and doesn’t play—in their work.
Mary Gray: Welcome to the Microsoft Research Podcast series “Just Tech: Centering Community-Driven Innovation at the Margins.” I’m Mary Gray, a Senior Principal Researcher at our New England lab in Cambridge, Massachusetts. I use my training as an anthropologist and communication media scholar to study people’s everyday uses of technology. In March 2020, I took all that I’d learned about app-driven services that deliver everything from groceries to telehealth to study how a coalition of community-based organizations in North Carolina might develop better tech to deliver the basic needs and health support to those hit hardest by the pandemic. Our research together, called Project Resolve, aims to create a new approach to community-driven innovation—one that brings computer science, engineering, the social sciences, and community expertise together to accelerate the roles that communities and technologies could play in boosting societal resilience. For this podcast, I’ll be talking with researchers, activists, and nonprofit leaders about the promises and challenges of what it means to build technology with rather than for society.
[MUSIC ENDS]
My guests today are Zachary Rowe, Joanna Velazquez, and Dr. Tawanna Dillahunt. Tawanna Dillahunt is an associate professor at the University of Michigan’s School of Information, working at the intersection of human-computer interaction, environmental, economic, and social sustainability and equity. Joanna Velazquez is a campaign manager at Detroit Action, a union of black and brown low- and no-income, homeless and housing-insecure Detroiters fighting for housing and economic justice. And Zachary Rowe is the executive director of Friends of Parkside, a not-for-profit, community-based organization dedicated to working with residents and other stakeholders to better the community surrounding the Detroit public housing complex in which it’s located. Tawanna, Joanna, Zachary, welcome to the podcast.
Zachary Rowe: Why, thank you.
Tawanna Dillahunt: Thanks for having us, Mary. So glad to be here.
Joanna Velazquez: Yes. Thank you. Thank you.
Mary Gray: I’m glad you’re here. I’m glad you’re here. So, I want to start us off thinking about what you believe you’re involved in when you say you’re involved in community-based work. So I want us to start by really defining some terms and seeing the range of how we think about this work we call community-driven innovation, community engagement. I’d like to ask each of you to tell us a little bit about how you got involved in community-based work—broadly defined—not just the tech piece of it—but what brought you into community-based work? Let me start with Dr. Dillahunt.
Tawanna Dillahunt: Sure, Mary. Thanks so much for that question. Um, you know, when I think about this, I think about my upbringing in North Carolina, a very small town in North Carolina, so it was very community-focused, community-oriented, and my grandfather was a farmer. Him and his wife owned a country store in which, you know, I worked in, so they were really serving the community, creating jobs in the community. My dad was a contractor, so built a lot of the homes in our neighborhood. My mom as a retired schoolteacher, and my sister, um, wrote grants in the community as a part of a public-housing community, and she kind of brought me into that work as well. So I feel like I was born and raised in two communities. It’s a part of my DNA.
Mary Gray: Mm, I love the “part of your DNA.” So, let me turn the question to you, Zachary Rowe. What got you involved in community-based work?
Zachary Rowe: You know, that’s a great question, and I was just sort of listening to Tawanna and how my upbringing also positioned me to be involved in community-based work. For me, growing up in public housing, one of the things that I realized early on is the perception of young folks who lived in public housing. Which, you know, a lot of times, 99.9 percent of the time, you know, folks had a negative perception of kids who lived in public housing. So, I remember, my friends and I, we were not like that perception. I’m not sure why I came up with this idea to change their perception, uh, but we started to do a lot of volunteer work in the community. One of the things that was happening in the community is that we had a lot of boarded-up units, in the neighborhood, and so, you know, we connected with an adult, and he bought the paint, and we painted all the boarded-up units a single color. And when you think about it, it doesn’t really make sense, but it made a major difference in the community. It was still boarded up, it was still paint, but it made a difference, you know, and it also sent a message that people cared. Um, then we started to do other things in the neighborhood, you know, started to have parties for kids and whatnot, and we even received an award from the city council. And so, for me, just, how I got started in community work had to do with changing the perception of young folks.
Mary Gray: Mmm. So, how about you, Joanna Velazquez?
Joanna Velazquez: Yes, this is a lovely question to kick us off. You know, similar to Tawanna, I feel like this is what we bonded on a little bit as we, like, got to know each other is, like, being born into community and just knowing how valuable, like, relationships are. My mom and my sisters and I moved to Detroit when I was 5 in October of 2000, and that was a really important moment in our life because, as a single mom, it was community that got us by. It was our pretend aunts and cousins that, you know, to outsiders it’s pretend, but to us it’s real. You build these beautiful spaces that are just full of love and joy, and it’s community that did that. You know, my grandma was in the Southwest area, and, like, everyone knew her. She was the neighborhood babysitter. So just, like, having these examples that community was super important is what followed me in life, and started volunteering at a very young age, kept it going, got me through college, and now I’m here, so—
Mary Gray: So, okay. I would love to turn to each of you and just hear, what’s a project you’re working on right now or a campaign that’s important to you that you’re most excited about sharing with listeners who are tuning into this program? So let me start with you, Zachary. Can you tell us a bit about what you’re working on that you want to bring to our listeners?
Zachary Rowe: One of the projects that I’m working on is, uh, what we’re calling our Community Tech Worker project. It’s loosely modeled after the Community Health Worker project, and I’m excited because one of the things that it does for me is that it gives me the opportunity to match my love of technology with my 9-to-5 job. In my other life I have a small computer consulting business, and so I always wanted to be able to connect the two, and so the Community Tech Worker project is allowing me to be able to share, you know, my passion for technology with residents. And also, it’s doing it on a level that makes sense, so we’re meeting them where they are. I’m excited.
Mary Gray: Can you say a little bit more about who you’re meeting and where they’re at when you’re meeting them?
Zachary Rowe: So, basically, I think in order to understand, you know, the Community Tech Worker project the way I envision it, it’s probably helpful just to maybe talk about the “who” we’re talking about. So, Friends of Parkside is a small, community-based organization located in Detroit in one of the public-housing sites, uh, in Detroit called the Villages At Parkside, and it was started by residents of the housing complex, and so the who that we’re talking about is public-housing residents. And when you talk about the digital divide or the lack of sort of digital skills, I mean, you’re talking about, you know, my community, and you’re probably talking about other communities across the country. And so, what the Community Tech Worker project will allow us to do is to be able to help residents develop basic computer skills so they can turn around and help other residents. Some people call it the “train-the-trainers model” or whatnot, but for us, it’s “reach-one-to-teach-one” kind of thing.
Mary Gray: And, Tawanna, can you just share a bit about what you’re working on and, uh, what the connections are to Zachary and Joanna?
