This is a guest blog post co-written with Minghui Yu and Jianzhe Xiao from Bytedance.
ByteDance is a technology company that operates a range of content platforms to inform, educate, entertain, and inspire people across languages, cultures, and geographies. Users trust and enjoy our content platforms because of the rich, intuitive, and safe experiences they provide. These experiences are made possible by our machine learning (ML) backend engine, with ML models built for content moderation, search, recommendation, advertising, and novel visual effects.
The ByteDance AML (Applied Machine Learning) team provides highly performant, reliable, and scalable ML systems and end-to-end ML services for the company’s business. We were researching ways to optimize our ML inference systems to reduce costs, without increasing response times. When AWS launched AWS Inferentia, a high-performance ML inference chip purpose-built by AWS, we engaged with our AWS account team to test if AWS Inferentia can address our optimization goals. We ran several proofs of concept, resulting in up to 60% lower inference cost compared to T4 GPU-based EC2 G4dn instances and up to 25% lower inference latency. To realize these cost savings and performance improvements, we decided to deploy models on AWS Inferentia-based Amazon Elastic Compute Cloud (Amazon EC2) Inf1 instances in production.
The following chart shows the latency improvement for one of our face detection models that was previously deployed on GPUs with Tensor RT. The average latency decreased by 20% (from 50 milliseconds to 40 milliseconds), and the p99 latency decreased by 25% (from 200 milliseconds to 150 milliseconds).
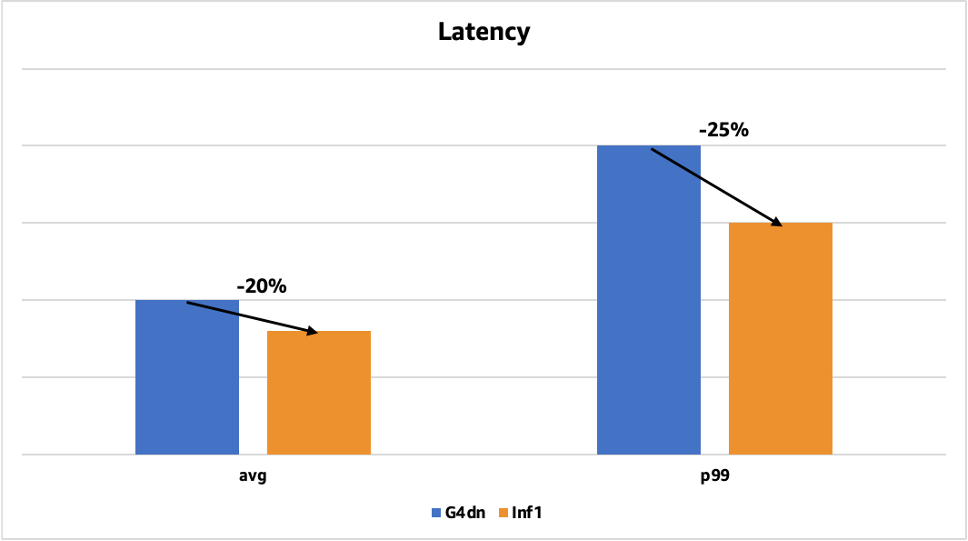
In this post, we share how we saved on inference costs while reducing latencies and increasing throughput using AWS Inferentia.
In search of high-performance, cost-effective compute
The ByteDance AML team focuses on the research and implementation of cutting-edge ML systems and the heterogenous computing resources they require. We create large-scale training and inference systems for a wide variety of recommender, natural language processing (NLP), and computer vision (CV) models. These models are highly complex and process a huge amount of data from the many content platforms ByteDance operates. Deploying these models requires significant GPU resources, whether in the cloud or on premises. Therefore, the compute costs for these inference systems are quite high.
We were looking to lower these costs without impacting throughput or latency. We wanted the cloud’s flexibility and faster delivery cycle, which is much shorter than the one needed for an on-premises setup. And although we were open to exploring new options for accelerated ML, we also wanted a seamless developer experience.
