![]()
The International Conference on Robotics and Automation (ICRA) 2020 is being hosted virtually from May 31 – Jun 4.
We’re excited to share all the work from SAIL that’s being presented, and you’ll find links to papers, videos and blogs below. Feel free to reach out to the contact authors directly to learn more about the work that’s happening at Stanford!
List of Accepted Papers
Design of a Roller-Based Dexterous Hand for Object Grasping and Within-Hand Manipulation

Authors: Shenli Yuan, Austin D. Epps, Jerome B. Nowak, J. Kenneth Salisbury
Contact: shenliy@stanford.edu
Award nominations: Best Paper, Best Student Paper, Best Paper Award in Robot Manipulation, Best Paper in Mechanisms and Design
Links: Paper | Video
Keywords: dexterous manipulation, grasping, grippers and other end-effectors
Distributed Multi-Target Tracking for Autonomous Vehicle Fleets
![]()
Authors: Ola Shorinwa, Javier Yu, Trevor Halsted, Alex Koufos, and Mac Schwager
Contact: shorinwa@stanford.edu
Award nominations: Best Paper
Links: Paper | Video
Keywords: mulit-target tracking, distributed estimation, multi-robot systems
Efficient Large-Scale Multi-Drone Delivery Using Transit Networks

Authors: Shushman Choudhury, Kiril Solovey, Mykel J. Kochenderfer, Marco Pavone
Contact: shushman@stanford.edu
Award nominations: Best Multi-Robot Systems Paper
Links: Paper | Video
Keywords: multi-robot, optimization, task allocation, route planning
Form2Fit: Learning Shape Priors for Generalizable Assembly from Disassembly
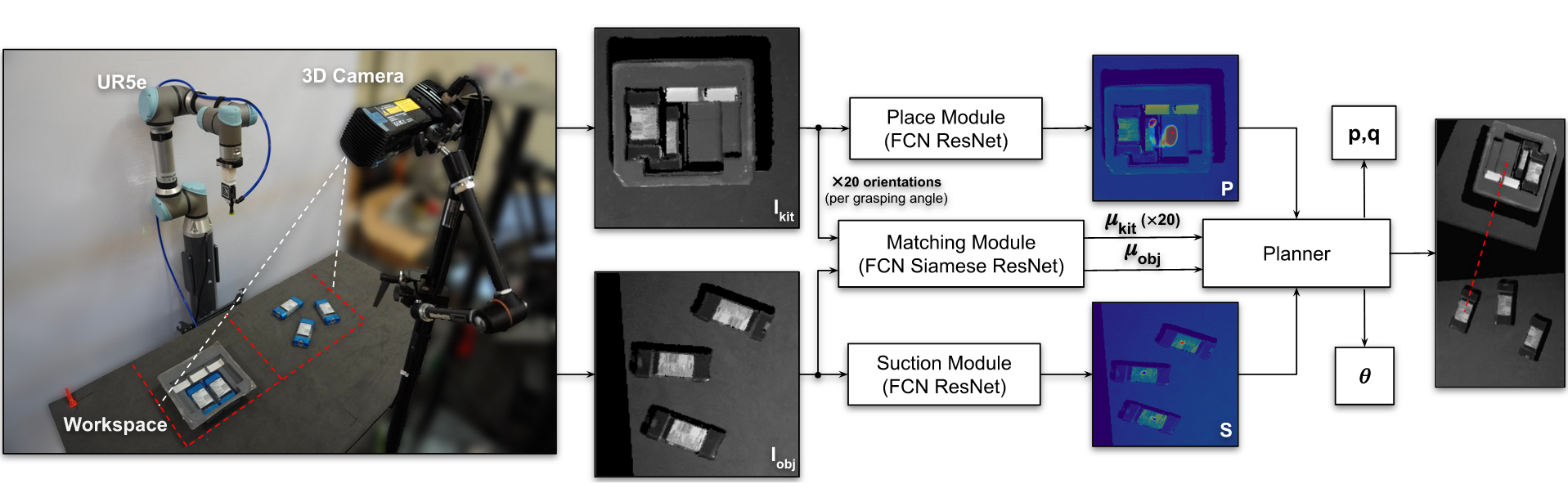
Authors: Kevin Zakka, Andy Zeng, Johnny Lee, Shuran Song
Contact: zakka@cs.stanford.edu
Award nominations: Best Automation Paper
Links: Paper | Blog Post | Video
Keywords: perception for grasping, assembly, robotics
Human Interface for Teleoperated Object Manipulation with a Soft Growing Robot

Authors: Fabio Stroppa, Ming Luo, Kyle Yoshida, Margaret M. Coad, Laura H. Blumenschein, and Allison M. Okamura
Contact: fstroppa@stanford.edu
Award nominations: Best Human-Robot Interaction Paper
Links: Paper | Video
Keywords: soft robot, growing robot, manipulation, interface, teleoperation
6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
Authors: Chen Wang, Roberto Martín-Martín, Danfei Xu, Jun Lv, Cewu Lu, Li Fei-Fei, Silvio Savarese, Yuke Zhu
Contact: chenwj@stanford.edu
Links: Paper | Blog Post | Video
Keywords: category-level 6d object pose tracking, unsupervised 3d keypoints
A Stretchable Capacitive Sensory Skin for Exploring Cluttered Environments
Authors: Alexander Gruebele, Jean-Philippe Roberge, Andrew Zerbe, Wilson Ruotolo, Tae Myung Huh, Mark R. Cutkosky
Contact: agruebe2@stanford.edu
Links: Paper
Keywords: robot sensing systems , skin , wires , capacitance , grasping
Accurate Vision-based Manipulation through Contact Reasoning
Authors: Alina Kloss, Maria Bauza, Jiajun Wu, Joshua B. Tenenbaum, Alberto Rodriguez, Jeannette Bohg
Contact: alina.kloss@tue.mpg.de
Links: Paper | Video
Keywords: manipulation planning, contact modeling, perception for grasping and manipulation
Assistive Gym: A Physics Simulation Framework for Assistive Robotics