Tawanna Dillahunt: I’m very much, uh, excited about the Community Tech Workers project for the same reason that Zachary mentioned, um, except I’m kind of a full-time professor, and I’m able to combine my passion of the community with, you know, my kind of full-time job, so I see, uh, the Community Tech Workers project as an opportunity to create a new position within a community that hopefully we can sustain over the long-term. Our team imagines that perhaps, you know, those Community Tech Workers who want to pursue a longer-term career in, let’s say, technology can train as a Community Tech Worker and then, you know, move onto maybe even, uh, jobs in IT, and then again, with the train-the-trainer model, have more tech workers who are embedded in the community, and so we’ve, you know, extended this project to, uh, support entrepreneurs, uh, so Professor Julie Hui and I are partnering with Detroit Neighborhood Entrepreneurs Project at, uh, Michigan and creating, again, capacity in the community—more tech workers to support small business owners who might need support with their businesses. I’ll add, uh, the work that, you know, we’ve done with Joanna and Detroit Action is really thinking about models and mechanisms to create opportunities for the community to imagine ways in which technology can support them. So imagining a future. It could be utopian future. It could be, you know, in our activity, we also did dystopian futures. And thinking about what are the community values, and what are the community strengths, and what are opportunities for technology to leverage both strengths and values to move toward the futures that the community imagines? So this is a way to bring the community’s perceptions into what technology can do, instead of kind of enforcing our technologist lens, you know, what we think might be nice. But it’s a way to bring the voices of the community in, uh, to our process.
Mary Gray: Joanna, would you tell us a little bit about work that you’re doing?
Joanna Velazquez: Yes. Yes, yes, yes. Actually, I want to pick it up a little bit, uh, from work between Tawanna and I, covering the Alternative Economy series. That five-week series was so incredible, and like Tawanna had said, it allowed folks to vision, and it allowed folks to imagine: what would they want if they could get their most perfect world where their needs were met and, you know, folks around them had what they needed as well? We created a space to meet folks where they’re at but also, like, ” Let’s think together. Let’s imagine together.” And why that’s so important and how we did that was because it activated our members to tap in into our Agenda for a New Economy, and so that’s the current work that we’ve got going on right now. I’m very excited about this campaign because it’s an entire platform that is aiming to address the root causes of poverty, the root causes of injustice, and really from a community-driven and community-organizing and civic-engagement point of view of how to get this agenda for a new economy forward. And it was because we had that visioning that we were able to continue to build with our members afterwards to allow them to guide this work, to develop this campaign, and then we launched it in December. And then, come this year, what’s really exciting is that this past Saturday, we actually just had a people’s forum, and part of the Agenda for a New Economy is getting reparations for folks who have been illegally foreclosed on due to overassessments here in the city on property taxes. And even those who are currently homeowners but still dealing with the overassessments in property taxes. We had over 700 community members call into a Zoom session this past Saturday to meet with the entire city council. These city council members were able to listen and hear directly from these impacted folks on their stories, on what they think is right, how they want compensation to look. Is it home repairs? Is it property tax credits? Is it creating systems to support families who have dealt with this crisis? You know, there’s emotional and mental trauma that is carried with this moving forward, and so it was so beautiful to see the community coming together. And so that is a part of the Agenda for a New Economy, these pieces that address the root causes, and so I’m excited to see how much more people power we can grow around this campaign to get winds that actually create change.
Mary Gray: Wow. So, I want to back up a second. Tell us a bit more about a recent collaboration where you felt technology was an important tool, but it was really the community organizing and the community engagement that was the magic of what you were doing. Let me start with you, Joanna.
Joanna Velazquez: Yeah, so, I will say, this entire pandemic experience, um, having to completely transition online, limited to only a few different times in which we were able to be in person. Like, technology has definitely shown up for us in a way that it’s allowed us to re-create our organizing infrastructure online, and still create places for folks to tap into, to help guide the work, to be directly involved with these campaigns—whether it’s to vision with us and spend time in our committee meetings. It’s allowed us to maintain our infrastructure, and I will say, like, that’s the biggest plus to it. And it’s even allowed us to tap into folks that maybe were only living online. Definitely a big learning lesson is, like, how do we continue to create online spaces? Digital organizing was a part of our work before, but it’s definitely become much more center to the way that we’re reaching folks and how we’re thinking about reaching folks and the intentionality that comes behind it. But I will say, the magic comes from the fact that when in those spaces, our folks are able to tap in, and so I will just say, like, technology’s biggest support has been about maintaining our infrastructure to keep meeting with folks, but it’s definitely within the meeting that the magic happens.
Mary Gray: Yeah. It’s almost, it feels like, you’re mainstreaming a way of using these tools for community action that maybe we didn’t see so deeply before. Um, Zachary, can I ask you a bit about, like, what’s a collaboration you’re involved in now that you really feel shows you the important role technology can play, but, really, its supporting role for the community organizing that you’re doing?
Zachary Rowe: Prior to sort of COVID or the COVID experience, we had limited use for technology only because, you know, our residents had limited technology. So technology really wasn’t a big component of what we do and how we do it kind of thing. We were sort of old-school, sort of the face-to-face meetings, phone calls, flyers, those kinds of things. But, when COVID hit, I mean that caused most all non-profits to have to sort of pivot and rethink the way that they sort of engaged community, and we were one of those. But I think for us it was harder because our infrastructure was not in place to actually do that, and probably even more importantly, our residents was not, you know, in a place where they sort of do that. So for us, you know, there was a lot of trying to take care of the basics. You know, do you have the Internet? Do you have a device? Do you know how to use a device? So, for us, it was a big learning curve in terms of the work, and don’t get me wrong. We’re not there yet. We’re not there yet. But we’re on the way, and you know, one of the things that Tawanna and I both talked about was the Community Tech Worker project, which came out of that, so I tell folks, “Never let a good crisis go to waste,” right? [LAUGHTER] And so within that COVID environment experience, I mean, we were able to sort of re-envision or re-imagine what this community can sort of be. Back in 2000, we actually envisioned a community where everyone had technology, everyone sort of was connected and using technology for work and for entertainment. We envisioned this—it just wasn’t possible. [LAUGHTER] The technology wasn’t there yet. And, also, I remember, you know, um, a year, year and a half ago, I actually emailed Tawanna sort of saying, “Hey, don’t you want to change the world?” And so, fortunately, she responded, and we’ve been working to at least change the world in Parkside. The magic for me is just working with residents to sort of see how they begin to realize that, yes, they can learn how to do this. Right? And sometimes it’s as simple as connecting to a Zoom meeting on their own without any help.
Mary Gray: Yeah. So, Tawanna, please share with us just what are some of these collaborations, and I can see, um, perhaps two of the co-conspirators that you work with, but maybe you want to share a bit more about what you’re working on these days that’s exciting to you.
