People can flexibly maneuver objects in their physical surroundings to accomplish various goals. One of the grand challenges in robotics is to successfully train robots to do the same, i.e., to develop a general-purpose robot capable of performing a multitude of tasks based on arbitrary user commands. Robots that are faced with the real world will also inevitably encounter new user instructions and situations that were not seen during training. Therefore, it is imperative for robots to be trained to perform multiple tasks in a variety of situations and, more importantly, to be capable of solving new tasks as requested by human users, even if the robot was not explicitly trained on those tasks.
Existing robotics research has made strides towards allowing robots to generalize to new objects, task descriptions, and goals. However, enabling robots to complete instructions that describe entirely new tasks has largely remained out-of-reach. This problem is remarkably difficult since it requires robots to both decipher the novel instructions and identify how to complete the task without any training data for that task. This goal becomes even more difficult when a robot needs to simultaneously handle other axes of generalization, such as variability in the scene and positions of objects. So, we ask the question: How can we confer noteworthy generalization capabilities onto real robots capable of performing complex manipulation tasks from raw pixels? Furthermore, can the generalization capabilities of language models help support better generalization in other domains, such as visuomotor control of a real robot?
In “BC-Z: Zero-Shot Task Generalization with Robotic Imitation Learning”, published at CoRL 2021, we present new research that studies how robots can generalize to new tasks that they were not trained to do. The system, called BC-Z, comprises two key components: (i) the collection of a large-scale demonstration dataset covering 100 different tasks and (ii) a neural network policy conditioned on a language or video instruction of the task. The resulting system can perform at least 24 novel tasks, including ones that require interaction with pairs of objects that were not previously seen together. We are also excited to release the robot demonstration dataset used to train our policies, along with pre-computed task embeddings.
 |
| The BC-Z system allows a robot to complete instructions for new tasks that the robot was not explicitly trained to do. It does so by training the policy to take as input a description of the task along with the robot’s camera image and to predict the correct action. |
Collecting Data for 100 Tasks
Generalizing to a new task altogether is substantially harder than generalizing to held-out variations in training tasks. Simply put, we want robots to have more generalization all around, which requires that we train them on large amounts of diverse data.
We collect data by teleoperating the robot with a virtual reality headset. This data collection follows a scheme similar to how one might teach an autonomous car to drive. First, the human operator records complete demonstrations of each task. Then, once the robot has learned an initial policy, this policy is deployed under close supervision where, if the robot starts to make a mistake or gets stuck, the operator intervenes and demonstrates a correction before allowing the robot to resume.
This mixture of demonstrations and interventions has been shown to significantly improve performance by mitigating compounding errors. In our experiments, we see a 2x improvement in performance when using this data collection strategy compared to only using human demonstrations.
| Example demonstrations collected for 12 out of the 100 training tasks, visualized from the perspective of the robot and shown at 2x speed. |
Training a General-Purpose Policy
For all 100 tasks, we use this data to train a neural network policy to map from camera images to the position and orientation of the robot’s gripper and arm. Crucially, to allow this policy the potential to solve new tasks beyond the 100 training tasks, we also input a description of the task, either in the form of a language command (e.g., “place grapes in red bowl”) or a video of a person doing the task.
 |
| To accomplish a variety of tasks, the BC-Z system takes as input either a language command describing the task or a video of a person doing the task, as shown here. |
By training the policy on 100 tasks and conditioning the policy on such a description, we unlock the possibility that the neural network will be able to interpret and complete instructions for new tasks. This is a challenge, however, because the neural network needs to correctly interpret the instruction, visually identify relevant objects for that instruction while ignoring other clutter in the scene, and translate the interpreted instruction and perception into the robot’s action space.
Experimental Results
In language models, it is well known that sentence embeddings generalize on compositions of concepts encountered in training data. For instance, if you train a translation model on sentences like “pick up a cup” and “push a bowl”, the model should also translate “push a cup” correctly.
We study the question of whether the compositional generalization capabilities found in language encoders can be transferred to real robots, i.e., being able to compose unseen object-object and task-object pairs.
We test this method by pre-selecting a set of 28 tasks, none of which were among the 100 training tasks. For example, one of these new test tasks is to pick up the grapes and place them into a ceramic bowl, but the training tasks involve doing other things with the grapes and placing other items into the ceramic bowl. The grapes and the ceramic bowl never appeared in the same scene during training.
In our experiments, we see that the robot can complete many tasks that were not included in the training set. Below are a few examples of the robot’s learned policy.
| The robot completes three instructions of tasks that were not in its training data, shown at 2x speed. |
Quantitatively, we see that the robot can succeed to some degree on a total of 24 out of the 28 held-out tasks, indicating a promising capacity for generalization. Further, we see a notably small gap between the performance on the training tasks and performance on the test tasks. These results indicate that simply improving multi-task visuomotor control could considerably improve performance.
