Machine learning (ML) helps organizations increase revenue, drive business growth, and reduce cost by optimizing core business functions across multiple verticals, such as demand forecasting, credit scoring, pricing, predicting customer churn, identifying next best offers, predicting late shipments, and improving manufacturing quality. Traditional ML development cycles take months and require scarce data science and ML engineering skills. Analysts’ ideas for ML models often sit in long backlogs awaiting data science team bandwidth, while data scientists focus on more complex ML projects requiring their full skillset.
To help break this stalemate, we’ve introduced Amazon SageMaker Canvas, a no-code ML solution that can help companies accelerate delivery of ML solutions down to hours or days. SageMaker Canvas enables analysts to easily use available data in data lakes, data warehouses, and operational data stores; build ML models; and use them to make predictions interactively and for batch scoring on bulk datasets—all without writing a single line of code.
In this post, we show how SageMaker Canvas enables collaboration between data scientists and business analysts, achieving faster time to market and accelerating the development of ML solutions. Analysts get their own no-code ML workspace in SageMaker Canvas, without having to become an ML expert. Analysts can then share their models from Canvas with a few clicks, which data scientists will be able to work with in Amazon SageMaker Studio, an end-to-end ML integrated development environment (IDE). By working together, business analysts can bring their domain knowledge and the results of the experimentation, while data scientists can effectively create pipelines and streamline the process.
Let’s deep dive on what the workflow would look like.
Business analysts build a model, then share it
To understand how SageMaker Canvas simplifies collaboration between business analysts and data scientists (or ML engineers), we first approach the process as a business analyst. Before you get started, refer to Announcing Amazon SageMaker Canvas – a Visual, No Code Machine Learning Capability for Business Analysts for instructions on building and testing the model with SageMaker Canvas.
For this post, we use a modified version of the Credit Card Fraud Detection dataset from Kaggle, a well-known dataset for a binary classification problem. The dataset is originally highly unbalanced—it has very few entries classified as a negative class (anomalous transactions). Regardless of the target feature distribution, we can still use this dataset, because SageMaker Canvas handles this imbalance as it trains and tunes a model automatically. This dataset consists of about 9 million cells. You can also download a reduced version of this dataset. The dataset size is much smaller, at around 500,000 cells, because it has been randomly under-sampled and then over-sampled with the SMOTE technique to ensure that as little information as possible is lost during this process. Running an entire experiment with this reduced dataset costs you $0 under the SageMaker Canvas Free Tier.
After the model is built, analysts can use it to make predictions directly in Canvas for either individual requests, or for an entire input dataset in bulk.

Models built with Canvas Standard Build can also be easily shared at a click of a button with data scientists and ML engineers that use SageMaker Studio. This allows a data scientist to validate the performance of the model you’ve built and provide feedback. ML engineers can pick up your model and integrate it with existing workflows and products available to your company and your customers. Note that, at the time of writing, it’s not possible to share a model built with Canvas Quick Build, or a time series forecasting model.
Sharing a model via the Canvas UI is straightforward:
- On the page showing the models that you’ve created, choose a model.
- Choose Share.

- Choose one or more versions of the model that you want to share.
- Optionally, include a note giving more context about the model or the help you’re looking for.
- Choose Create SageMaker Studio Link.

- Copy the generated link.

And that’s it! You can now share the link with your colleagues via Slack, email, or any other method of your preference. The data scientist needs to be in the same SageMaker Studio domain in order to access your model, so make sure this is the case with your organization admin.

Data scientists access the model information from SageMaker Studio
Now, let’s play the role of a data scientist or ML engineer, and see things from their point of view using SageMaker Studio.
The link shared by the analyst takes us into SageMaker Studio, the first cloud-based IDE for the end-to-end ML workflow.

The tab opens automatically, and shows an overview of the model created by the analyst in SageMaker Canvas. You can quickly see the model’s name, the ML problem type, the model version, and which user created the model (under the field Canvas user ID). You also have access to details about the input dataset and the best model that SageMaker was able to produce. We will dive into that later in the post.
On the Input Dataset tab, you can also see the data flow from the source to the input dataset. In this case, only one data source is used and no join operations have been applied, so a single source is shown. You can analyze statistics and details about the dataset by choosing Open data exploration notebook. This notebook lets you explore the data that was available before training the model, and contains an analysis of the target variable, a sample of the input data, statistics and descriptions of columns and rows, as well as other useful information for the data scientist to know more about the dataset. To learn more about this report, refer to Data exploration report.

