Chronomics is a tech-bio company that uses biomarkers—quantifiable information taken from the analysis of molecules—alongside technology to democratize the use of science and data to improve the lives of people. Their goal is to analyze biological samples and give actionable information to help you make decisions—about anything where knowing more about the unseen is important. Chronomics’s platform enables providers to seamlessly implement at-home diagnostics at scale—all without sacrificing efficiency or accuracy. It has already processed millions of tests through this platform and delivers a high-quality diagnostics experience.
During the COVID-19 pandemic, Chronomics sold lateral flow tests (LFT) for detecting COVID-19. The users register the test on the platform by uploading a picture of the test cassette and entering a manual reading of the test (positive, negative or invalid). With the increase in the number of tests and users, it quickly became impractical to manually verify if the reported result matched the result in the picture of the test. Chronomics wanted to build a scalable solution that uses computer vision to verify the results.
In this post, we share how Chronomics used Amazon Rekognition to automatically detect the results of a COVID-19 lateral flow test.
Preparing the data
The following image shows the picture of a test cassette uploaded by a user. The dataset consists of images like this one. These images are to be classified as positive, negative, or invalid, corresponding to the outcome of a COVID-19 test.

The main challenges with the dataset were the following:
- Imbalanced dataset – The dataset was extremely skewed. More than 90% of the samples were from the negative class.
- Unreliable user inputs – Readings that were manually reported by the users were not reliable. Around 40% of the readings didn’t match the actual result from the picture.
To create a high-quality training dataset, Chronomics engineers decided to follow these steps:
- Manual annotation – Manually select and label 1,000 images to ensure that the three classes are evenly represented
- Image augmentation – Augment the labeled images to increase the number to 10,000
Image augmentation was performed using Albumentations, an open-source Python library. A number of transformations like rotation, rescale, and brightness were performed to generate 9,000 synthetic images. These synthetic images were added to the original images to create a high-quality dataset.
Building a custom computer vision model with Amazon Rekognition
Chronomics’s engineers turned towards Amazon Rekognition Custom Labels, a feature of Amazon Rekognition with AutoML capabilities. After training images are provided, it can automatically load and inspect the data, select the right algorithms, train a model, and provide model performance metrics. This significantly accelerates the process of training and deploying a computer vision model, making it the primary reason for Chronomics to adopt Amazon Rekognition. With Amazon Rekognition, we were able to get a highly accurate model in 3–4 weeks as opposed to spending 4 months trying to build a custom model to achieve the desired performance.
The following diagram illustrates the model training pipeline. The annotated images were first preprocessed using an AWS Lambda function. This preprocessing step ensured that the images were in the appropriate file format and also performed some additional steps like resizing the image and converting the image from RGB to grayscale. It was observed that this improved the performance of the model.
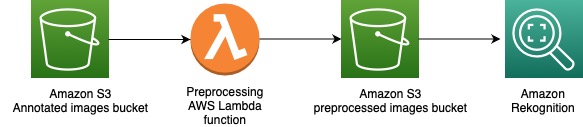
After the model has been trained, it can be deployed for inference using just a single click or API call.
Model performance and fine-tuning
The model yielded an accuracy of 96.5% and a F1 score of 97.9% on a set of out-of-sample images. The F1 score is a measure that uses both precision and recall to measure the performance of a classifier. The DetectCustomLabels API is used to detect the labels of a supplied image during inference. The API also returns the confidence that Rekognition Custom Labels has in the accuracy of the predicted label. The following chart has the distribution of the confidence scores of the predicted labels for the images. The x-axis represents the confidence score multiplied by 100, and the y-axis is the count of the predictions in log-scale.

By setting a threshold on the confidence score, we can filter out predictions that have a lower confidence. A threshold of 0.99 resulted in an accuracy of 99.6%, and 5% of the predictions were discarded. A threshold of 0.999 resulted in an accuracy of 99.87%, with 27% of the predictions discarded. In order to deliver the right business value, Chronomics picked a threshold of 0.99 to maximize the accuracy and minimize the rejection of predictions. For more information, see Analyzing an image with a trained model.
The discarded predictions can also be routed to a human in the loop using Amazon Augmented AI (Amazon A2I) for manually processing the image. For more information on how to do this, refer to Use Amazon Augmented AI with Amazon Rekognition.
The following image is an example where the model has correctly identified the test as invalid with a confidence of 0.999.

Conclusion
In this post, we showed the ease with which Chronomics quickly built and deployed a scalable computer vision-based solution that uses Amazon Rekognition to detect the result of a COVID-19 lateral flow test. The Amazon Rekognition API makes it very easy for practitioners to accelerate the process of building computer vision models.
Learn about how you can train computer vision models for your specific business use case by visiting Getting started with Amazon Rekognition custom labels and by reviewing the Amazon Rekognition Custom Labels Guide.
About the Authors
 Mattia Spinelli is a Senior Machine Learning Engineer at Chronomics, a biomedical company. Chronomics’s platform enables providers to seamlessly implement at-home diagnostics at scale—all without sacrificing efficiency or accuracy.
Mattia Spinelli is a Senior Machine Learning Engineer at Chronomics, a biomedical company. Chronomics’s platform enables providers to seamlessly implement at-home diagnostics at scale—all without sacrificing efficiency or accuracy.
 Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports.
Pinak Panigrahi works with customers to build machine learning driven solutions to solve strategic business problems on AWS. When not occupied with machine learning, he can be found taking a hike, reading a book or catching up with sports.
 Jay Rao is a Principal Solutions Architect at AWS. He enjoys providing technical and strategic guidance to customers and helping them design and implement solutions on AWS.
Jay Rao is a Principal Solutions Architect at AWS. He enjoys providing technical and strategic guidance to customers and helping them design and implement solutions on AWS.
 Pashmeen Mistry is a Senior Product Manager at AWS. Outside of work, Pashmeen enjoys adventurous hikes, photography, and spending time with his family.
Pashmeen Mistry is a Senior Product Manager at AWS. Outside of work, Pashmeen enjoys adventurous hikes, photography, and spending time with his family.