A guest post by Sandeep Mistry, Arm
Introduction
Emojis allow us to express emotions in the digital world, they are relatively easy to input on smartphone and tablet devices equipped with touch screen based virtual keyboards, but they are not as easy to input on traditional computing devices that have physical keyboards. To input emojis on these devices, users typically use a keyboard shortcut or mouse to bring up an on-screen emoji selector, and then use a mouse to select the desired emoji from a series of categories.
This blog will highlight an in-depth open-source guide that uses tinyML on an Arm Cortex-M based device to create a dedicated input device. This device will take real-time input from a camera and applies a machine learning (ML) image classification model to detect if the image from the camera contains a set of known hand gestures (✋, 👎, 👍, 👊). When the hand gesture is detected with high certainty, the device will then use the USB Human Interface Device (HID) protocol to “type” the emoji on the PC.
The TensorFlow Lite for Microcontrollers run-time with Arm CMSIS-NN is used as the on-device ML inferencing framework on the dedicated input device. On-device inferencing will allow us to reduce the latency of the system, as the image data will be processed at the source (instead of being transmitted to a cloud service). The user’s privacy will also be preserved, as no image data will leave the device at inference time.
|
NOTE: The complete in-depth and interactive tutorial is available on Google Colab and all technical assets for the guide can be found on GitHub. |
Microcontrollers and Keyboards
Microcontroller Units (MCUs) are self-contained computing systems embedded in the devices you use every day, including your keyboard! Like all computing systems, they have inputs and outputs.
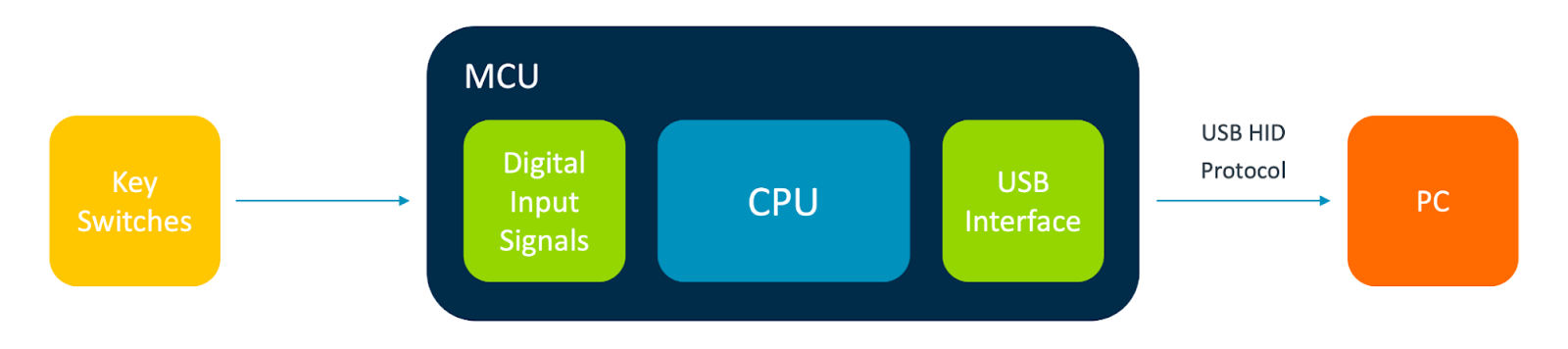 |
| Block diagram of USB keyboard |
 |
| Block diagram of computer vision based emoji “keyboard” |
The OpenMV development platform
OpenMV is an open source (Micro) Python powered Machine Vision platform. The OpenMV product line-up consists of several Arm Cortex-M based development boards. Each board is equipped with an on-board camera and MCU. For this project, the OpenMV Cam H7 or OpenMV Cam H7 R2 board will suit our needs.
What we will need
 |
| OpenMV Cam H7 Camera (left) and microSD card (right) |
- Hardware
- OpenMV Cam H7 or OpenMV Cam H7 R2 board
- MicroSD card with at least 2 MB of storage space
- USB micro cable
- Software
- Services
Dataset
The dataset contains ~23k image files of people performing various hand gestures over a 30 second period.