Tawanna Dillahunt: Yeah, so definitely the most exciting projects, uh, you’ve heard about, um, from Zachary and Joanna. Um, other projects—there’s a collaboration with my, um, colleague, Professor Tiffany Veinot and a collaborator, uh, Patrick Shih at Indiana University Bloomington. I mentioned earlier that a lot of my work is around employment, and one barrier to employment is transportation. At least in Detroit, before COVID, transportation was a significant barrier. And, um, we began asking the question, you know, how are people overcoming the transportation barriers now, and how can technology amplify what it is that they’re doing already? And we thought of new models for transportation because I had done work where we onboarded people to Uber, and, um, technology was a barrier, right? They needed intermediaries to help them install the application and create a log-in account. Then some people didn’t have credit cards, right? And so, what are ways in which we can overcome those technological barriers? Again, we’re seeing this need for intermediaries. And Patrick Shih has done a lot of work with time banking, and we’ve seen how people are using time banks to share cars, share pickup trucks for moving, to, you know, get rides to the airport or to the grocery store or to healthcare appointments, or to work. So right now, we’re looking at how do we think about trust and reciprocity, and safety within a time-bank context to overcome transportation barriers? And looking at ways to update or build, you know, that, and, again, thinking about who the intermediaries might be in providing this type of support. So that’s another exciting project that I have going on.
Mary Gray: So definitely all of you innovate, you activate, you organize communities, and I’m just wondering if you could share with us what community innovation means to you. What does it look like on the ground to you? And let me maybe start with Tawanna.
Tawanna Dillahunt: Yeah, I think that’s a great question. And I think I can, start from Zachary’s, you know, introduction where he talked about being a kid and thinking about the perceptions of the kids who live in, uh, public housing, and they said, “Hey, we want to change this perception.” Innovation is painting the buildings. To me that’s innovation. Innovation is Zachary saying, “Hey, you want to change the world?” Right? Like, how do we go about building capacity in a community, right? How do we think through this Community Tech Workers, you know, concept? What does that look like, right? This is the community coming together with a challenge that they’re facing, bringing people together to work towards addressing that. No hierarchy, nothing, just sheer innovation, sheer problem-solving.
Mary Gray: I love that. I love that because I feel like you’re setting up for us that, you know, technology is really about creation, so what does it look like when people create together? So, Zachary, for you, could you just say a bit about, how do you define community innovation, especially when you’re explaining it to folks who maybe don’t see how technology would fit into that?
Zachary Rowe: So, I think, for me, just in terms of innovation, uh, one of the things that we’re always trying to do is solve problems, for the most part. Usually when you’re innovating, it’s because of something. You’re doing it for a reason. It’s not like you’re sitting there sort of saying, “Oh, well, I’m going to innovate today.” Okay, let me tell a story. Um, so, we had young—we had kids that was working with us for the summer. Every other day, they had to pass out flyers. And so they got tired of passing out flyers, and I said, “Well, if you guys can come up with a better way of getting the word out, I’m listening,” right? They came up with the idea of sending out text messages. I’m talking about 10 years ago, right? Now, the challenge with sending out text messages is that, you know, I really didn’t know a lot about sending out text messages, and also I was concerned about the cost, right? But they realized that they can use Gmail to send out text messages, because with Gmail, you use the phone number and the carrier, and it comes on your phone as a text message. For me, that was really innovative. They had a problem that they wanted to solve, which meant that they didn’t want to pass out the flyers, but they wanted to get the word out, and also there was this cost factor that they had to sort of think through, but that was really really creative, you know?
Mary Gray: I love that. And, Joanna, I wonder if you have some examples of just where you’ve seen folks innovate by really re-purposing the tools that are there, and where you see room for communities being able to set an agenda for what to do with technologies, how to re-purpose them to meet their needs.
Joanna Velazquez: It’s about, um, yeah, addressing a problem, right? Like, that’s where people get creative, is, like, something needs to happen. Every action has a reaction, right? [LAUGHTER] You know, this kind of happens a lot, but, like, really organically, right? Really organically, because, for me, it happens in a one-to-one where, like, I’m having a conversation with a member, and they’re talking to me about, you know, what’s their issue, what’s going on, you know, what’s—what’s really getting at you that you need it to change, and so our folks will share these stories, and then we’ll get to a point where it’s like, “Well, what do you want to do about it? How do we change it?” That is when we start talking about strategy. And so, I don’t know if that exactly is, like, re-purposing anything other than just, like, very critical thinking and, like, open conversation and dialogue with folks. So that to me is, like, how our folks really show and are active in, like, community innovation with the work, because it’s in a one-to-one where you are finding the real solutions to the problems—
Zachary Rowe: Mm-hmm.
Joanna Velazquez: —to the real problems that they’re actually facing.
Mary Gray: You’re bringing up for me how often, in computer science and engineering, the Holy Grail, the mantra is scale. Scale up, scale up. And what I hear you saying is, like, part of something being powerful and useful is also getting down to that nitty-gritty. It’s getting down to understanding, like, from, you know, one person at a time, the power of that change, and then you’ve got 700 people, like you were saying, showing up on a call.
Joanna Velazquez: Yeah.
Mary Gray: I mean that’s—I think that’s really powerful and an important intervention, maybe a course correction, for how we think about what success looks like when we’re engaging communities. I want to ask you all, and I wanted to direct this to Zachary and Tawanna, to maybe talk about the Community Tech Worker projects that you’re doing and the challenges—and also the opportunities—that you’re seeing coming out of that work. It strikes me as a good example of just that grappling with both how you scale but how you keep it real, where it’s meaningful scaling. So, if I could ask Zachary—would you tell us a bit about the Community Tech Worker project, and just set up for us what is it you’re trying to do? What are you aiming for? Where are there places where you’re hitting some hurdles and working through them?
Zachary Rowe: The Community Tech Worker project, for me, was an attempt to solve a problem. Um, earlier, I talked about the fact that during sort of the COVID pandemic, we realized that, you know, our residents didn’t have access to technology, and those who did have access to technology didn’t have the Internet. Uh, and if they did have the Internet, they didn’t have the skill. So the Community Tech Worker project was a way for us to begin to address those kinds of issues. One of the things that we realized is that the kind of skills that most people take for granted in terms of being able to use Zoom, being able to use email, uh, being to upload documents. I mean, for the most part, some of us take those things for granted, but there was a whole community of folks that did not have those skills, right? There was even a subpopulation that really didn’t have those skills. I’m talking about our seniors. And so what the Community Tech Worker project allowed us to do is begin to identify folks from the neighborhood who were interested in learning how to be Community Tech Workers. Now, I’m sort of saying interested in being a Community Tech Worker because we were—we did not identify the tech-y folks or the geeky folks, whatever. We sort of said, “Hey, come as you are,” and, well, we learned some—we got some lessons behind that, too, but—
Mary Gray: Okay. [LAUGHTER] You need to say a few of those lessons.
Zachary Rowe: Well, you know. Well, “Come as you are,” meaning you may not know how to turn the computer on, right? So—
Mary Gray: Yep, yep. That’s real.