We learned from our AWS team that AWS Inferentia-based EC2 Inf1 instances deliver high-performance ML inference at the lowest cost-per-inference in the cloud. We were curious to explore them and found them to be well-suited to our use case, because we run substantial machine learning on large amounts of image, object, speech, and text data. They were definitely a good fit for our goals, because we could realize huge cost savings given the complexity of our models and volume of daily predictions. Furthermore, AWS Inferentia features a large amount of on-chip memory, which you can use for caching large models instead of storing them off chip. We recognized that this can have a significant impact in reducing inference latency because the processing cores of AWS Inferentia, called NeuronCores, have high-speed access to models that are stored in on-chip memory and aren’t limited by the off-chip memory bandwidth.
Ultimately, after evaluating several options, we chose EC2 Inf1 instances for their better performance/price ratio compared to G4dn instances and NVIDIA T4 on premises. We engaged in a cycle of continuous iteration with the AWS team to unlock the price and performance benefits of Inf1.
Deploying inference workloads on AWS Inferentia
Getting started with AWS Inferentia using the AWS Neuron SDK involved two phases: compilation of model code and deployment on Inf1 instances. As is common when moving ML models to any new infrastructure, there were some challenges that we faced. We were able to overcome these challenges with diligence and support from our AWS team. In the following sections, we share several useful tips and observations based on our experience deploying inference workloads on AWS Inferentia.
Conformer model for OCR
Our optical character recognition (OCR) conformer model detects and reads text within images. We worked on several optimizations to get high performance (QPS) for a variety of batch sizes, while keeping the latency low. Some key optimizations are noted below:
- Compiler optimizations – By default, Inferentia performs best on inputs with a fixed sequence length, which presented a challenge as the length of textual data is not fixed. To overcome this, we split our model into two parts: an encoder and a decoder. We compiled these two sub-models separately and then merged them into a single model via TorchScript. By running the for loop control flow on CPUs, this approach enabled support for variable sequence lengths on Inferentia.
- Depthwise convolution performance – We encountered a DMA bottleneck in the depthwise convolution operation, which is heavily used by our conformer model. We worked closely with the AWS Neuron team to identify and resolve the DMA access performance bottleneck, which improved the performance of this operation and improved the overall performance of our OCR model.
We created two new model variants to optimize our deployment on Inferentia:
- Combined and unrolled encoder/decoder – Instead of using an independently compiled encoder and decoder, we combined the encoder and a fully unrolled decoder into a single model and compiled this model as a single NEFF. Unrolling the decoder makes it possible to run all of the decoder control flow on Inferentia without using any CPU operations. With this approach, each iteration of the decoder uses exactly the amount of compute necessary for that token. This approach improves performance because we significantly reduce the excess computation that was previously introduced by padding inputs. Furthermore, no data transfer from Inferentia to CPU is necessary between decoder iterations, which drastically reduces I/O time. This version of the model does not support early stopping.
- Partitioned unrolled decoder – Similar to the combined fully unrolled model, this variant of the model unrolls multiple iterations of the decoder and compiles them as a single execution (but does not include the encoder). For example, for a maximum sequence length of 75, we can unroll the decoder into 3 partitions which compute tokens 1-25, 26-50, and 51-75. In terms of I/O, this is also significantly faster because we do not need to transfer the encoder output once per every iteration. Instead, the outputs are only transferred once per each decoder partition. This version of the model does support early stopping, but only at the partition boundaries. The partition boundaries can be tuned for each specific application to ensure that the majority of requests execute only one partition.
To further improve performance, we made the following optimizations to reduce memory usage or improve access efficiency:
- Tensor deduplication and reduced copies – This is a compiler optimization that significantly reduces the size of unrolled models and the number of instructions/memory access by reusing tensors to improve space efficiency.
- Reduced instructions – This is a compiler optimization that is used with the non-padded version of the decoder to significantly reduce the total number of instructions.
- Multi-core deduplication – This is a runtime optimization that is an alternative to the tensor deduplication. With this option, all multicore models will be significantly more space efficient.
ResNet50 model for image classification
ResNet-50 is a pre-trained deep learning model for image classification. It is a Convolutional Neural Network (CNN or ConvNet) that is most commonly applied to analyzing visual imagery. We used the following techniques to improve this model’s performance on Inferentia:
- Model transformation – Many of ByteDance’s models are exported in ONNX format, which Inferentia currently does not natively support. To handle these ONNX models, the AWS Neuron team provided scripts to transform our models from ONNX format to PyTorch models, which can be directly compiled for Inferentia using torch-neuron.
