A guest post by Emily Xie, Software Engineer
Background
Urban legend says that Mona Lisa’s eyes will follow you as you move around the room. This is known as the “Mona Lisa effect.” For fun, I recently programmed an interactive digital portrait that brings this phenomenon to life through your browser and webcam.

At its core, the project leverages TensorFlow.js, deep learning, and some image processing techniques. The general idea is as follows: first, we must generate a sequence of images of Mona Lisa’s head, with eyes gazing from the left to right. From this pool, we’ll continuously select and display a single frame in real-time based on the viewer’s location.
In this post, I’ll walk through the specifics of the project’s technical design and implementation.
Animating the Mona Lisa with Deep Learning
Image animation is a technique that allows one to puppeteer a still image through a driving video. Using a deep-learning-based approach, I was able to generate a highly convincing animation of Mona Lisa’s gaze.
Specifically, I used the First Order Motion Model (FOMM), released by Aliaksandr Siarohin et al. in 2019. At a very high level, this method is composed of two modules: one for motion extraction, and another for image generation. The motion module detects keypoints and local affine transformations from the driving video. Diffs of these values between consecutive frames are then used as input to a network that predicts a dense motion field, along with an occlusion mask which specifies the image regions that either need to be modified or contextually inferred. The image generation network, then, detects facial landmarks and produces the final output––the source image, warped and in-painted according to the results of the motion module.
I chose FOMM in particular because of its ease of use. Prior models in this domain had been “object-specific”, meaning that they required detailed data of the object to be animated, whereas FOMM operated agnostically to this. More importantly, the authors released an open-source, out-of-the-box implementation with pre-trained weights for facial animation. Because of this, applying the model to the Mona Lisa became a surprisingly straightforward endeavor: I simply cloned the repo into a Colab notebook, produced a short driving video of me with my eyes moving around, and fed it through the model along with a screenshot of La Gioconda’s head. The resulting movie was stellar. From this, I ultimately sampled just 33 images to constitute the final animation.
 |
| Example of a driving video and the image animation predictions generated by FOMM. |
 |
| A subsample of the final animation frames, produced using the First Order Motion Model. |
Image Blending
While I could’ve re-trained the model for my project’s purposes, I decided to work within the constraints of Siarohin’s weights in order to avoid the time and computational resources that would’ve been otherwise required. This, however, meant that the resulting frames were fixed at a lower resolution than desired, and consisted of just the subject’s head. But since I wanted the final visual to include the entirety of Mona Lisa––hands, torso, and background included––my plan was to simply superimpose the output head frames onto an image of the painting.
 |
| An example of a head frame overlaid on top of the underlying image. To best illustrate the problem, the version shown here is from an earlier iteration of the project where there was further resolution loss in the head frame. |
This, however, produced its own set of challenges. If you look at the example above, you’ll notice that the lower-resolution output of the model––coupled with some subtle collateral background changes due to FOMM’s warping procedure––causes the head frame to visually jut out. In other words, it was a bit obvious that this was just a picture on top of another picture. To address this, I did some image processing in Python to “blend” the head image into the underlying one.
First, I resized the head frame to its original resolution. From there, I created a new frame using a weighted average of these blurred out pixels and the corresponding pixels in the underlying image, where the weight––or alpha––of a pixel in the head frame decreases as it moves away from the midpoint.
The function to determine alpha was adapted from a 2D sigmoid, and is expressed as:
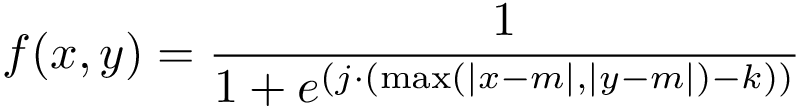
Where j determines the logistic function’s slope, k is the inflection point, and m is the midpoint of the input values. Graphed out, the function looks like:
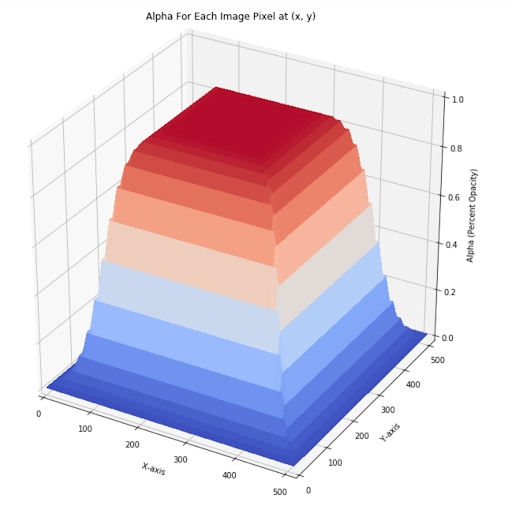
After I applied the above procedure to all 33 frames in the animation set, the resulting superimpositions each appeared to be a single image to the unsuspecting eye:

Tracking the Viewer’s Head via BlazeFace
All that was left at this point was to determine how to track the user via the webcam and display the corresponding frame.
Naturally, I turned to TensorFlow.js for the job. The library offered a fairly robust set of models to detect the presence of a human given visual input, but after some research and thinking, I landed on BlazeFace as my method of choice.
BlazeFace is a deep-learning based object recognition model that detects human faces and facial landmarks. It is specifically trained for using mobile camera input. This worked well for my use case, as I expected most viewers to be using their webcam in a similar manner––with their heads in frame, front-facing, and fairly close to the camera––whether through their mobile devices or on their laptops.
My foremost consideration in selecting this model, however, was its extraordinary speed of detection. To make this project convincing, I needed to be able to run the entire animation in real time, including the facial recognition step. BlazeFace adapts the single-shot detection (SSD) model, a deep-learning-based object detection algorithm that simultaneously proposes bounding boxes and detects objects in just one forward pass of the network. BlazeFace’s lightweight detector is capable of recognizing facial landmarks at speeds as fast as 200 frames per second.
 |
| A demo of what BlazeFace can capture given an input image: bounding boxes for a human head, along with facial landmarks. |
Having settled on the model, I then wrote code to continually pipe the user’s webcam data into BlazeFace. On each run, the model outputted an array of facial landmarks and their corresponding 2D coordinate positions. Using this, I approximated the X coordinate of the face’s center by calculating the midpoint between the eyes.
Finally, I mapped this result to an integer between 0 and 32. These values, as you may recall, each represented a frame in the animated sequence––with 0 depicting Mona Lisa with her eyes to the left, and 32 with her eyes to the right. From there, it was just a matter of displaying the frame on the screen.
Try it out!
You can play with the project at monalisaeffect.com. To follow more of my work, feel free to check out my personal website, Github, or Twitter.
Acknowledgements
Thanks to Andrew Fu for reading this post and providing me feedback, to Nick Platt for lending his ear and thoughts on a frontend bug, and to Jason Mayes along with the rest of the team at Google for their work in reaching out and amplifying this project.