Over the past several years, deep neural networks (DNNs) have been quite successful in driving impressive performance gains in several real-world applications, from image recognition to genomics. However, modern DNNs often have far more trainable model parameters than the number of training examples and the resulting overparameterized networks can easily overfit to noisy or corrupted labels (i.e., examples that are assigned a wrong class label). As a consequence, training with noisy labels often leads to degradation in accuracy of the trained model on clean test data. Unfortunately, noisy labels can appear in several real-world scenarios due to multiple factors, such as errors and inconsistencies in manual annotation and the use of inherently noisy label sources (e.g., the internet or automated labels from an existing system).
Earlier work has shown that representations learned by pre-training large models with noisy data can be useful for prediction when used in a linear classifier trained with clean data. In principle, it is possible to directly train machine learning (ML) models on noisy data without resorting to this two-stage approach. To be successful, such alternative methods should have the following properties: (i) they should fit easily into standard training pipelines with little computational or memory overhead; (ii) they should be applicable in “streaming” settings where new data is continuously added during training; and (iii) they should not require data with clean labels.
In “Constrained Instance and Class Reweighting for Robust Learning under Label Noise”, we propose a novel and principled method, named Constrained Instance reWeighting (CIW), with these properties that works by dynamically assigning importance weights both to individual instances and to class labels in a mini-batch, with the goal of reducing the effect of potentially noisy examples. We formulate a family of constrained optimization problems that yield simple solutions for these importance weights. These optimization problems are solved per mini-batch, which avoids the need to store and update the importance weights over the full dataset. This optimization framework also provides a theoretical perspective for existing label smoothing heuristics that address label noise, such as label bootstrapping. We evaluate the method with varying amounts of synthetic noise on the standard CIFAR-10 and CIFAR-100 benchmarks and observe considerable performance gains over several existing methods.
Method
Training ML models involves minimizing a loss function that indicates how well the current parameters fit to the given training data. In each training step, this loss is approximately calculated as a (weighted) sum of the losses of individual instances in the mini-batch of data on which it is operating. In standard training, each instance is treated equally for the purpose of updating the model parameters, which corresponds to assigning uniform (i.e., equal) weights across the mini-batch.
However, empirical observations made in earlier works reveal that noisy or mislabeled instances tend to have higher loss values than those that are clean, particularly during early to mid-stages of training. Thus, assigning uniform importance weights to all instances means that due to their higher loss values, the noisy instances can potentially dominate the clean instances and degrade the accuracy on clean test data.
Motivated by these observations, we propose a family of constrained optimization problems that solve this problem by assigning importance weights to individual instances in the dataset to reduce the effect of those that are likely to be noisy. This approach provides control over how much the weights deviate from uniform, as quantified by a divergence measure. It turns out that for several types of divergence measures, one can obtain simple formulae for the instance weights. The final loss is computed as the weighted sum of individual instance losses, which is used for updating the model parameters. We call this the Constrained Instance reWeighting (CIW) method. This method allows for controlling the smoothness or peakiness of the weights through the choice of divergence and a corresponding hyperparameter.
