Natural language processing (NLP) has witnessed impressive developments
in answering questions, summarizing or translating reports, and
analyzing sentiment or offensiveness. Much of this progress is owed to
training ever-larger language models, such
as T5 or GPT-3,
that use deep monolithic architectures to internalize how language is
used within text from massive Web crawls. During training, these models
distill the facts they read into implicit knowledge, storing in their
parameters not only the capacity to “understand” language tasks, but
also highly abstract knowledge representations of entities, events, and
facts the model needs for solving tasks.
Despite the well-publicized success of large language models, their
black-box nature hinders key goals of NLP. In particular, existing large
language models are generally:
-
Inefficient. Researchers continue to enlarge these models, leading
to striking inefficiencies as the field already pushes past 1
trillion parameters. This imposes a considerable environmental impact
and its costs exclude all but a few large organizations from the
ability to train—or in many cases even deploy—such models. -
Opaque. They encode “knowledge” into model weights, synthesizing
what they manage to memorize from training examples. This makes it
difficult to discern what sources—if any—the model uses to make a
prediction, a concerning problem in practice as these models
frequently generate fluent yet untrue statements. -
Static. They are expensive to update. We cannot efficiently adapt a
GPT model trained on, say, Wikipedia text from 2019 so it reflects
the knowledge encoded in the 2021 Wikipedia—or the latest snapshot
of the medical preprint server medRXiv. In practice, adaptation often
necessitates expensive retraining or fine-tuning on the new corpus.
This post explores an emerging alternative, Retrieval-based NLP, in
which models directly “search” for information in a text corpus to
exhibit knowledge, leveraging the representational strengths of language models
while addressing the challenges above. Such
models—including REALM, RAG, ColBERT-QA,
and Baleen—are
already advancing the state of the art for tasks like answering
open-domain questions and verifying complex claims, all with
architectures that back their predictions with checkable sources while
being 100–1000× smaller, and thus far cheaper to execute, than GPT-3. At
Stanford, we have shown that improving the expressivity and
supervision of scalable neural retrievers can lead to much stronger NLP
systems: for instance, ColBERT-QA improves answer correctness on open-QA
benchmarks by up to 16 EM points and Baleen improves the ability to
check complex claims on
HoVer,
correctly and with provenance, by up to 42 percentage points against existing work.
Retrieval-based NLP
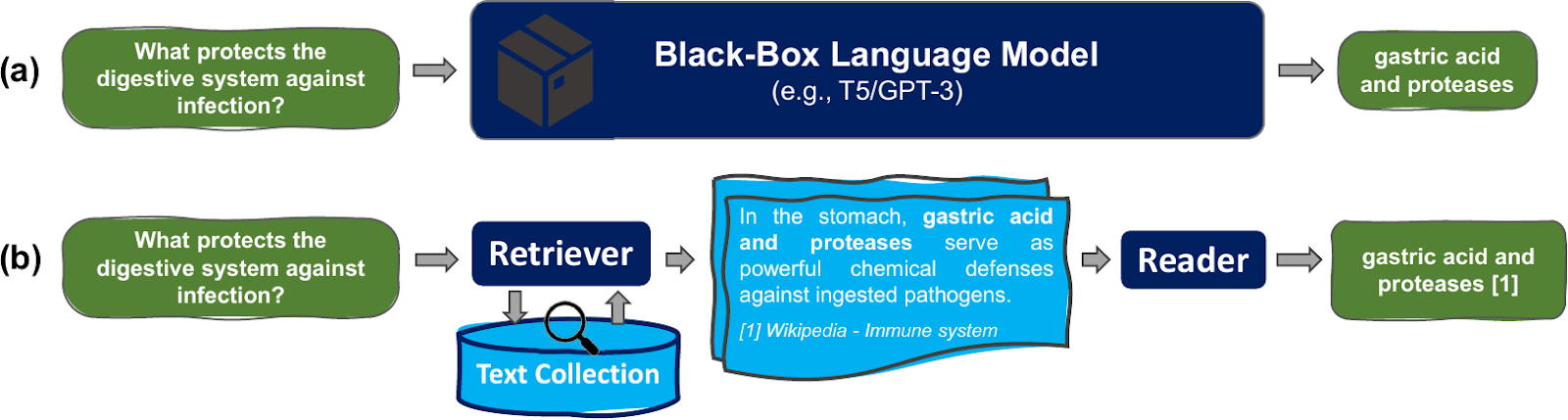
As Figure 1 illustrates, retrieval-based NLP methods view tasks as
“open-book”
exams: knowledge is encoded explicitly in the form of a text corpus like
Wikipedia, the medical literature, or a software’s API documentation. When
solving a language task, the model learns to search for pertinent passages
and to then use the retrieved information for crafting knowledgeable responses.