Zachary Rowe: Exactly. Part of our understanding is that, “Hey, do we want to have a minimum skill level?” Like, “Hey, you got to at least know how to turn it on.” Or are we still going to look at folks—even if you don’t know how to cut it on—we still welcome you. So, we still have to figure that one out, right? But I think for me, it was important that we didn’t, like I said, identify the geeky folks who already knew how to do it because, you know, sometimes just because you know how to do it, they may not know how to teach it. Folks who are learning how to use technology for the first time is more sympathetic and more patient and more understanding of others, right? So, basically, like I said, my thing is to make sure that, uh, we work with residents to develop those basic skills, and I love how Tawanna talked about the project because she talked about this larger vision in terms of, you know, building those advanced skills. Right now, I’m just focusing on the basic skills, you know? So it’s nice to have her there sort of saying, “Hey, you know, they can do more, they can do more, they can do more.”
Tawanna Dillahunt: Yeah, I think we still need to work through this is, do we want to call it Community Tech Workers? Because for some, “tech” might be exclusive, right? They might not identify with “tech.” and so, you know, there’s a question of, who do we miss? You know, in the beginning, who felt excluded just by the way we framed, you know, this opportunity? The team definitely talked about this, um, do you need to come in with basic skillset? And just building on what Zachary said, you know, those who might not know how to turn on a computer, I mean, their strengths are—it’s the empathy, right? Because if you’re a “geek,” you might not be the best person to talk to people in patience. These are things that came out of our training, right? We need to know how to work with or speak with, you know, other community members and understand the questions that they have, and how do you identify what the problem might be. So, I mean, Zachary mentioned, you know, larger challenges. You know, I think good community work and collaborations—I mean, also as researchers, you know—when I think about collaborating with community partners, I think about sustainability, right? What happens if I’m no longer here? And even, you know, if the funding goes dry, what capacity did we build together, and how do we continue? You know, how do we continue on? So I’m thinking about, how do we sustain a role in the community? You know, maybe we call it Community Tech Workers. Maybe we call it, you know, um, Neighborhood Intermediaries. I’m not sure what we’ll call it. How does that role sustain itself? And, you know, think about funding long-term, thinking about opportunities. We’re collaborating with Community Health Workers, who, you know, need digital skills, too. I mean, arguably, we could, you know, maybe reach out to Ford Medical Center because telehealth is big. Some people are not sure how to log into tele-healthcare appointments. Or maybe online grocery delivery services would say, you know, “Maybe there’s a benefit if we had people who could support others in ordering.” If we had that, then maybe, you know, big business is always looking at revenue at the end of the day, so, like, how does this factor into there? What does building community digital capacity mean in the long-term, and how do we sustain these roles?
Mary Gray: I want to pick up that phrase you just put out there—community digital capacity. I actually want to really hold that up. I want to lift that up because community digital capacity, where I hear all of you talking about, that means boosting, lifting communities to do the work they’re doing. Like, I really hear that capacity building as this critical role that technologies could be playing that they haven’t really played yet. Like, we haven’t really given technologies a chance to, at least from the builder side, to fully be focused on how do we build communities’ capacity? So I’m saying this because one of the goals of the Project Resolve research that I’m doing right now that resonates with what I hear you all saying is: the goal is to think about how would you co-develop and support a coalition of community-based organizations, community healthcare workers, who have an idea of what their needs are, absolutely have an agenda, and they’re rarely ever given the chance to set that agenda when it comes to what tools are built for them to do their work and to own those tools and to fully use the data they collect as power—and that they can share with their communities. So, a big part of what we’re working on is thinking about the role of participatory action research, you know, community-based participatory design, all of these phrases we have that we throw around. I want to talk about what that looks like, because it’s—it’s really hard when you’re doing it right so—or trying to do it right. [LAUGHTER] So I would just love to hear you talk a bit about: what does that mean to you? What does that look like? Let me start with Joanna.
Joanna Velazquez: The project that Tawanna and I had did together really speaks to the way that I think about participatory research, is first things first, that I feel folks get wrong in spaces that I’m in—with campaign strategy and all this stuff is that people automatically want to go to, like, numbers and data-driven stuff and, ugh. But I just don’t understand how a conversation doesn’t bring much more—and I respect data, okay? Here’s the thing. I absolutely respect data. I don’t want to say that I don’t.
Mary Gray:[LAUGHTER] Respect the data.
Joanna Velazquez: I really do. But it’s within the lived experiences where the actual information is at. So when I think about participatory research and how that looks like in our work is, it’s absolutely by creating visioning spaces. Like, that gives us so much data by, like, what do people even care about? Like, are we even kicking up a campaign that matters? But, you know, even outside of visioning is just simply asking, like, you know, “On this question of housing, like, does that actually feel like it would meet your needs?” You know, “what are your needs?” The conversation that develops that, you know, creates that qualitative data, I think, is, like, where the magic is at. And then take that to figure out what the metrics, can, you know, support that or show where the cracks are, you know, that paints this bigger picture when we go into advocacy mode. Participatory research really starts in the conversations, in the meeting spaces, in the lived experiences that people are sharing.
Mary Gray: Ooh. Ooh, I love that. I love that in so many ways. Let me ask the same question to you, um, let me start with Tawanna. Especially knowing how computer science and engineering and particularly, um, human-centered design, human-computer interaction strives to think about participation, participatory design as what we should aim for, what does it mean to you, and how does it get rough when you’re in the thick of it?
Tawanna Dillahunt: Yeah. Um, you know, in our field, when we talk about participatory design, I think there’s an inherent outcome or expectation that we’re going to have a product or tangible output, like a user interface or some application. When I think about community-based participatory research, which comes out of the public health field, we’re thinking about the community, we’re equitable partners in the research, and we’re not really engaging unless there is a common goal, right? When I engage, you know, with the community, you know, I’m interested in creating jobs, interested in employment. Are there other organizations that are interested in, you know, new economies, new digital economies, or anyone else, who cares about, you know, access to healthy food or transportation? And you’re partnering because you have the same North Star, right?
Mary Gray: Mm-hmm.
Tawanna Dillahunt: And in this partnership, you know, you figure out, “Okay, here’s the general direction.” You might not have the exact—like, researchers come in with research questions, you know, and—
Mary Gray:[LAUGHTER] Yes.
Tawanna Dillahunt: —then you can say, “Well, yeah, if you address this research question, that’ll definitely be beneficial. It’ll help us, you know, understand these—these other things that we’re trying to get to,” but that’s not necessarily our core. We like it, but it might not be our core. And then when you’re engaging in community-based participatory research, it is a long-term process, right? You’re planning ahead. As a researcher, you have to address the research questions. We need to think about how this—how we can leverage these insights maybe to inform, you know, technology, but it’s not necessarily the outcome. Maybe we’re exploring existing technologies and exploring it in the context of a time bank, right? What changes need to be made to a time bank in order address the transportation needs of transportation-insecure communities, rural communities, that kind of thing? And so, that’s what, you know, community-based participatory research means to me, which is a little bit different from user-centered design and participatory design because you’re really going in with the technology-first approach.
