Organizations across industries have a large number of physical documents such as invoices that they need to process. It is difficult to extract information from a scanned document when it contains tables, forms, paragraphs, and check boxes. Organization have been addressing these problems with manual effort or custom code or by using Optical Character Recognition (OCR) technology. However, that requires templates for form extraction and custom workflows.
Moreover, after extracting the text or content from a document, they want to extract insights from these receipts or invoices for their end users. However, that would require building a complex NLP model. Training the model would require a large amount of training data and compute resources. Building and training a machine learning model could be expensive and time-consuming.
Further, providing a human like interface to interact with these documents is cumbersome for end users. These end users often call the help desk but over time this adds cost to the organization.
This post shows you how to use AWS AI services to automate text data processing and insight discovery. With AWS AI services such as Amazon Textract, Amazon Comprehend and Amazon Lex, you can set up an automated serverless solution to address this requirement. We will walk you through below steps:
- Extract text from receipts or invoices in pdf or images with Amazon Textract.
- Derive insights with Amazon Comprehend.
- Interact with these insights in natural language using Amazon Lex.
Next, we will go through the services and the architecture for building the solution to solve the problem.
Services used
This solution uses the following AI services, serverless technologies, and managed services to implement a scalable and cost-effective architecture:
- Amazon Cognito – Lets you add user signup, signin, and access control to your web and mobile apps quickly and easily.
- AWS Lambda – Executes code in response to triggers such as changes in data, shifts in system state, or user actions. Because Amazon S3 can directly trigger a Lambda function, you can build a variety of real-time serverless data-processing systems.
- Amazon Lex – Provides an interface to create conversational chatbots.
- Amazon Comprehend – NLP service that uses machine learning to find insights and relationships in text.
- Amazon Textract– Uses ML to extract text and data from scanned documents in PDF, JPEG, or PNG formats.
- Amazon Simple Storage Service (Amazon S3) – Serves as an object store for your documents and allows for central management with fine-tuned access controls.
Architecture
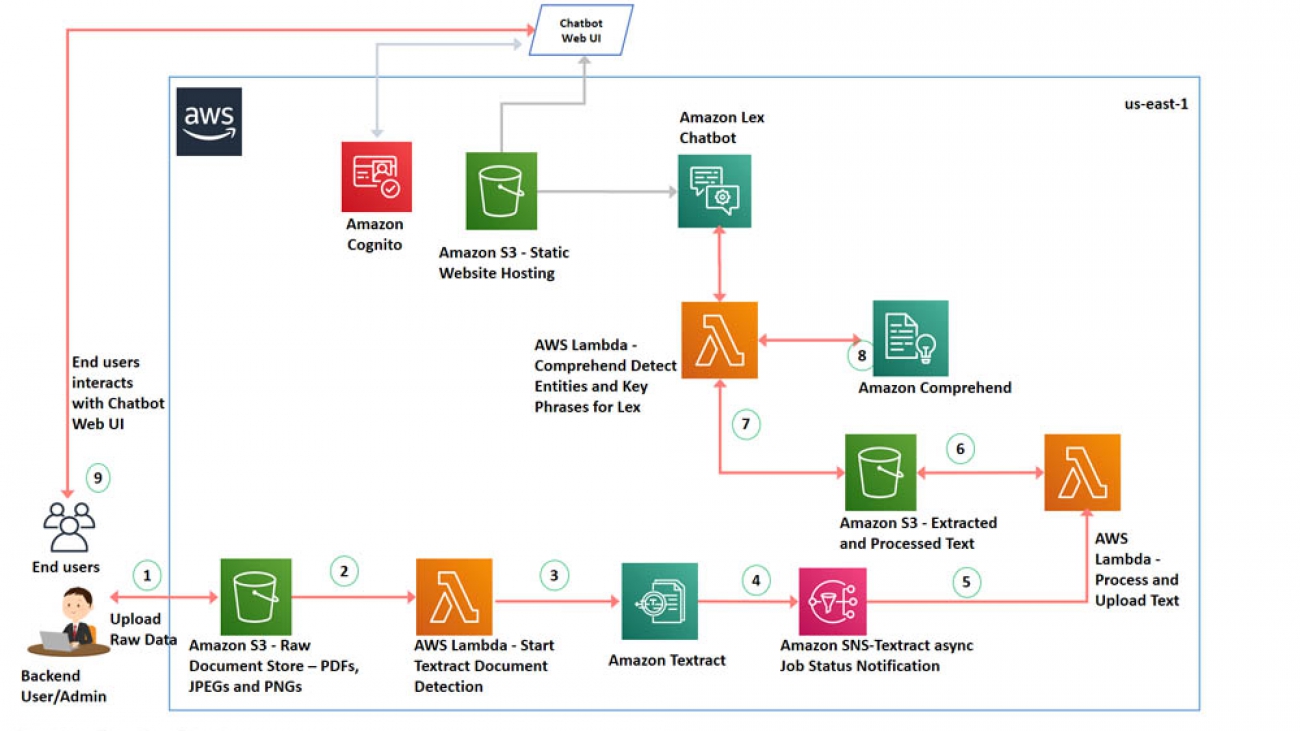
The following diagram illustrates the architecture of the solution.
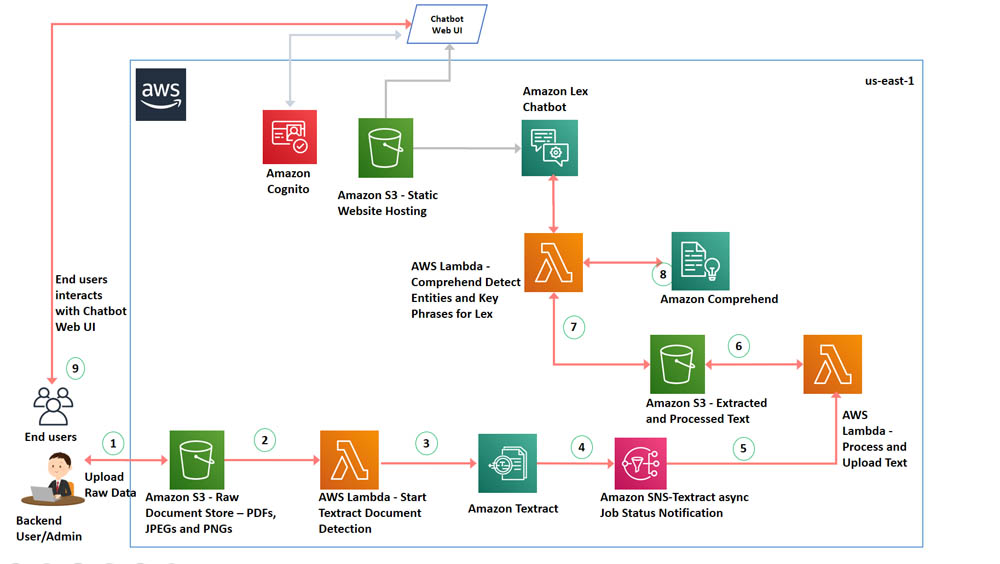
The architecture contains the following steps:
- The backend user or administrator uses the AWS Management Console or AWS Command Line Interface (AWS CLI) to upload the PDF documents or images to an S3 bucket.
- The Amazon S3 upload triggers a AWS Lambda function.
- The Lambda function invokes an Amazon Textract StartDocumentTextDetection API, which sets up an asynchronous job to detect text from the PDF you uploaded.
- Amazon Textract notifies Amazon Simple Notification Service (Amazon SNS) when text processing is complete.
- A second Lambda function gets the notification from SNS topic when the job is completed to detect text.
- Once the lambda is notified of job completion from Amazon SNS, it calls a Amazon Textract GetDocumentTextDetection API to receive the result from asynchronous operation and loads the results into an S3 bucket.
- A Lambda function is used for fulfillment of the Amazon Lex intents. For a more detailed sequence of interactions please refer to the Building your chatbot step in “Deploying the Architecture with Cloudformation” section.
- Amazon Comprehend uses ML to find insights and relationships in text. The lambda function uses boto3 APIs that Amazon Comprehend provides for entity and key phrases detection.
- In response to the Bot’s welcome message, the user types “Show me the invoice summary”, this invokes the GetInvoiceSummary Lex intent and the Lambda function invokes the Amazon Comprehend DetectEntities API to detect entities for fulfillment.
- When the user types “Get me the invoice details”, this invokes the GetInvoiceDetails intent, Amazon Lex prompts the user to enter Invoice Number, and the Lambda function invokes the Amazon Comprehend DetectEntities API to return the Invoice Details message.
- When the user types “Can you show me the invoice notes for <invoice number>”, this invokes the GetInvoiceNotes intent, and the Lambda function invokes the Amazon Comprehend DetectKeyPhrases API to return comments associated with the invoice.
- You deploy the Lexbot Web UI in your AWS Cloudformation template by using an existing CloudFormation stack as a nested stack. To download the stack, see Deploy a Web UI for Your Chatbot. This nested stack deploys a Lex Web UI, the webpage is served as a static website from an S3 bucket. The web UI uses Amazon Cognito to generate an access token for authentication and uses AWS CodeStar to set up a delivery pipeline.The end-users interact this chatbot web UI.
Deploying the architecture with AWS CloudFormation
You deploy a CloudFormation template to provision the necessary AWS Indentity and Access Management (IAM) roles, services, and components of the solution including Amazon S3, Lambda, Amazon Textract, Amazon Comprehend, and the Amazon Lex chatbot.
- Launch the following CloudFormation template and in the US East (N. Virginia) Region:

- Don’t make any changes to stack name or parameters botname
InvoiceBot. - In the Capabilities and transforms section, select all three check-boxes to provide acknowledgment to AWS CloudFormation to create IAM resources and expand the template.

For more information about these resources, see AWS IAM resources.
This template uses AWS Serverless Application Model (AWS SAM), which simplifies how to define functions and APIs for serverless applications, and also has features for these services, like environment variables.
- Choose Create stack.

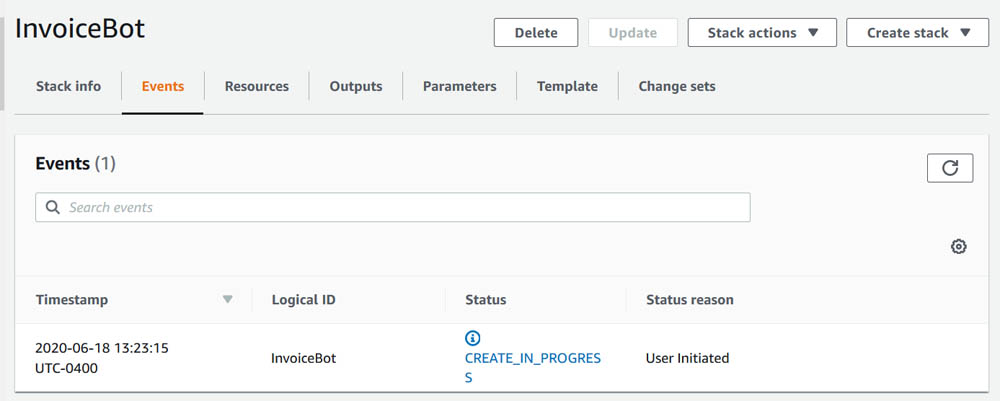
The following screenshot of the Stack Detail page shows the status of the stack as CREATE_IN_PROGRESS. It can take up to 20 minutes for the status to change to CREATE_COMPLETE.
- On the Outputs tab, copy the value of
LexLambaFunctionArn,AssetsUploadBucket,ExtractedTextfilesBucket, andLexUIWebAppUrl.

Uploading documents to the S3 bucket
To upload your documents to your new S3 bucket, choose the S3 bucket URL corresponding to AssetsUploadBucket that you copied earlier. Upload a PDF or image to start the text extraction flow.
You can download the invoice used in this blog from the GitHub repo and upload it to the AssetsUploadBucket S3 URL. We recommend to customize this solution for your invoice templates. For more information about uploading files, see How do I upload files and folders to an S3 bucket?
After the upload completes, you can see the file on the Amazon S3 console on the Overview tab.
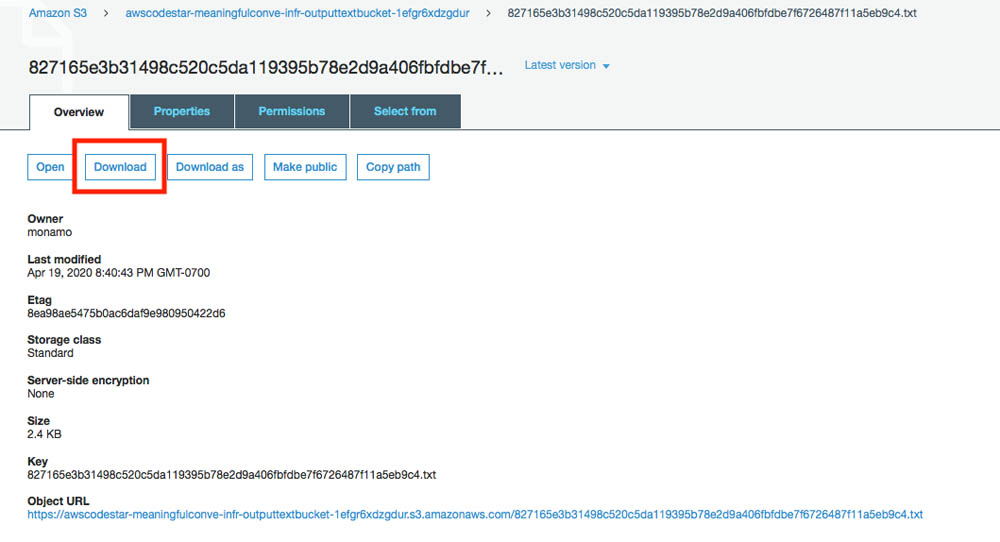
After you upload the file, the text is extracted from the document. To see an extracted file with the text, open the bucket by choosing the URL you copied earlier.