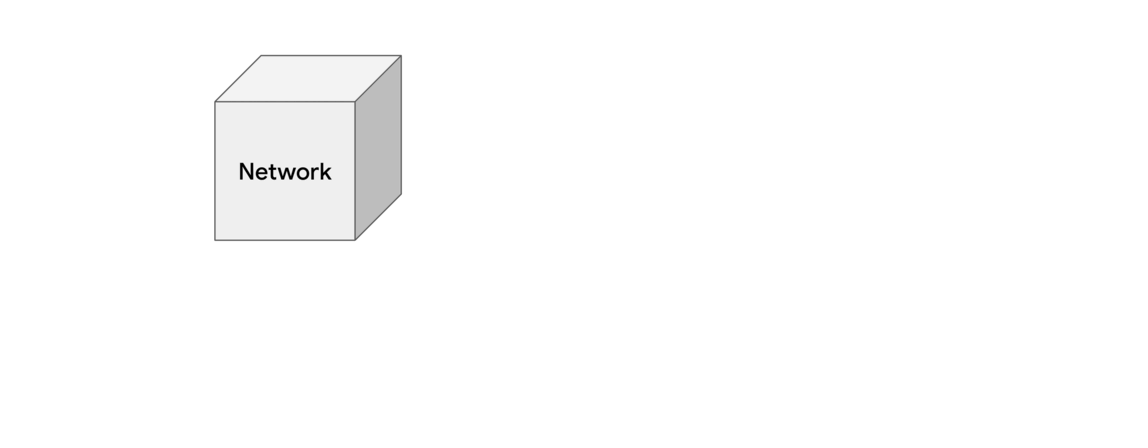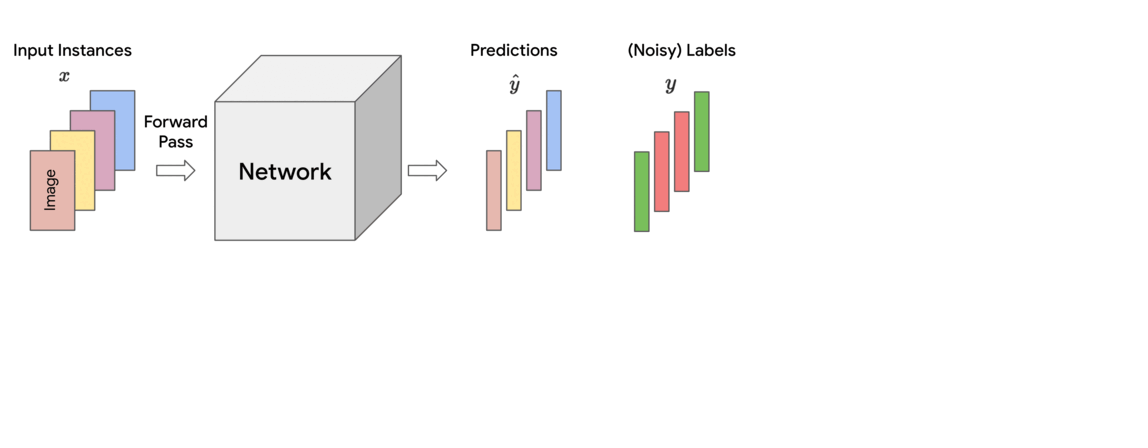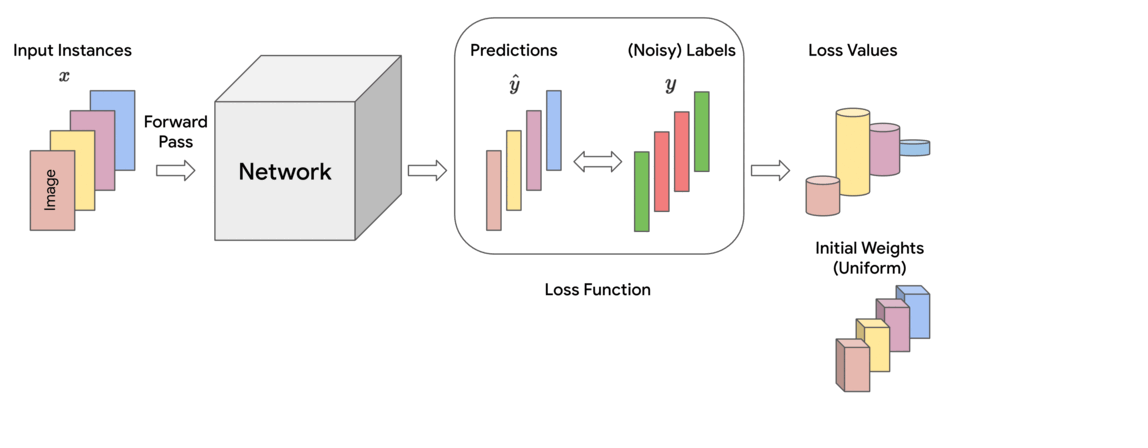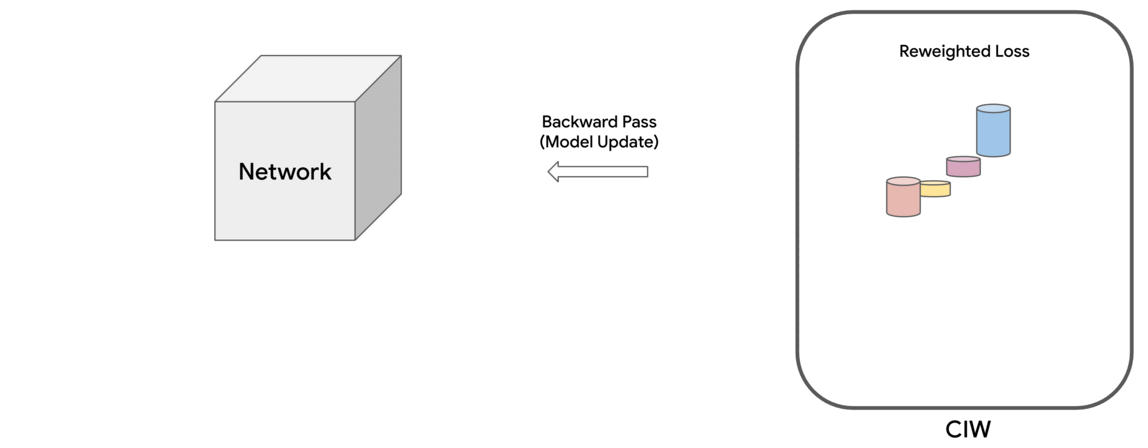 |
| Schematic of the proposed Constrained Instance reWeighting (CIW) method. |
Illustration with Decision Boundary on a 2D Dataset
As an example to illustrate the behavior of this method, we consider a noisy version of the Two Moons dataset, which consists of randomly sampled points from two classes in the shape of two half moons. We corrupt 30% of the labels and train a multilayer perceptron network on it for binary classification. We use the standard binary cross-entropy loss and an SGD with momentum optimizer to train the model. In the figure below (left panel), we show the data points and visualize an acceptable decision boundary separating the two classes with a dotted line. The points marked red in the upper half-moon and those marked green in the lower half-moon indicate noisy data points.
The baseline model trained with the binary cross-entropy loss assigns uniform weights to the instances in each mini-batch, thus eventually overfitting to the noisy instances and resulting in a poor decision boundary (middle panel in the figure below).