Mary Gray: Yeah. No, and I feel like we’ve been discovering in our work, really, the first grant is about building trust, because there’s no reason anybody should trust anybody from coming outside of their communities, especially if they’re at all at the margins. And if we’re coming from a university and we don’t lead with, “How can I help you?” first, it understandably can create even more barriers. So yeah, I don’t think we give ourselves enough room to say, “The first stretch of time is let’s get to know each other and give you a reason to participate in anything I’m bringing.” So I want to ask Zachary—could you just tell us about the Detroit Urban Research Center and your definition of community-based participatory action research?
Zachary Rowe: Yeah. So, the Detroit UR—well, we call it the Detroit URC—um, for short. Um, so, basically, the Detroit URC, uh, started back in 1995 and in a nutshell, the URC focused on fostering health equity through community-based participatory research. Years ago, I didn’t really see the point of research or data, really. It is not that it wasn’t important. It was just how it was introduced to the community. Uh, and so, we were introduced to research by sort of the traditional research approach where you had researchers coming to the community, pretty much have their way or do whatever they wanted, and leave, right? They rarely shared the data. They rarely, you know, asked us any questions. They rarely involved the community. So, basically, they would come in with their survey, with their questions, get their answers, and leave. We won’t hear from them again until the next project, right? And so, to be honest, we were pretty much soured on the whole idea of research for years until, you know, folks from the University of Michigan School of Public Health, you know, came to Detroit talking to community groups about this thing called CBPR. Uh, we’d never heard of it before, but we was intrigued by the fact that whole idea behind CBPR is that the community partners are equal partner in the research, from developing the initial research question to disseminating the results, and everything in between. And so this was a different way of doing research that really appealed to community partners. You know, it definitely appealed to us, uh, because we were at the table—sometimes agreeing and sometimes disagreeing with some of the research stuff, but that was okay, though, because we were all equal partners. Um, you know, I value research now, but I value CBPR research more than others, though, just because we’re at the table, right?
Mary Gray: Hmm. Tawanna, did you want to jump in?
Tawanna Dillahunt: No, I totally agree. I remember, um, sharing with my class, uh, last year Zachary’s video [LAUGHTER] on, uh, community-based participatory research where he—I think we’re at a potluck together, and—you know, you bring your own dish, and—and everybody else brings their dishes, and we can enjoy a meal together. If you don’t like the greens, you know, you can stay away from the greens, you know, but we’re all eating here. Like, I thought Zachary was going to go there. I love that analogy.
Zachary Rowe: Okay. Well, thank you.
Mary Gray: We’ll just have to make sure that link’s available. [LAUGHTER] I think that would be a great thing to put on the podcast. And I want to bring up what I feel like we have to talk about, and I was going to ask Joanna if you would maybe lead us off in thinking about how power differentials factor into this work. For example, I’m a white woman working with a group of predominantly Black and brown community members, many people undocumented, all of them doing community health. My biggest connection is my mom was a nurse, so I understand some of that world, but I would love to talk about how we strive for that sense of equality. We’re also navigating power differentials that come from our institutions. So, maybe if, yeah, you’d want to speak to that.
Joanna Velazquez: One of the values that we hold that I’ve been trained on is just, like, the people closest to the issue know their solution. The people furthest from it, you know, can theorize and get all philosophical, but it’s not coming from a lived experience. So that shows up a lot in conversations where, uh, you know, we’re trying to all get alignment, build coalition, build power, and, like, people operate differently, and people haven’t done the same type of, you know, conscious thinking or unpacking of their own internalized white supremacy or capitalism or patriarchy. Um, Detroit Action is an anti-capitalist organization, and so that comes up a lot in our work, in our strategy, in the way that we’re building with folks, because we’re all at different levels from our own perspectives. But it’s really important to hold onto the value, right, of, like, those closest to the issue know the solution, because if we stay there then it makes ego getting checked at the door just a little bit easier because we’re grounded on that same value. And so I would say, like, this comes up a lot in so many different ways, but for me, as I do my work, like I said, it has to go back to that one-to-one for me because my members are working class. My members don’t have the technological access to these meetings. They can’t always tap in really quick. And so in these one-on-ones, it’s where I can utilize their time to our best agreement, really, on, like, how to move this work forward, and it’s where their stories can guide the work, and that’s where I can build trust with them, because I work in the largest Black city of America. Like, I’m not a Black person. I cannot speak for the Black community, but what I can do is utilize my time to talk with all my members to know that their stories are guiding this work. And so that’s what I do, and that’s what I have to do, and create the meeting spaces where they can continue to guide the work, whether it’s visioning, whether it’s the committee space to make the decision, whether it’s the one-to-one because we just need to talk and I need to get your input on how this supposed to go. You know, and it comes down to that. For me, it comes down to that. That’s how we address, like, this power stuff, but it comes up in so many different ways. Um, the amount of racial scapegoating that we have to experience as a Black and brown city from our elected officials or the media for painting narratives that it’s on us to turn out for the results of some type of election, X, Y, Z. It comes up in so many different ways. We’re constantly battling it, but it’s our—I think it’s our values that keep us at least principled in our struggle, because we are going to struggle. We are going to mess up. We do need the feedback. We do need to be able to manage up, horizontally, whatever the case is. Membership is included in that. Like, it’s not just staff. So, you know, being able to at least create the safe spaces to be uncomfortable is the thing in which we are able to, like, address power dynamics in these relationships and systems.
Mary Gray: Okay, just a quick follow-up. And I’ll direct it at Tawanna and Zachary, just to be able to build on what Joanna is saying here. Where have you seen in your work this effort of putting folks closest to the problem, who have their solutions, in the driver’s seat for taking on the technology piece of that, for being able to build something that supports the solutions they already have?
Tawanna Dillahunt: Yeah. I mean, I think it goes back to co-designing. And this is kind of like once you figure out what the technology is, you’ve come up with this “solution” together, then I think that’s when the developer can step in, and it’s a matter of co-designing. It’s that agile approach where, “Okay, here’s how I understand it. Let me create this,” or “Let me conceptualize it in a prototype way, and, you know, this back-and-forth communication. Is this what we’re seeing?” This is, you know, some example of our past work when creating dream gigs with job seekers and having the job seekers see, “Oh, yeah, this is exactly what I need. And, oh, by the way, if there’s a way to connect this, can you tell us how we can access, you know, volunteer work so that we can build our skills? That would be amazing.” Right? And so, we’re building it together, you know, the co-designing and co-development, and they might not be programming, but they’re looking at the output and talking to the developer, or at least seeing the output, the outcome of the developer, and say, “Yes, this is what I was asking for,” or, “No, no, no, no, this is not what I was asking for.” But it takes a lot of work up front to get to that point, I think.
Mary Gray: So, how should researchers compensate—like, really recognize the value that community members are putting in? Like, what is a way to really, genuinely honor and compensate the contributions community members are making to development? Let me ask that of you, Zachary. Like, what’s the best way to show up?