In doing so, retrieval helps decouple the capacity that language models have for
understanding text from how they store knowledge, leading to three key advantages.
Tackling Inefficiency. Retrieval-based models can be much smaller and
faster, and thus more environmentally friendly. Unlike black-box language models,
the parameters no longer need to store an ever-growing list of facts, as
such facts can be retrieved. Instead, we can dedicate those parameters
for processing language and solving tasks, leaving us with smaller
models that are highly effective. For instance, ColBERT-QA achieves
47.8% EM on the open-domain Natural Questions task, whereas a fine-tuned
T5-11B model (with 24x more parameters) and a few-shot GPT-3 model (with
400x more parameters) achieve only 34.8% and 29.9%, respectively.
Tackling Opaqueness. Retrieval-based NLP offers a transparent contract
with users: when the model produces an answer, we can read the sources
it retrieved and judge their relevance and credibility for ourselves.
This is essential whether the model is factually correct or not: by
inspecting the sources surfaced by a system like Baleen, we can trust
its outputs only if we find that reliable sources do support them.
Tackling Static Knowledge. Retrieval-based models emphasize learning
general techniques for finding and connecting information from the
available resources. With facts stored as text, the retrieval knowledge
store can be efficiently updated or expanded by modifying the text
corpus, all while the model’s capacity for finding and using information
remains constant. Besides computational cost reductions, this expedites generality:
developers, even in niche domains, can “plug in” a domain-specific text
collection and rely on retrieval to facilitate domain-aware responses.
ColBERT: Scalable yet expressive neural retrieval
As the name suggests, retrieval-based NLP relies on semantically rich search to extract
information. For search be practical and effective, it must scale to massive text corpora.
To draw on the open-book exam analogy, it’s hopeless to linearly look
through the pages of a hefty textbook during the exam—we need scalable
strategies for organizing the content in advance, and efficient
techniques for locating relevant information at inference time.
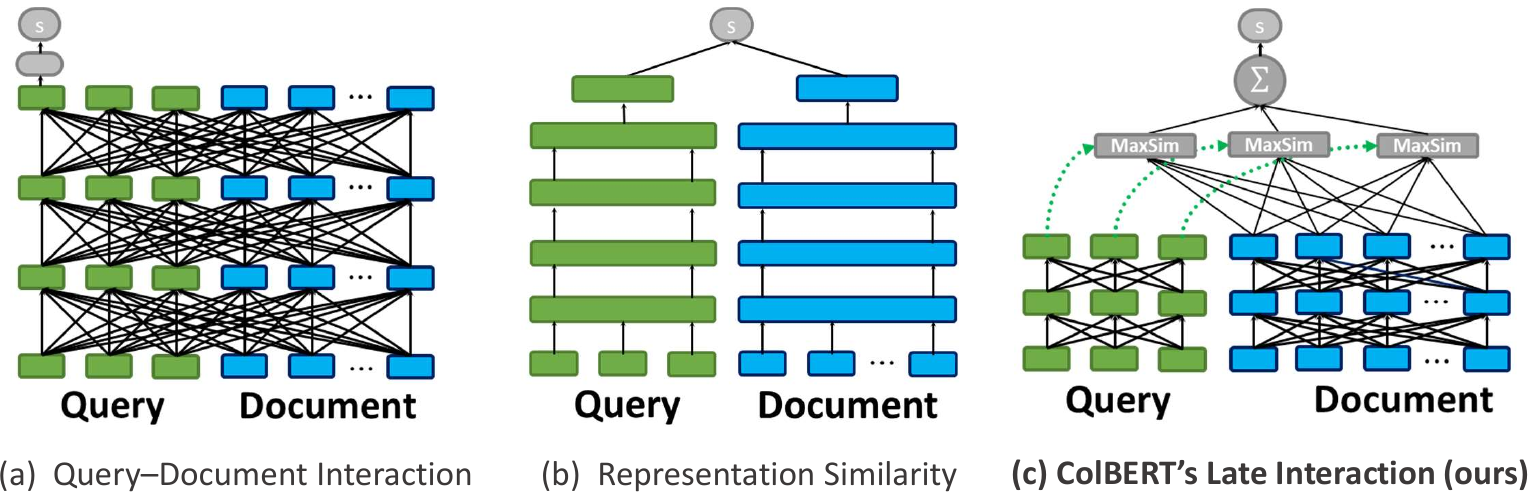
Traditionally in IR, search tasks were conducted using bag-of-words
models like BM25, which seek documents that contain the same tokens as
the query. In
2019, search was revolutionized with BERT for
ranking and its deployment
in Google and Bing for
Web search. The standard approach is illustrated in Figure 2(a). Each
document is concatenated with the query, and both are fed jointly into a BERT
model, fine-tuned to estimate relevance. BERT doubled the MRR@10 quality
metric over BM25 on the popular MS MARCO Passage Ranking leaderboard,
but it simultaneously posed a fundamental limitation: scoring
each query–document pair requires billions of computational operations
(FLOPs). As a result, BERT can only be used to re-rank the top-k (e.g.,
top-1000) documents already extracted by simpler methods like BM25,
having no capacity to recover useful documents that bag-of-word search
misses.