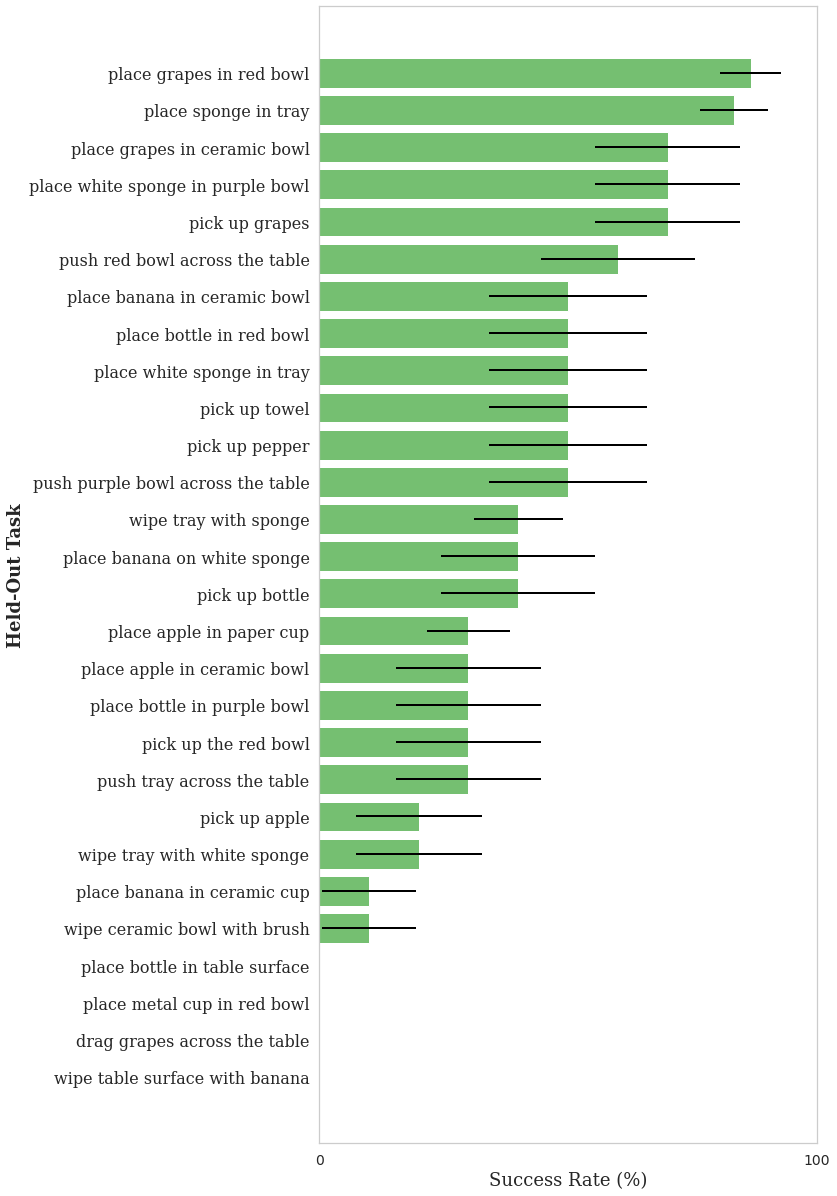 |
| The BC-Z performance on held-out tasks, i.e., tasks that the robot was not trained to perform. The system correctly interprets the language command and translates that into action to complete many of the tasks in our evaluation. |
Takeaways
The results of this research show that simple imitation learning approaches can be scaled in a way that enables zero-shot generalization to new tasks. That is, it shows one of the first indications of robots being able to successfully carry out behaviors that were not in the training data. Interestingly, language embeddings pre-trained on ungrounded language corpora make for excellent task conditioners. We demonstrated that natural language models can not only provide a flexible input interface to robots, but that pretrained language representations actually confer new generalization capabilities to the downstream policy, such as composing unseen object pairs together.
In the course of building this system, we confirmed that periodic human interventions are a simple but important technique for achieving good performance. While there is a substantial amount of work to be done in the future, we believe that the zero-shot generalization capabilities of BC-Z are an important advancement towards increasing the generality of robotic learning systems and allowing people to command robots. We have released the teleoperated demonstrations used to train the policy in this paper, which we hope will provide researchers with a valuable resource for future multi-task robotic learning research.
Acknowledgements
We would like to thank the co-authors of this research: Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, and Sergey Levine. This project was a collaboration between Google Research and the Everyday Robot Project. We would like to give special thanks to Noah Brown, Omar Cortes, Armando Fuentes, Kyle Jeffrey, Linda Luu, Sphurti Kirit More, Jornell Quiambao, Jarek Rettinghouse, Diego Reyes, Rosario Jau-regui Ruano, and Clayton Tan for overseeing robot operations and collecting human videos of the tasks, as well as Jeffrey Bingham, Jonathan Weisz, and Kanishka Rao for valuable discussions. We would also like to thank Tom Small for creating animations in this post and Paul Mooney for helping with dataset open-sourcing.