Authors: Zackory Erickson, Vamsee Gangaram, Ariel Kapusta, C. Karen Liu, and Charles C. Kemp
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; physics simulation; reinforcement learning; physical human robot interaction
Controlling Assistive Robots with Learned Latent Actions
Authors: Dylan P. Losey, Krishnan Srinivasan, Ajay Mandlekar, Animesh Garg, Dorsa Sadigh
Contact: dlosey@stanford.edu
Links: Paper | Blog Post | Video
Keywords: human-robot interaction, assistive control
Distal Hyperextension is Handy: High Range of Motion in Cluttered Environments
Authors: Wilson Ruotolo, Rachel Thomasson, Joel Herrera, Alex Gruebele, Mark R. Cutkosky
Contact: wruotolo@stanford.edu
Links: Paper | Video
Keywords: dexterous manipulation, grippers and other end-effectors, multifingered hands
Dynamically Reconfigurable Discrete Distributed Stiffness for Inflated Beam Robots
Authors: Brian H. Do, Valory Banashek, Allison M. Okamura
Contact: brianhdo@stanford.edu
Links: Paper | Video
Keywords: soft robot materials and design; mechanism design; compliant joint/mechanism
Dynamically Reconfigurable Tactile Sensor for Robotic Manipulation
Authors: Tae Myung Huh, Hojung Choi, Simone Willcox, Stephanie Moon, Mark R. Cutkosky
Contact: taemyung@stanford.edu
Links: Paper | Video
Keywords: robot sensing systems , electrodes , force , force measurement , capacitance
Enhancing Game-Theoretic Autonomous Car Racing Using Control Barrier Functions
Authors: Gennaro Notomista, Mingyu Wang, Mac Schwager, Magnus Egerstedt
Contact: mingyuw@stanford.edu
Links: Paper
Keywords: autonomous driving
Evaluation of Non-Collocated Force Feedback Driven by Signal-Independent Noise
Authors: Zonghe Chua, Allison Okamura, Darrel Deo
Contact: chuazh@stanford.edu
Links: Paper | Video
Keywords: haptics and haptic interfaces; prosthetics and exoskeletons; brain-machine interface
From Planes to Corners: Multi-Purpose Primitive Detection in Unorganized 3D Point Clouds
Authors: Christiane Sommer, Yumin Sun, Leonidas Guibas, Daniel Cremers, Tolga Birdal
Contact: tbirdal@stanford.edu
Links: Paper | Code | Video
Keywords: plane detection, corner detection, orthogonal, 3d geometry, computer vision, point pair, slam
Guided Uncertainty-Aware Policy Optimization: Combining Learning and Model-Based Strategies for Sample-Efficient Policy Learning
Authors: Michelle A. Lee, Carlos Florensa, Jonathan Tremblay, Nathan Ratliff, Animesh Garg, Fabio Ramos, Dieter Fox
Contact: mishlee@stanford.edu
Links: Paper | Video
Keywords: deep learning in robotics and automation, perception for grasping and manipulation, learning and adaptive systems
IRIS: Implicit Reinforcement without Interaction at Scale for Learning Control from Offline Robot Manipulation Data
Authors: Ajay Mandlekar, Fabio Ramos, Byron Boots, Silvio Savarese, Li Fei-Fei, Animesh Garg, Dieter Fox
Contact: amandlek@stanford.edu
Links: Paper | Video
Keywords: imitation learning, reinforcement learning, robotics
Interactive Gibson Benchmark: A Benchmark for Interactive Navigation in Cluttered Environments
