Introducing CATER: A diagnostic dataset for video understanding that, by design, requires temporal reasoning to be solved.
While deep features have revolutionized static image analysis, deep video descriptors have struggled to outperform classic hand-crafted descriptors. Though recent works have shown improvements by through spatio-temporal architectures, simpler frame-based architectures still routinely appear among top performers in video challenge benchmarks. This raises the natural question: are videos trivially understandable by simply aggregating the predictions over a sampled set of frames?
At some level, the answer must be no. Reasoning about high-level cognitive concepts such as intentions, goals, and causal relations requires reasoning over long-term temporal structure and order. For example, consider the cup-and-ball parlor game shown next. In these games, an operator puts a target object (ball) under one of multiple container objects (cups), and moves them about, possibly revealing the target at various times and recursively containing cups within other cups. The task at the end is to tell which of the cups is covering the ball. Even in its simplest instantiation, one can expect any human or computer system that solves this task to require the ability to model state of the world over long temporal horizons, reason about occlusion, understand the spatiotemporal implications of containment, etc.
Given such intricate requirements for spatiotemporal reasoning, why don’t spatiotemporal models readily outperform their frame-based counterparts? We posit that this is due to limitations of existing video benchmarks. Even though datasets have evolved significantly in the past few years, tasks have remained highly correlated to the scene and object context. In this work, we take an alternate approach to developing a video understanding dataset. Inspired by the CLEVR dataset, and the adversarial parlor games described above, we introduce CATER, a diagnostic dataset for Compositional Actions and TEmporal Reasoning in dynamic tabletop scenes. We define three tasks on the dataset, each with an increasingly higher level of complexity, but set up as classification problems in order to be comparable to existing benchmarks for easy transfer of existing models and approaches. Next, we introduce the dataset, associated tasks, and evaluate state of the art video models, showing that they struggle on CATER’s temporal reasoning tasks.
The CATER Dataset
-

2 objects move at a time -
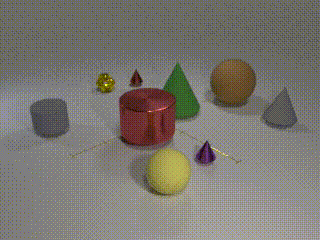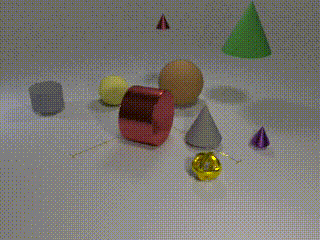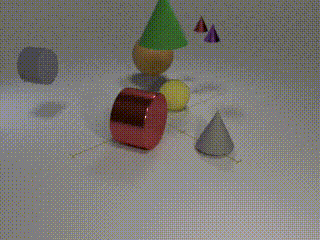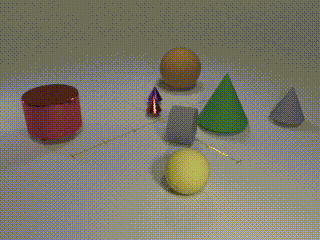
All objects move -

The camera also moves

Our CATER dataset builds upon the CLEVR dataset, which was originally proposed for question-answering based visual reasoning tasks (an example on left). CATER inherits and extends the set of object shapes, sizes, colors and materials present from CLEVR. Specifically, we add two new object shapes: inverted cones and a special object called a ‘snitch’, which we created to look like three intertwined toruses in metallic gold color (see if you can find it in the above videos!). In addition, we define four atomic actions: ‘rotate’, ‘pick-place’, ‘slide’ and ‘contain’; a subset of which is afforded by each object. While the first three are self-explanatory, the final action, ‘contain’, is a special operation, only afforded by the cones. In it, a cone is pick-placed on top of another object, which may be a sphere, a snitch or even a smaller cone. This also allows for recursive containment, as a cone can contain a smaller cone that contains another object. Once a cone ‘contains’ an object, it is constrained to only ‘slide’ actions and effectively slides all objects contained within the cone. This holds until the top-most cone is ‘pick-place’d to another location, effectively ending the containment for that top-most cone. Given these objects and actions, the videos are generated by first spawning a random number of objects with random parameters at random locations, and then adding a series of actions for all or subset of the objects. As the samples from CATER above show, we can control for the complexity of the data by limiting the number of objects, number of moving objects, as well as the motion of the camera.