The key limitation of this approach is that it encodes queries and
documents jointly. Many representation-similarity systems have been
proposed to tackle this, some of which re-purpose BERT within the
paradigm depicted in Figure 2(b). In these systems
(like SBERT and ORQA,
and more
recently DPR and ANCE,
every document in the corpus is fed into a BERT encoder that produces a
dense vector meant to capture the semantics of the document. At search
time, the query is encoded, separately, through another BERT encoder, and the
top-k related documents are found using a dot product between the query
and document vectors. By removing the expensive interactions between the
query and the document, these models are able to scale far more
efficiently than the approach in Figure 2(a).
Nonetheless, representation-similarity models suffer from an
architectural bottleneck: they encode the query and document into
coarse-grained representations and model relevance as a single dot
product. This greatly diminishes quality compared with expensive
re-rankers that model token-level interactions between the contents of
queries and documents. Can we efficiently scale fine-grained, contextual
interactions to a massive corpus, without compromising speed or quality?
It turns out that the answer is “yes”, using a paradigm called late
interaction, first devised in
our ColBERT1 [code]
model, which appeared at SIGIR 2020.
As depicted in Figure 2(c), ColBERT independently encodes queries and
documents into fine-grained multi-vector representations. It then
attempts to softly and contextually locate each query token inside the
document: for each query embedding, it finds the most similar embedding
in the document with a “MaxSim” operator and then sums up all of the
MaxSims to score the document. “MaxSim” is a careful choice that allows
us to index the document embeddings for Approximate Nearest Neighbor
(ANN) search, enabling us to scale this rich interaction to millions of passages with latency
on the order of tens of milliseconds. For instance, ColBERT can search over all
passages in English Wikipedia in approximately 70 milliseconds per query.
On MS MARCO Passage Ranking, ColBERT preserved the MRR@10 quality of BERT re-rankers while boosting recall@1k to nearly 97%
against the official BM25 ranking’s recall@1k of just 81%.
Making neural retrievers more lightweight remains an active area of
development, with models like DeepImpact
that trade away some quality for extreme forms of efficiency and
developments like BPR
and quantized ColBERT
that reduce the storage footprint by an order of magnitude while
preserving the quality of DPR and ColBERT, respectively.
ColBERT-QA and Baleen: Specializing neural retrieval to complex tasks, with tracked provenance
While scaling expressive search mechanisms is critical, NLP models need
more than just finding the right documents. In particular, we want NLP models
to use retrieval to answer questions, fact-check claims, respond
informatively in a conversation, or identify the sentiment of a piece of
text. Many tasks of this kind—dubbed knowledge-intensive language
tasks—are collected in
the KILT benchmark.
The most popular task is open-domain question answering (or Open-QA).
Systems are given a question from any domain and must produce an answer,
often by reference to the passages in a large corpus, as depicted in
Figure 1(b).