The CIW method reweights the instances in each mini-batch based on their corresponding loss values (right panel in the figure below). It assigns larger weights to the clean instances that are located on the correct side of the decision boundary and damps the effect of noisy instances that incur a higher loss value. Smaller weights for noisy instances help in preventing the model from overfitting to them, thus allowing the model trained with CIW to successfully converge to a good decision boundary by avoiding the impact of label noise.
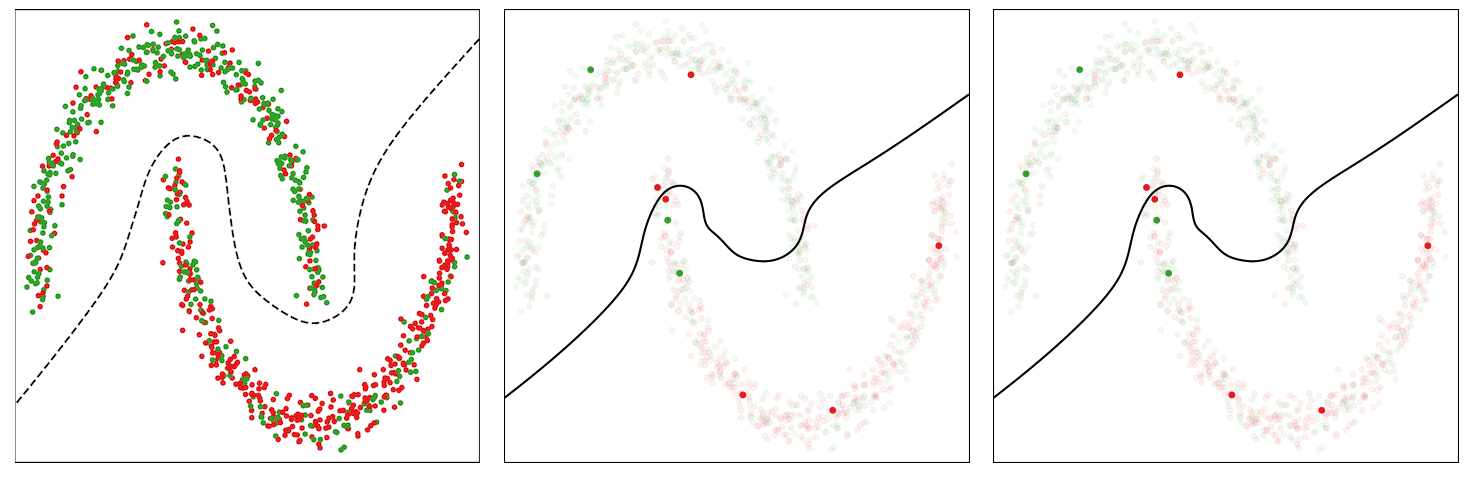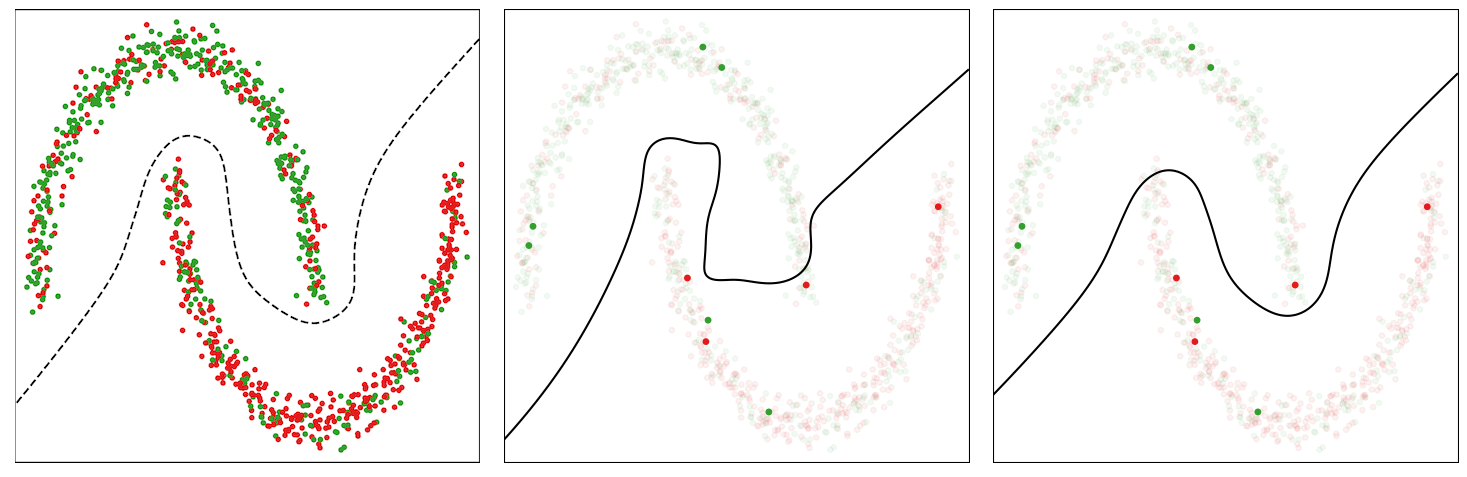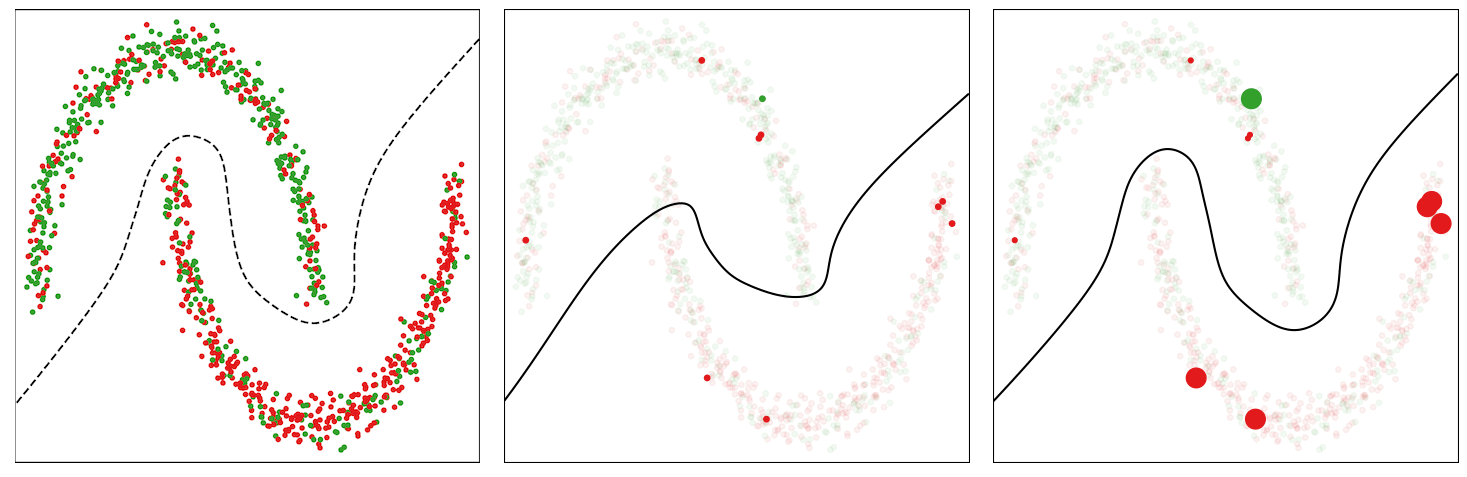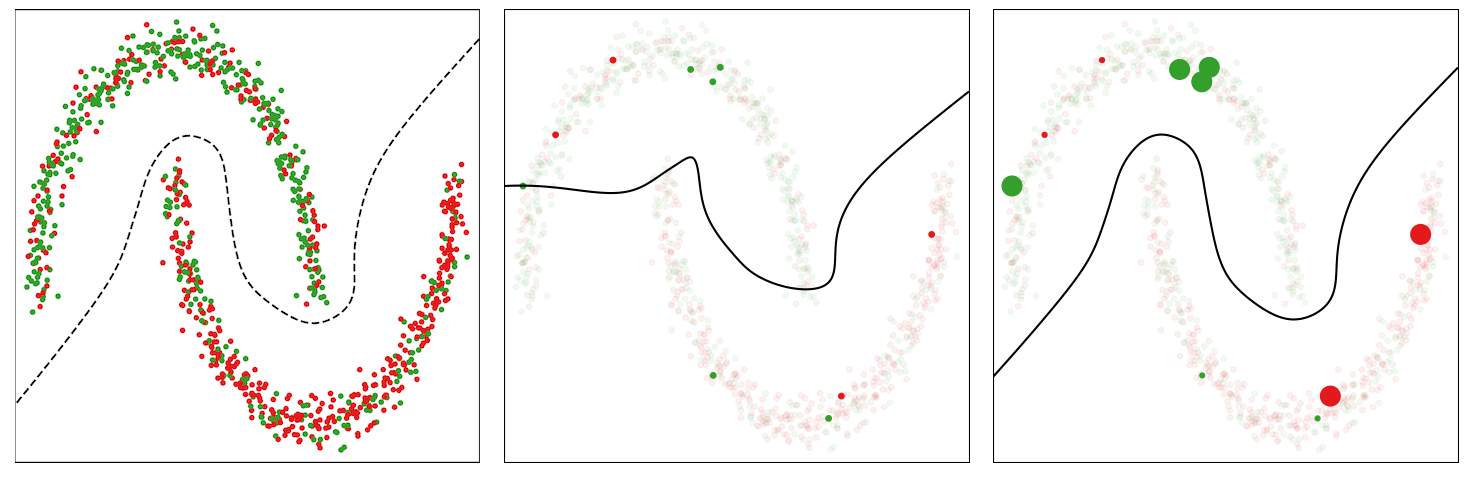 |
| Illustration of decision boundary as the training proceeds for the baseline and the proposed CIW method on the Two Moons dataset. Left: Noisy dataset with a desirable decision boundary. Middle: Decision boundary for standard training with cross-entropy loss. Right: Training with the CIW method. The size of the dots in (middle) and (right) are proportional to the importance weights assigned to these examples in the minibatch. |
<!–
 |
 |
 |
| Illustration of decision boundary as the training proceeds for the baseline and the proposed CIW method on the Two Moons dataset. Left: Noisy dataset with a desirable decision boundary. Middle: Decision boundary for standard training with cross-entropy loss. Right: Training with the CIW method. The size of the dots in (middle) and (right) are proportional to the importance weights assigned to these examples in the minibatch. |
–>
Constrained Class reWeighting