On the Overview tab, you can download the file and inspect the content to see if it’s the same as the text in the uploaded file.
Building your chatbot
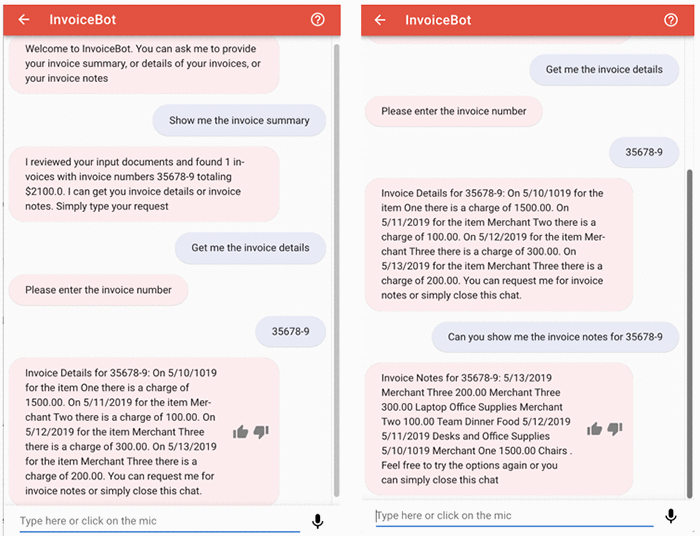
We will use the following conversation to model the bot:
Bot: Welcome to InvoiceBot. You can ask me to provide your invoice summary, or details of your invoices, or your invoice notes
User: Show me the invoice summary
Bot: I reviewed your input documents and found 1 invoice with invoice numbers 35678-9 totaling $2100.0. I can get you invoice details or invoice notes. Simply type your request
User: Get me the invoice details
Bot: Please enter the invoice number
User: 35678-9
Bot: Invoice Details for 35678-9: On 5/10/1019 for the item One there is a charge of 1500.00. On 5/11/2019 for the item Merchant Two there is a charge of 100.00. On 5/12/2019 for the item Merchant Three there is a charge of 300.00. On 5/13/2019 for the item Merchant Three there is a charge of 200.00. You can request me for invoice notes or simply close this chat.
User: Can you show me the invoice notes for 35678-9
Bot: Invoice Notes for 35678-9: 5/13/2019 Merchant Three 200.00 Merchant Three 300.00 Laptop Office Supplies Merchant Two 100.00 Team Dinner Food 5/12/2019 5/11/2019 Desks and Office Supplies 5/10/1019 Merchant One 1500.00 Chairs . Feel free to try the options again or you can simply close this chat
We will build an Amazon Lex bot (InvoiceBot) with the following intents:
- GetInvoiceSummary – Intent that’s invoked when the user requests to view the Invoice Summary. This is fulfilled by a Lambda function and returns the count of invoices available, and the total amount of the invoices
- GetInvoiceDetails – Intent that’s invoked when the user requests to view the Invoice Details. This is fulfilled by a Lambda function and provides item level breakdown of the invoices including Date, Quantity and Item Details
- GetInvoiceNotes – Intent that’s invoked when the user requests to view the Invoice Notes. This is fulfilled by a Lambda function and provides notes from the invoices uploaded with Date and Item Description.
Publishing your chatbot
As described in the solution overview earlier, you use an Amazon Lex chatbot (InvoiceBot) to interact with the insights Amazon Comprehend derives from the text Amazon Textract extracts.
To publish your chatbot, complete the following steps:
- On the Amazon Lex console, choose Bots.
- Choose the chatbot you created.