| Benchmark | System | Metric | Gains | Baselines |
|---|---|---|---|---|
| Open-Domain Question Answering | ||||
| Open-NaturalQuestions | ColBERT-QA | Answer Match | +3 | RAG, DPR, REALM, BM25+BERT |
| Open-TriviaQA | +12 | |||
| Open-SQuAD | +17 | |||
| Multi-Hop Reasoning | ||||
| HotPotQA | Baleen | Retrieval Success@20 | +10 / NA | MDR / IRRR |
| Passage-Pair Match | +5 / +3 | |||
| HoVer | Retrieval Success@100 | +48 / +17 | TF-IDF / ColBERT-Hop | |
| “HoVer Score” for Claim Verification with Provenance |
+42 | Official “TF-IDF + BERT” Baseline | ||
| Cross-Lingual Open-Domain Question Answering | ||||
| XOR TyDi | GAAMA with ColBERT from IBM Research |
Recall@5000-tokens | +10 | Official “DPR + Vanilla Transformer” Baseline |
| Zero-Shot Information Retrieval | ||||
| BEIR | ColBERT | Recall@100 | Outperforms other off-the-shelf dense retrievers on 13/17 tasks |
DPR, ANCE, SBERT, USE-QA |
Two popular models in this space are REALM and RAG, which rely on the
ORQA and DPR retrievers discussed earlier. REALM and RAG jointly tune a
retriever as well as a reader, a modeling component that consumes the
retrieved documents and produces answers or responses. Take RAG as an
example: its reader is a generative BART model, which attends to the
passages while generating the target outputs. While they constitute
important steps toward retrieval-based NLP, REALM and RAG suffer from
two major limitations. First, they use the restrictive paradigm of
Figure 2(b) for retrieval, thereby sacrificing recall: they are often
unable to find relevant passages for conducting their tasks. Second,
when training the retriever, REALM and RAG collect documents by
searching for them inside the training loop and, to make this practical, they
freeze the document encoder when fine-tuning, restricting the model’s adaptation to the task.
ColBERT-QA2 is an Open-QA system (published at TACL’21) that we built on
top of ColBERT to tackle both problems. By adapting ColBERT’s expressive search to the task,
ColBERT-QA finds useful passages for a larger fraction of the questions and thus
enables the reader component to answer more questions correctly and with provenance.
In addition, ColBERT-QA introduces relevance-guided supervision (RGS),
a training strategy whose goal is to adapt a
retriever like ColBERT to the specifics of an NLP task like Open-QA. RGS
proceeds in discrete rounds, using the retriever trained in the previous
round to collect “positive” passages that are likely useful for the
reader—specifically, passages ranked highly by the latest version of the
retriever and that also overlap with the gold answer of the question—and
challenging “negative” passages. By converging to a high coverage of
positive passages and by effectively sampling hard negatives, ColBERT-QA
improves retrieval Success@20 by more than 5-, 5-, and 12-point gains on
the open-domain QA settings of NaturalQuestions, TriviaQA, and SQuAD, and thus greatly
improves downstream answer match.
A more sophisticated version of the Open-QA task is multi-hop reasoning,
where systems must answer questions or verify claims by gathering
information from multiple sources. Systems in this space,
like GoldEn, MDR,
and IRRR,
find relevant documents and “hop” between them—often by running
additional searches—to find all pertinent sources. While these models
have demonstrated strong performance for two-hop tasks, scaling robustly
to more hops is challenging as the search space grows exponentially.
To tackle this, our Baleen3 system
(accepted as a Spotlight paper at NeurIPS’21) introduces a richer pipeline for
multi-hop retrieval: after each retrieval “hop”, Baleen summarizes the
pertinent information from the passages into a short context that is used
to inform future hops. In doing so, Baleen controls the search space
architecturally—obviating the need to explore each potential passage
at every hop—without sacrificing recall. Baleen also extends ColBERT’s
late interaction: it allows the representations of different documents
to “focus” on distinct parts of the same query, as each of those documents
in the corpus might satisfy a distinct aspect of the same complex query.
As a result of its more deliberate architecture and its stronger
retrieval modeling, Baleen saturates retrieval on the popular two-hop
HotPotQA benchmark (raising answer-recall@20 from 89% by MDR to 96%) and
dramatically improves performance on the harder four-hop claim
verification
benchmark HoVer,
finding all required passages in 92% of the examples—up from just 45%
for the official baseline and 75% for a many-hop flavor of ColBERT.
In these tasks, when our retrieval-based models make predictions, we can
inspect their underlying sources and decide whether we can trust the
answer. And when model errors stem from specific sources, those can be
removed or edited, and making sure models are faithful to such edits
is an active area of work.
Generalizing models to new domains with robust neural retrieval
In addition to helping with efficiency and transparency, retrieval
approaches promise to make domain generalization and knowledge updates
much easier in NLP. Exhibiting up-to-date, domain-specific knowledge is
essential for many applications: you might want to answer questions over
recent publications on COVID-19 or to develop a chatbot that guides
customers to suitable products among those currently available in a
fast-evolving inventory. For such applications, NLP models should be
able to leverage any corpus provided to them, without having to train a
new version of the model for each emerging scenario or domain.