Instance reweighting assigns lower weights to instances with higher losses. We further extend this intuition to assign importance weights over all possible class labels. Standard training uses a one-hot label vector as the class weights, assigning a weight of 1 to the labeled class and 0 to all other classes. However, for the potentially mislabeled instances, it is reasonable to assign non-zero weights to classes that could be the true label. We obtain these class weights as solutions to a family of constrained optimization problems where the deviation of the class weights from the label one-hot distribution, as measured by a divergence of choice, is controlled by a hyperparameter.
Again, for several divergence measures, we can obtain simple formulae for the class weights. We refer to this as Constrained Instance and Class reWeighting (CICW). The solution to this optimization problem also recovers the earlier proposed methods based on static label bootstrapping (also referred as label smoothing) when the divergence is taken to be total variation distance. This provides a theoretical perspective on the popular method of static label bootstrapping.
Using Instance Weights with Mixup
We also propose a way to use the obtained instance weights with mixup, which is a popular method for regularizing models and improving prediction performance. It works by sampling a pair of examples from the original dataset and generating a new artificial example using a random convex combination of these. The model is trained by minimizing the loss on these mixed-up data points. Vanilla mixup is oblivious to the individual instance losses, which might be problematic for noisy data because mixup will treat clean and noisy examples equally. Since a high instance weight obtained with our CIW method is more likely to indicate a clean example, we use our instance weights to do a biased sampling for mixup and also use the weights in convex combinations (instead of random convex combinations in vanilla mixup). This results in biasing the mixed-up examples towards clean data points, which we refer to as CICW-Mixup.
We apply these methods with varying amounts of synthetic noise (i.e., the label for each instance is randomly flipped to other labels) on the standard CIFAR-10 and CIFAR-100 benchmark datasets. We show the test accuracy on clean data with symmetric synthetic noise where the noise rate is varied between 0.2 and 0.8.
We observe that the proposed CICW outperforms several methods and matches the results of dynamic mixup, which maintains the importance weights over the full training set with mixup. Using our importance weights with mixup in CICW-M, resulted in significantly improved performance vs these methods, particularly for larger noise rates (as shown by lines above and to the right in the graphs below).
 |
| Test accuracy on clean data while varying the amount of symmetric synthetic noise in the training data for CIFAR-10 and CIFAR-100. Methods compared are: standard Cross-Entropy Loss (CE), Bi-tempered Loss, Active-Passive Normalized Loss, the proposed CICW, Mixup, Dynamic Mixup, and the proposed CICW-Mixup. |
Summary and Future Directions
We formulate a novel family of constrained optimization problems for tackling label noise that yield simple mathematical formulae for reweighting the training instances and class labels. These formulations also provide a theoretical perspective on existing label smoothing–based methods for learning with noisy labels. We also propose ways for using the instance weights with mixup that results in further significant performance gains over instance and class reweighting. Our method operates solely at the level of mini-batches, which avoids the extra overhead of maintaining dataset-level weights as in some of the recent methods.
As a direction for future work, we would like to evaluate the method on realistic noisy labels that are encountered in large scale practical settings. We also believe that studying the interaction of our framework with label smoothing is an interesting direction that can result in a loss adaptive version of label smoothing. We are also excited to release the code for CICW, now available on Github.
Acknowledgements
We’d like to thank Kevin Murphy for providing constructive feedback during the course of the project.