After analyzing the input dataset, let’s move on to the second tab of the model overview, AutoML Job. This tab contains a description of the AutoML job when you selected the Standard Build option in SageMaker Canvas.
The AutoML technology underneath SageMaker Canvas eliminates the heavy lifting of building ML models. It automatically builds, trains, and tunes the best ML model based on your data by using an automated approach, while allowing you to maintain full control and visibility. This visibility on the generated candidate models as well as the hyper-parameters used during the AutoML process is contained in the candidate generation notebook, which is available on this tab.
The AutoML Job tab also contains a list of every model built as part of the AutoML process, sorted by the F1 objective metric. To highlight the best model out of the training jobs launched, a tag with a green circle is used in the Best Model column. You can also easily visualize other metrics used during the training and evaluation phase, such as the accuracy score and the Area Under the Curve (AUC). To learn more about the models that you can train during an AutoML job and the metrics used for evaluating the performances of the trained model, refer to Model support, metrics, and validation.
To learn more about the model, you can now right-click the best model and choose Open in model details. Alternatively, you can choose the Best model link at the top of the Model overview section you first visited.

The model details page contains a plethora of useful information regarding the model that performed best with this input data. Let’s first focus on the summary at the top of the page. The preceding example screenshot shows that, out of hundreds of model training runs, an XGBoost model performed best on the input dataset. At the time of this writing, SageMaker Canvas can train three types of ML algorithms: linear learner, XGBoost, and a multilayer perceptron (MLP), each with a wide variety of preprocessing pipelines and hyper-parameters. To learn more about each algorithm, refer to supported algorithms page.
SageMaker also includes an explanatory functionality thanks to a scalable and efficient implementation of KernelSHAP, based on the concept of a Shapley value from the field of cooperative game theory that assigns to each feature an importance value for a particular prediction. This allows for transparency about how the model arrived at its predictions, and it’s very useful to define feature importance. A complete explainability report including feature importance is downloadable in PDF, notebook, or raw data format. In that report, a wider set of metrics are shown as well as a full list of hyper-parameters used during the AutoML job. To learn more about how SageMaker provides integrated explainability tools for AutoML solutions and standard ML algorithms, see Use integrated explainability tools and improve model quality using Amazon SageMaker Autopilot.
Finally, the other tabs in this view show information about performance details (confusion matrix, precision recall curve, ROC curve), artifacts used for inputs and generated during the AutoML job, and network details.
At this point, the data scientist has two choices: directly deploy the model, or create a training pipeline that can be scheduled or triggered manually or automatically. The following sections provide some insights into both options.
Deploy the model directly
If the data scientist is satisfied with the results obtained by the AutoML job, they can directly deploy the model from the Model Details page. It’s as simple as choosing Deploy model next to the model name.

SageMaker shows you two options for deployment: a real-time endpoint, powered by Amazon SageMaker endpoints, and batch inference, powered by Amazon SageMaker batch transform.
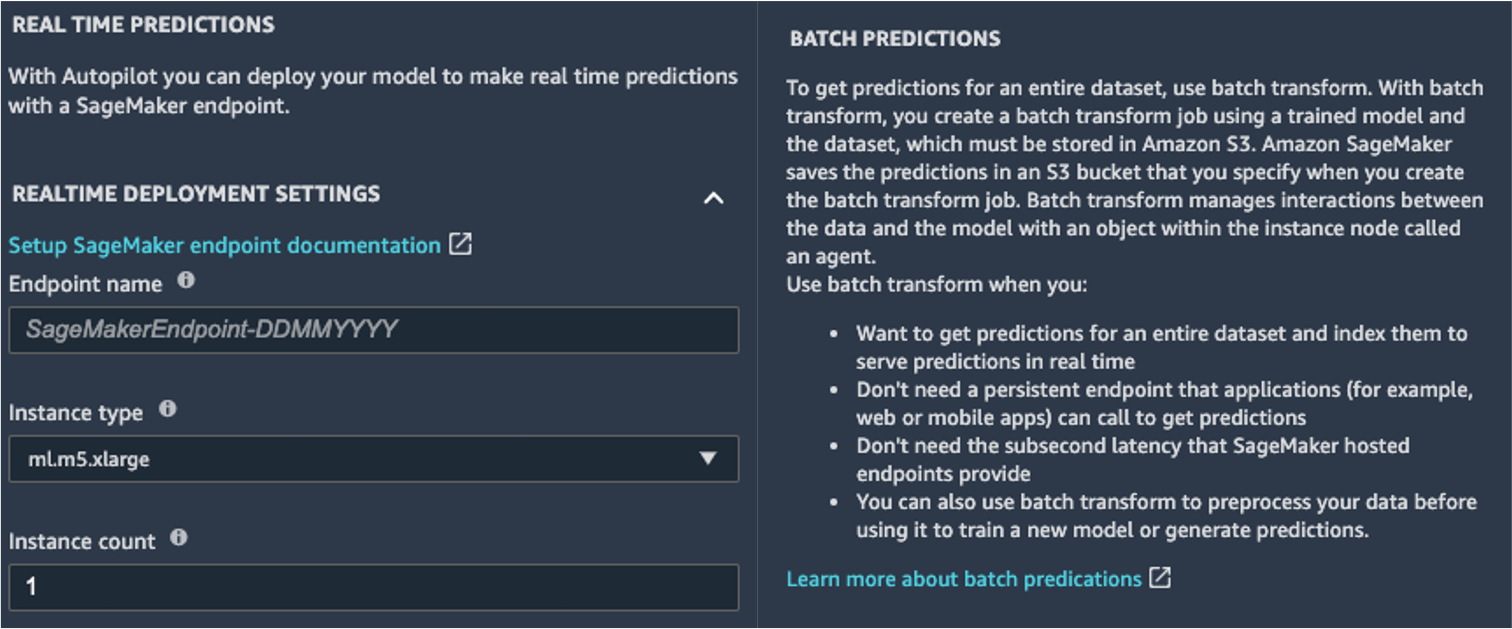
SageMaker also provides other modes of inference. To learn more, see Deploy Models for Inference.
To enable the real-time predictions mode, you simply give the endpoint a name, an instance type, and an instance count. Because this model doesn’t require heavy compute resources, you can use a CPU-based instance with an initial count of 1. You can learn more about the different kind of instances available and their specs on the Amazon SageMaker Pricing page (in the On-Demand Pricing section, choose the Real-Time Inference tab). If you don’t know which instance you should choose for your deployment, you can also ask SageMaker to find the best one for you according to your KPIs by using the SageMaker Inference Recommender. You can also provide additional optional parameters, regarding whether or not you want to capture request and response data to or from the endpoint. This can prove useful if you’re planning on monitoring your model. You can also choose which content you wish to provide as part of your response—whether it’s just the prediction or the prediction probability, the probability of all classes, and the target labels.
To run a batch scoring job getting predictions for an entire set of inputs at one time, you can launch the batch transform job from the AWS Management Console or via the SageMaker Python SDK. To learn more about batch transform, refer to Use Batch Transform and the example notebooks.
Define a training pipeline
ML models can very rarely, if ever, be considered static and unchanging, because they drift from the baseline they’ve been trained on. Real-world data evolves over time, and more patterns and insights emerge from it, which may or may not be captured by the original model trained on historical data. To solve this problem, you can set up a training pipeline that automatically retrains your models with the latest data available.
In defining this pipeline, one of the options of the data scientist is to once again use AutoML for the training pipeline. You can launch an AutoML job programmatically by invoking the create_auto_ml_job() API from the AWS Boto3 SDK. You can call this operation from an AWS Lambda function within an AWS Step Functions workflow, or from a LambdaStep in Amazon SageMaker Pipelines.
Alternatively, the data scientist can use the knowledge, artifacts, and hyper-parameters obtained from the AutoML job to define a complete training pipeline. You need the following resources:
-
The algorithm that worked best for the use case – You already obtained this information from the summary of the Canvas-generated model. For this use case, it’s the XGBoost built-in algorithm. For instructions on how to use the SageMaker Python SDK to train the XGBoost algorithm with SageMaker, refer to Use XGBoost with the SageMaker Python SDK.