Tasks on CATER
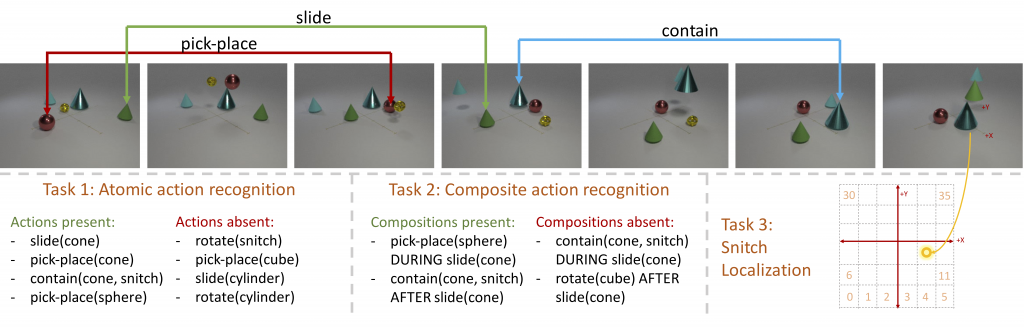
We define three tasks with increasing temporal reasoning complexity on CATER, as illustrated in the figure above.
- The first and perhaps the simplest task is Atomic Action Recognition. This task requires the models to classify what individual actions happen in a given video, out of a total of 14 action classes we define in CATER. This is set up as a multi-label classification problem, since multiple actions can happen in a video, and the model needs to predict all of them. The predictions are evaluated using mean Average Precision (mAP), which is a standard metric metric used in similar problem settings.
- The second task on CATER is Compositional Action Recognition. Here, the models need to reason about ordering of different actions in the video (i.e., X happens “before”/”after”/”during” Y), and predict all the combinations that are active in the given video, out of the 301 unique combinations possible using the 14 atomic actions. Similar to Task 1, it is evaluated using mAP.
- Finally, the flagship task on CATER is Snitch Localization, which is directly inspired from the cup-and-ball shell game described earlier. The task now is to predict the location of the snitch at the end of the video. While it may seem trivial to localize it from the last frame, it may not always be possible to do that due to occlusions and recursive containments. For simplicity, we pose this as a classification problem by quantizing the (6 times 6) grid on the floor into 36 cells, and evaluate the performance using a standard accuracy metric.
How do video models fare on CATER?
We evaluate multiple state of the art video recognition models on all tasks defined on CATER. Specifically, we focus on three broad model architectures:
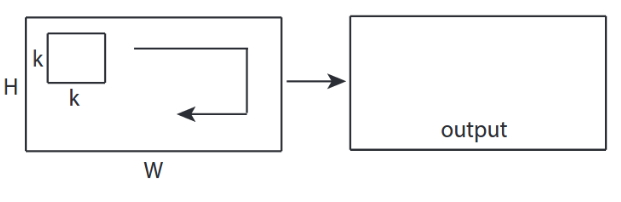
- Frame-level models: These models are similar to image classification models, and are applied to a sampled set of frames from the video. The specific architecture we use is Inception-V2, based on the popular TSN paper, which obtained strong performance on multiple video understanding tasks.
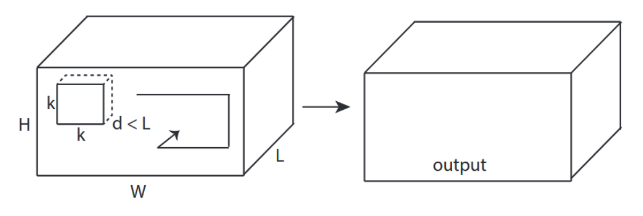
- Spatio-temporal models: These models extend the idea of 2D convolution (over the height-width of an image) to a 3D convolution (over the height-width-time of a video clip), as shown in the figure above. These models are better capable of capturing the temporal dynamics in videos. Specifically, we experiment with the ResNet-3D architecture, along with its non-local extension, from the Non-Local Neural Networks paper, which also obtains strong performance on video recognition tasks.