Images from the dataset will need to be relabeled as follows:
|
Since the swipe right and swipe left gestures in the Kaggle dataset do not correspond to any of these classes, any images in these classes will need to be discarded for our model.
Images in the Kaggle dataset are taken over a 30 second period, they might contain other gestures at the start or end of the series. For example, some of the people in the dataset started with their hands in a fist position before eventually going to the labeled gesture hand up, thumbs up and thumbs down. Other times the person in the dataset starts off with no hand gesture in frame.
We have gone ahead and manually re-labeled the images into the classes, it can be found in CSV format in the data folder on GitHub, and contains labels for ~14k images.
TensorFlow model
You can find more details on the training pipeline used here in this Colab Notebook.
Loading and Augmenting Images
Images from the dataset can be loaded as a TensorFlow Dataset using the tf.keras.utils.image_dataset_from_directory(…) API. This API supports adjusting the image’s color mode (to grayscale) and size (96×96 pixels) to meet the model’s desired input format. Built-in Keras layers for data augmentation (random: flipping, rotation, zooming, and contrast adjustments) will also be used during training.
Model Architecture
MobileNetV1 is a well-known model architecture used for image classification tasks, including the TensorLite for Microcontrollers Person detection example. This model architecture is trained on our dataset, with the same alpha (0.25) and image sizes (96x96x1) used in the Visual Wake Words Dataset paper. A MobileNetV1 model is composed of 28 layers, but a single call to the Keras tf.keras.applications.mobilenet.MobileNet(…) API can be used to easily create a MobileNetV1 model for 5 output classes and the desired alpha and input shape values:
|
mobilenet_025_96 = tf.keras.applications.mobilenet.MobileNet( |
The MicroPython based firmware used on the OpenMV Cam H7 does not include support for all of the layer types in the MobileNetV1 model created using the Keras API, however it can be adapted to use supported layers using only ~30 lines of Python code. Once the model is adapted and trained it can then be converted to TensorFlow Lite format using the tf.lite.TFLiteConverter.from_keras_model(..) API. The resulting .tflite file can then be used for on-device inference on the OpenMV development board.
OpenMV Application and inferencing
The .tflite model can then be integrated into the OpenMV application. You can find more details on the inference application in the Colab Notebook and full source code in the openmv folder on GitHub.
The application will loop continuously performing the following steps:
 |
| Block Diagram of Application processing pipeline |
- Grab an image frame from the camera.
- Get the ML model’s output for the captured image frame.
- Filter the ML model’s output for high certainty predictions using “low activation” and “margin of confidence” techniques.
- Use an exponential smoothing function to smooth the model’s noisy (Softmax) outputs.
- Use the exponentially smoothed model outputs to determine if a new hand gesture is present.
- Then “type” the associated emoji on a PC using the USB HID protocol.
Conclusion
Throughout this project we’ve covered an end-to-end flow of training a custom image classification model and how to deploy it locally to a Arm Cortex-M7 based OpenMV development board using TensorFlow Lite! TensorFlow was used in a Google Colab notebook to train the model on a re-labeled public dataset from Kaggle. After training, the model was converted into TensorFlow Lite format to run on the OpenMV board using the TensorFlow Lite for Microcontrollers run-time along with accelerated Arm CMSIS-NN kernels.
At inference time the model’s outputs were processed using model certainty techniques, and then fed output from the (Softmax) activation output into an exponential smoothing function to determine when to send keystrokes over USB HID to type emojis on a PC. The dedicated input device we created was able to capture and process grayscale 96×96 image data at just under 20 fps on an Arm Cortex-M7 processor running at 480 MHz. On-device inferencing provided a low latency response and preserved the privacy of the user by keeping all image data at the source and processing it locally.
Build one yourself by purchasing an OpenMV Cam H7 R2 board on openmv.io or a distributor. The project can be extended by fine tuning the model on your own data or applying transfer learning techniques and using the model we developed as base to train other hand gestures. Maybe you can find another public dataset for facial gestures and use it to type 😀 emojis when you smile!
A big thanks to Sparsh Gupta for sharing the Gesture Recognition dataset on Kaggle under a public domain license and my Arm colleagues Rod Crawford, Prathyusha Venkata, Elham Harirpoush, and Liliya Wu for their help in reviewing the material for this blog post and associated tutorial!