Authors: Fei Xia, William B. Shen, Chengshu Li, Priya Kasimbeg, Micael Tchapmi, Alexander Toshev, Roberto Martín-Martín, Silvio Savarese
Contact: feixia@stanford.edu
Links: Paper | Video
Keywords: visual navigation, deep learning in robotics, mobile manipulation
KETO: Learning Keypoint Representations for Tool Manipulation
Authors: Zengyi Qin, Kuan Fang, Yuke Zhu, Li Fei-Fei, Silvio Savarese
Contact: qinzy@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: manipulation, representation, keypoint, interaction, self-supervised learning
Learning Hierarchical Control for Robust In-Hand Manipulation
Authors: Tingguang Li, Krishnan Srinivasan, Max Qing-Hu Meng, Wenzhen Yuan, Jeannette Bohg
Contact: tgli@link.cuhk.edu.hk
Links: Paper | Blog Post | Video
Keywords: in-hand manipulation, robotics, reinforcement learning, hierarchical
Learning Task-Oriented Grasping from Human Activity Datasets
Authors: Mia Kokic, Danica Kragic, Jeannette Bohg
Contact: mkokic@kth.se
Links: Paper
Keywords: perception, grasping
Learning a Control Policy for Fall Prevention on an Assistive Walking Device
Authors: Visak CV Kumar, Sehoon Ha, Gregory Sawicki, C. Karen Liu
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; human motion modeling; physical human robot interaction; reinforcement learning
Learning an Action-Conditional Model for Haptic Texture Generation
Authors: Negin Heravi, Wenzhen Yuan, Allison M. Okamura, Jeannette Bohg
Contact: nheravi@stanford.edu
Links: Paper | Blog Post | Video
Keywords: haptics and haptic interfaces
Learning to Collaborate from Simulation for Robot-Assisted Dressing
Authors: Alexander Clegg, Zackory Erickson, Patrick Grady, Greg Turk, Charles C. Kemp, C. Karen Liu
Contact: karenliu@cs.stanford.edu
Links: Paper
Keywords: assistive robotics; physical human robot interaction; reinforcement learning; physics simulation; cloth manipulation
Learning to Scaffold the Development of Robotic Manipulation Skills
Authors: Lin Shao, Toki Migimatsu, Jeannette Bohg
Contact: lins2@stanford.edu
Links: Paper | Video
Keywords: learning and adaptive systems, deep learning in robotics and automation, intelligent and flexible manufacturing
Map-Predictive Motion Planning in Unknown Environments
Authors: Amine Elhafsi, Boris Ivanovic, Lucas Janson, Marco Pavone
Contact: amine@stanford.edu
Links: Paper
Keywords: motion planning deep learning robotics
Motion Reasoning for Goal-Based Imitation Learning
Authors: De-An Huang, Yu-Wei Chao, Chris Paxton, Xinke Deng, Li Fei-Fei, Juan Carlos Niebles, Animesh Garg, Dieter Fox
Contact: dahuang@stanford.edu
Links: Paper | Video
Keywords: imitation learning, goal inference
Object-Centric Task and Motion Planning in Dynamic Environments
Authors: Toki Migimatsu, Jeannette Bohg
Contact: takatoki@cs.stanford.edu
Links: Paper | Blog Post | Video
Keywords: control of systems integrating logic, dynamics, and constraints
Optimal Sequential Task Assignment and Path Finding for Multi-Agent Robotic Assembly Planning
Authors: Kyle Brown, Oriana Peltzer, Martin Sehr, Mac Schwager, Mykel Kochenderfer
Contact: kjbrown7@stanford.edu
Links: Paper | Video