- Tracker: For task 3, we also experiment with a tracking based solution, where we initialize a state of the art tracker to a box around the initial ground truth position of the snitch on the first frame. At the last frame, we take the center point of the tracked box in the image plane, and project it to the 3D world plane using a precomputed homography between the image and world planes. The projected 3D point is then converted to the quantized grid position and evaluated for the top-1 accuracy.
Since most video models are designed to operate on short clips of the whole video, we experiment with two approaches to aggregate the predictions over the whole video:
- Average pooling (Avg): This is the typical approach used on most benchmarks, where we average the last layer predictions (logits) for each frame/clip of the video.
- LSTM: We train a 2-layer LSTM over the features from clips in the video. While LSTMs haven’t shown strong improvements on standard video classification benchmarks, we experiment with them here given the temporal nature of our tasks.
| Model | Top-1 (Avg) |
Top-1 (LSTM) |
| Random | 2.8 | 2.8 |
| Frame-level RGB model | 14.1 | 25.6 |
| Spatio-temporal RGB model | 57.4 | 60.2 |
| Tracker | 33.9 | 33.9 |
Task 1 and 2 are presented in the paper.

We observed that most models are easily able to solve the Task 1, since that only requires short-term temporal reasoning to recognize individual actions. Task 2 and 3, on the other hand, pose more of a challenge to video models, given their temporal nature. While full results are provided in the paper, we highlight some key results on the snitch localization task (Task 3) in the attached table. First, we note that the 2D, or frame-level models, perform quite poorly on this task. This is unlike the observation on other standard video datasets, where the frame-level models are quite competitive with spatio-temporal models. Second, we note that a state of the art tracking method (Zhu et al., ECCV’18), is only able to solve about a third of the videos, showing that low-level trackers may not solve this task either (see, for example, the attached video of a tracker failure case). Third, the performance of LSTM aggregation was always better than average pooling, since that is better suited to capture the temporal nature of the tasks. And finally, we note that best performance is still fairly low on this task, suggesting scope for future work.
Diagnostics using CATER
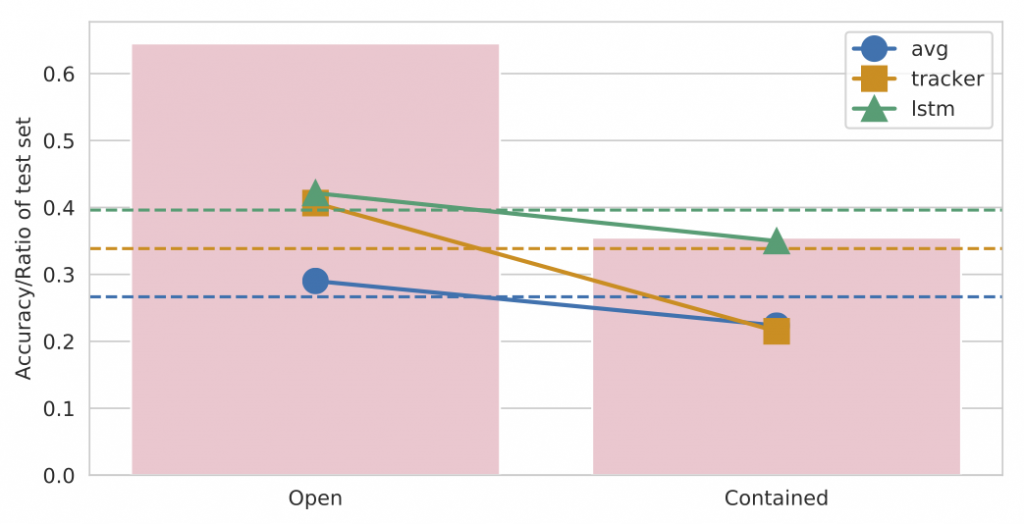
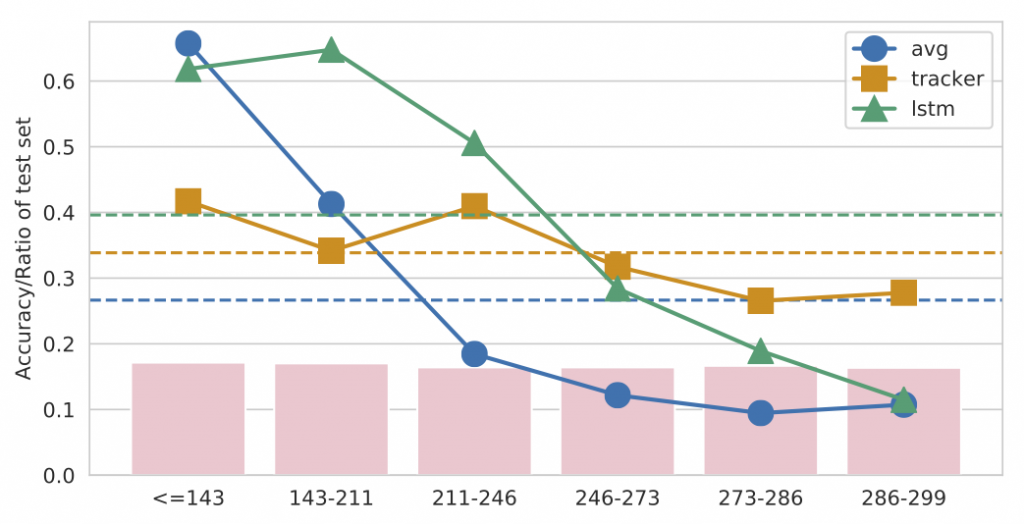