Zachary Rowe: Well, uh, for me, I would say the best way is to ask. You know, I mean, for some, it may just be monetary. They may just want cash, or they just may want credit. I would just ask the community, “How you want your contribution to be recognized,” and be willing to do it, you know? I just want to go back to a question you asked earlier, um, power. And one of the things that I’ve learned over time is to understand the power you do have and use it, right? One thing that all research projects have in mind is the need for data, and if they’re collecting the data from the community, then that’s your power, because community folks can say, “No, we don’t want to participate.” Right? So, you know, I know that sounds kind of simplistic, but it works. [LAUGHTER]
Mary Gray: Yeah.
Zachary Rowe: And so, once you understand where you power is and you use it, then it begins to have an impact. Then also, one of the other things that I realized, our researchers that we work with are wonderful. Tawanna is wonderful, right? But it’s not Tawanna that’s the problem. Sometimes it’s the university infrastructure, right? It’s the county department. Maybe it’s, you know, maybe it’s the IRB. I mean, there are other issues that really don’t get and don’t understand why community partners are a part of the research team or why they’re on the project.
Mary Gray: So, I want to ask you, what are some future projects you’re most excited about heading into 2022? What is keeping you excited about pushing forward? Let me start with Tawanna.
Tawanna Dillahunt: Yeah. Definitely the Community Tech Workers work, and I have a student, uh, Alex Lu, who’s working on understanding residents’ perceptions of safety alongside Project Greenlight in Detroit, and so he’s going to take a photo-voice approach as a way to capture community narratives of safety and kind of exhibit these photos once we’re there, and he’s also, um, extending this to video voice, which might be a little bit more complex, but there’s a methodological understanding of how video voice might work in a community context, given that we can take videos over our phone.
Mary Gray: Wow. And how about you, Zachary? What are you excited about for 2022?
Zachary Rowe: Uh, definitely we’re excited about making sure that residents of Parkside develop those basic skills to be able to navigate the online world, right? Also, I’m excited about another project I’m working on called Deciders, whereby we’re developing an online tool that allows communities to set their own priorities.
Mary Gray: Joanna, what’s coming up in 2022?
Joanna Velazquez: 2022 is a big year. It’s a big, big year. It’s a midterm year, midterm election, so, um, maybe not necessarily excited about election season, but I’m excited to see how our members tap in and weigh in and, like Zachary said, power is simply just acting, and so how are we going to use this moment to seize our power? What are the actions we’re going to take to drive our Agenda for a New Economy forward, but also to defend Black voters? We’re a part of a coalition to defend the Black vote in Michigan. It is definitely under attack, and it’s unfortunate, but corporate actors are involved, and so we’re asking them to no longer fund these folks, um, that are putting these 39 voter suppression bills forward in the state of Michigan, which is so unfortunate, and now trying to sidestep the governor with a voter-suppression ballot initiative called Secure MI Vote. Um, “Suppress MI Vote” is what we rename it, but, yeah, there’s a lot of things that we’re tapped into this year, but definitely excited for how our members show up in this election.
Zachary Rowe: Show up and show out, right?
Joanna Velazquez: Show up and show out, you’ve got it.
Mary Gray: Thank you. Thank you, thank you.
[MUSIC STARTS OVER DIALOGUE]
Okay, I’m going to just take a second to thank the three of you for joining me today, and I want more. I hope we get to have another conversation, but thanks for sharing your work with us.
Zachary Rowe: Thank you.
Tawanna Dillahunt: Thank you.
Joanna Velazquez: Thank you for having us. Thank you. Mary Gray: And thanks to our listeners for tuning in. If you’d like to learn more about community-driven innovation, check out the other episodes in our “Just Tech” series. Also, be sure to subscribe for new episodes of the Microsoft Research Podcast wherever you listen to your favorite shows.
Imagine a pizza maker working with a ball of dough. She might use a spatula to lift the dough onto a cutting board then use a rolling pin to flatten it into a circle. Easy, right? Not if this pizza maker is a robot.
For a robot, working with a deformable object like dough is tricky because the shape of dough can change in many ways, which are difficult to represent with an equation. Plus, creating a new shape out of that dough requires multiple steps and the use of different tools. It is especially difficult for a robot to learn a manipulation task with a long sequence of steps — where there are many possible choices — since learning often occurs through trial and error.
Researchers at MIT, Carnegie Mellon University, and the University of California at San Diego, have come up with a better way. They created a framework for a robotic manipulation system that uses a two-stage learning process, which could enable a robot to perform complex dough-manipulation tasks over a long timeframe. A “teacher” algorithm solves each step the robot must take to complete the task. Then, it trains a “student” machine-learning model that learns abstract ideas about when and how to execute each skill it needs during the task, like using a rolling pin. With this knowledge, the system reasons about how to execute the skills to complete the entire task.
The researchers show that this method, which they call DiffSkill, can perform complex manipulation tasks in simulations, like cutting and spreading dough, or gathering pieces of dough from around a cutting board, while outperforming other machine-learning methods.
Beyond pizza-making, this method could be applied in other settings where a robot needs to manipulate deformable objects, such as a caregiving robot that feeds, bathes, or dresses someone elderly or with motor impairments.
“This method is closer to how we as humans plan our actions. When a human does a long-horizon task, we are not writing down all the details. We have a higher-level planner that roughly tells us what the stages are and some of the intermediate goals we need to achieve along the way, and then we execute them,” says Yunzhu Li, a graduate student in the Computer Science and Artificial Intelligence Laboratory (CSAIL), and author of a paper presenting DiffSkill.
Li’s co-authors include lead author Xingyu Lin, a graduate student at Carnegie Mellon University (CMU); Zhiao Huang, a graduate student at the University of California at San Diego; Joshua B. Tenenbaum, the Paul E. Newton Career Development Professor of Cognitive Science and Computation in the Department of Brain and Cognitive Sciences at MIT and a member of CSAIL; David Held, an assistant professor at CMU; and senior author Chuang Gan, a research scientist at the MIT-IBM Watson AI Lab. The research will be presented at the International Conference on Learning Representations.
Student and teacher
The “teacher” in the DiffSkill framework is a trajectory optimization algorithm that can solve short-horizon tasks, where an object’s initial state and target location are close together. The trajectory optimizer works in a simulator that models the physics of the real world (known as a differentiable physics simulator, which puts the “Diff” in “DiffSkill”). The “teacher” algorithm uses the information in the simulator to learn how the dough must move at each stage, one at a time, and then outputs those trajectories.
Then the “student”neural network learns to imitate the actions of the teacher. As inputs, it uses two camera images, one showing the dough in its current state and another showing the dough at the end of the task. The neural network generates a high-level plan to determine how to link different skills to reach the goal. It then generates specific, short-horizon trajectories for each skill and sends commands directly to the tools.