- Performance optimization – We worked closely with the AWS Neuron team to tune the scheduling heuristic in the compiler to optimize performance of our ResNet-50 models.
Multi-modal model for content moderation
Our multi-modal deep learning model is a combination of multiple separate models. The size of this model is relatively large, which caused model loading failures on Inferentia. The AWS Neuron team successfully solved this problem by using weight sharing to reduce the device memory usage. The Neuron team released this weight de-duplication feature in the Neuron libnrt library and also improved Neuron Tools for more precise metrics. The runtime weight de-duplication feature can be enabled by setting the following environment variable before running inference:
NEURON_RT_MULTI_INSTANCE_SHARED_WEIGHTS=1
The updated Neuron SDK reduced the overall memory consumption of our duplicated models, which enabled us to deploy our multi-modal model for multi-core inference.
Migrating more models to AWS Inferentia
At ByteDance, we continue to deploy innovative deep learning models to deliver delightful user experiences to almost 2 billion monthly active users. Given the massive scale at which we operate, we’re constantly looking for ways to save costs and optimize performance. We will continue to migrate models to AWS Inferentia to benefit from its high performance and cost-efficiency. We also want AWS to launch more AWS Inferentia-based instance types, such as ones with more vCPUs for preprocessing tasks. Going forward, ByteDance is hoping to see more silicon innovation from AWS to deliver the best price performance for ML applications.
If you’re interested in learning more about how AWS Inferentia can help you save costs while optimizing performance for your inference applications, visit the Amazon EC2 Inf1 instances product page.
About the Authors
 Minghui Yu is a Senior Machine Learning Team Lead for Inference at ByteDance. His focus area is AI Computing Acceleration and Machine Learning System. He is very interested in heterogeneous computing and computer architecture in the post Moore era. In his spare time, he likes basketball and archery.
Minghui Yu is a Senior Machine Learning Team Lead for Inference at ByteDance. His focus area is AI Computing Acceleration and Machine Learning System. He is very interested in heterogeneous computing and computer architecture in the post Moore era. In his spare time, he likes basketball and archery.
 Jianzhe Xiao is a Senior Software Engineer Team Lead in AML Team at ByteDance. His current work focuses on helping the business team speed up the model deploy process and improve the model’s inference performance. Outside of work, he enjoys playing the piano.
Jianzhe Xiao is a Senior Software Engineer Team Lead in AML Team at ByteDance. His current work focuses on helping the business team speed up the model deploy process and improve the model’s inference performance. Outside of work, he enjoys playing the piano.
 Tian Shi is a Senior Solutions Architect at AWS. His focus area is data analytics, machine learning and serverless. He is passionate about helping customers design and build reliable and scalable solutions on the cloud. In his spare time, he enjoys swimming and reading.
Tian Shi is a Senior Solutions Architect at AWS. His focus area is data analytics, machine learning and serverless. He is passionate about helping customers design and build reliable and scalable solutions on the cloud. In his spare time, he enjoys swimming and reading.
 Jia Dong is Customer Solutions Manager at AWS. She enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Jia enjoys travel, Yoga and movies.
Jia Dong is Customer Solutions Manager at AWS. She enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Jia enjoys travel, Yoga and movies.
 Jonathan Lunt is a software engineer at Amazon with a focus on ML framework development. Over his career he has worked through the full breadth of data science roles including model development, infrastructure deployment, and hardware-specific optimization.
Jonathan Lunt is a software engineer at Amazon with a focus on ML framework development. Over his career he has worked through the full breadth of data science roles including model development, infrastructure deployment, and hardware-specific optimization.
 Joshua Hannan is a machine learning engineer at Amazon. He works on optimizing deep learning models for large-scale computer vision and natural language processing applications.
Joshua Hannan is a machine learning engineer at Amazon. He works on optimizing deep learning models for large-scale computer vision and natural language processing applications.
 Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.
Shruti Koparkar is a Senior Product Marketing Manager at AWS. She helps customers explore, evaluate, and adopt EC2 accelerated computing infrastructure for their machine learning needs.