Having close control over the dataset generation process enables us to perform diagnostics impossible with any previous dataset. While full analysis over multiple control parameters (like camera motion, number of objects etc.) is provided in the paper, we highlight two ablations in the figure above. First, we evaluate the performance of our models with different aggregation schemes, over the cases when the snitch was visible at the end of the video, and when it was contained. As expected, the performance drops when it’s contained, with the tracking based model dropping the most suggesting that the tracker is not effective at handling the containments and occlusions. In the second ablation, we evaluate the performance as a function of the last time in the video the snitch moves. We observe that the performance of all models consistently drops as the snitch keeps moving throughout the video. Interestingly, the tracker is the most resilient approach here, since it attempts to explicitly keep track of the snitch’s position until the end, unlike the other models that rely on aggregating belief over the snitch’s location over all clips of the video. The following video provides some qualitative examples of the videos where models perform well (easy cases) and the ones where they do not (hard cases).
Discussion
To conclude, in this work we introduced and used CATER to analyze several leading network designs on hard spatiotemporal reasoning tasks. We found most models struggle on CATER, especially on the snitch localization task which requires long term reasoning. Such temporal reasoning challenges are common in the real world, and solving those would be the cornerstone of the next improvements in machine video understanding. That said, CATER is, by no means, a complete solution to the video understanding problem. Like any other synthetic or simulated dataset, it should be considered in addition to real world benchmarks. One of our findings is that while high-level semantic tasks such as activity recognition may be addressable with current architectures given a richly labeled dataset, “mid-level” tasks such as tracking still pose tremendous challenges, particularly under long-term occlusions and containment. We believe addressing such challenges will enable broader temporal reasoning tasks that capture intentions, goals, and causal behavior.
Additionally, note that CATER is also not limited to video classification. Recent papers have also used CATER for other related tasks like video reconstruction and for learning object permanence. We have released a pre-generated version of CATER, along with full metadata, which can be used to define arbitrarily fine-grained spatio-temporal reasoning tasks. Additionally, we have released the code to generate CATER as well as the baselines discussed above, which can be used to reproduce our experiments or generate a custom variant of CATER for other tasks.
Interested in more details?
Check out the links to the paper, complete codebase with pre-trained models, talk and project webpage below.