The researchers used this technique to experiment with three different simulated dough-manipulation tasks. In one task, the robot uses a spatula to lift dough onto a cutting board then uses a rolling pin to flatten it. In another, the robot uses a gripper to gather dough from all over the counter, places it on a spatula, and transfers it to a cutting board. In the third task, the robot cuts a pile of dough in half using a knife and then uses a gripper to transport each piece to different locations.
A cut above the rest
DiffSkill was able to outperform popular techniques that rely on reinforcement learning, where a robot learns a task through trial and error. In fact, DiffSkill was the only method that was able to successfully complete all three dough manipulation tasks. Interestingly, the researchers found that the “student” neural network was even able to outperform the “teacher” algorithm, Lin says.
“Our framework provides a novel way for robots to acquire new skills. These skills can then be chained to solve more complex tasks which are beyond the capability of previous robot systems,” says Lin.
Because their method focuses on controlling the tools (spatula, knife, rolling pin, etc.) it could be applied to different robots, but only if they use the specific tools the researchers defined. In the future, they plan to integrate the shape of a tool into the reasoning of the “student” network so it could be applied to other equipment.
The researchers intend to improve the performance of DiffSkill by using 3D data as inputs, instead of images that can be difficult to transfer from simulation to the real world. They also want to make the neural network planning process more efficient and collect more diverse training data to enhance DiffSkill’s ability to generalize to new situations. In the long run, they hope to apply DiffSkill to more diverse tasks, including cloth manipulation.
This work is supported, in part, by the National Science Foundation, LG Electronics, the MIT-IBM Watson AI Lab, the Office of Naval Research, and the Defense Advanced Research Projects Agency Machine Common Sense program.
Deep neural network (DNN) model compression for efficient on-device inference is becoming increasingly important to reduce memory requirements and keep user data on-device. To this end, we propose a novel differentiable k-means clustering layer (DKM) and its application to train-time weight clustering-based DNN model compression. DKM casts k-means clustering as an attention problem and enables joint optimization of the DNN parameters and clustering centroids. Unlike prior works that rely on additional regularizers and parameters, DKM-based compression keeps the original loss function and model…Apple Machine Learning Research