Keywords: multi robot systems, multi agent path finding, mixed integer programming, automated manufacturing, sequential task assignment
Refined Analysis of Asymptotically-Optimal Kinodynamic Planning in the State-Cost Space
Authors: Michal Kleinbort, Edgar Granados, Kiril Solovey, Riccardo Bonalli, Kostas E. Bekris, Dan Halperin
Contact: kirilsol@stanford.edu
Links: Paper
Keywords: motion planning, sampling-based planning, rrt, optimality
Retraction of Soft Growing Robots without Buckling
Authors: Margaret M. Coad, Rachel P. Thomasson, Laura H. Blumenschein, Nathan S. Usevitch, Elliot W. Hawkes, and Allison M. Okamura
Contact: mmcoad@stanford.edu
Links: Paper | Video
Keywords: soft robot materials and design; modeling, control, and learning for soft robots
Revisiting the Asymptotic Optimality of RRT*
Authors: Kiril Solovey, Lucas Janson, Edward Schmerling, Emilio Frazzoli, and Marco Pavone
Contact: kirilsol@stanford.edu
Links: Paper | Video
Keywords: motion planning, rapidly-exploring random trees, rrt*, sampling-based planning
Sample Complexity of Probabilistic Roadmaps via Epsilon Nets
Authors: Matthew Tsao, Kiril Solovey, Marco Pavone
Contact: mwtsao@stanford.edu
Links: Paper | Video
Keywords: motion planning, sampling-based planning, probabilistic roadmaps, epsilon nets
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Authors: Mengyuan Yan, Yilin Zhu, Ning Jin, Jeannette Bohg
Contact: myyan92@gmail.com, bohg@stanford.edu
Links: Paper | Video
Keywords: self-supervision, deformable objects
Spatial Scheduling of Informative Meetings for Multi-Agent Persistent Coverage
Authors: Ravi Haksar, Sebastian Trimpe, Mac Schwager
Contact: rhaksar@stanford.edu
Links: Paper | Video
Keywords: distributed systems, multi-robot systems, multi-robot path planning
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction
Authors: Bingbin Liu, Ehsan Adeli, Zhangjie Cao, Kuan-Hui Lee, Abhijeet Shenoi, Adrien Gaidon, Juan Carlos Niebles
Contact: eadeli@stanford.edu
Links: Paper | Video
Keywords: spatiotemporal graphs, forecasting, graph neural networks, autonomous-driving.
TRASS: Time Reversal as Self-Supervision
Authors: Suraj Nair, Mohammad Babaeizadeh, Chelsea Finn, Sergey Levine, Vikash Kumar
Contact: surajn@stanford.edu
Links: Paper | Blog Post | Video
Keywords: visual planning; reinforcement learning; self-supervision
UniGrasp: Learning a Unified Model to Grasp with Multifingered Robotic Hands
Authors: Lin Shao, Fabio Ferreira, Mikael Jorda, Varun Nambiar, Jianlan Luo, Eugen Solowjow, Juan Aparicio Ojea, Oussama Khatib, Jeannette Bohg
Contact: lins2@stanford.edu
Links: Paper | Video
Keywords: deep learning in robotics and automation; grasping; multifingered hands
Vine Robots: Design, Teleoperation, and Deployment for Navigation and Exploration
Authors: Margaret M. Coad, Laura H. Blumenschein, Sadie Cutler, Javier A. Reyna Zepeda, Nicholas D. Naclerio, Haitham El-Hussieny, Usman Mehmood, Jee-Hwan Ryu, Elliot W. Hawkes, and Allison M. Okamura
Contact: mmcoad@stanford.edu
Links: Paper | Video
Keywords: soft robot applications; field robots
We look forward to seeing you at ICRA!
































{kind=link}