While large language models are trained using plenty of data from the
Web, this snapshot is:
-
Static. The Web evolves as the world does: Wikipedia articles
reflect new elected officials, news articles describe current events, and
scientific papers communicate new research. Despite this, a language
model trained in 2020 has no way to learn about 2021 events, short
of training and releasing a new version of the model. -
Incomplete. Many topics are under-represented in Web crawls like C4
and The Pile. Suppose we seek to answer questions over the ACL
papers published 2010–2021; there is no guarantee that The Pile
contains all papers from the ACL Anthology a priori and there is no
way to plug that in ad-hoc without additional training. Even when
some ACL papers are present (e.g., through arXiv, which is included
in The Pile), they form only a tiny sliver of the data, and it is
difficult to reliably restrict the model to specifically those
papers for answering NLP questions. -
Public-only. Many applications hinge on private text, like internal
company policies, in-house software documentation, copyrighted
textbooks and novels, or personal email. Because models like GPT-3
never see such data in their training, they are fundamentally
incapable of exhibiting knowledge pertaining to those topics without
special re-training or fine-tuning.
With retrieval-based NLP, models learn effective ways to encode and
extract information, allowing them to generalize to updated text,
specialized domains, or private data without resorting to additional
training. This suggests a vision where developers “plug in” their text
corpus, like in-house software documentation, which is indexed by a
powerful retrieval-based NLP model that can then answer questions, solve
classification tasks, or generate summaries using the knowledge from the
corpus, while always supporting its predictions with provenance from the
corpus.
An exciting benchmark connected to this space
is BEIR,
which evaluates retrievers on their capacity for search “out-of-the-box”
on unseen IR tasks, like Argument Retrieval, and in new domains, like
the COVID-19 research literature. While retrieval offers a concrete
mechanism for generalizing NLP models to new domains, not every IR model
generalizes equally: the BEIR evaluations highlight the impact of
modeling and supervision choices on generalization. For instance, due to
its late interaction modeling, a vanilla off-the-shelf ColBERT retriever
achieved the strongest recall of all competing IR models in the initial
BEIR evaluations, outperforming the other off-the-shelf dense
retrievers—namely, DPR, ANCE, SBERT, and USE-QA—on 13 out of 17
datasets. The BEIR benchmark continues to develop quickly, a recent
addition being the
TAS-B model,
which advances a sophisticated supervision approach to distill ColBERT
and BERT models into single-vector representations, inheriting much of
their robustness in doing so. While retrieval allows rapid deployment in new
domains, explicitly adapting retrieval to new scenarios is also
possible. This is an active area of research, with work
like QGen and AugDPR that
generate synthetic questions and use those to explicitly fine-tune
retrievers for targeting a new corpus.
Summary: Is retrieval “all you need”?
The black-box nature of large language models like T5 and GPT-3 makes
them inefficient to train and deploy, opaque in their knowledge representations and in backing
their claims with provenance, and static in facing a constantly evolving world and diverse downstream contexts.
This post explores retrieval-based NLP, where models retrieve information
pertinent to solving their tasks from a plugged-in text corpus. This
paradigm allows NLP models to leverage the representational strengths
of language models, while needing much smaller architectures, offering
transparent provenance for claims, and enabling efficient updates and adaptation.
We surveyed much of the existing and emerging work in this space and
highlighted some of our work at Stanford, including
ColBERT
for scaling up expressive retrieval to massive corpora via late
interaction,
ColBERT-QA for
accurately answering open-domain questions by adapting high-recall
retrieval to the task, and
Baleen for
solving tasks that demand information from several independent sources
using a condensed retrieval architecture.
We continue to actively maintain
our code as open source.
Acknowledgments. We would like to thank Megha Srivastava and Drew A. Hudson for helpful comments and feedback on this blog post. We also thank Ashwin Paranjape, Xiang Lisa Li, and Sidd Karamcheti for valuable and insightful discussions.
-
Omar Khattab and Matei Zaharia. “ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT.” Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 2020. ↩
-
Omar Khattab, Christopher Potts, Matei Zaharia; “Relevance-guided Supervision for OpenQA with ColBERT.” Transactions of the Association for Computational Linguistics 2021; 9 929–944. doi: https://doi.org/10.1162/tacl_a_00405 ↩
-
Omar Khattab, Christopher Potts, and Matei Zaharia. “Baleen: Robust Multi-Hop Reasoning at Scale via Condensed Retrieval.” (To appear at NeurIPS 2021.) arXiv preprint arXiv:2101.00436 (2021). ↩