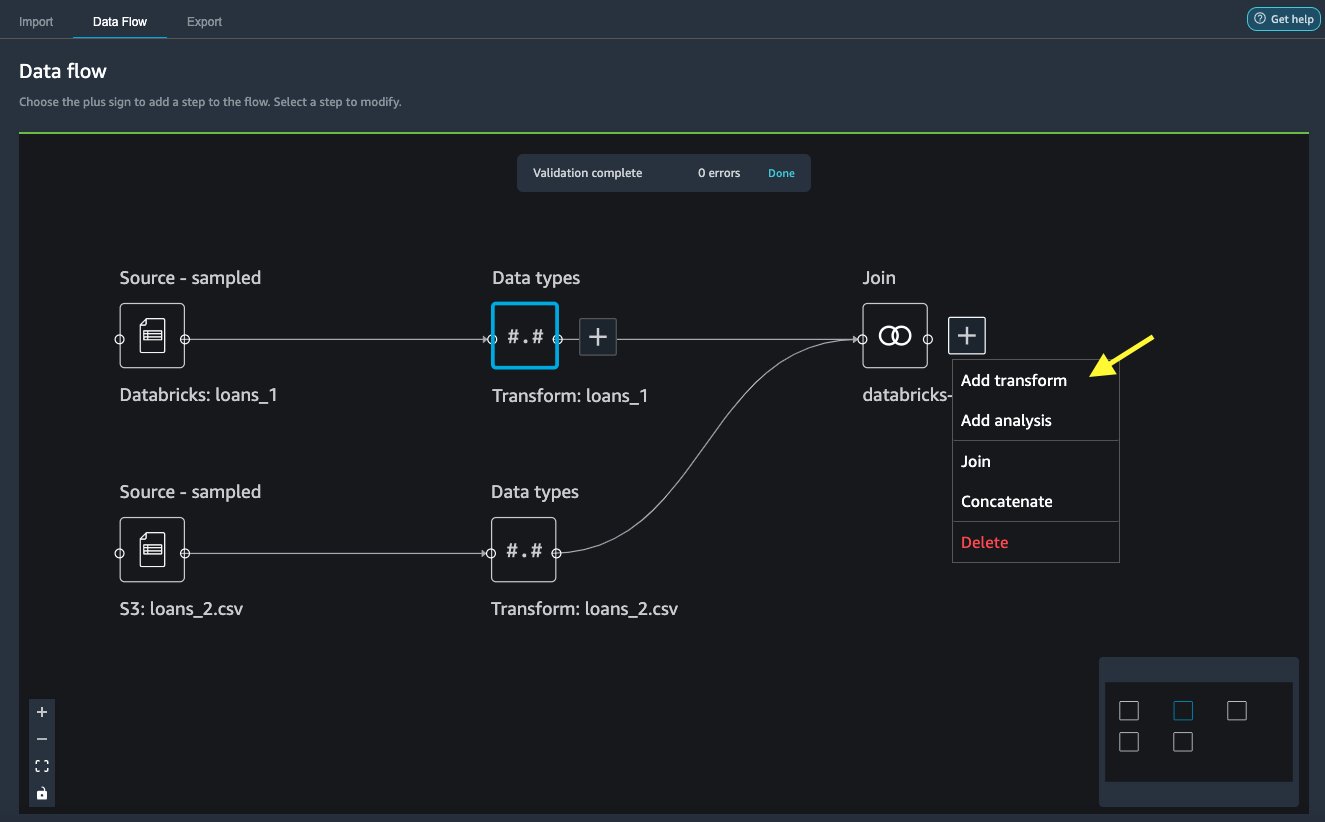



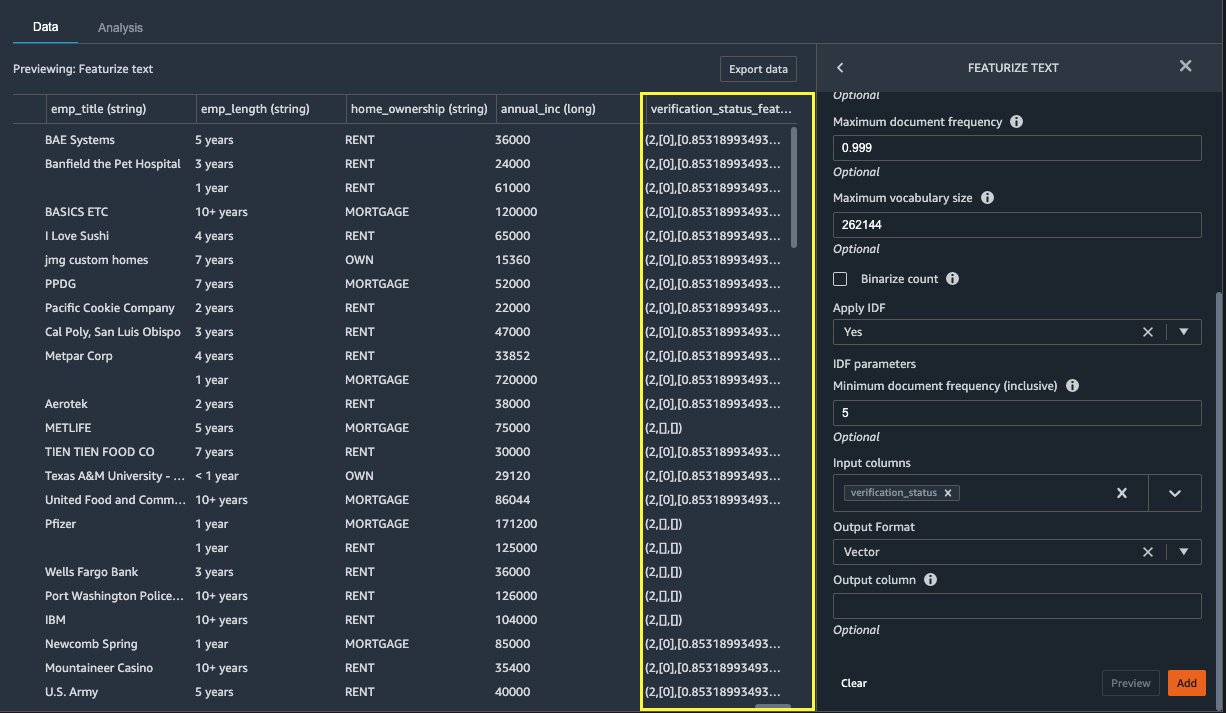

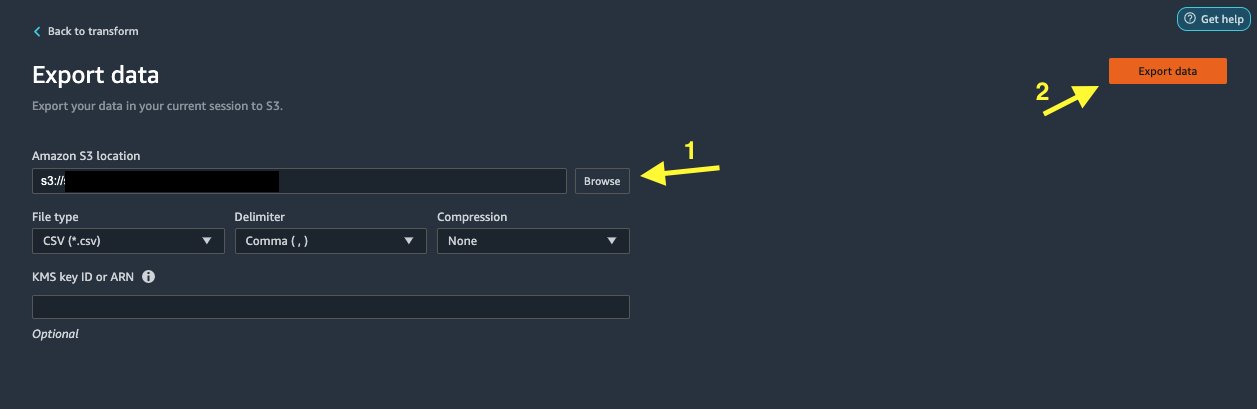
 Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using Artificial Intelligence and Machine Learning. In his spare time, Roop enjoys reading and hiking.
Roop Bains is a Solutions Architect at AWS focusing on AI/ML. He is passionate about helping customers innovate and achieve their business objectives using Artificial Intelligence and Machine Learning. In his spare time, Roop enjoys reading and hiking. Igor Alekseev is a Partner Solution Architect at AWS in Data and Analytics. Igor works with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect, he implemented many projects in Big Data, including several data lakes in the Hadoop ecosystem. As a Data Engineer, he was involved in applying AI/ML to fraud detection and office automation. Igor’s projects were in a variety of industries including communications, finance, public safety, manufacturing, and healthcare. Earlier, Igor worked as full stack engineer/tech lead.
Igor Alekseev is a Partner Solution Architect at AWS in Data and Analytics. Igor works with strategic partners helping them build complex, AWS-optimized architectures. Prior joining AWS, as a Data/Solution Architect, he implemented many projects in Big Data, including several data lakes in the Hadoop ecosystem. As a Data Engineer, he was involved in applying AI/ML to fraud detection and office automation. Igor’s projects were in a variety of industries including communications, finance, public safety, manufacturing, and healthcare. Earlier, Igor worked as full stack engineer/tech lead. Huong Nguyen is a Sr. Product Manager at AWS. She is leading the user experience for SageMaker Studio. She has 13 years’ experience creating customer-obsessed and data-driven products for both enterprise and consumer spaces. In her spare time, she enjoys reading, being in nature, and spending time with her family.
Huong Nguyen is a Sr. Product Manager at AWS. She is leading the user experience for SageMaker Studio. She has 13 years’ experience creating customer-obsessed and data-driven products for both enterprise and consumer spaces. In her spare time, she enjoys reading, being in nature, and spending time with her family. Henry Wang is a software development engineer at AWS. He recently joined the Data Wrangler team after graduating from UC Davis. He has an interest in data science and machine learning and does 3D printing as a hobby.
Henry Wang is a software development engineer at AWS. He recently joined the Data Wrangler team after graduating from UC Davis. He has an interest in data science and machine learning and does 3D printing as a hobby.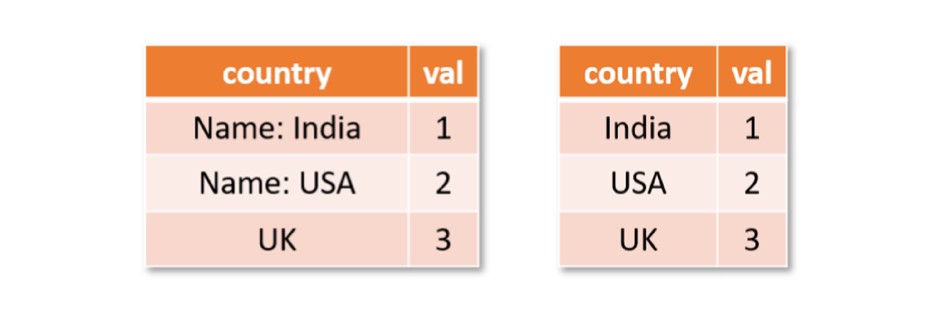
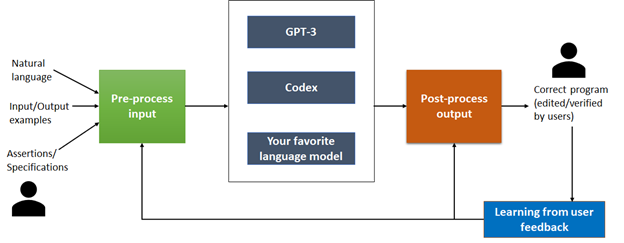


 “
“