-
The hyperparameters derived by the AutoML job – These are available in the Explainability section. You can use them as inputs when defining the training job with the SageMaker Python SDK.

-
The feature engineering code provided in the Artifacts section – You can use this code both for preprocessing the data before training (for example, via Amazon SageMaker Processing), or before inference (for example, as part of a SageMaker inference pipeline).

You can combine these resources as part of a SageMaker pipeline. We omit the implementation details in this post—stay tuned for more content coming on this topic.
Conclusion
SageMaker Canvas lets you use ML to generate predictions without needing to write any code. A business analyst can autonomously start using it with local datasets, as well as data already stored on Amazon Simple Storage Service (Amazon S3), Amazon Redshift, or Snowflake. With just a few clicks, they can prepare and join their datasets, analyze estimated accuracy, verify which columns are impactful, train the best performing model, and generate new individual or batch predictions, all without any need for pulling in an expert data scientist. Then, as needed, they can share the model with a team of data scientists or MLOps engineers, who import the models into SageMaker Studio, and work alongside the analyst to deliver a production solution.
Business analysts can independently gain insights from their data without having a degree in ML, and without having to write a single line of code. Data scientists can now have additional time to work on more challenging projects that can better use their extensive knowledge of AI and ML.
We believe this new collaboration opens the door to building many more powerful ML solutions for your business. You now have analysts producing valuable business insights, while letting data scientists and ML engineers help refine, tune, and extend as needed.
Additional Resources
- To learn more about how SageMaker can further help business analysts, refer to Amazon SageMaker for Business Analysts.
- To find out more about how SageMaker allows data scientists develop, train, and deploy their ML models, check out Amazon SageMaker for Data Scientists.
- For more information about how SageMaker can aid MLOps engineers in streamlining the ML lifecycle using MLOps, refer to Amazon SageMaker for MLOps Engineers.
About the Authors
 Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
Davide Gallitelli is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in Brussels and works closely with customers throughout Benelux. He has been a developer since he was very young, starting to code at the age of 7. He started learning AI/ML at university, and has fallen in love with it since then.
 Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.
Mark Roy is a Principal Machine Learning Architect for AWS, helping customers design and build AI/ML solutions. Mark’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. He has helped companies in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. Mark holds six AWS certifications, including the ML Specialty Certification. Prior to joining AWS, Mark was an architect, developer, and technology leader for over 25 years, including 19 years in financial services.