- Under Intents, choose GetInvoiceSummary.
- Under Fulfilment, select your Lambda function.
- Search for the function by entering
LexLambdaFunctionand selecting the result.
A pop-up box appears.
- Choose OK.

- Choose Save intent.
- Repeat these steps for the remaining two intents,
GetInvoiceDetailsandGetInvoiceNotes. - Choose Build.
- When the build is complete, choose Publish.

- For Create an alias, enter
Latest. You can consider a different name; names like test, dev, beta, or prod primarily refer to the environment of the bot. - Choose Publish.

The following page opens after the bot is published.
- Choose Close.
Using the chatbot
Your chatbot is now ready to use. Navigate to the URL LexUIWebAppUrl copied from the AWS CloudFormation Outputs tab. The following screenshots show the user conversation with the bot (read from left to right):
Conclusion
This post demonstrated how to create a conversational chatbot in Amazon Lex that enables interaction with insights derived using Amazon Comprehend and Amazon Textract from a text in images or in a PDF document. The code from this post is available on the GitHub repo for you to use and extend. We are interested to hear how you would like to apply this solution for your usecase. Please share your thoughts and questions in the comments section.
About the Authors
 Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector Team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML .
Mona Mona is an AI/ML Specialist Solutions Architect based out of Arlington, VA. She works with World Wide Public Sector Team and helps customers adopt machine learning on a large scale. She is passionate about NLP and ML Explainability areas in AI/ML .
 Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
Prem Ranga is an Enterprise Solutions Architect based out of Houston, Texas. He is part of the Machine Learning Technical Field Community and loves working with customers on their ML and AI journey. Prem is passionate about robotics, is an Autonomous Vehicles researcher, and also built the Alexa-controlled Beer Pours in Houston and other locations.
 Saida Chanda is a Senior Partner Solutions Architect based out of Seattle, WA. He is a technology enthusiast who drives innovation through AWS partners to meet customers complex business requirements via simple solutions. His areas of interest are ML and DevOps. In his spare time, he likes to spend time with family and exploring his innerself through meditation.
Saida Chanda is a Senior Partner Solutions Architect based out of Seattle, WA. He is a technology enthusiast who drives innovation through AWS partners to meet customers complex business requirements via simple solutions. His areas of interest are ML and DevOps. In his spare time, he likes to spend time with family and exploring his innerself through meditation.









 Luis Leon is the IT Innovation Advisor responsible for the data science practice in the IT at Euler Hermes. He is in charge of the ideation of digital projects as well as managing the design, build and industrialization of at scale machine learning products. His main interests are Natural Language Processing, Time Series Analysis and non-supervised learning.
Luis Leon is the IT Innovation Advisor responsible for the data science practice in the IT at Euler Hermes. He is in charge of the ideation of digital projects as well as managing the design, build and industrialization of at scale machine learning products. His main interests are Natural Language Processing, Time Series Analysis and non-supervised learning. Hamza Benchekroun is Data Scientist in the IT Innovation hub at Euler Hermes focusing on deep learning solutions to increase productivity and guide decision making across teams. His research interests include Natural Language Processing, Time Series Analysis, Semi-Supervised Learning and their applications.
Hamza Benchekroun is Data Scientist in the IT Innovation hub at Euler Hermes focusing on deep learning solutions to increase productivity and guide decision making across teams. His research interests include Natural Language Processing, Time Series Analysis, Semi-Supervised Learning and their applications. Hatim Binani is data scientist intern in the IT Innovation hub at Euler Hermes. He is an engineering student at INSA Lyon in the computer science department. His field of interest is data science and machine learning. He contributed within the IT innovation team to the deployment of Watson on Amazon Sagemaker.
Hatim Binani is data scientist intern in the IT Innovation hub at Euler Hermes. He is an engineering student at INSA Lyon in the computer science department. His field of interest is data science and machine learning. He contributed within the IT innovation team to the deployment of Watson on Amazon Sagemaker. Guillaume Chambert is an IT security engineer at Euler Hermes. As SOC manager, he strives to stay ahead of new threats in order to protect Euler Hermes’ sensitive and mission-critical data. He is interested in developing innovation solutions to prevent critical information from being stolen, damaged or compromised by hackers.
Guillaume Chambert is an IT security engineer at Euler Hermes. As SOC manager, he strives to stay ahead of new threats in order to protect Euler Hermes’ sensitive and mission-critical data. He is interested in developing innovation solutions to prevent critical information from being stolen, damaged or compromised by hackers.